MySQL批量插入遇上唯一索引避免方法
一、背景
以前使用SQL Server进行表分区的时候就碰到很多关于唯一索引的问题:Step8:SQL Server 当表分区遇上唯一约束,没想到在MySQL的分区中一样会遇到这样的问题:MySQL表分区实战。
今天我们来了解MySQL唯一索引的一些知识:包括如何创建,如何批量插入,还有一些技巧上SQL;
这些问题的根源在什么地方?有什么共同点?MySQL中也有分区对齐的概念?唯一索引是在很多系统中都会出现的要求,有什么办法可以避免?它对性能的影响有多大?
二、过程
(一) 导入差异数据,忽略重复数据,IGNORE INTO的使用
在MySQL创建表的时候,我们通常创建一个表的时候是以一个自增ID值作为主键,那么MySQL就会以PRIMARY KEY作为聚集索引键和主键,既然是主键,那当然是唯一的了,所以重复执行下面的插入语句会报1062错误:如Figure1所示;
代码如下:
-- 创建测试表
CREATE TABLE `testtable` (
`Id` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
`UserId` INT(11) DEFAULT NULL,
`UserName` VARCHAR(10) DEFAULT NULL,
`UserType` INT(11) DEFAULT NULL,
PRIMARY KEY (`Id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8;
-- 插入测试数据
INSERT INTO testtable(Id,UserId,UserName,UserType)
VALUES(1,101,'aa',1),(2,102,'bbb',2),(3,103,'ccc',3);

(Figure1:Duplicate entry '1' for key 'PRIMARY')
但是在实际的生产环境中,需求往往是需要在UserId键值中设置唯一索引,今天我就以这个作为示例,进行唯一索引的测试:
代码如下:
-- 创建测试表1
CREATE TABLE `testtable1` (
`Id` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
`UserId` INT(11) DEFAULT NULL,
`UserName` VARCHAR(10) DEFAULT NULL,
`UserType` INT(11) DEFAULT NULL,
PRIMARY KEY (`Id`),
UNIQUE KEY `IX_UserId` (`UserId`)
) ENGINE=INNODB DEFAULT CHARSET=utf8;
-- 创建测试表2
CREATE TABLE `testtable2` (
`Id` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
`UserId` INT(11) DEFAULT NULL,
`UserName` VARCHAR(10) DEFAULT NULL,
`UserType` INT(11) DEFAULT NULL,
PRIMARY KEY (`Id`),
UNIQUE KEY `IX_UserId` (`UserId`)
) ENGINE=INNODB DEFAULT CHARSET=utf8;
-- 插入测试数据1
INSERT INTO testtable1(Id,UserId,UserName,UserType)
VALUES(1,101,'aa',1),(2,102,'bbb',2),(3,103,'ccc',3);
-- 插入测试数据2
INSERT INTO testtable2(Id,UserId,UserName,UserType)
VALUES(1,201,'aaa',1),(2,202,'bbb',2),(3,203,'ccc',3),(4,101,'xxxx',5);
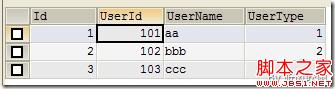
(Figure2:testtable1记录)
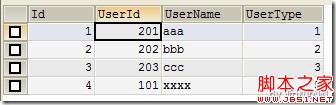
(Figure3:testtable2记录)
通过执行上面的SQL脚本,我们在testtable1和testtable2都创建了唯一索引:UNIQUE KEY `IX_UserId` (`UserId`),这就说明UserId在testtable1和testtable2表中都是唯一的,如果把testtable2的数据批量导入到testtable1,如果执行下面【导入1】的SQL,就会出现1062的错误,导致整个过程会回滚,没有达到导入差异数据的目的。
代码如下:
INSERT INTO testtable1(UserId,UserName,UserType)
SELECT UserId,UserName,UserType FROM testtable2;
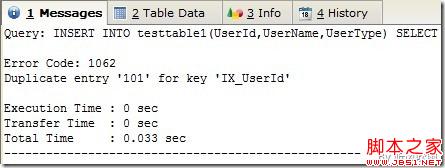
(Figure4:Duplicate entry '101' for key 'IX_UserId')
MySQL提供一个关键字:IGNORE,这个关键字判断每条记录是否存在,是否违反饿了表中的唯一索引,如果存在就不插入,而不存在的记录就会插入。
代码如下:
-- 导入2
INSERT IGNORE INTO testtable1(UserId,UserName,UserType)
SELECT UserId,UserName,UserType FROM testtable2;
所以执行完【导入2】,就会产生Figure5的结果,这已经达到了我们的目的了,但是你有没发现自增的ID值跳过了一些值,这是因为我们之前执行【导入1】失败造成的,虽然我们的事务回滚了,但是自增ID会出现断层。在SQL Server中也会有这样的问题。扩展阅读:简单实用SQL脚本Part:查找SQL Server 自增ID值不连续记录
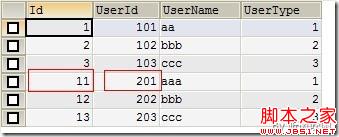
(Figure5:IGNORE效果)
(二) 导入并覆盖重复数据,REPLACE INTO 的使用
1. 把testtable1和testtable2分别回滚到Figure2和Figure3的状态(使用TRUNCATE TABLE命名再执行Insert语句),这个时候再执行下面的SQL,看有什么效果:
代码如下:
-- 导入3
REPLACE INTO testtable1(UserId,UserName)
SELECT UserId,UserName FROM testtable2;
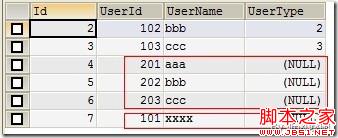
(Figure6:REPLACE效果)
从上图Figure6中,我们可以看到:UserId为101的记录发生了改变,不单UserName修改了,而且UserType也变为NULL了。
所以,如果导入中发现了重复的,先删除再插入,如果记录有多个字段,在插入的时候如果有的字段没有赋值,那么新插入的记录这些字段为空(新插入记录的UserType都为NULL)。
需要注意的是,当你replace的时候,如果被插入的表如果没有指定列,会用NULL表示,而不是这个表原来的内容。如果插入的内容列和被插入的表列一样,则不会出现NULL。
2. 如果我们表结构UserType字段不允许为空,而且没有默认值的情况,执行【导入3】会发生什么事情呢?
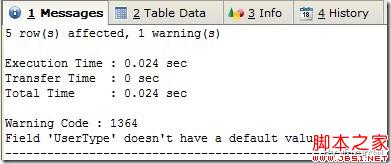
(Figure7:返回警告信息)
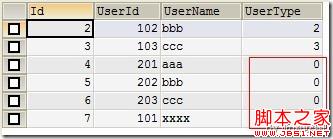
(Figure8:UserType被设置为0)
通过Figure7和Figure8,我们知道数据记录还是插入了,只是返回Field 'UserType' doesn't have a default value的警告,插入记录的UserType字段都被设置为0('UserType' 为int数据类型)。
3. 如果我们希望导入的时候一起更新UserType字段的值,这自然很简单了,使用下面的SQL脚本就可以解决:
代码如下:
-- 导入4
REPLACE INTO testtable1(UserId,UserName,UserType)
SELECT UserId,UserName,UserType FROM testtable2;
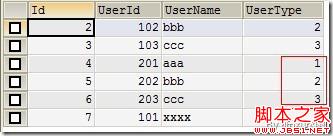
(Figure9:一起更新UserType)
(三) 导入保留重复数据未指定字段,INSERT INTO ON DUPLICATE KEY UPDATE 的使用
把testtable1和testtable2分别回滚到Figure2和Figure3的状态(使用TRUNCATE TABLE命名再执行Insert语句),这个时候再执行下面的SQL,看有什么效果:
代码如下:
-- 导入5
INSERT INTO testtable1(UserId,UserName)
SELECT UserId,UserName FROM testtable2
ON DUPLICATE KEY UPDATE
testtable1.UserName = testtable2.UserName;
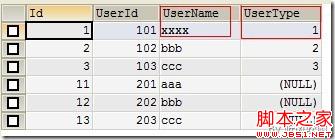
(Figure10:保留UserType值)
对比Figure2、Figure3与Figure10,UserId为101的记录:更新了UserName的值,保留了UserType的值;但是由于【导入5】中没有指定UserType,所以新插入记录的UserType是为NULL的。
代码如下:
-- 导入6
INSERT INTO testtable1(UserId,UserName,UserType)
SELECT UserId,UserName,UserType FROM testtable2
ON DUPLICATE KEY UPDATE
testtable1.UserName = testtable2.UserName;
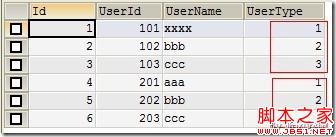
(Figure11:保留UserType值)
对比Figure2、Figure3与Figure11,只插入testtable2表的UserId,UserName字段,但是保留testtable1表的UserType字段。如果发现有重复的记录,做更新操作;在原有记录基础上,更新指定字段内容,其它字段内容保留。
(四) 总结
当在一个UNIQUE键上插入包含重复值的记录时,默认的insert会报1062错误,MYSQL可以通过以上三种不同的方式和你的业务逻辑进行处理。
三、参考文献
MYSQL插入处理重复键值的几种方法
相关推荐
-
mysql索引使用技巧及注意事项
一.索引的作用 一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,所以查询语句的优化显然是重中之重. 在数据量和访问量不大的情况下,mysql访问是非常快的,是否加索引对访问影响不大.但是当数据量和访问量剧增的时候,就会发现mysql变慢,甚至down掉,这就必须要考虑优化sql了,给数据库建立正确合理的索引,是mysql优化的一个重要手段. 索引的目的在于提高查询效率,可以类比字典,如果要查"mysql
-
MySQL 主键与索引的联系与区别分析
关系数据库依赖于主键,它是数据库物理模式的基石.主键在物理层面上只有两个用途: 惟一地标识一行. 作为一个可以被外键有效引用的对象. 索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针.下面是主键和索引的一些区别与联系. 1. 主键一定是唯一性索引,唯一性索引并不一定就是主键. 所谓主键就是能够唯一标识表中某一行的属性或属性组,一个表只能有一个主键,但可以有多个候选索引.因为主键可以唯一标识某一行记录,所以可以确保执行数据更新.删除的
-

基于mysql全文索引的深入理解
前言:本文简单讲述全文索引的应用实例,MYSQL演示版本5.5.24. Q:全文索引适用于什么场合? A:全文索引是目前实现大数据搜索的关键技术. 至于更详细的介绍请自行百度,本文不再阐述. -------------------------------------------------------------------------------- 一.如何设置? 如图点击结尾处的{全文搜索}即可设置全文索引,不同MYSQL版本名字可能不同. 二.设置条件 1.表的存储引擎是MyISAM,默认
-
Mysql中的Btree与Hash索引比较
mysql最常用的索引结构是btree(O(log(n))),但是总有一些情况下我们为了更好的性能希望能使用别的类型的索引.hash就是其中一种选择,例如我们在通过用户名检索用户id的时候,他们总是一对一的关系,用到的操作符只是=而已,假如使用hash作为索引数据结构的话,时间复杂度可以降到O(1).不幸的是,目前的mysql版本(5.6)中,hash只支持MEMORY和NDB两种引擎,而我们最常用的INNODB和MYISAM都不支持hash类型的索引. 不管怎样,还是要了解一下这两种索引的区别
-
MYSQL索引无效和索引有效的详细介绍
1.WHERE字句的查询条件里有不等于号(WHERE column!=...),MYSQL将无法使用索引2.类似地,如果WHERE字句的查询条件里使用了函数(如:WHERE DAY(column)=...),MYSQL将无法使用索引3.在JOIN操作中(需要从多个数据表提取数据时),MYSQL只有在主键和外键的数据类型相同时才能使用索引,否则即使建立了 索引也不会使用4.如果WHERE子句的查询条件里使用了比较操作符LIKE和REGEXP,MYSQL只有在搜索模板的第一个字符不是通配符的情况下才
-
Mysql建表与索引使用规范详解
一. MySQL建表,字段需设置为非空,需设置字段默认值.二. MySQL建表,字段需NULL时,需设置字段默认值,默认值不为NULL.三. MySQL建表,如果字段等价于外键,应在该字段加索引.四. MySQL建表,不同表之间的相同属性值的字段,列类型,类型长度,是否非空,是否默认值,需保持一致,否则无法正确使用索引进行关联对比.五. MySQL使用时,一条SQL语句只能使用一个表的一个索引.所有的字段类型都可以索引,多列索引的属性最多15个.六. 如果可以在多个索引中进行选择,MySQL通常
-
Mysql索引会失效的几种情况分析
索引并不是时时都会生效的,比如以下几种情况,将导致索引失效: 1.如果条件中有or,即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因) 注意:要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引 2.对于多列索引,不是使用的第一部分,则不会使用索引 3.like查询是以%开头 4.如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引 5.如果mysql估计使用全表扫描要比使用索引快,则不使用索引 此外,查看索引的使用情况show status li
-
MySQL 索引分析和优化
一.什么是索引? 索引用来快速地寻找那些具有特定值的记录,所有MySQL索引都以B-树的形式保存.如果没有索引,执行查询时MySQL必须从第一个记录开始扫描整个表的所有记录,直至找到符合要求的记录.表里面的记录数量越多,这个操作的代价就越高.如果作为搜索条件的列上已经创建了索引,MySQL无需扫描任何记录即可迅速得到目标记录所在的位置.如果表有1000个记录,通过索引查找记录至少要比顺序扫描记录快100倍. 假设我们创建了一个名为people的表: CREATE TABLE people ( p
-
mysql 添加索引 mysql 如何创建索引
1.添加PRIMARY KEY(主键索引) mysql>ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` ) 2.添加UNIQUE(唯一索引) mysql>ALTER TABLE `table_name` ADD UNIQUE ( `column` ) 3.添加INDEX(普通索引) mysql>ALTER TABLE `table_name` ADD INDEX index_name ( `column` ) 4.添加FULLTEX
-
MySQL索引类型总结和使用技巧以及注意事项
在数据库表中,对字段建立索引可以大大提高查询速度.假如我们创建了一个 mytable表: 复制代码 代码如下: CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL ); 我们随机向里面插入了10000条记录,其中有一条:5555, admin. 在查找username="admin"的记录 SELECT * FROM mytable WHERE username='admin';时,如果在