ThreadLocal数据存储结构原理解析
目录
- 一:简述
- 二:TheadLocal的原理分析
- 1.ThreadLocal的存储结构
- 2.源码分析
- set()方法
- 三:源码分析
- createMap()
- 源码:
- 流程图:
- expungeStaleEntry()
- cleanSomeSlots()
- rehash()
- resize()
- get()方法
- getEntry()
- getEntryAfterMiss()
- remove()
- 四:总结
一:简述
我们很多时候为了实现数据在线程级别下的隔离,会使用到ThreadLocal,那么TheadLocal是如何实现数据隔离的呢?今天就和大家一起分析一下ThreadLocal的实现原理。
二:TheadLocal的原理分析
1.ThreadLocal的存储结构
每个Thread对象中都有一个threadLocals成员变量,threadLocals是一个类型为ThreadLocalMap的map,而ThreadLocal正是基于这个map来实现线程级别的数据隔离的。
我们先看ThreadLocalMap的成员变量
//默认的初始化容量大小
private static final int INITIAL_CAPACITY = 16;
//Entry数组 真正存储的数据结构
private Entry[] table;
//记录当前元素的数量
private int size = 0;
//扩容的阈值
private int threshold;
Entry数组是真正存储数据的地方,可以看出Entry是一个key-value的存储结构,以当前ThreadLocal对象的引用作为key,存储的值为value。Entry继承了WeakReference,并且在构造函数的时候,调用super(k)(也就是WeakReference的构造函数)来对key进行初始化,所以Entry的key是一个弱引用。
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
根据上面的分析,我们可以知道ThreadLocal的存储结构大概是这样的:
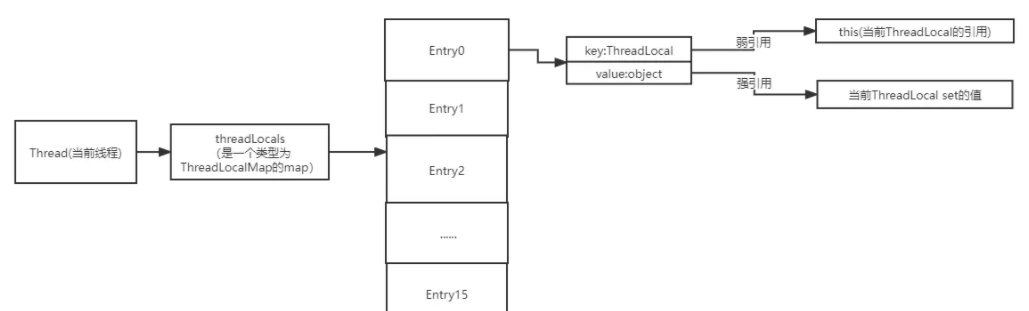
2.源码分析
接下来我们从ThreadLocal的set(),get(),remove()方法为入口对ThreadLocal的源码进行分析。
set()方法
首先判断当前线程的threadLocals是否初始化,如果没有初始化,那么调用createMap()方法进行初始化并设置值,否则调用ThreadLocalMap的set()方法设置值。
流程图:

三:源码分析
public void set(T value) {
//利用当前线程获取它的threadLocals(threadLocals是一个ThreadLocalMap)
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
//如果已经初始化 那么就调用ThreadLocalMap的set()方法
if (map != null)
map.set(this, value);
else
// 没有初始化 先进行初始化
createMap(t, value);
}
ThreadLocalMap getMap(Thread t) {
//返回当前线程的threadLocals
return t.threadLocals;
}
createMap()
createMap()会调用ThreadLocalMap的构造函数对当前线程的threadLocals初始化,并且初始化Entry数组,然后利用hash算法计算出数组下标,将需要set的值存储在Entry数组。
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
// 初始化Entry数组
table = new Entry[INITIAL_CAPACITY];
//计算数组下标
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
//设置默认的扩容阈值 和默认容量一样
setThreshold(INITIAL_CAPACITY);
}
如果threadLocals已经初始化,直接调用ThreadLocalMap的set(),接下来看ThreadLocalMap的set()方法。
首先利用hash算法计算数组下标,如果计算出的位置没有值,直接将值设置进去,如果存在值(出现hash冲突),分为三种情况:
1.如果key相同,那么直接覆盖值
2.如果计算出的位置的Entry的key为null,那么说明是无效的数据(key为null,entry不为null),为了避免内存泄漏需要清除这种数据。所以调用replaceStaleEntry()方法将无效数据清除并且将需要设置的值设置到Entry数组中。
3.如果key不相同,而且计算出的位置的Entry的key不为null,那么进入到下一次for循环将计算出的下标+1,(如果到达下标最大值,则设置为0),利用新的位置重新进行判断,直到获取到一个合法的位置(线性寻址法解决hash冲突的问题)。
注:这里大家可以评论区讨论下为什么不和HashMap那样利用链表法解决hash冲突。我个人的看法是因为ThreadLocal的数据量不会向HashMap那么多,所以不需要利用链表和红黑树来解决hash冲突,链表法解决代码相对比较复杂而且扩容迁移数据的数据会比较麻烦。
源码:
private void set(ThreadLocal<?> key, Object value) {
// We don't use a fast path as with get() because it is at
// least as common to use set() to create new entries as
// it is to replace existing ones, in which case, a fast
// path would fail more often than not.
Entry[] tab = table;
int len = tab.length;
// 计算数组下标
int i = key.threadLocalHashCode & (len-1);
//如果出现hash冲突会进入for循环
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
//如果key相同 那么直接将值覆盖
if (k == key) {
e.value = value;
return;
}
//如果key为null 那么说明是无效的数据 需要进行清除
if (k == null) {
//调用replaceStaleEntry()方法进行清除数据 并设置值
replaceStaleEntry(key, value, i);
return;
}
}
//如果没有hash冲突 直接赋值到对应下标的位置
tab[i] = new Entry(key, value);
// 将当前元素个数+1
int sz = ++size;
//如果没有需要清除的元素,并且当前元素个数已经达到扩容的阈值,那么进行扩容
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
接下来看replaceStaleEntry(),看ThreadLocal是如何清除无效的数据的。
当前节点是无效的数据,那么周围也可能存在无效的数据,所以ThreadLocal在清除无效的数据时,会顺便清除周围的连续的无效数据,先利用for循环从当前节点向前遍历,调整slotToExpunge的值(slotToExpunge 用于保存开始清除无效数据的下标位置), 然后向后遍历,如果有entry的key和需要存放的数据的key相同,那么直接覆盖值,并且交换当前节点和新设置的entry的值。
流程图:

private void replaceStaleEntry(ThreadLocal<?> key, Object value,
int staleSlot) {
Entry[] tab = table;
int len = tab.length;
Entry e;
// slotToExpunge 用于保存开始清除无效数据的下标位置
int slotToExpunge = staleSlot;
//从当前位置向前遍历,直到找到一个有效数据的下标
for (int i = prevIndex(staleSlot, len);
(e = tab[i]) != null;
i = prevIndex(i, len))
//e.get()返回Entry的key,威null代表是无效数据
//(因为只有entry不为null才会进入for循环) 所以key为null,就是无效数据
//for循环将清除无效数据的下标往前挪
if (e.get() == null)
slotToExpunge = i;
//从当前位置往后遍历
for (int i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
//如果遍历的是否发现有和当前Entry相同的key的entry,那么交换两者的位置
if (k == key) {
e.value = value;
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
//如果slotToExpunge和staleSlot相等
//证明当前节点的前面没有和当前节点连续的无效数据
//所以从交换完的位置开始清除无效数据 调用cleanSomeSlots()方法和expungeStaleEntry()方法清除无效数据 清除完返回。
if (slotToExpunge == staleSlot)
slotToExpunge = i;
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
//如果key为null 而且当前entry之前没有与当前节点连续的无效数据
//刷新开始清除无效数据的下标
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
// If key not found, put new entry in stale slot
//如果没有找到连续的无效数据 把当前的节点的value重置为null 并且将新的值赋值到当前位置
//因为当前的entry是无效的数据
tab[staleSlot].value = null;
tab[staleSlot] = new Entry(key, value);
// If there are any other stale entries in run, expunge them
//如果slotToExpunge 和 staleSlot不相等 说明有连续的无效数据需要顺便清除
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
注:大家可以在评论区讨论一下,这里为什么要交换一下数据,我个人认为,第一是为了保证数据存储的位置尽可能的在hash计算出位置,有利于后续的get()方法,第二:交换位置之后有利于让无效的数据连续起来,提高清除无效数据的效率。
真正清除无效数据的方法是expungeStaleEntry()方法和cleanSomeSlots()方法
我们先看expungeStaleEntry()方法
expungeStaleEntry()
expungeStaleEntry()方法从当前节点开始向后遍历(直到遇到enrty为null的节点),将无效数据清除,并且重新计算有效的entry的数组下标,如果计算出的下标和entry的下标不相同(这是因为采用了线性寻址法,所以hash计算出下标可能和实际的下标不一样),重新找到合适的位置。
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// expunge entry at staleSlot
//先将当前节点清除
tab[staleSlot].value = null;
tab[staleSlot] = null;
size--;
// Rehash until we encounter null
Entry e;
int i;
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == null) {
//key为null 证明是无效数据 清除
e.value = null;
tab[i] = null;
size--;
} else {
//重新计算数组下标 如果数组下标发生变化 那么将数据迁移到新的位置上
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
//重新利用线性寻址法寻找合适的下标位置
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}
然后是cleanSomeSlots()方法
cleanSomeSlots()
调用log(n)次expungeStaleEntry()方法进行清除无效数据。这个官方说不调用n次来清除,为了效率,而且经过测试调用log(n)次清除无效的数据的效果已经很好了。(n代表entry数组的长度)。
private boolean cleanSomeSlots(int i, int n) {
//removed 是否清除了数据的标记
boolean removed = false;
Entry[] tab = table;
int len = tab.length;
do {
i = nextIndex(i, len);
Entry e = tab[i];
if (e != null && e.get() == null) {
n = len;
removed = true;
i = expungeStaleEntry(i);
}
} while ( (n >>>= 1) != 0);
return removed;
}
如果set()方法设置值之后,需要扩容会调用rehash()方法进行扩容。
先调用expungeStaleEntries()清除一下数据,如果还是需要扩容,那么调用resize()进行扩容。
rehash()
private void rehash() {
//再试清除一下数据
expungeStaleEntries();
// Use lower threshold for doubling to avoid hysteresis
//如果还是需要扩容 那么会调用 resize()进行扩容
if (size >= threshold - threshold / 4)
resize();
}
resize()
resize()方法会创建一个容量为原来两倍的数组,并且将数据迁移到新的数组上面,将新的数组赋值给table变量。(扩容方法比较简单)
private void resize() {
Entry[] oldTab = table;
int oldLen = oldTab.length;
int newLen = oldLen * 2;
Entry[] newTab = new Entry[newLen];
int count = 0;
for (int j = 0; j < oldLen; ++j) {
Entry e = oldTab[j];
if (e != null) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null; // Help the GC
} else {
int h = k.threadLocalHashCode & (newLen - 1);
//线性寻址法解决hash冲突
while (newTab[h] != null)
h = nextIndex(h, newLen);
newTab[h] = e;
count++;
}
}
}
setThreshold(newLen);
size = count;
table = newTab;
}
get()方法
获取到当前线程的threadLocals,如果threadLocals已经初始化,那么调用getEntry()方法获取值。否则调用setInitialValue()获取我们在initialValue()设置的初始化的值。
public T get() {
Thread t = Thread.currentThread();
//利用当前线程获取它的threadLocals(threadLocals是一个ThreadLocalMap)
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
现在我们看getEntry()方法
如果找到key相同的Entry 直接返回,否则调用getEntryAfterMiss()方法
getEntry()
private Entry getEntry(ThreadLocal<?> key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
//如果找到key相同的Entry 直接返回
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}
getEntryAfterMiss()
getEntryAfterMiss()从当前节点往后遍历查找,遍历找到key相同的entry,找到就返回,否则返回null,如果有无效数据,顺便清除一下。
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
while (e != null) {
ThreadLocal<?> k = e.get();
//找到key相同的entry 直接返回
if (k == key)
return e;
if (k == null)
//当前数据为无效数据 清除一下
expungeStaleEntry(i);
else
//否则向后继续查找
i = nextIndex(i, len);
e = tab[i];
}
return null;
}
最后是remove()方法
remove()
利用hash算法计算下标,从下标位置开始往后遍历,找到key相同的entry,将entry删除,顺便调用expungeStaleEntry()方法清除一下无效的数据。
public void remove() {
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
m.remove(this);
}
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
e.clear();
expungeStaleEntry(i);
return;
}
}
}
四:总结
本篇文章对ThreadLocal的数据存储结构,以及set(),get(),remove()方法进行了分析。最后给大家可以再讨论一个问题:为什么ThreadLocal的Entry的key要使用弱引用?
以上就是ThreadLocal数据存储结构原理解析的详细内容,更多关于ThreadLocal数据存储结构的资料请关注我们其它相关文章!
相关推荐
-
TransmittableThreadLocal解决线程间上下文传递烦恼
目录 前言 示例 使用方式 小结 前言 在一些项目中,经常会遇到需要把当前线程中的上下文传递到其他线程中的情况,比如某项目包含国际化操作,在业务请求进来时需要把对应的国家代码存储到当前线程中,以便后续的业务逻辑能够根据国家代码正确地处理:另外在一些异步化操作中,也要保证异常线程中也能够正确地获取到对应的国家代码. 在上述业务场景中,我们很自然的就想到了使用ThreadLocal,但是ThreadLocal无法解决父子线程间上下文传递的问题,此时InheritableThreadLocal站出来了
-
Springboot公共字段填充及ThreadLocal模块改进方案
目录 1. 公共字段自动填充 1.1 问题分析 1.2 基本功能实现 1.2.1 思路分析 1.3 代码实现 1). 实体类的属性上加入@TableField注解,指定自动填充的策略. 2). 按照框架要求编写元数据对象处理器,在此类中统一为公共字段赋值,此类需要实现MetaObjectHandler接口. 2 使用ThreadLocal对公共字段填充功能进行完善 2.1 思路分析 2.1.1 提出设想 2.1.2 分析问题 2.2 ThreadLocal 2.2.1 ThreadLocal基本
-
不规范使用ThreadLocal导致bug分析解决
目录 因为线程重用导致的信息错乱的bug 正确使用的姿势 更优雅的处理方式 最后 因为线程重用导致的信息错乱的bug ThreadLocal一般用于线程间的数据隔离,通过将数据缓存在ThreadLocal中,可以极大的提升性能.但是,如果错误的使用Threadlocal,可能会引起不可预期的bug,以及造成内存泄露. 有时我们会在一个接口中缓存某些数据到ThreadLocal中,但是我们要意识到,处理请求的这些线程是由tomcat提供的,而tomcat提供的线程都是配置在一个线程池中的. 也就是
-
java开发工作中对InheritableThreadLocal使用思考
目录 引言 1. 先说结论 2. 实验例子 3. 详解 3.1 JavaDoc 3.2 源码 3.2.1 childValue方法 4. 实验例子流程图 引言 最近在工作中结合线程池使用 InheritableThreadLocal 出现了获取线程变量“错误”的问题,看了相关的文档和源码后在此记录. 1. 先说结论 InheritableThreadLocal 只有在父线程创建子线程时,在子线程中才能获取到父线程中的线程变量: 当配合线程池使用时:“第一次在线程池中开启线程,能在子线程中获取到父
-
ThreadLocal作用原理与内存泄露示例解析
目录 ThreadLocal作用 简单例子 局部变量.成员变量 . ThreadLocal.静态变量 共享 or 隔离 原理 源码分析 TheadLocal TheadLocalMap ThreadLocal与内存泄漏 小结 ThreadLocal作用 对于Android程序员来说,很多人都是在学习消息机制时候了解到ThreadLocal这个东西的.那它有什么作用呢?官方文档大致是这么描述的: ThreadLocal提供了线程局部变量 每个线程都拥有自己的变量副本,可以通过ThreadLocal
-
ThreadLocal数据存储结构原理解析
目录 一:简述 二:TheadLocal的原理分析 1.ThreadLocal的存储结构 2.源码分析 set()方法 三:源码分析 createMap() 源码: 流程图: expungeStaleEntry() cleanSomeSlots() rehash() resize() get()方法 getEntry() getEntryAfterMiss() remove() 四:总结 一:简述 我们很多时候为了实现数据在线程级别下的隔离,会使用到ThreadLocal,那么TheadLoca
-

Java流程控制顺序结构原理解析
这篇文章主要介绍了Java流程控制顺序结构原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 流程控制的概念 在一个程序执行的过程中,各条语句的执行顺序对程序的结果是有直接影响的.也就是说,程序的流程对运行结果有直接的影响.所以,我们必须清楚每条语句的执行流程.而且,很多时候我们要通过控制语句的执行顺序来实现我们要完成的功能. 流程控制之顺序结构 根据代码的编写顺序,从上往下,依次执行. 顺序结构之流程图 需求 举例说明顺序结构的执行
-
vue.js数据响应式原理解析
目录 Object.defineProperty() 定义 defineReactive 函数 递归侦测对象的全部属性 流程分析 observe 函数 Observer 类 完善 defineReactive 函数 One More Thing Object.defineProperty() 得力于 Object.defineProperty() 的特性,vue 的数据变化有别于 react 和小程序,是非侵入式的.详细介绍可以看 MDN 文档,这里特别说明几点: get / set 属性是函数
-
nginx http模块数据存储结构小结
从本节开始,我们将进入http模块实现原理的讲解,关于http模块,有一个非常重要的点就是其是如何存储http块.server块和location块的数据的,而且nginx有的配置项是可以在多个配置块中使用的,当http块.server块和location块中两个或者两个以上的配置块都配置了该配置项的时候,就会有一个问题是,nginx是如何处理这些配置项的.本文主要讲解http块中的各个模块数据的存储方式,这将是理解nginx的http模块的工作方式的重要基石. 1. 核心模块的存储方式 在ng
-
mysql的Buffer Pool存储及原理解析
目录 一.前言 1.buffer pool是什么 2.buffer pool的工作流程 3.buffer pool缓冲池和查询缓存(query cache) 二.buffer pool的内存数据结构 1.数据页概念 2.那么怎么识别数据在哪个缓存页中 3.buffer pool的初始化与配置 3.1.初始化 3.2.buffer pool的配置 3.3.Buffer Pool Size 设置和生效过程 3.4.Buffer Pool Instances 3.5.SHOW ENGINE INNOD
-
Spring mvc JSON数据交换格式原理解析
什么是JSON JSON(JavaScript Object Notation, JS 对象标记) 是一种轻量级的数据交换格式,目前使用特别广泛. 采用完全独立于编程语言的文本格式来存储和表示数据. 简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言. 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率. 在 JavaScript 语言中,一切都是对象.因此,任何JavaScript 支持的类型都可以通过 JSON 来表示,例如字符串.数字.对象.数组等.看看他的要求和
-
Java运行时数据区划分原理解析
Java中对象创建,内存分配,垃圾回收的权力交给了虚拟机,这其中有利也有弊,程序员也减轻了负担,但是如果不熟悉Java的内存区域划分,一旦出现内存溢出和泄漏,将会很难定位问题的根源,这就有必要了解Java的运行时数据区划分. 方法区(Method Area) 是由各个线程共享的内存区域,用来存储已被虚拟机加载的类型信息.常量.静态变量.即时编译器编译后的代码缓存等数据. 堆(Heap) Java虚拟机所管理的一块最大的内存区域,由所有的线程共享的一块内存区域:堆内存在虚拟机启动时创建,用来存放对
-
vue数据双向绑定原理解析(get & set)
前端的数据双向绑定指的是view(视图)和model(数据)两者之间的关系:view层是页面上展示给用户看的信息,model层一般是指通过http请求从后台返回的数据.view到model的绑定都是通过事件回调函数操作的,model到view的绑定有多种方法. angular,react,vue等mv*模式的框架都实现了数据双向绑定:angular是通过脏检查即新老数据的比较来确定哪些数据发生了变化,从而将它更新到view中:vue则是通过设置数据的get和set函数来实现的,这种方式在性能上是
-
Java web数据可视化实现原理解析
这周用java web制作了全国各个省份的疫情数据的可视化,做的是最基础的柱状图. 先导入 相应的echarts包和插件 <script type="text/javascript"> // 基于准备好的dom,初始化echarts实例 var myChart = echarts.init(document.getElementById('main')); // 指定图表的配置项和数据 myChart.setOption({ title: { text: '全国各省确诊人数
-
Java ThreadLocal原理解析以及应用场景分析案例详解
目录 ThreadLocal的定义 ThreadLocal的应用场景 ThreadLocal的demo TheadLocal的源码解析 ThreadLocal的set方法 ThreadLocal的get方法 ThreadLocalMap的结构 ThreadLocalMap的set方法 ThreadLocalMap的getEntry方法 ThreadLocal的内存泄露 如何避免内存泄露呢 应用实例 实际应用二 总结 ThreadLocal的定义 JDK对ThreadLocal的定义如下: The