Python脚本实现12306火车票查询系统
最近我看到看到使用python实现火车票查询,我自己也实现了,感觉收获蛮多的,下面我就把每一步骤都详细给分享出来。(注意使用的是python3)
首先我将最终结果给展示出来:
在cmd命令行执行:python tickets.py -dk shanghai chengdu 20161007 > result.txt
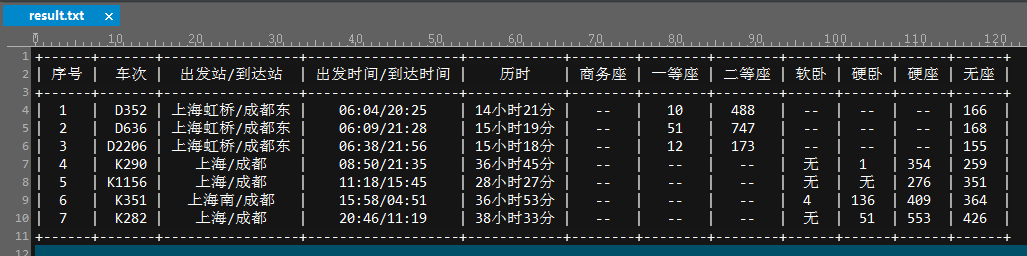
意思是:查询 上海--成都 2016.10.07 的D和K开头的列车信息,并保存到 result.txt文件中;下面就是result.txt文件中的结果:
下面的将是实现步骤:
1、安装第三方库 pip install 安装:requests,docopt,prettytable
2、docopt可以用来解析从命令行中输入的参数:
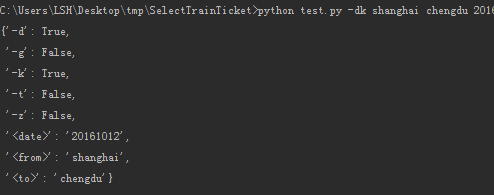
""" Usage: test [-gdtkz] <from> <to> <date> Options: -h,--help 显示帮助菜单 -g 高铁 -d 动车 -t 特快 -k 快速 -z 直达 Example: tickets -gdt beijing shanghai 2016-08-25 """ import docopt args = docopt.docopt(__doc__) print(args) # 上面 """ """ 包含中的: #Usage: # test [-gdtkz] <from> <to> <date> #是必须要的 test 是可以随便写的,不影响解析
最终打印的结果是一个字典,方便后面使用:
3、获取列车的信息
我们在12306的余票查询的接口:
url:https://kyfw.12306.cn/otn/lcxxcx/query?purpose_codes=ADULT&queryDate=2016-10-05&from_station=CDW&to_station=SHH
方法为:get
传输的参数:queryDate:2016-10-05、from_station:CDW、to_station:SHH
其中城市对应简称是需要另外的接口查询得出
3.1 查询城市对应的简称:
这个接口的url = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.8968'
方法是get,对返回结果利用正则表达式,取出城市名和简称的值(返回的值类似:7@cqn|重庆南|CRW|chongqingnan|cqn|,我们需要的就是:CRW、chongqingnan),代码如下
parse_stations.py:
#coding=utf-8
from prettytable import PrettyTable
class TrainCollection(object):
"""
解析列车信息
"""
# 显示车次、出发/到达站、 出发/到达时间、历时、一等坐、二等坐、软卧、硬卧、硬座
header = '序号 车次 出发站/到达站 出发时间/到达时间 历时 商务座 一等座 二等座 软卧 硬卧 硬座 无座'.split()
def __init__(self,rows,traintypes):
self.rows = rows
self.traintypes = traintypes
def _get_duration(self,row):
"""
获取车次运行的时间
"""
duration = row.get('lishi').replace(':','小时') + '分'
if duration.startswith('00'):
return duration[4:]
elif duration.startswith('0'):
return duration[1:]
return duration
@property
def trains(self):
result = []
flag = 0
for row in self.rows:
if row['station_train_code'][0] in self.traintypes:
flag += 1
train = [
# 序号
flag,
# 车次
row['station_train_code'],
# 出发、到达站点
'/'.join([row['from_station_name'],row['to_station_name']]),
# 成功、到达时间
'/'.join([row['start_time'],row['arrive_time']]),
# duration 时间
self._get_duration(row),
# 商务座
row['swz_num'],
# 一等座
row['zy_num'],
# 二等座
row['ze_num'],
# 软卧
row['rw_num'],
# 硬卧
row['yw_num'],
# 硬座
row['yz_num'],
# 无座
row['wz_num']
]
result.append(train)
return result
def print_pretty(self):
"""打印列车信息"""
pt = PrettyTable()
pt._set_field_names(self.header)
for train in self.trains:
pt.add_row(train)
print(pt)
if __name__ == '__main__':
t = TrainCollection()
其中pprint这个模块能是打印出来的信息,更加方便阅读:
在cmd中运行:python parse_stations.py > stations.py
就会在当前目录下得到stations.py文件,文件中就是站点名字和简称,在stations.py文件中加入"stations = "这样就是一个字典,方便后面的取值,下面就是stations.py文件的内容:

3.2 现在获取列车信息的参数已经准备齐了,接下来就是拿到列车的返回值,解析出自己需要的信息,比如:车次号,一等座的票数等等。。,myprettytable.py
#coding=utf-8
from prettytable import PrettyTable
class TrainCollection(object):
"""
解析列车信息
"""
# 显示车次、出发/到达站、 出发/到达时间、历时、一等坐、二等坐、软卧、硬卧、硬座
header = '序号 车次 出发站/到达站 出发时间/到达时间 历时 商务座 一等座 二等座 软卧 硬卧 硬座 无座'.split()
def __init__(self,rows,traintypes):
self.rows = rows
self.traintypes = traintypes
def _get_duration(self,row):
"""
获取车次运行的时间
"""
duration = row.get('lishi').replace(':','小时') + '分'
if duration.startswith('00'):
return duration[4:]
elif duration.startswith('0'):
return duration[1:]
return duration
@property
def trains(self):
result = []
flag = 0
for row in self.rows:
if row['station_train_code'][0] in self.traintypes:
flag += 1
train = [
# 序号
flag,
# 车次
row['station_train_code'],
# 出发、到达站点
'/'.join([row['from_station_name'],row['to_station_name']]),
# 成功、到达时间
'/'.join([row['start_time'],row['arrive_time']]),
# duration 时间
self._get_duration(row),
# 商务座
row['swz_num'],
# 一等座
row['zy_num'],
# 二等座
row['ze_num'],
# 软卧
row['rw_num'],
# 硬卧
row['yw_num'],
# 硬座
row['yz_num'],
# 无座
row['wz_num']
]
result.append(train)
return result
def print_pretty(self):
"""打印列车信息"""
pt = PrettyTable()
pt._set_field_names(self.header)
for train in self.trains:
pt.add_row(train)
print(pt)
if __name__ == '__main__':
t = TrainCollection()
prettytable 这个库是能打印出类似mysql查询数据显示出来的格式,
4、接下来就是整合各个模块:tickets.py
"""Train tickets query via command-line.
Usage:
tickets [-gdtkz] <from> <to> <date>
Options:
-h,--help 显示帮助菜单
-g 高铁
-d 动车
-t 特快
-k 快速
-z 直达
Example:
tickets -gdt beijing shanghai 2016-08-25
"""
import requests
from docopt import docopt
from stations import stations
# from pprint import pprint
from myprettytable import TrainCollection
class SelectTrain(object):
def __init__(self):
"""
获取命令行输入的参数
"""
self.args = docopt(__doc__)#这个是获取命令行的所有参数,返回的是一个字典
def cli(self):
"""command-line interface"""
# 获取 出发站点和目标站点
from_station = stations.get(self.args['<from>']) #出发站点
to_station = stations.get(self.args['<to>']) # 目的站点
leave_time = self._get_leave_time()# 出发时间
url = 'https://kyfw.12306.cn/otn/lcxxcx/query?purpose_codes=ADULT&queryDate={0}&from_station={1}&to_station={2}'.format(
leave_time,from_station,to_station)# 拼接请求列车信息的Url
# 获取列车查询结果
r = requests.get(url,verify=False)
traindatas = r.json()['data']['datas'] # 返回的结果,转化成json格式,取出datas,方便后面解析列车信息用
# 解析列车信息
traintypes = self._get_traintype()
views = TrainCollection(traindatas,traintypes)
views.print_pretty()
def _get_traintype(self):
"""
获取列车型号,这个函数的作用是的目的是:当你输入 -g 是只是返回 高铁,输入 -gd 返回动车和高铁,当不输参数时,返回所有的列车信息
"""
traintypes = ['-g','-d','-t','-k','-z']
# result = []
# for traintype in traintypes:
# if self.args[traintype]:
# result.append(traintype[-1].upper())
trains = [traintype[-1].upper() for traintype in traintypes if self.args[traintype]]
if trains:
return trains
else:
return ['G','D','T','K','Z']
def _get_leave_time(self):
"""
获取出发时间,这个函数的作用是为了:时间可以输入两种格式:2016-10-05、20161005
"""
leave_time = self.args['<date>']
if len(leave_time) == 8:
return '{0}-{1}-{2}'.format(leave_time[:4],leave_time[4:6],leave_time[6:])
if '-' in leave_time:
return leave_time
if __name__ == '__main__':
cli = SelectTrain()
cli.cli()
好了,基本上就结束了,按照开头的哪样,就能查询你想要的车次信息了
以上所述是小编给大家介绍的Python脚本实现12306火车票查询系统,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
利用python代码写的12306订票代码
本文实例讲述了python代码写的12306订票代码,分享给大家供大家参考. 具体实现方法如下: import datetime import json import re import sys import time import Image import PyV8 import requests import tools.email_helper as emailHelper reload(sys) sys.setdefaultencoding('utf-8') # @UndefinedVa
-

使用Python神器对付12306变态验证码
临近春节,我们小编带领大家用Python抢火车票! 首先我们需要splinter 安装: pip install splinter -i http://pypi.douban.com/simple –trusted-host pypi.douban.com 然后还需要一个浏览器的驱动,当然用chrome啦 下载地址: http://chromedriver.storage.googleapis.com/index.html?path=2.20/ 根据下载的自己的电脑系统选择下载包,我的windo
-
python+pyqt实现12306图片验证效果
本文实例为大家分享了python实现12306图片验证效果的具体代码,供大家参考,具体内容如下 思路:在鼠标点击位置加一个按钮,然后再按钮中的点击事件中写一个关闭事件. #coding:utf-8 from PyQt4.QtGui import * from PyQt4.QtCore import * from push_button import * from PIL import Image class Yanzheng(QWidget): def __init__(self,parent=
-
Python 用户登录验证的小例子
复制代码 代码如下: #!/usr/bin/python#coding=gbk class User: def __init__(self,username,password,age,sex): self.username=username self.password=password self.age=age self.sex=sex def tell(self): print 'UserContext:Name:%s
-
Python模拟登录12306的方法
本文实例讲述了Python模拟登录12306的方法.分享给大家供大家参考. 具体实现方法如下: 复制代码 代码如下: #!/usr/bin/python # -*- coding: utf-8 -*- import re; import sys; import cookielib; import urllib; import urllib2; import optparse; import json; import httplib2; reload(sys) sys.setdefaulten
-
Python验证码识别处理实例
一.准备工作与代码实例 (1)安装PIL:下载后是一个exe,直接双击安装,它会自动安装到C:\Python27\Lib\site-packages中去, (2)pytesser:下载解压后直接放C:\Python27\Lib\site-packages(根据你安装的Python路径而不同),同时,新建一个pytheeer.pth,内容就写pytesser,注意这里的内容一定要和pytesser这个文件夹同名,意思就是pytesser文件夹,pytesser.pth,及内容都要一样! (3)Te
-
Python爬虫模拟登录带验证码网站
爬取网站时经常会遇到需要登录的问题,这是就需要用到模拟登录的相关方法.python提供了强大的url库,想做到这个并不难.这里以登录学校教务系统为例,做一个简单的例子. 首先得明白cookie的作用,cookie是某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据.因此我们需要用Cookielib模块来保持网站的cookie. 这个是要登陆的地址 http://202.115.80.153/ 和验证码地址 http://202.115.80.153/CheckCode.
-
python 图片验证码代码
下面是一个实战项目的结果. 复制代码 代码如下: #coding: utf-8 import Image,ImageDraw,ImageFont,os,string,random,ImageFilter def initChars(): """ 允许的字符集合,初始集合为数字.大小写字母 usage: initChars() param: None return: list 返回允许的字符集和 for: picChecker类初始字符集合 todo: Nothing &quo
-
Python爬虫爬验证码实现功能详解
主要实现功能: - 登陆网页 - 动态等待网页加载 - 验证码下载 很早就有一个想法,就是自动按照脚本执行一个功能,节省大量的人力--个人比较懒.花了几天写了写,本着想完成验证码的识别,从根本上解决问题,只是难度太高,识别的准确率又太低,计划再次告一段落. 希望这次经历可以与大家进行分享和交流. Python打开浏览器 相比与自带的urllib2模块,操作比较麻烦,针对于一部分网页还需要对cookie进行保存,很不方便.于是,我这里使用的是Python2.7下的selenium模块进行网页上的操
-
python实现发送和获取手机短信验证码
首先为大家分享python实现发送手机短信验证码后台方法,供大家参考,具体内容如下 1.生成4位数字验证码 def createPhoneCode(session): chars=['0','1','2','3','4','5','6','7','8','9'] x = random.choice(chars),random.choice(chars),random.choice(chars),random.choice(chars) verifyCode = "".join(x) s