使用Pytorch如何完成多分类问题
目录
- Pytorch如何完成多分类
- 为什么要用transform
- 归一化
- 模型
- 总结
Pytorch如何完成多分类
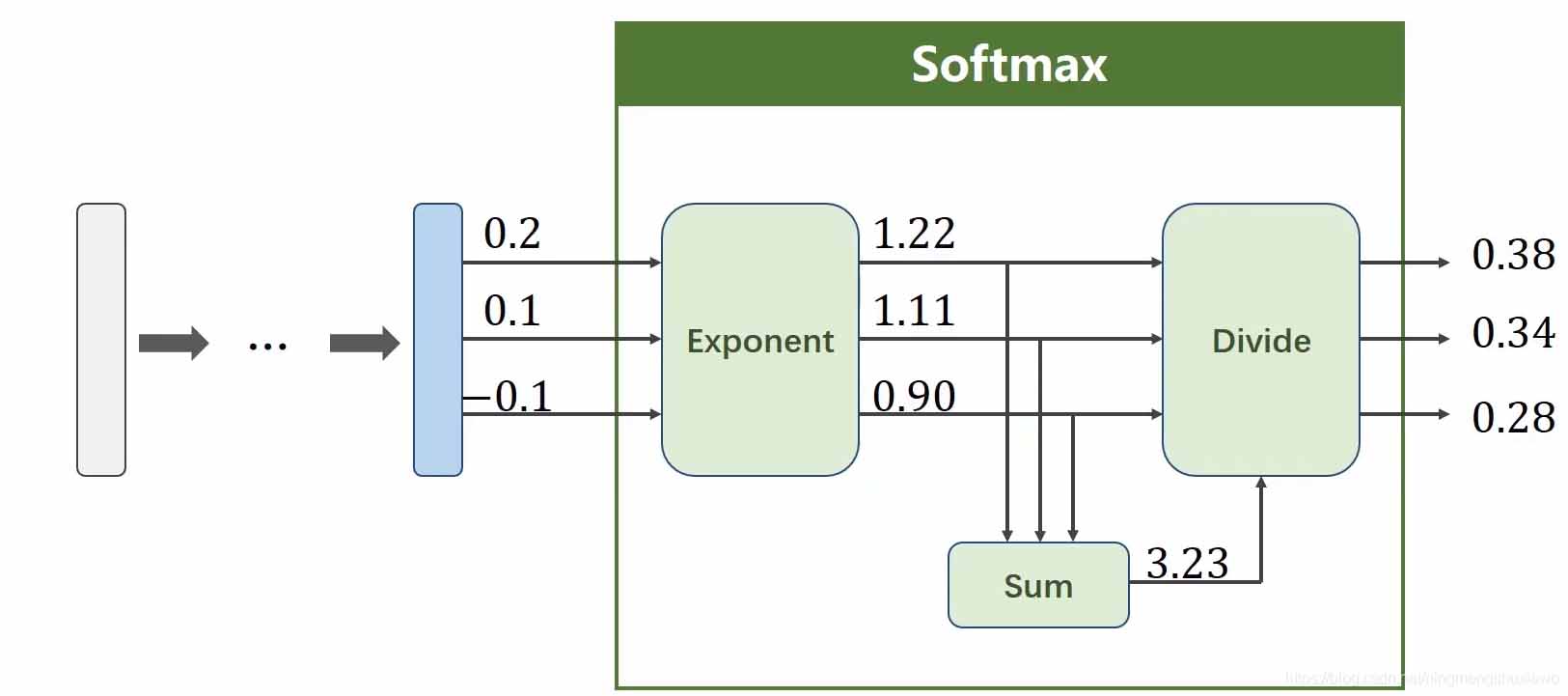
多分类问题在最后的输出层采用的Softmax Layer,其具有两个特点:1.每个输出的值都是在(0,1);2.所有值加起来和为1.
假设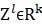 是最后线性层的输出,则对应的Softmax function为:
是最后线性层的输出,则对应的Softmax function为:
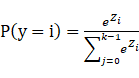
输出经过sigmoid运算即可是西安输出的分类概率都大于0且总和为1。
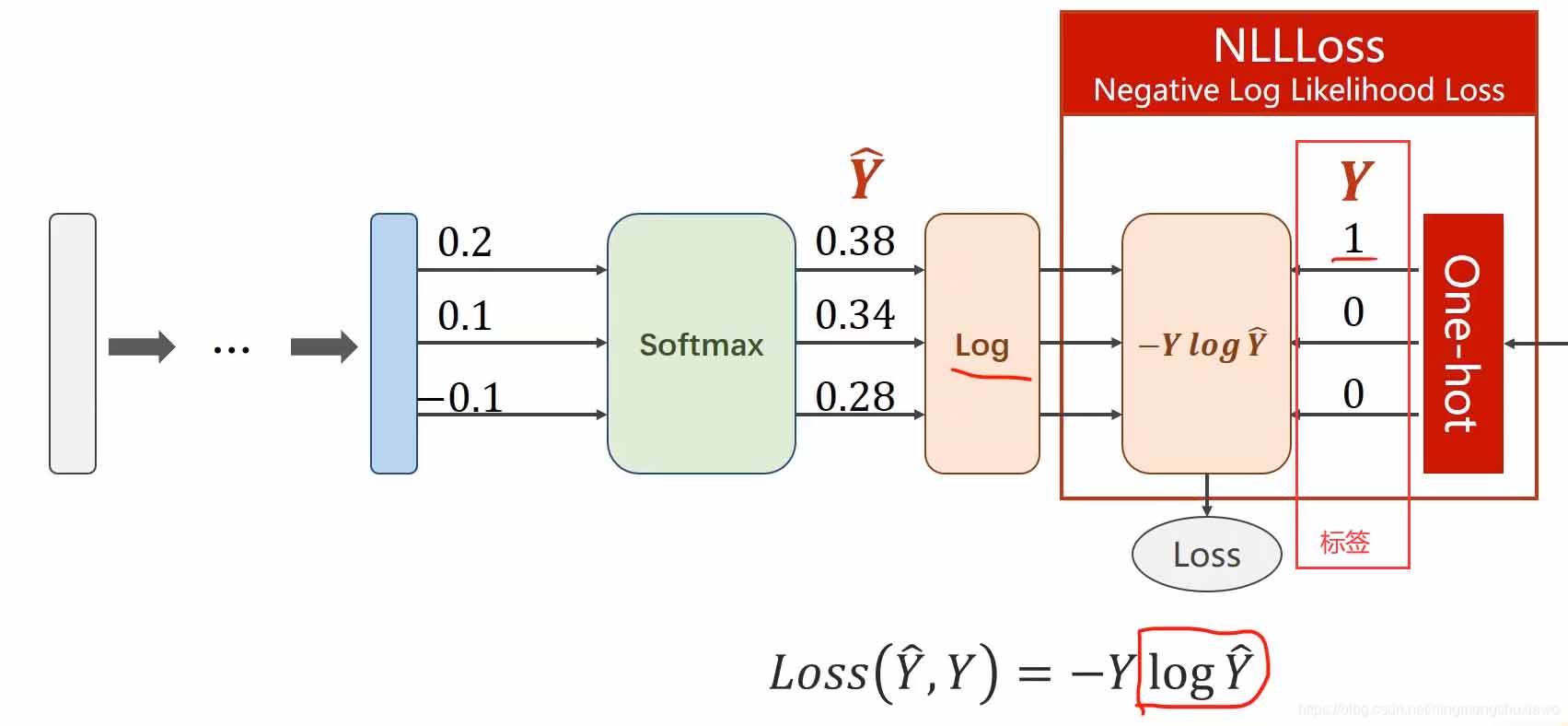
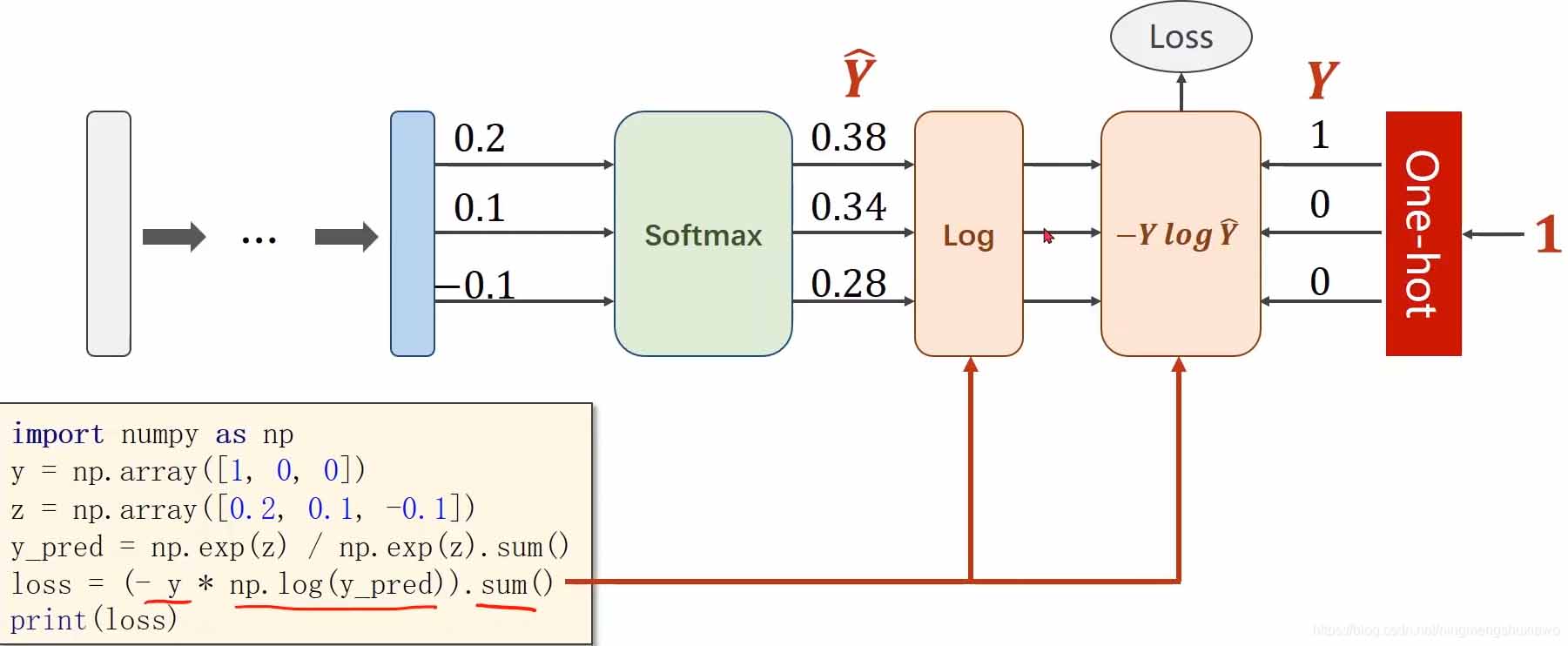
上图的交叉熵损失就包含了softmax计算和右边的标签输入计算(即框起来的部分)
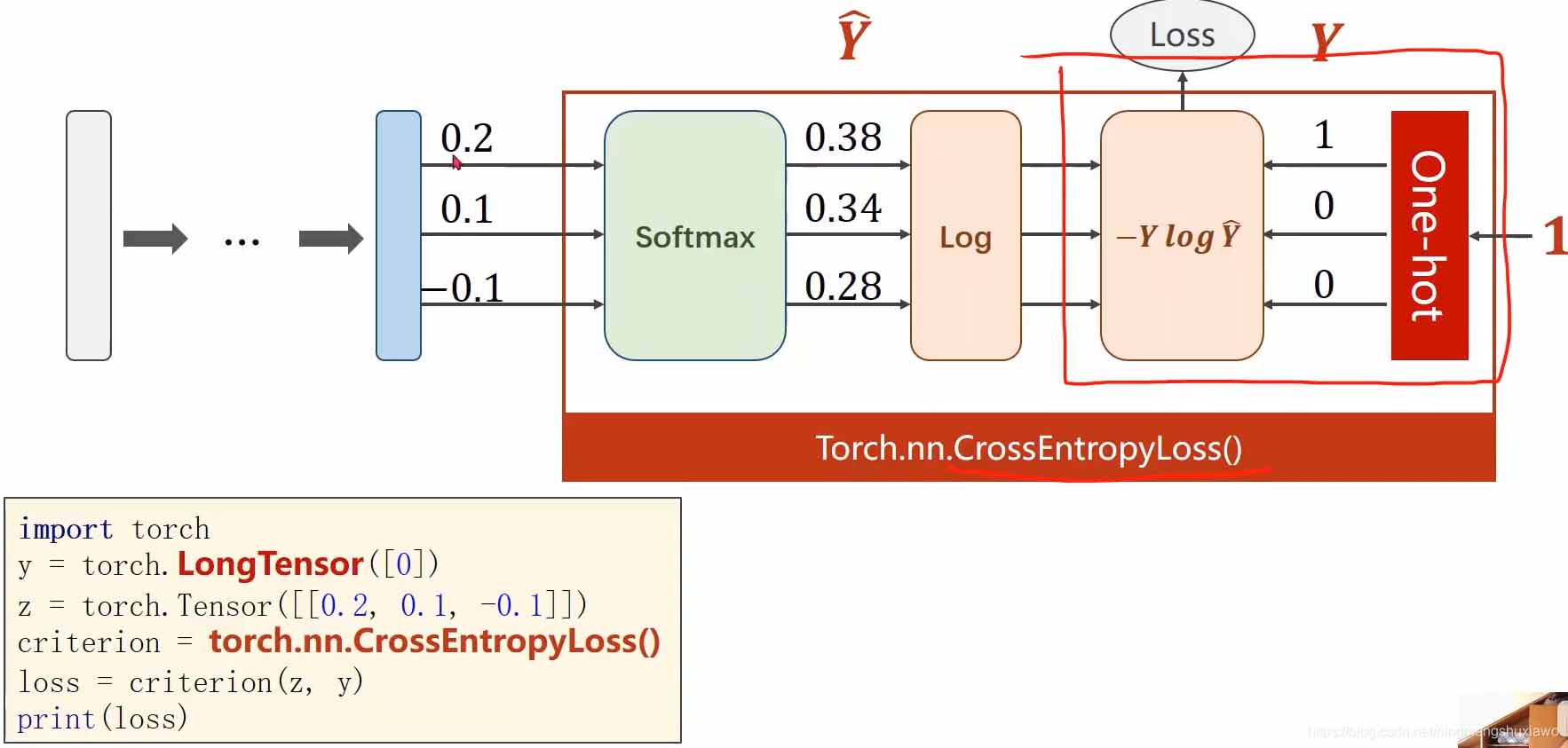
所以在使用交叉熵损失的时候,神经网络的最后一层是不要做激活的,因为把它做成分布的激活是包含在交叉熵损失里面的,最后一层不要做非线性变换,直接交给交叉熵损失。

如上图,做交叉熵损失时要求y是一个长整型的张量,构造时直接用
criterion = torch.nn.CrossEntropyLoss()

3个类别,分别是2,0,1
Y_pred1 ,Y_pred2还是线性输出,没经过softmax,还不是概率分布,比如Y_pred1,0.9最大,表示对应为第3个的概率最大,和2吻合,1.1最大,表示对应为第1个的概率最大,和0吻合,2.1最大,表示对应为第2个的概率最大,和1吻合,那么Y_pred1 的损失会比较小
对于Y_pred2,0.8最大,表示对应为第1个的概率最大,和0不吻合,0.5最大,表示对应为第3个的概率最大,和2不吻合,0.5最大,表示对应为第3个的概率最大,和2不吻合,那么Y_pred2 的损失会比较大
Exercise 9-1: CrossEntropyLoss vs NLLLoss
What are the differences?
• Reading the document:
• https://pytorch.org/docs/stable/nn.html#crossentropyloss
• https://pytorch.org/docs/stable/nn.html#nllloss
• Try to know why:
• CrossEntropyLoss <==> LogSoftmax + NLLLoss

为什么要用transform
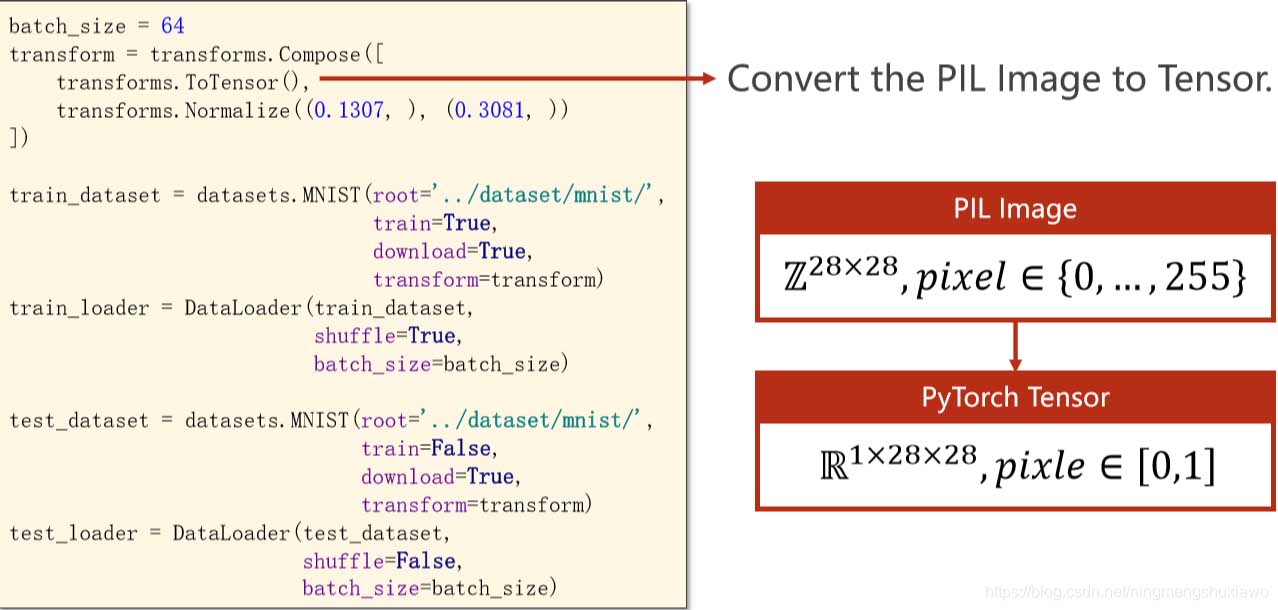
transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307, ), (0.3081, )) ])
PyTorch读图像用的是python的imageLibrary,就是PIL,现在用的都是pillow,pillow读进来的图像用神经网络处理的时候,神经网络有一个特点就是希望输入的数值比较小,最好是在-1到+1之间,最好是输入遵从正态分布,这样的输入对神经网络训练是最有帮助的
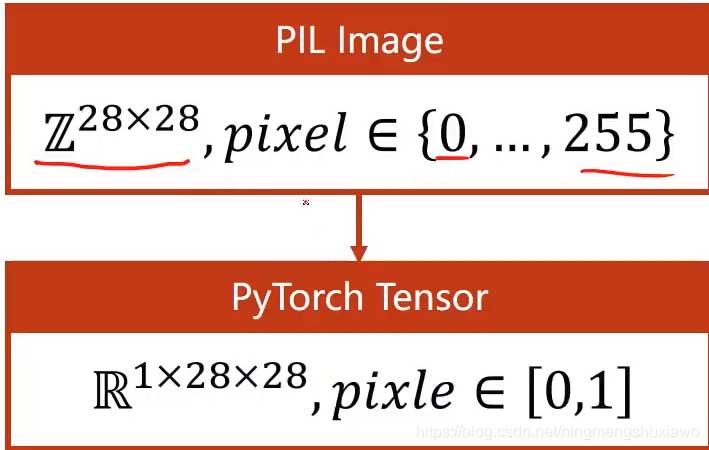
原始图像是28*28的像素值在0到255之间,我们把它转变成图像张量,像素值是0到1
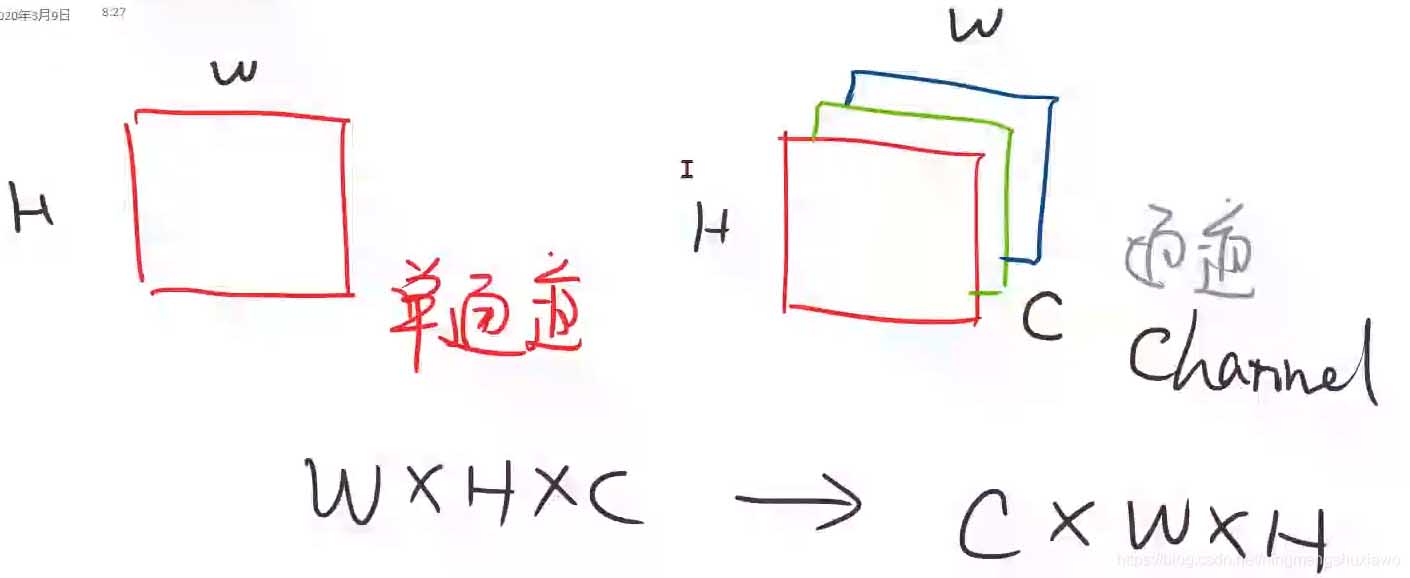
在视觉里面,灰度图就是一个矩阵,但实际上并不是一个矩阵,我们把它叫做单通道图像,彩色图像是3通道,通道有宽度和高度,一般我们读进来的图像张量是WHC(宽高通道)
在PyTorch里面我们需要转化成CWH,把通道放在前面是为了在PyTorch里面进行更高效的图像处理,卷积运算。所以拿到图像之后,我们就把它先转化成pytorch里面的一个Tensor,把0到255的值变成0到1的浮点数,然后把维度由2828变成128*28的张量,由单通道变成多通道,
这个过程可以用transforms的ToTensor这个函数实现

归一化
transforms.Normalize((0.1307, ), (0.3081, ))

这里的0.1307,0.3081是对Mnist数据集所有的像素求均值方差得到的
也就是说,将来拿到了图像,先变成张量,然后Normalize,切换到0,1分布,然后供神经网络训练
如上图,定义好transform变换之后,直接把它放到数据集里面,为什么要放在数据集里面呢,是为了在读取第i个数据的时候,直接用transform处理

模型
输入是一组图像,激活层改用Relu
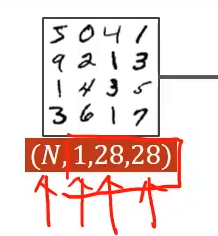
全连接神经网络要求输入是一个矩阵
所以需要把输入的张量变成一阶的,这里的N表示有N个图片
view函数可以改变张量的形状,-1表示将来自动去算它的值是多少,比如输入是n128*28
将来会自动把n算出来,输入了张量就知道形状,就知道有多少个数值
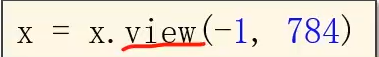
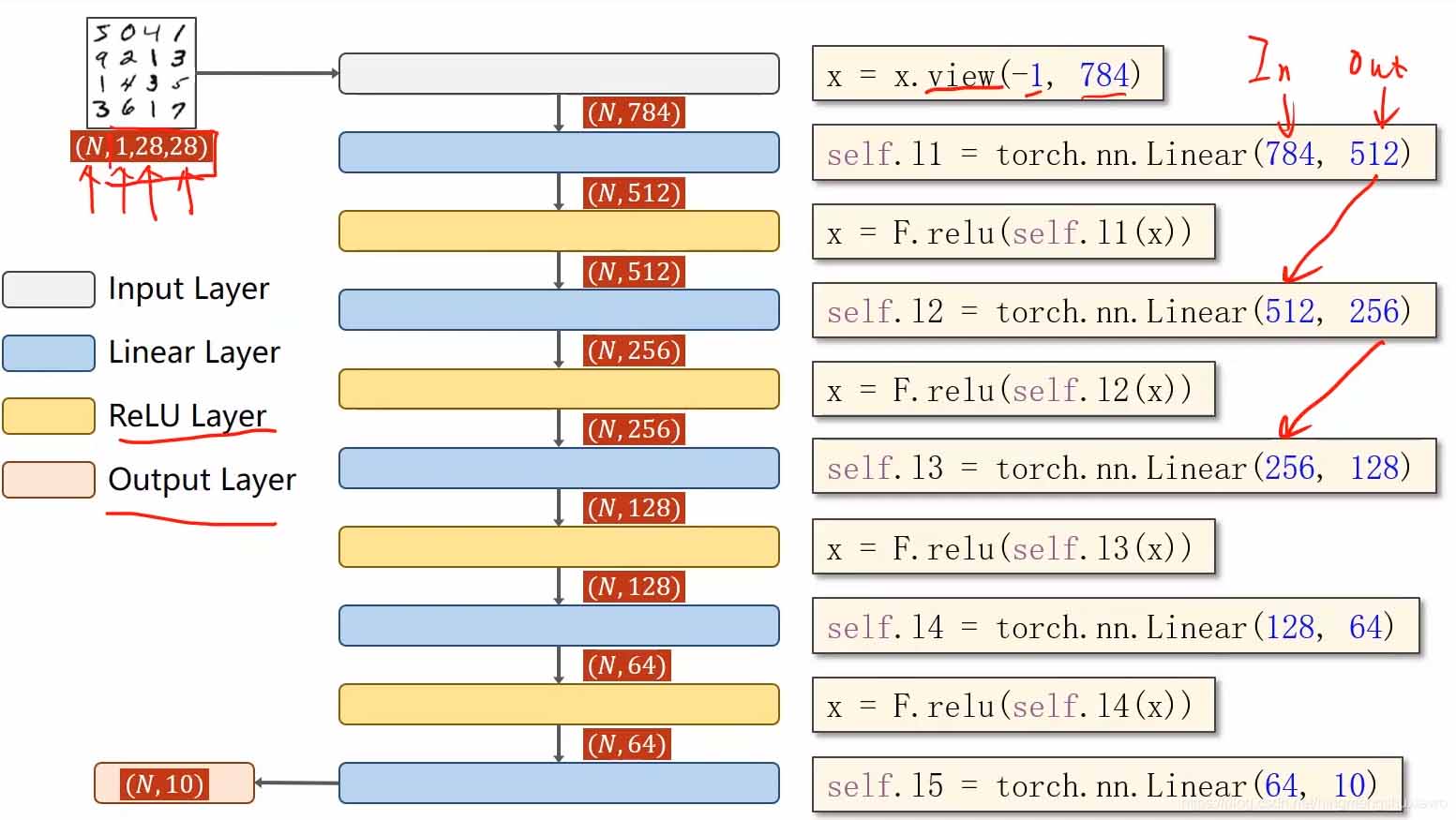
最后输出是(N,10)因为是有0-9这10个标签嘛,10表示该图像属于某一个标签的概率,现在还是线性值,我们再用softmax把它变成概率
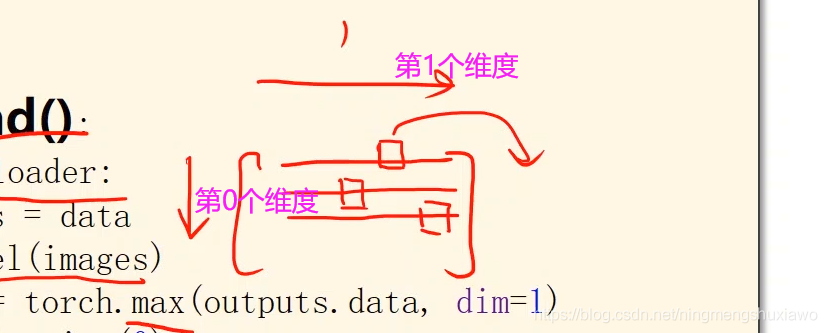
#沿着第一个维度找最大值的下标,返回值有两个,因为是10列嘛,返回值一个是每一行的最大值,另一个是最大值的下标(每一个样本就是一行,每一行有10个量)(行是第0个维度,列是第1个维度)
MNIST数据集训练代码
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
# prepare dataset
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(), #先将图像变换成一个张量tensor。
transforms.Normalize((0.1307,), (0.3081,))
#其中的0.1307是MNIST数据集的均值,0.3081是MNIST数据集的标准差。
]) # 归一化,均值和方差
train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True,
download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False,
download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# design model using class
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
# 28 * 28 = 784
# 784 = 28 * 28,即将N *1*28*28转化成 N *1*784
x = x.view(-1, 784) # -1其实就是自动获取mini_batch
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x) # 最后一层不做激活,不进行非线性变换
model = Net()
#CrossEntropyLoss <==> LogSoftmax + NLLLoss。
#也就是说使用CrossEntropyLoss最后一层(线性层)是不需要做其他变化的;
#使用NLLLoss之前,需要对最后一层(线性层)先进行SoftMax处理,再进行log操作。
# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
#momentum 是带有优化的一个训练过程参数
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# training cycle forward, backward, update
def train(epoch):
running_loss = 0.0
#enumerate()函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,
#同时列出数据和数据下标,一般用在 for 循环当中。
#enumerate(sequence, [start=0])
for batch_idx, data in enumerate(train_loader, 0):
# 获得一个批次的数据和标签
inputs, target = data
optimizer.zero_grad()
#forward + backward + update
# 获得模型预测结果(64, 10)
outputs = model(inputs)
# 交叉熵代价函数outputs(64,10),target(64)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():#不需要计算梯度。
for data in test_loader:
images, labels = data
outputs = model(images)
#orch.max的返回值有两个,第一个是每一行的最大值是多少,第二个是每一行最大值的下标(索引)是多少。
_, predicted = torch.max(outputs.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度
total += labels.size(0)
correct += (predicted == labels).sum().item() # 张量之间的比较运算
print('accuracy on test set: %d %% ' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
PyTorch: Softmax多分类实战操作
多分类一种比较常用的做法是在最后一层加softmax归一化,值最大的维度所对应的位置则作为该样本对应的类.本文采用PyTorch框架,选用经典图像数据集mnist学习一波多分类. MNIST数据集 MNIST 数据集(手写数字数据集)来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST). 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口
-
pytorch 多分类问题,计算百分比操作
二分类或分类问题,网络输出为二维矩阵:批次x几分类,最大的为当前分类,标签为one-hot型的二维矩阵:批次x几分类 计算百分比有numpy和pytorch两种实现方案实现,都是根据索引计算百分比,以下为具体二分类实现过程. pytorch out = torch.Tensor([[0,3], [2,3], [1,0], [3,4]]) cond = torch.Tensor([[1,0], [0,1], [1,0], [1,0]]) persent = torch.mean(torch.eq(
-
PyTorch手写数字数据集进行多分类
目录 一.实现过程 0.导包 1.准备数据 2.设计模型 3.构造损失函数和优化器 4.训练和测试 二.参考文献 一.实现过程 本文对经典手写数字数据集进行多分类,损失函数采用交叉熵,激活函数采用ReLU,优化器采用带有动量的mini-batchSGD算法. 所有代码如下: 0.导包 import torch from torchvision import transforms,datasets from torch.utils.data import DataLoader import tor
-
Pytorch入门之mnist分类实例
本文实例为大家分享了Pytorch入门之mnist分类的具体代码,供大家参考,具体内容如下 #!/usr/bin/env python # -*- coding: utf-8 -*- __author__ = 'denny' __time__ = '2017-9-9 9:03' import torch import torchvision from torch.autograd import Variable import torch.utils.data.dataloader as Data
-
Pytorch实现神经网络的分类方式
本文用于利用Pytorch实现神经网络的分类!!! 1.训练神经网络分类模型 import torch from torch.autograd import Variable import matplotlib.pyplot as plt import torch.nn.functional as F import torch.utils.data as Data torch.manual_seed(1)#设置随机种子,使得每次生成的随机数是确定的 BATCH_SIZE = 5#设置batch
-

Python机器学习之基于Pytorch实现猫狗分类
一.环境配置 安装Anaconda 具体安装过程,请点击本文 配置Pytorch pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torch pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torchvision 二.数据集的准备 1.数据集的下载 kaggle网站的数据集下载地址: https://www.kaggle.com/lizhensheng/-2000 2.
-
Pytorch实现逻辑回归分类
本文实例为大家分享了Pytorch实现逻辑回归分类的具体代码,供大家参考,具体内容如下 1.代码实现 步骤: 1.获得数据2.建立逻辑回归模型3.定义损失函数4.计算损失函数5.求解梯度6.梯度更新7.预测测试集 import torch import torch.nn as nn import numpy as np import matplotlib.pyplot as plt from torch.autograd import Variable import torchvision.da
-
使用Pytorch如何完成多分类问题
目录 Pytorch如何完成多分类 为什么要用transform 归一化 模型 总结 Pytorch如何完成多分类 多分类问题在最后的输出层采用的Softmax Layer,其具有两个特点:1.每个输出的值都是在(0,1):2.所有值加起来和为1. 假设是最后线性层的输出,则对应的Softmax function为: 输出经过sigmoid运算即可是西安输出的分类概率都大于0且总和为1. 上图的交叉熵损失就包含了softmax计算和右边的标签输入计算(即框起来的部分) 所以在使用交叉熵损失的时候
-
pytorch + visdom 处理简单分类问题的示例
环境 系统 : win 10 显卡:gtx965m cpu :i7-6700HQ python 3.61 pytorch 0.3 包引用 import torch from torch.autograd import Variable import torch.nn.functional as F import numpy as np import visdom import time from torch import nn,optim 数据准备 use_gpu = True ones = n
-
基于Pytorch实现的声音分类实例代码
目录 前言 环境准备 安装libsora 安装PyAudio 安装pydub 训练分类模型 生成数据列表 训练 预测 其他 总结 前言 本章我们来介绍如何使用Pytorch训练一个区分不同音频的分类模型,例如你有这样一个需求,需要根据不同的鸟叫声识别是什么种类的鸟,这时你就可以使用这个方法来实现你的需求了. 源码地址:https://github.com/yeyupiaoling/AudioClassification-Pytorch 环境准备 主要介绍libsora,PyAudio,pydub
-
pytorch 实现二分类交叉熵逆样本频率权重
通常,由于类别不均衡,需要使用weighted cross entropy loss平衡. def inverse_freq(label): """ 输入label [N,1,H,W],1是channel数目 """ den = label.sum() # 0 _,_,h,w= label.shape num = h*w alpha = den/num # 0 return torch.tensor([alpha, 1-alpha]).cuda(
-
详解PyTorch批训练及优化器比较
一.PyTorch批训练 1. 概述 PyTorch提供了一种将数据包装起来进行批训练的工具--DataLoader.使用的时候,只需要将我们的数据首先转换为torch的tensor形式,再转换成torch可以识别的Dataset格式,然后将Dataset放入DataLoader中就可以啦. import torch import torch.utils.data as Data torch.manual_seed(1) # 设定随机数种子 BATCH_SIZE = 5 x = torch.li
-
Pytorch BCELoss和BCEWithLogitsLoss的使用
BCELoss 在图片多标签分类时,如果3张图片分3类,会输出一个3*3的矩阵. 先用Sigmoid给这些值都搞到0~1之间: 假设Target是: 下面我们用BCELoss来验证一下Loss是不是0.7194! emmm应该是我上面每次都保留4位小数,算到最后误差越来越大差了0.0001.不过也很厉害啦哈哈哈哈哈! BCEWithLogitsLoss BCEWithLogitsLoss就是把Sigmoid-BCELoss合成一步.我们直接用刚刚的input验证一下是不是0.7193: 嘻嘻,我