pandas实战:分析三国志人物示例实现
目录
- 简介
- 背景
- 特点:
- 安装
简介
背景
Pandas 是 Python 的一个工具库,用于数据分析。
由 AQR Capital Management 于 2008 年 4 月开发,2009 年开源,最初被作为金融数据分析工具而开发出来。
Pandas 名称来源于 panel data(面板数据)和 Python data analysis(Python 数据分析)。
适用于金融、统计等数据分析领域。
特点:
两大数据结构
Series 和 DataFrame
(1)Series:一维数据(列+索引)
pandas.Series(['东汉', '马腾', '?', 212], index=['国家', '姓名', '出生年份', '逝世年份'])

(2)DataFrame:二维数据(表格:多个列+行/列索引)
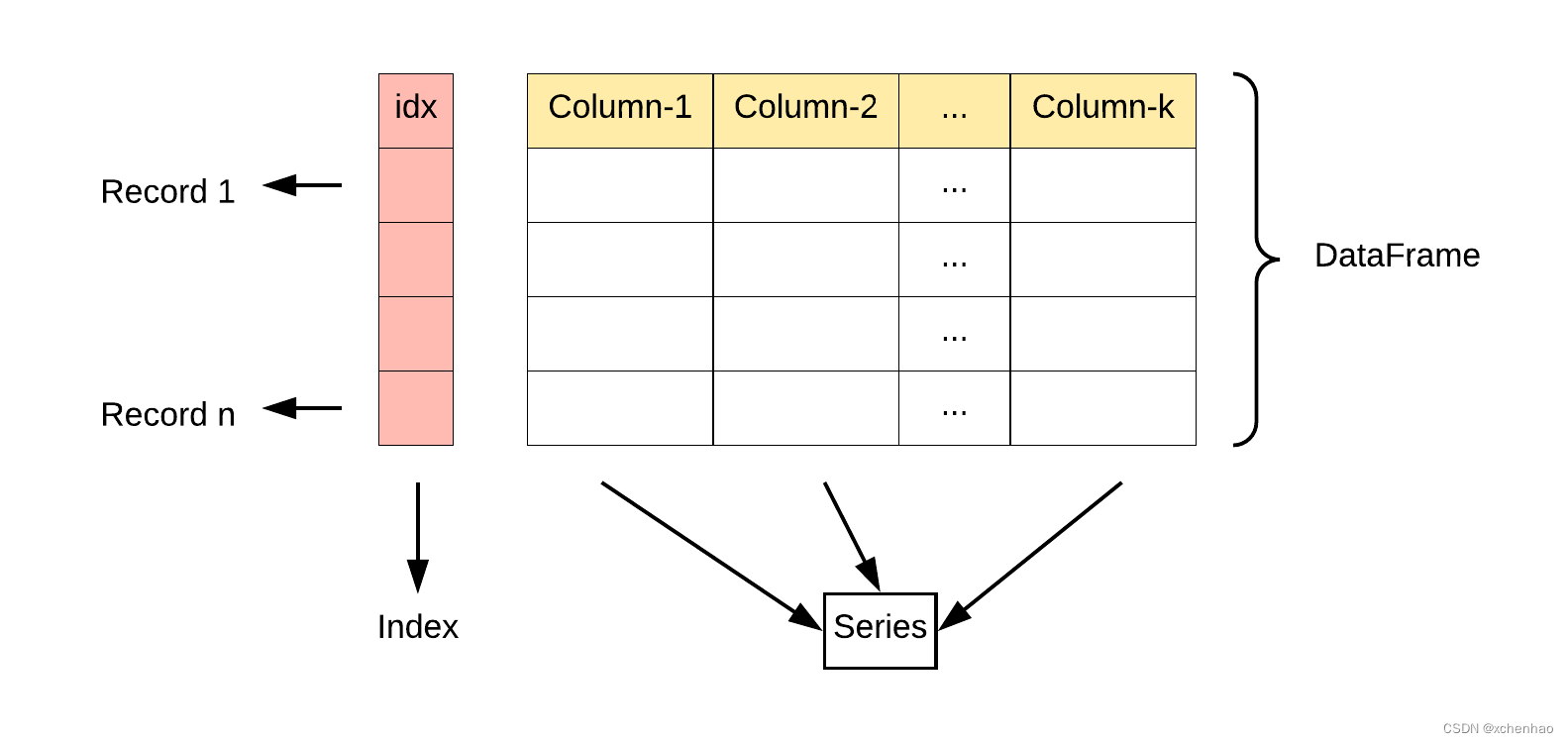
pandas.DataFrame([
['东汉', 300],
['魏国', 800],
['蜀国', 400],
['吴国', 600],
['西晋', 1000]
], columns=['国家', '国力'])
安装
如果你使用的是数据科学的 Python 发行版:Anaconda,可以使用 conda 安装
conda install pandas
如果是普通的 Python 环境,可以使用 pip 安装
pip install pandas
实战
我们先看看数据长啥样,数据存在 sanguo.csv 文档中
$ head sanguo.csv

(1)导入模块
import pandas as pd
(2)读取 csv 数据
# 当前目录下的 sanguo.csv 文件,na_values 指定哪些值为空
df = pd.read_csv('./sanguo.csv', na_values=['na', '-', 'N/A', '?'])
1)查看数据
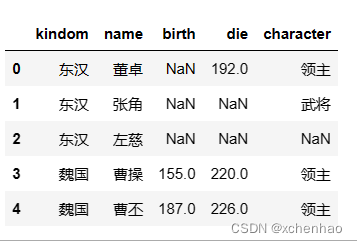
# 查看前 5 条 df.head(5) # NaN 为空值
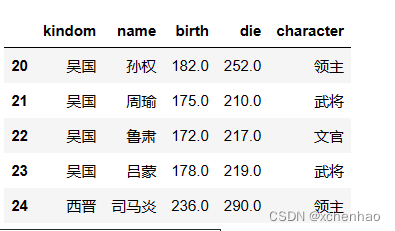
# 查看后 5 条 df.tail(5)
2)查看数据概况
df.dtypes # 查看数据类型
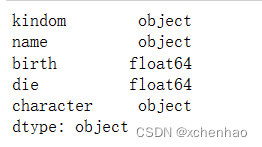
df.info() # 有 25 行,5 列 # 各列的名称(kindom、name、birth、die、character)、非空数目、数据类型
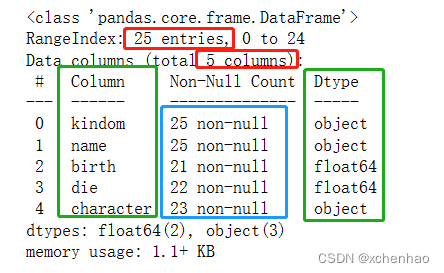
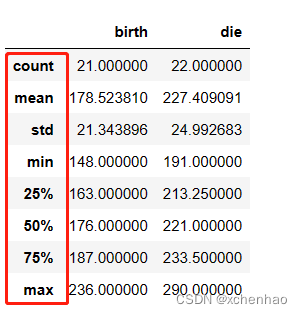
df.describe() # 查看数值型列统计值:总数、平均值、标准差、最小值、25%/50%/75% 分位数、最大值
3)数据操作
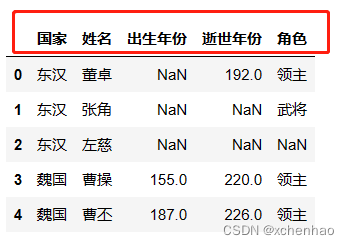
设置列名
df.columns = ['国家', '姓名', '出生年份', '逝世年份', '角色'] df.head()
添加新列
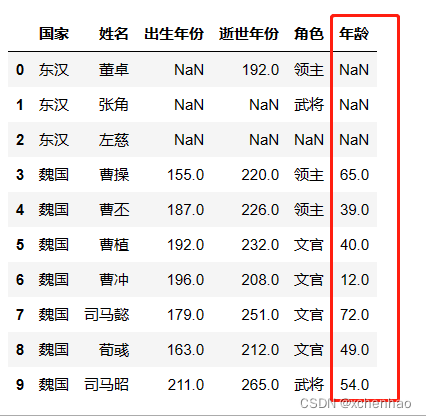
# 计算年龄 df['年龄'] = df['逝世年份'] - df['出生年份'] df.head(10)
计算列平均值、中位数、众数、最/小值
平均值:df['年龄'].mean()
中位数:df['年龄'].median()
众数:df['年龄'].mode()
最大值:df['年龄'].max()
最小值:df['年龄'].min()
列筛选
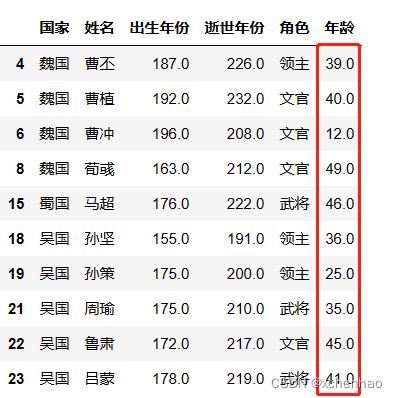
# 筛选年轮小于 50 的数据 df[df['年龄'] < 50]
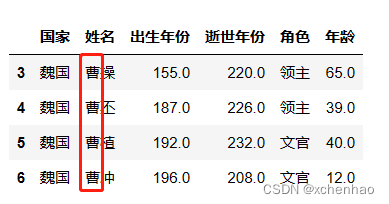
# 筛选曹姓的数据
df[df['姓名'].str.startswith('曹')]
分组
df.groupby('国家')['姓名'].count()
# 类似于 SQL: SELECT 国家, COUNT(姓名) FROM x GROUP BY 国家

apply 函数
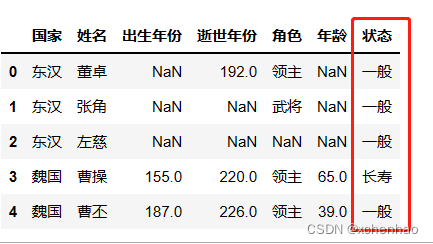
df['状态'] = df['年龄'].apply(lambda x: '长寿' if isinstance(x, (int, float)) and x > 50 else '一般') df.head()
取数据:loc、iloc
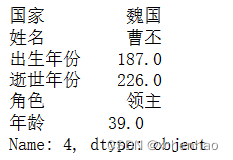
df.loc[4]
取第 5 行数据(索引从 0 开始)
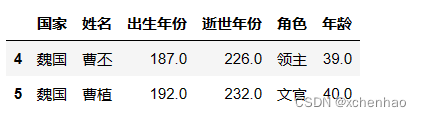
df.loc[4:5]
取第 5~6 行数据
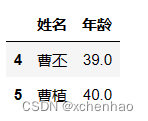
df.loc[4, '姓名']或 df.iloc[4, 1]取第 5 行姓名列或第 5 行第 2 列

df.loc[4, ['姓名', '年龄']]或 df.iloc[4, [1, 5]]取第 5 行姓名、年龄列或第 5 行第 2 列、第 6 列

df.loc[4:5, ['姓名', '年龄']]或 df.iloc[[4, 5], [1, 5]]或 df.iloc[4:6, [1, 5]]取第 5~6 行姓名、年龄列或取第 5~6 行第 2 列、第 6 列
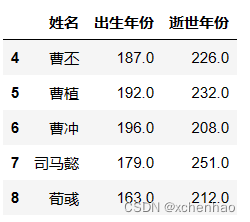
df.iloc[4:9, 1:4]取 5~10 列第 2~5 列
追加、合并数据
concat
# 创建列 newpeople = pd.Series(['东汉', '马腾', '?', 212, '?'], index=['国家', '姓名', '出生年份', '逝世年份', '年龄']) # 将 Series 转为 DataFrame,并对 DataFrame 转置(列转行) newpeople = newpeople.to_frame().T # 追加行(axis=0),重置索引(ignore_index=True) df2 = pd.concat([df, newpeople], axis=0, ignore_index=True) df2.tail()
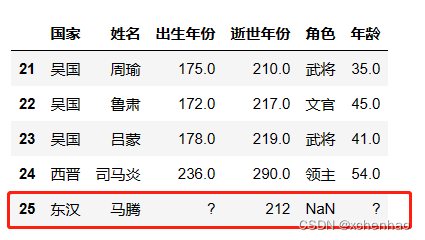
merge
# 创建表格
kindom_power = pd.DataFrame([
['东汉', 300],
['魏国', 800],
['蜀国', 400],
['吴国', 600],
['西晋', 1000]
], columns=['国家', '国力'])
# 按国家列进行两个表格(左 df,右 kindom_power)合并
df3 = pd.merge(left=df, right=kindom_power, on='国家')
df3.head(10)
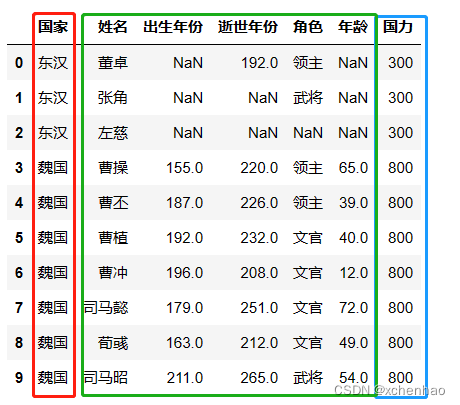
4)导出数据
# 写入 sanguo_result.csv 中,不输出索引值
df.to_csv('sanguo_result.csv', index=False)
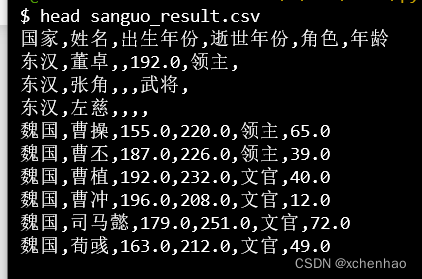
到此这篇关于pandas实战:分析三国志人物示例实现的文章就介绍到这了,更多相关pandas实战内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Pandas如何将表格的前几行生成html实战案例
目录 一.Pandas如何将表格的前几行生成html 1.1主要知识点 1.2创建 python 文件 1.3运行结果 二.Pandas如何计算一列数字的中位数 2.1主要知识点 2.2创建 python 文件 2.3运行结果 三.Pandas如何获取某个数据列最大和最小的5个数 3.1主要知识点 3.2创建 python 文件 3.3运行结果 四.Pandas如何查看客户是否流失字段的数据映射 4.1主要知识点 4.2创建 python 文件 4.3运行结果 一.Pandas如何将表格的前几行
-

Python实战之利用Geopandas算出每个省面积
目录 1.准备 2.基本使用 3.绘制并算出每个省的面积 GeoPandas是一个基于pandas,针对地理数据做了特别支持的第三方模块. 它继承pandas.Series和pandas.Dataframe,实现了GeoSeries和GeoDataFrame类,使得其操纵和分析平面几何对象非常方便. 1.准备 开始之前,你要确保Python和pip已经成功安装在电脑上. 请选择以下任一种方式输入命令安装依赖: 1.Windows 环境 打开 Cmd (开始-运行-CMD). 2.MacOS 环境
-
Pandas如何对Categorical类型字段数据统计实战案例
目录 一.Pandas如何对Categorical类型字段数据统计 1.1主要知识点 1.2创建 python 文件 1.3运行结果 二.Pandas如何从股票数据找出收盘价最低行 2.1主要知识点 2.2创建 python 文件 2.3运行结果 三.Pandas如何给股票数据新增年份和月份 3.1主要知识点 3.2创建 python 文件 3.3运行结果 四.Pandas如何获取表格的信息和基本数据统计 4.1主要知识点 4.2创建 python 文件 4.3运行结果 五.Pandas如何使用
-
pandas去除重复值的实战
目录 加载数据 sample抽样函数 指定需要更新的值 append直接添加 append函数用法 根据某一列key值进行去重(key唯一) 加载数据 首先,我们需要加载到所需要的数据,这里我们所需要的数据是同过sample函数采样过来的. import pandas as pd #这里说明一下,clean_beer.csv数据有两千多行数据 #所以从其中采样一部分,来进行演示,当然可以简单实用data.head()也可以做练习 data = pd.read_csv('clean_beer.cs
-
机器学习实战之knn算法pandas
开始学习机器学习实战这本书,打算看完了再回头看 周志华的 机器学习.机器学习实战的代码都是用numpy写的,有些麻烦,所以考虑用pandas来实现代码,也能回顾之前学的 用python进行数据分析.感觉目前章节的测试方法太渣,留着以后学了更多再回头写. # coding: gbk import pandas as pd import numpy as np def getdata(path): data = pd.read_csv(path, header=None, sep='\t') cha
-
Python实战基础之Pandas统计某个数据列的空值个数
目录 一.实战场景 二.主要知识点 三.菜鸟实战 1.创建 python 文件 2.运行结果 补充:Pandas检查是否有空值.处理空值 总结 一.实战场景 实战场景:Pandas 如何统计某个数据列的空值个数 二.主要知识点 文件读写 基础语法 Pandas numpy 三.菜鸟实战 马上安排! 1.创建 python 文件 """ 对如下DF,设置两个单元格的值 ·使用iloc 设置(3,B)的值是nan ·使用loc设置(8,D)的值是nan ""&
-
五个Pandas 实战案例带你分析操作数据
目录 构建数据 分析维度1:时间 2019-2021年每月销量走势 2019-2021销售额走势 年度销量.销售额和平均销售额 分析维度2:商品 水果年度销量占比 各水果年度销售金额对比 商品月度销量变化 分析维度3:地区 不同地区的销量 分析维度4:用户 用户订单量.金额对比 用户水果喜好 用户分层—RFM模型 用户复购周期分析 大家好,之前分享过很多关于 Pandas 的文章,今天我给大家分享5个小而美的 Pandas 实战案例. 内容主要分为: 如何自行模拟数据 多种数据处理方式 数据统计
-
pandas实战:分析三国志人物示例实现
目录 简介 背景 特点: 安装 简介 背景 Pandas 是 Python 的一个工具库,用于数据分析. 由 AQR Capital Management 于 2008 年 4 月开发,2009 年开源,最初被作为金融数据分析工具而开发出来. Pandas 名称来源于 panel data(面板数据)和 Python data analysis(Python 数据分析). 适用于金融.统计等数据分析领域. 特点: 两大数据结构 Series 和 DataFrame (1)Series:一维数据(
-
python数据可视化使用pyfinance分析证券收益示例详解
目录 pyfinance简介 pyfinance包含六个模块 returns模块应用实例 收益率计算 CAPM模型相关指标 风险指标 基准比较指标 风险调整收益指标 综合业绩评价指标分析实例 结语 pyfinance简介 在查找如何使用Python实现滚动回归时,发现一个很有用的量化金融包--pyfinance.顾名思义,pyfinance是为投资管理和证券收益分析而构建的Python分析包,主要是对面向定量金融的现有包进行补充,如pyfolio和pandas等. pyfinance包含六个模块
-
pandas实现数据合并的示例代码
目录 一. concat--数据合并 1.1 概述 1.2 指定合并的轴方向--axis 1.3 指定合并轴另外一个轴标签是否合并--join 1.4 指定合并轴原标签是否需要变化--ignore_index 1.5 指定合并轴方向新的index,便于区分数据--keys 1.6 指定合并轴方向新的index 的含义名称,一般和keys一起使用,让合并后的数据更直观--names 1.7 指定合并时是否允许合并轴上有重复标签--verify_integrity 二. merge--数据连接 2.
-
pandas实现数据可视化的示例代码
目录 一.概述 1.1 plot函数参数 1.2 本文用到的数据源说明 二.折线图--kind='line' 三.柱状图--kind='bar' 3.1 各组数据(列)分开展示 3.2 各组(列)数据合并展示--stacked 3.3 横向柱状图--kind='barh' 四.直方图--kind='hist' 4.1 概述 4.2 自定义直方图横向区间数量 4.3 多子图展示多序列数据 4.4 一维数据密度图--kind='kde' 4.5 累积直方图--cumulative = True 五
-
pandas数据拼接的实现示例
一 前言 pandas数据拼接有可能会用到,比如出现重复数据,需要合并两份数据的交集,并集就是个不错的选择,知识追寻者本着技多不压身的态度蛮学习了一下下: 二 数据拼接 在进行学习数据转换之前,先学习一些数拼接相关的知识 2.1 join()联结 有关merge操作知识追寻者这边不提及,有空可能后面会专门出一篇相关文章,因为其学习方式根SQL的表联结类似,不是几行能说清楚的知识点: join操作能将 2 个DataFrame 合并为一块,前提是DataFrame 之间的列没有重复: # -*-
-
Pandas DataFrame求差集的示例代码
在Pandas中 求差集没有专门的函数.处理办法就是将两个DataFrame追加合并,然后去重. divident.append(hasThisYearDivident) noHasThisYearDivident = divident.drop_duplicates(subset='ts_code', keep=False, inplace=True, ignore_index=True) 具体函数用法: https://pandas.pydata.org/pandas-docs/stable
-
Python实现层次分析法及自调节层次分析法的示例
假设我们遇到如下问题: ①对于M个方案,每个方案有N个属性,在已知各个方案每个属性值&&任意两个属性的重要程度的前提下,如何选择最优的方案? ②对于一个层级结构,在已知各底层指标相互之间的重要程度下,如何确定各底层指标对最高级指标的权值? - - 此时,便可用层次分析法将我们的主观想法--"谁比谁重要"转换为客观度量--"权值" 层次分析法 层次分析法的基本思想是将复杂问题分为若干层次和若干因素,在同一层次的各要素之间简单地进行比较判断和计算,并评估
-
pandas实现按照Series分组示例
目录 1 按照一个Series进行分组 2 按照多个Series进行分组 3 分组和聚合采用不同的列或Series进行 本文用到的表格内容如下: 先来看一下数据情形 import pandas as pd life_df = pd.read_excel(r'C:\Users\admin\Desktop\生活用品表.xlsx') print(life_df) result: 分类 编号 名称 0 水果 0 苹果 1 水果 1 橙子 2 生
-
pandas对齐运算的实现示例
目录 1.算术运算和数据对齐 1.1 Series 1.2 DataFrame 2.使用填充值的算术方法 2.1 Series 2.2 DataFrame 3.DataFrame和Series混合运算 3.1 按行广播 3.2 按列广播 1.算术运算和数据对齐 import numpy as np import pandas as pd 1.1 Series a1 = pd.Series(np.arange(4),index=['a','b','c','d']) a2 = pd.Series(n