C++开发:为什么多线程读写shared_ptr要加锁的详细介绍
我在《Linux 多线程服务端编程:使用 muduo C++ 网络库》第 1.9 节“再论 shared_ptr 的线程安全”中写道:
(shared_ptr)的引用计数本身是安全且无锁的,但对象的读写则不是,因为 shared_ptr 有两个数据成员,读写操作不能原子化。根据文档(http://www.boost.org/doc/libs/release/libs/smart_ptr/shared_ptr.htm#ThreadSafety), shared_ptr 的线程安全级别和内建类型、标准库容器、std::string 一样,即:
• 一个 shared_ptr 对象实体可被多个线程同时读取(文档例1);
• 两个 shared_ptr 对象实体可以被两个线程同时写入(例2),“析构”算写操作;
• 如果要从多个线程读写同一个 shared_ptr 对象,那么需要加锁(例3~5)。
请注意,以上是 shared_ptr 对象本身的线程安全级别,不是它管理的对象的线程安全级别。
后文(p.18)则介绍如何高效地加锁解锁。本文则具体分析一下为什么“因为 shared_ptr 有两个数据成员,读写操作不能原子化”使得多线程读写同一个 shared_ptr 对象需要加锁。这个在我看来显而易见的结论似乎也有人抱有疑问,那将导致灾难性的后果,值得我写这篇文章。本文以 boost::shared_ptr 为例,与 std::shared_ptr 可能略有区别。
shared_ptr 的数据结构
shared_ptr 是引用计数型(reference counting)智能指针,几乎所有的实现都采用在堆(heap)上放个计数值(count)的办法(除此之外理论上还有用循环链表的办法,不过没有实例)。具体来说,shared_ptr<Foo> 包含两个成员,一个是指向 Foo 的指针 ptr,另一个是 ref_count 指针(其类型不一定是原始指针,有可能是 class 类型,但不影响这里的讨论),指向堆上的 ref_count 对象。ref_count 对象有多个成员,具体的数据结构如图 1 所示,其中 deleter 和 allocator 是可选的。

图 1:shared_ptr 的数据结构。
为了简化并突出重点,后文只画出 use_count 的值:

以上是 shared_ptr<Foo> x(new Foo); 对应的内存数据结构。
如果再执行 shared_ptr<Foo> y = x; 那么对应的数据结构如下。
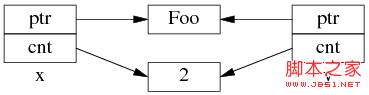
但是 y=x 涉及两个成员的复制,这两步拷贝不会同时(原子)发生。
中间步骤 1,复制 ptr 指针:

中间步骤 2,复制 ref_count 指针,导致引用计数加 1:

步骤1和步骤2的先后顺序跟实现相关(因此步骤 2 里没有画出 y.ptr 的指向),我见过的都是先1后2。
既然 y=x 有两个步骤,如果没有 mutex 保护,那么在多线程里就有 race condition。
多线程无保护读写 shared_ptr 可能出现的 race condition
考虑一个简单的场景,有 3 个 shared_ptr<Foo> 对象 x、g、n:
shared_ptr<Foo> g(new Foo); // 线程之间共享的 shared_ptrshared_ptr<Foo> x; // 线程 A 的局部变量shared_ptr<Foo> n(new Foo); // 线程 B 的局部变量
一开始,各安其事。

线程 A 执行 x = g; (即 read g),以下完成了步骤 1,还没来及执行步骤 2。这时切换到了 B 线程。

同时编程 B 执行 g = n; (即 write g),两个步骤一起完成了。
先是步骤 1:

再是步骤 2:

这是 Foo1 对象已经销毁,x.ptr 成了空悬指针!
最后回到线程 A,完成步骤 2:

多线程无保护地读写 g,造成了“x 是空悬指针”的后果。这正是多线程读写同一个 shared_ptr 必须加锁的原因。
当然,race condition 远不止这一种,其他线程交织(interweaving)有可能会造成其他错误。
思考,假如 shared_ptr 的 operator= 实现是先复制 ref_count(步骤 2)再复制 ptr(步骤 1),会有哪些 race condition?
杂项shared_ptr 作为 unordered_map 的 key
如果把 boost::shared_ptr 放到 unordered_set 中,或者用于 unordered_map 的 key,那么要小心 hash table 退化为链表。http://stackoverflow.com/questions/6404765/c-shared-ptr-as-unordered-sets-key/12122314#12122314
直到 Boost 1.47.0 发布之前,unordered_set<std::shared_ptr<T> > 虽然可以编译通过,但是其 hash_value 是 shared_ptr 隐式转换为 bool 的结果。也就是说,如果不自定义hash函数,那么 unordered_{set/map} 会退化为链表。https://svn.boost.org/trac/boost/ticket/5216
Boost 1.51 在 boost/functional/hash/extensions.hpp 中增加了有关重载,现在只要包含这个头文件就能安全高效地使用 unordered_set<std::shared_ptr> 了。
这也是 muduo 的 examples/idleconnection 示例要自己定义 hash_value(const boost::shared_ptr<T>& x) 函数的原因(书第 7.10.2 节,p.255)。因为 Debian 6 Squeeze、Ubuntu 10.04 LTS 里的 boost 版本都有这个 bug。
为什么图 1 中的 ref_count 也有指向 Foo 的指针?
shared_ptr<Foo> sp(new Foo) 在构造 sp 的时候捕获了 Foo 的析构行为。实际上 shared_ptr.ptr 和 ref_count.ptr 可以是不同的类型(只要它们之间存在隐式转换),这是 shared_ptr 的一大功能。分 3 点来说:
1. 无需虚析构;假设 Bar 是 Foo 的基类,但是 Bar 和 Foo 都没有虚析构。
shared_ptr<Foo> sp1(new Foo); // ref_count.ptr 的类型是 Foo*
shared_ptr<Bar> sp2 = sp1; // 可以赋值,自动向上转型(up-cast)
sp1.reset(); // 这时 Foo 对象的引用计数降为 1
此后 sp2 仍然能安全地管理 Foo 对象的生命期,并安全完整地释放 Foo,因为其 ref_count 记住了 Foo 的实际类型。
2. shared_ptr<void> 可以指向并安全地管理(析构或防止析构)任何对象;muduo::net::Channel class 的 tie() 函数就使用了这一特性,防止对象过早析构,见书 7.15.3 节。
shared_ptr<Foo> sp1(new Foo); // ref_count.ptr 的类型是 Foo*
shared_ptr<void> sp2 = sp1; // 可以赋值,Foo* 向 void* 自动转型
sp1.reset(); // 这时 Foo 对象的引用计数降为 1
此后 sp2 仍然能安全地管理 Foo 对象的生命期,并安全完整地释放 Foo,不会出现 delete void* 的情况,因为 delete 的是 ref_count.ptr,不是 sp2.ptr。
3. 多继承。假设 Bar 是 Foo 的多个基类之一,那么:
shared_ptr<Foo> sp1(new Foo);
shared_ptr<Bar> sp2 = sp1; // 这时 sp1.ptr 和 sp2.ptr 可能指向不同的地址,因为 Bar subobject 在 Foo object 中的 offset 可能不为0。
sp1.reset(); // 此时 Foo 对象的引用计数降为 1
但是 sp2 仍然能安全地管理 Foo 对象的生命期,并安全完整地释放 Foo,因为 delete 的不是 Bar*,而是原来的 Foo*。换句话说,sp2.ptr 和 ref_count.ptr 可能具有不同的值(当然它们的类型也不同)。
为什么要尽量使用 make_shared()?
为了节省一次内存分配,原来 shared_ptr<Foo> x(new Foo); 需要为 Foo 和 ref_count 各分配一次内存,现在用 make_shared() 的话,可以一次分配一块足够大的内存,供 Foo 和 ref_count 对象容身。数据结构是:

不过 Foo 的构造函数参数要传给 make_shared(),后者再传给 Foo::Foo(),这只有在 C++11 里通过 perfect forwarding 才能完美解决。
相关推荐
-
详解C++中shared_ptr的使用教程
shared_ptr是一种智能指针(smart pointer).shared_ptr的作用有如同指针,但会记录有多少个shared_ptrs共同指向一个对象. 这便是所谓的引用计数(reference counting).一旦最后一个这样的指针被销毁,也就是一旦某个对象的引用计数变为0,这个对象会被自动删除.这在非环形数据结构中防止资源泄露很有帮助. auto_ptr由于它的破坏性复制语义,无法满足标准容器对元素的要求,因而不能放在标准容器中:如果我们希望当容器析构时能自动把它容纳的指针元素所
-
浅析Boost智能指针:scoped_ptr shared_ptr weak_ptr
一. scoped_ptrboost::scoped_ptr和std::auto_ptr非常类似,是一个简单的智能指针,它能够保证在离开作用域后对象被自动释放.下列代码演示了该指针的基本应用: 复制代码 代码如下: #include <string>#include <iostream>#include <boost/scoped_ptr.hpp> class implementation{public: ~implementation() { std::cout
-

C++开发:为什么多线程读写shared_ptr要加锁的详细介绍
我在<Linux 多线程服务端编程:使用 muduo C++ 网络库>第 1.9 节"再论 shared_ptr 的线程安全"中写道: (shared_ptr)的引用计数本身是安全且无锁的,但对象的读写则不是,因为 shared_ptr 有两个数据成员,读写操作不能原子化.根据文档(http://www.boost.org/doc/libs/release/libs/smart_ptr/shared_ptr.htm#ThreadSafety), shared_ptr 的线程
-
IOS开发之多线程NSThiread GCD NSOperation Runloop
IOS中的进程和线程 通长来说一个app就是一个进程 ios开发中较少的运用进程间的通信(XPC),绝大多数使用线程. 在ios开发中,为了保证流畅性以及线程安全,所有与UI相关的操作都应该放在主线程,所以有时候主线程也叫UI线程. 影响UI体验,耗时时间较长的操作,尽量放到非主线程中.比如网络请求以及和本地的IO操作. 在IOS开发中有关于多线程的知识点主要包括:NSThread.GCD.NSOperation和Runloop NSThread NSthread就是一个线程,它的底层是对pth
-
对Python多线程读写文件加锁的实例详解
Python的多线程在io方面比单线程还是有优势,但是在多线程开发时,少不了对文件的读写操作.在管理多个线程对同一文件的读写操作时,就少不了文件锁了. 使用fcntl 在linux下,python的标准库有现成的文件锁,来自于fcntl模块.这个模块提供了unix系统fcntl()和ioctl()的接口. 对于文件锁的操作,主要需要使用 fcntl.flock(fd, operation)这个函数. 其中,参数 fd 表示文件描述符:参数 operation 指定要进行的锁操作,该参数的取值有如
-
Android编程开发实现多线程断点续传下载器实例
本文实例讲述了Android编程开发实现多线程断点续传下载器.分享给大家供大家参考,具体如下: 使用多线程断点续传下载器在下载的时候多个线程并发可以占用服务器端更多资源,从而加快下载速度,在下载过程中记录每个线程已拷贝数据的数量,如果下载中断,比如无信号断线.电量不足等情况下,这就需要使用到断点续传功能,下次启动时从记录位置继续下载,可避免重复部分的下载.这里采用数据库来记录下载的进度. 效果图: 断点续传 1.断点续传需要在下载过程中记录每条线程的下载进度 2.每次下载开始之前先读取数据库
-
Android开发之多线程中实现利用自定义控件绘制小球并完成小球自动下落功能实例
本文实例讲述了Android开发之多线程中实现利用自定义控件绘制小球并完成小球自动下落功能的方法.分享给大家供大家参考,具体如下: 1.布局界面 <RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:tools="http://schemas.android.com/tools" android:layout_width="match_pare
-
iOS开发探索多线程GCD常用函数
目录 正文 单例 栅栏函数 调度组 dispatch_group_t 信号量 dispatch_semaphore_t dispatch_source 总结 正文 前篇文章我们了解了GCD的任务的原理,接下来我们在探索一下GCD中我们开发常用的函数 单例 下面我们从源码中看一下我们创建单例的时候使用的dispatch_once,都做了什么,是通过什么操作保证全局唯一的 void dispatch_once(dispatch_once_t *val, dispatch_block_t block)
-
iOS开发探索多线程GCD任务示例详解
目录 引言 同步任务 死锁 异步任务 总结 引言 在上一篇文章中,我们探寻了队列是怎么创建的,串行队列和并发队列之间的区别,接下来我们在探寻一下GCD的另一个核心 - 任务 同步任务 void dispatch_sync(dispatch_queue_t queue, DISPATCH_NOESCAPE dispatch_block_t block); 我们先通过lldb查看其堆栈信息,分别查看其正常运行和死锁状态的信息 我们再通过源码查询其实现 #define _dispatch_Block_
-
iOS开发探索多线程GCD队列示例详解
目录 引言 进程与线程 1.进程的定义 2.线程的定义 3. 进程和线程的关系 4. 多线程 5. 时间片 6. 线程池 GCD 1.任务 2.队列 3.死锁 总结 引言 在iOS开发过程中,绕不开网络请求.下载图片之类的耗时操作,这些操作放在主线程中处理会造成卡顿现象,所以我们都是放在子线程进行处理,处理完成后再返回到主线程进行展示. 多线程贯穿了我们整个的开发过程,iOS的多线程操作有NSThread.GCD.NSOperation,其中我们最常用的就是GCD. 进程与线程 在了解GCD之前
-
Java多线程 乐观锁和CAS机制详细
目录 一.悲观锁和乐观锁 1.悲观锁 2.乐观锁 二.CAS机制 一.悲观锁和乐观锁 1.悲观锁 悲观锁是基于一种悲观的态度类来防止一切数据冲突,它是以一种预防的姿态在修改数据之前把数据锁住,然后再对数据进行读写,在它释放锁之前任何人都不能对其数据进行操作,直到前面一个人把锁释放后下一个人数据加锁才可对数据进行加锁,然后才可以对数据进行操作.synchronized是悲观锁,这种线程一旦得到锁,其他需要锁的线程就挂起的情况就是悲观锁. 特点:可以完全保证数据的独占性和正确性,因为每次请求都会先对
-
python GUI库图形界面开发之PyQt5多线程中信号与槽的详细使用方法与实例
PyQt5简单多线程信号与槽的使用 最简单的多线程使用方法是利用QThread函数,展示QThread函数和信号简单结合的方法 import sys from PyQt5.QtCore import * from PyQt5.QtWidgets import * class Main(QWidget): def __init__( self, parent=None ): super(Main, self).__init__(parent) #创建一个线程实例并设置名称 变量 信号与槽 self