Android性能优化死锁监控知识点详解
目录
- 前言
- 死锁检测
- 线程Block状态
- 获取当前线程所请求的锁
- 通过锁获取当前持有的线程
- 线程启动
- nativePeer 与 native Thread tid 与java Thread tid
- dlsym与调用
- 系统限制
- 死锁检测所有代码
- 总结
前言
“死锁”,这个从接触程序开发的时候就会经常听到的词,它其实也可以被称为一种“艺术”,即互斥资源访问循环的艺术,在Android中,如果主线程产生死锁,那么通常会以ANR结束app的生命周期,如果是两个子线程的死锁,那么就会白白浪费cpu的调度资源,同时也不那么容易被发现,就像一颗“肿瘤”,永远藏在app中。当然,本篇介绍的是业内常见的死锁监控手段,同时也希望通过死锁,去挖掘更加底层的知识,同时让我们更加了解一些常用的监控手段。
我们很容易模拟一个死锁操作,比如
val lock1 = Object()
val lock2 = Object()
Thread ({
synchronized(lock1){
Thread.sleep(2000)
synchronized(lock2){
}
}
},"thread222").start()
Thread ({
synchronized(lock2) {
Thread.sleep(1000)
synchronized(lock1) {
}
}
},"thread111").start()
因为thread111跟thread222都同时持有着对方想要的临界资源(互斥资源),因此这两个线程都处在互相等待对方的状态。
死锁检测
我们怎么判断死锁:是否存在一个线程所持有的锁被另一个线程所持有,同时另一个线程也持有该线程所需要的锁,因此我们需要知道以下信息才能进行死锁分析:
- 线程所要获取的锁是什么
- 该锁被什么线程所持有
- 是否产生循环依赖的限制(本篇就不涉及了,因为我们知道了前两个就可以自行分析了)
线程Block状态
通过我们对synchronized的了解,当线程多次获取不到锁的时候,此时线程就会进入悲观锁状态,因此线程就会尝试进入阻塞状态,避免进一步的cpu资源消耗,因此此时两个线程都会处于block 阻塞的状态,我们就能知道,处于被block状态的线程就有可能产生死锁(只是有可能),我们可以通过遍历所有线程,查看是否处于block状态,来进行死锁判断的第一步
val threads = getAllThread()
threads.forEach {
if(it?.isAlive == true && it.state == Thread.State.BLOCKED){
进入死锁判断
}
}
获取所有线程
private fun getAllThread():Array<Thread?>{
val threadGroup = Thread.currentThread().threadGroup;
val total = Thread.activeCount()
val array = arrayOfNulls<Thread>(total)
threadGroup?.enumerate(array)
return array
}
通过对线程的判断,我们能够排除大部分非死锁的线程,那么下一步我们要怎么做呢?如果线程发生了死锁,那么一定拥有一个已经持有的互斥资源并且不释放才有可能造成死锁对不对!那么我们下一步,就是要检测当前线程所持有的锁,如果两个线程同时持有对方所需要的锁,那么就会产生死锁
获取当前线程所请求的锁
虽然我们在java层没有相关的api提供给我们获取线程当前想要请求的锁,但是在我们的native层,却可以轻松做到,因为它在art中得到更多的支持。
ObjPtr<mirror::Object> Monitor::GetContendedMonitor(Thread* thread) {
// This is used to implement JDWP's ThreadReference.CurrentContendedMonitor, and has a bizarre
// definition of contended that includes a monitor a thread is trying to enter...
ObjPtr<mirror::Object> result = thread->GetMonitorEnterObject();
if (result == nullptr) {
// ...but also a monitor that the thread is waiting on.
MutexLock mu(Thread::Current(), *thread->GetWaitMutex());
Monitor* monitor = thread->GetWaitMonitor();
if (monitor != nullptr) {
result = monitor->GetObject();
}
}
return result;
}
其中第一步尝试着通过thread->GetMonitorEnterObject()去拿
mirror::Object* GetMonitorEnterObject() const REQUIRES_SHARED(Locks::mutator_lock_) {
return tlsPtr_.monitor_enter_object;
}
其中tlsPtr_ 其实就是art虚拟机中对于线程ThreadLocal的代表,即代表着只属于线程的本地对象,会先尝试从这里拿,拿不到的话通过Thread类中的wait_mutex_对象去拿
Mutex* GetWaitMutex() const LOCK_RETURNED(wait_mutex_) {
return wait_mutex_;
}
GetContendedMonitor 提供了一个方法查询当前线程想要的锁对象,这个锁对象以ObjPtrmirror::Object对象表示,其中mirror::Object类型是art中相对应于java层的Object类的代表,我们了解一下即可。看到这里我们可能还有一个疑问,这个Thread* thread的入参是什么呢?(其实是nativePeer,下文我们会了解)
我们有办法能够查询到线程当前请求的锁,那么这个锁被谁持有呢?只有解决这两个问题,我们才能进行死锁的判断对不对,我们继续往下
通过锁获取当前持有的线程
我们还记得上文中返回的锁对象是以ObjPtrmirror::Object表示的,当然,art中同样提供了方法,让我们通过这个锁对象去查询当前是哪个线程持有
uint32_t Monitor::GetLockOwnerThreadId(ObjPtr<mirror::Object> obj) {
DCHECK(obj != nullptr);
LockWord lock_word = obj->GetLockWord(true);
switch (lock_word.GetState()) {
case LockWord::kHashCode:
// Fall-through.
case LockWord::kUnlocked:
return ThreadList::kInvalidThreadId;
case LockWord::kThinLocked:
return lock_word.ThinLockOwner();
case LockWord::kFatLocked: {
Monitor* mon = lock_word.FatLockMonitor();
return mon->GetOwnerThreadId();
}
default: {
LOG(FATAL) << "Unreachable";
UNREACHABLE();
}
}
}
这里函数比较简单,如果当前调用正常,那么执行的就是LockWord::kFatLocked,返回的是native层的Thread的tid,最终是以uint32_t类型表示
注意这里GetLockOwnerThreadId中返回的Thread id千万不要跟Java层的Thread对象的tid混淆,这里的tid才是真正的线程id标识
线程启动
我们来看一下native层主线程的启动,它随着art虚拟机的启动随即启动,我们都知道java层的线程其实在没有跟操作系统的线程绑定的时候,它只能算是一块内存!只要经过与native线程绑定后,这时的Thread才能真正具备线程调度的能力,下面我们以主线程启动举例子:
thread.cc
void Thread::FinishStartup() {
Runtime* runtime = Runtime::Current();
CHECK(runtime->IsStarted());
// Finish attaching the main thread.
ScopedObjectAccess soa(Thread::Current());
// 这里是关键,为什么主线程称为“main线程”的原因
soa.Self()->CreatePeer("main", false, runtime->GetMainThreadGroup());
soa.Self()->AssertNoPendingException();
runtime->RunRootClinits(soa.Self());
soa.Self()->NotifyThreadGroup(soa, runtime->GetMainThreadGroup());
soa.Self()->AssertNoPendingException();
}
可以看到,为什么主线程被称为“主线程”,是因为在art虚拟机启动的时候,通过CreatePeer函数,创建的名称是“main”,CreatePeer是native线程中非常重要的存在,所有线程创建都经过它,这个函数有点长,笔者这里做了删减
void Thread::CreatePeer(const char* name, bool as_daemon, jobject thread_group) {
Runtime* runtime = Runtime::Current();
CHECK(runtime->IsStarted());
JNIEnv* env = tlsPtr_.jni_env;
if (thread_group == nullptr) {
thread_group = runtime->GetMainThreadGroup();
}
// 设置了线程名字
ScopedLocalRef<jobject> thread_name(env, env->NewStringUTF(name));
// Add missing null check in case of OOM b/18297817
if (name != nullptr && thread_name.get() == nullptr) {
CHECK(IsExceptionPending());
return;
}
// 设置Thread的各种属性
jint thread_priority = GetNativePriority();
jboolean thread_is_daemon = as_daemon;
// 创建了一个java层的Thread对象,名字叫做peer
ScopedLocalRef<jobject> peer(env, env->AllocObject(WellKnownClasses::java_lang_Thread));
if (peer.get() == nullptr) {
CHECK(IsExceptionPending());
return;
}
{
ScopedObjectAccess soa(this);
tlsPtr_.opeer = soa.Decode<mirror::Object>(peer.get()).Ptr();
}
env->CallNonvirtualVoidMethod(peer.get(),
WellKnownClasses::java_lang_Thread,
WellKnownClasses::java_lang_Thread_init,
thread_group, thread_name.get(), thread_priority, thread_is_daemon);
if (IsExceptionPending()) {
return;
}
// 看到这里,非常关键,self 指向了当前native Thread对象 self->Thread
Thread* self = this;
DCHECK_EQ(self, Thread::Current());
env->SetLongField(peer.get(),
WellKnownClasses::java_lang_Thread_nativePeer,
reinterpret_cast64<jlong>(self));
ScopedObjectAccess soa(self);
StackHandleScope<1> hs(self);
....
}
这里其实就是一次jni调用,把java中的Thread 的nativePeer 进行了赋值,而赋值的内容,正是通过了这个调用SetLongField
env->SetLongField(peer.get(),
WellKnownClasses::java_lang_Thread_nativePeer,
reinterpret_cast64<jlong>(self));
这里我们简单了解一下SetLongField,如果进行过jni开发的同学应该能过明白,其实就是把peer.get()得到的对象(其实就是java层的Thread对象)的nativePeer属性,赋值为了self(native层的Thread对象的指针),并强转换为了jlong类型。我们接下来回到java层
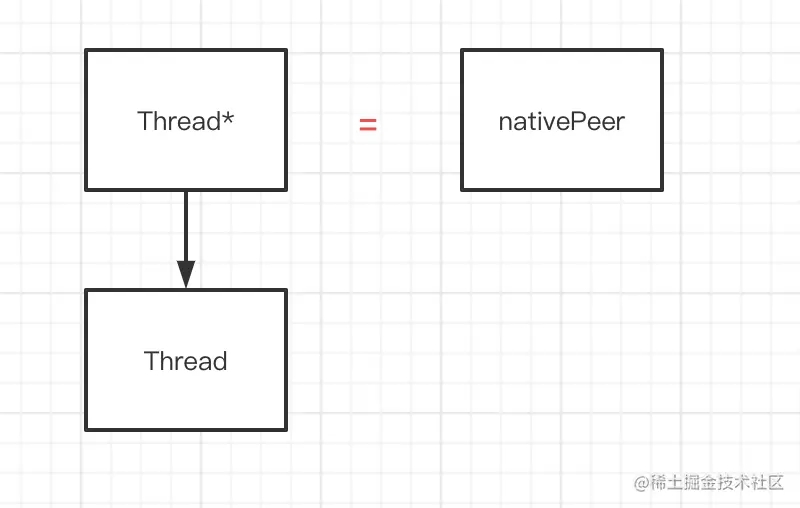
Thread.java private volatile long nativePeer;
说了一大堆,那么这个nativePeer究竟是个什么?通过上面的代码分析,我们能够明白了,Thread.java中的nativePeer就是一个指针,它所指向的内容正是native层中的Thread
nativePeer 与 native Thread tid 与java Thread tid
经过了上面一段落,我们了解了nativePeer,那么我们继续对比一下java层Thread tid 与native层Thread tid。我们通过在kotlin/java中,调用Thread对象的id属性,其实得到的是这个
private long tid;
它的生成方法如下
/* Set thread ID */ tid = nextThreadID();
private static synchronized long nextThreadID() {
return ++threadSeqNumber;
}
可以看到,虽然它的确能代表一个java层中Thread的标识,但是生成其实可以看到,他也仅仅是一个普通的累积id生成,同时也并没有在native层中被当作唯一标识进行使用。
而native Thread 的 tid属性,才是真正的线程id
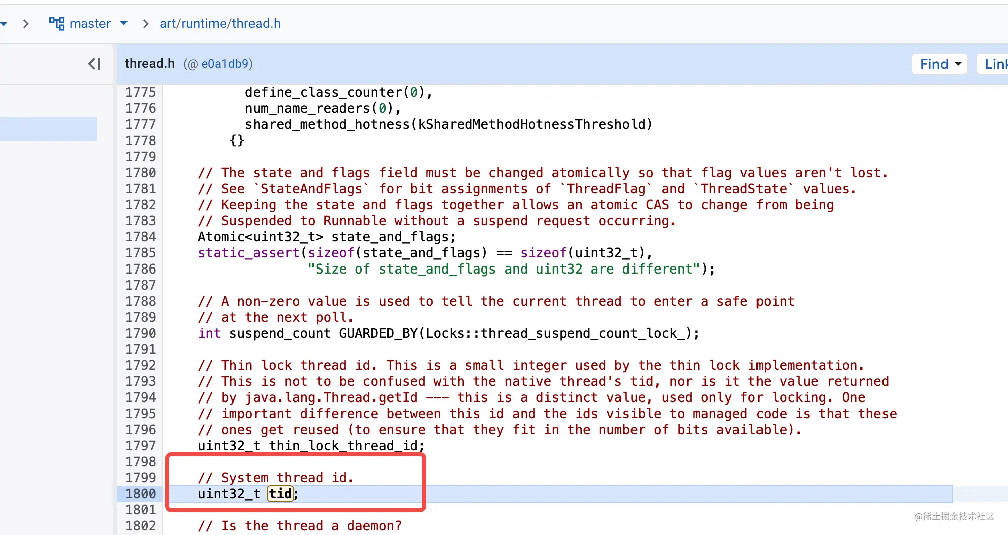
在art中,通过GetTid获取
pid_t GetTid() const {
return tls32_.tid;
}
同时我们也可以注意到,tid 是保存在 tls32_结构体中,并且其位于Thread对象的开头,从内存分布上看,tid位于state_and_flags、suspend_count、think_lock_thread_id之后,还记得我们上面说过的nativePeer嘛?我们一直强调native是Thread的指针对象
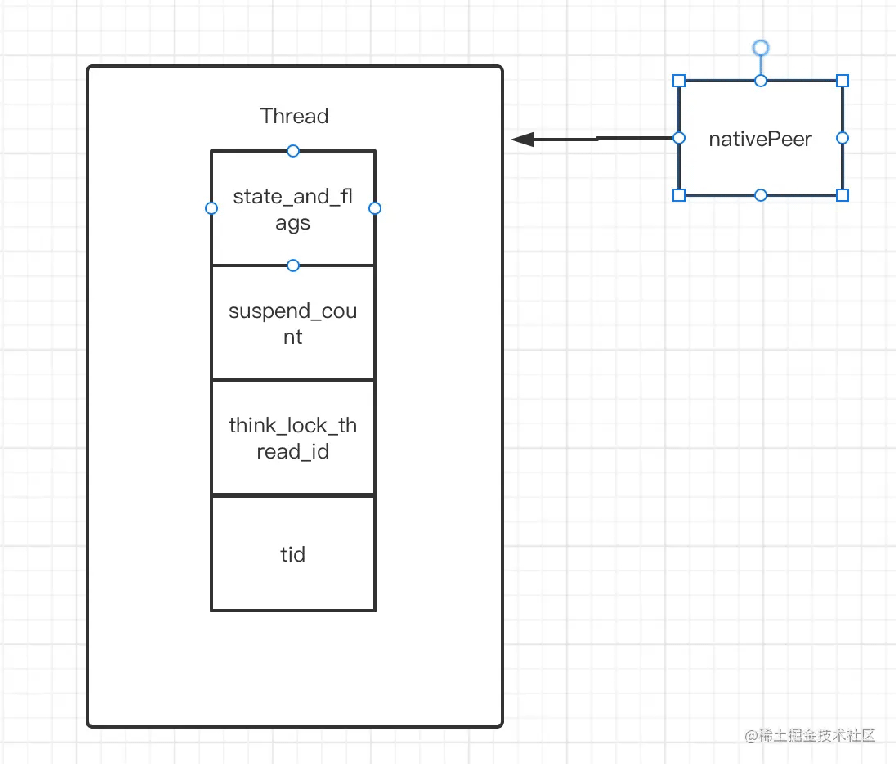
因此我们可以通过指针的偏移,从而算出nativePeer到tid的换算公式,即nativePeer指针向下偏移三位就找到了tid(因为state_and_flags,state_and_flags,think_lock_thread_id都是int类型,那么对应的指针也就是int * )这里有点绕,因为涉及指针的内容
int *pInt = reinterpret_cast<int *>(native_peer); //地址 +3,得到tid pInt = pInt + 3; return *pInt;
nativePeer对象因为就在java层,我们很容易通过反射就能拿到
val nativePeer = Thread::class.java.getDeclaredField("nativePeer")
nativePeer.isAccessible = true
val currentNativePeer = nativePeer.get(it)
这里我们通过nativePeer换算成tid可以写成一个jni方法
external fun nativePeer2Threadid(nativePeer:Long):Int
实现就是
extern "C"
JNIEXPORT jint JNICALL
Java_com_example_signal_MainActivity_nativePeer2Threadid(JNIEnv *env, jobject thiz,
jlong native_peer) {
if (native_peer != 0) {
//long 强转 int
int *pInt = reinterpret_cast<int *>(native_peer);
//地址 +3,得到 native id
pInt = pInt + 3;
return *pInt;
}
}
}
dlsym与调用
我们上面终于把死锁能涉及到的点都讲完,比如如何获取线程所请求的锁,当前锁又被那个线程持有,如何通过nativePeer获取Thread id 做了分析,但是还有一个点我们还没能解决,就是如何调用这些函数。我们需要调用的是GetContendedMonitor,GetLockOwnerThreadId,这个时候dlsym系统调用就出来了,我们可以通过dlsym 进行调用我们想要调用的函数
void* dlsym(void* __handle, const char* __symbol);
这里的symbol是什么呢?其实我们所有的elf(so也是一种elf文件)的所有调用函数都会生成一个符号,代表着这个函数,它在elf的.text中。而我们android中,就会通过加载so的方式加载系统库,加载的系统库libart.so里面就包含着我们想要调用的函数GetContendedMonitor,GetLockOwnerThreadId的符号
我们可以通过objdump -t libart.so 查看符号

这里我们直接给出来各个符号,读者可以直接用objdump查看符号
GetContendedMonitor 对应的符号是
_ZN3art7Monitor19GetContendedMonitorEPNS_6ThreadE
GetLockOwnerThreadId 对应的符号
sdk <= 29 _ZN3art7Monitor20GetLockOwnerThreadIdEPNS_6mirror6ObjectE >29是这个 _ZN3art7Monitor20GetLockOwnerThreadIdENS_6ObjPtrINS_6mirror6ObjectEEE
系统限制
然后到这里,我们还是没能完成调用,因为dlsym等dl系列的系统调用,因为从Android 7.0开始,Android系统开始阻止App中直接使用dlopen(), dlsym()等函数打开系统动态库,好家伙!谷歌大兄弟为了安全的考虑,做了很多限制。但是这个防君子不防程序员,业内依旧有很多绕过系统的限制的方法,我们看一下dlsym
__attribute__((__weak__))
void* dlsym(void* handle, const char* symbol) {
const void* caller_addr = __builtin_return_address(0);
return __loader_dlsym(handle, symbol, caller_addr);
}
__builtin_return_address是Linux一个内建函数(通常由编译器添加),__builtin_return_address(0)用于返回当前函数的返回地址。
在__loader_dlsym 会进行返回地址的校验,如果此时返回地址不是属于系统库的地址,那么调用就不成功,这也是art虚拟机保护手段,因此我们很容易就得出一个想法,我们是不是可以用系统的某个函数去调用dlsym,然后把结果给到我们自己的函数消费就可以了?是的,业内已经有很多这个方案了,比如ndk_dlopen
我们拿arm架构进行分析,arm架构中LR寄存器就是保存了当前函数的返回地址,那么我们是不是在调用dlsym时可以通过汇编代码直接修改LR寄存器的地址为某个系统库的函数地址就可以了?嗯!是的,但是我们还需要把原来的LR地址给保存起来,不然就没办法还原原来的调用了。
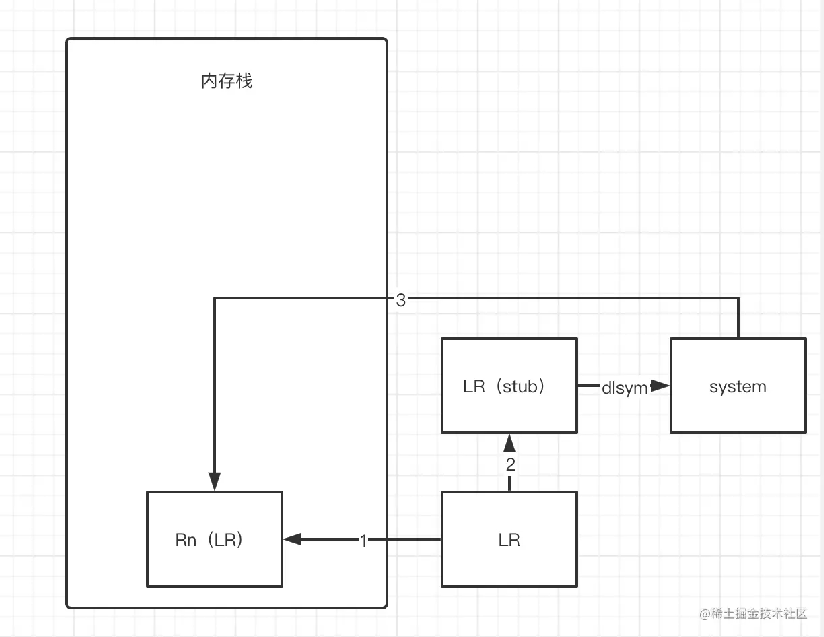
这里我们拿ndk_dlopen的实现举例子
if (SDK_INT <= 0) {
char sdk[PROP_VALUE_MAX];
__system_property_get("ro.build.version.sdk", sdk);
SDK_INT = atoi(sdk);
LOGI("SDK_INT = %d", SDK_INT);
if (SDK_INT >= 24) {
static __attribute__((__aligned__(PAGE_SIZE))) uint8_t __insns[PAGE_SIZE];
STUBS.generic_stub = __insns;
mprotect(__insns, sizeof(__insns), PROT_READ | PROT_WRITE | PROT_EXEC);
// we are currently hijacking "FatalError" as a fake system-call trampoline
uintptr_t pv = (uintptr_t)(*env)->FatalError;
uintptr_t pu = (pv | (PAGE_SIZE - 1)) + 1u;
uintptr_t pd = (pv & ~(PAGE_SIZE - 1));
mprotect((void *)pd, pv + 8u >= pu ? PAGE_SIZE * 2u : PAGE_SIZE, PROT_READ | PROT_WRITE | PROT_EXEC);
quick_on_stack_back = (void *)pv;
// arm架构汇编实现
#elif defined(__arm__)
// r0~r3
/*
0x0000000000000000: 08 E0 2D E5 str lr, [sp, #-8]!
0x0000000000000004: 02 E0 A0 E1 mov lr, r2
0x0000000000000008: 13 FF 2F E1 bx r3
*/
memcpy(__insns, "\x08\xE0\x2D\xE5\x02\xE0\xA0\xE1\x13\xFF\x2F\xE1", 12);
if ((pv & 1u) != 0u) { // Thumb
/*
0x0000000000000000: 0C BC pop {r2, r3}
0x0000000000000002: 10 47 bx r2
*/
memcpy((void *)(pv - 1), "\x0C\xBC\x10\x47", 4);
} else {
/*
0x0000000000000000: 0C 00 BD E8 pop {r2, r3}
0x0000000000000004: 12 FF 2F E1 bx r2
*/
memcpy(quick_on_stack_back, "\x0C\x00\xBD\xE8\x12\xFF\x2F\xE1", 8);
} //if
其中我们拿(*env)->FatalError作为了混淆系统调用的stub,我们参照着流程图去理解上述代码:
- 02 E0 A0 E1 mov lr, r2 把r2寄存器的内容放到了lr寄存器,这个r2存的东西就是FatalError的地址
- 0x0000000000000008: 13 FF 2F E1 bx r3 ,通过bx指令调转,就可以正常执行我们的dlsym了,r3就是我们自己的dlsym的地址
- 0x0000000000000000: 0C 00 BD E8 pop {r2, r3} 调用完r3寄存器的方法把r2寄存器放到调用栈下,提供给后面的执行进行消费
- 0x0000000000000004: 12 FF 2F E1 bx r2 ,最后就回到了我们的r2,完成了一次调用
总之,我们想要做到dl系列的调用,就是想尽方法去修改对应架构的函数返回地址的数值。
死锁检测所有代码
const char *get_lock_owner_symbol_name() {
if (SDK_INT <= 29) {
return "_ZN3art7Monitor20GetLockOwnerThreadIdEPNS_6mirror6ObjectE";
} else {
return "_ZN3art7Monitor20GetLockOwnerThreadIdENS_6ObjPtrINS_6mirror6ObjectEEE";
}
}
extern "C"
JNIEXPORT jint JNICALL
Java_com_example_signal_MyHandler_deadLockMonitor(JNIEnv *env, jobject thiz,
jlong native_thread) {
//1、初始化
ndk_init(env);
//2、打开动态库libart.so
void *so_addr = ndk_dlopen("libart.so", RTLD_NOLOAD);
void * get_contended_monitor = ndk_dlsym(so_addr, "_ZN3art7Monitor19GetContendedMonitorEPNS_6ThreadE");
void * get_lock_owner_thread = ndk_dlsym(so_addr, get_lock_owner_symbol_name());
int monitor_thread_id = 0;
if (get_contended_monitor != nullptr && get_lock_owner_thread != nullptr) {
//1、调用一下获取monitor的函数,返回当前线程想要竞争的monitor
int monitorObj = ((int (*)(long)) get_contended_monitor)(native_thread);
if (monitorObj != 0) {
// 2、获取这个monitor被哪个线程持有,返回该线程id
monitor_thread_id = ((int (*)(int)) get_lock_owner_thread)(monitorObj);
} else {
monitor_thread_id = 0;
}
}
return monitor_thread_id;
}
extern "C"
JNIEXPORT jint JNICALL
Java_com_example_signal_MainActivity_nativePeer2Threadid(JNIEnv *env, jobject thiz,
jlong native_peer) {
if (native_peer != 0) {
if (SDK_INT > 20) {
//long 强转 int
int *pInt = reinterpret_cast<int *>(native_peer);
//地址 +3,得到 native id
pInt = pInt + 3;
return *pInt;
}
}
}
extern "C" jint JNI_OnLoad(JavaVM *vm, void *reserved) {
char sdk[PROP_VALUE_MAX];
__system_property_get("ro.build.version.sdk", sdk);
SDK_INT = atoi(sdk);
return JNI_VERSION_1_4;
}
对应java层
external fun deadLockMonitor(nativeThread:Long):Int
private fun getAllThread():Array<Thread?>{
val threadGroup = Thread.currentThread().threadGroup;
val total = Thread.activeCount()
val array = arrayOfNulls<Thread>(total)
threadGroup?.enumerate(array)
return array
}
external fun nativePeer2Threadid(nativePeer:Long):Int
总结
我们通过死锁这个例子,去了解了native层Thread的相关方法,同时也了解了如何使用dlsym打开函数符号并调用。本篇Android性能优化就到此结束,更多关于Android性能优化死锁监控的资料请关注我们其它相关文章!
相关推荐
-
Android性能优化之JVMTI与内存分配
目录 前言 JVMTI JVMTI 简介: native层开启jvmti 前置准备 复写Agent 开启jvmtiCapabilities 设置jvmtiEventCallbacks 开启监听 java层开启agent 验证分配数据 总结 前言 内存治理一直是每个开发者最关心的问题,我们在日常开发中会遇到各种各样的内存问题,比如OOM,内存泄露,内存抖动等等,这些问题都有以下共性: 难发现,内存问题一般很难发现,业务开发中关系系数更少 治理困难,内存问题治理困难,比如oom,往往堆栈只是压死骆驼
-
Android性能优化之弱网优化详解
目录 弱网优化 1.Serializable原理 1.1 分析过程 1.2 Serializable接口 1.3 ObjectOutputStream 1.4 序列化后二进制文件的一点解读 1.5 常见的集合类的序列化问题 1.5.1 HashMap 1.5.2 ArrayList 2.Parcelable 2.1 Parcel的简介 2.2 Parcelable的三大过程介绍(序列化.反序列化.描述) 2.2.1 描述 2.2.2 序列化 2.2.3 反序列化 2.3 Parcelable的实
-

Android性能优化之plt hook与native线程监控详解
目录 背景 native 线程创建 PLT PLT Hook xhook bhook plt hook总结 背景 我们在android超级优化-线程监控与线程统一可以知道,我们能够通过asm插桩的方式,进行了线程的监控与线程的统一,通过一系列的黑科技,我们能够将项目中的线程控制在一个非常可观的水平,但是这个只局限在java层线程的控制,如果我们项目中存在着native库,或者存在着很多其他so库,那么native层的线程我们就没办法通过ASM或者其他字节码手段去监控了,但是并不是就没有办法,还有
-
Android性能优化系列篇UI优化
目录 前言 一.UI优化 1.1 系统做的优化 1.1.1 硬件加速 1.2 优化方案 1.2.1 java代码布局 1.2.2 View重用 1.2.3 异步创建view 1.2.4 xml布局优化 1.2.5 异步布局框架Litho 1.2.6 屏幕适配 1.2.7 Flutter 1.2.8 Jetpack Compose 1.3 工具篇 1.3.1 Choreographer 1.3.2 LayoutInspector/Android Device Monitor 1.3.3 Systr
-
Android性能优化之捕获java crash示例解析
目录 背景 java层crash由来 为什么java层异常会导致crash 捕获crash 总结 背景 crash一直是影响app稳定性的大头,同时在随着项目逐渐迭代,复杂性越来越提高的同时,由于主观或者客观的的原因,都会造成意想不到的crash出现.同样的,在android的历史化过程中,就算是android系统本身,在迭代中也会存在着隐含的crash.我们常说的crash包括java层(虚拟机层)crash与native层crash,本期我们着重讲一下java层的crash. java层cr
-
Android性能优化之RecyclerView分页加载组件功能详解
目录 引言 1 分页加载组件 1.1 功能定制 1.2 手写分页列表 1.3 生命周期管理 2 github 引言 在Android应用中,列表有着举足轻重的地位,几乎所有的应用都有列表的身影,但是对于列表的交互体验一直是一个大问题.在性能比较好的设备上,列表滑动几乎看不出任何卡顿,但是放在低端机上,卡顿会比较明显,而且列表中经常会伴随图片的加载,卡顿会更加严重,因此本章从手写分页加载组件入手,并对列表卡顿做出对应的优化 1 分页加载组件 为什么要分页加载,通常列表数据存储在服务端会超过100条
-
Android性能优化之线程监控与线程统一详解
目录 背景 常规解决方案 线程监控 当前线程统计 线程信息具体化 线程统一 Thread创建 注意 总结 背景 在我们日常开发中,多线程管理一直是非常头疼的问题之一,尤其在历史性长,结构复杂的app中,线程数会达到好几百个甚至更多,然而过多的线程不仅仅带来了内存上的消耗同时也降低了cpu调度的效率,过多的cpu调度带来的消耗的坏处甚至超过了多线程带来的好处. 在我们日常开发中,通常会遇到以下几个问题 某个场景会创造过多的线程,最终导致oom 线程池过多问题,比如三方库有一套线程池,自己项目也有一
-
Android 性能优化实现全量编译提速的黑科技
目录 一.背景描述 二.效果展示 2.1.测试项目介绍 三.思路问题分析与模块搭建: 3.1.思路问题分析 3.2.模块搭建 四.问题解决与实 编译流程启动,需要找到哪一个 module做了修改 module 依赖关系获取 module 依赖关系 project 替换成 aar 技术方案 hook 编译流程 五.一天一个小惊喜( bug 较多) 5.1 output 没有打包出 aar 5.2 发现运行起来后存在多个 jar 包重复问题 5.3 发现 aar/jar 存在多种依赖方式 5.4 发
-
Android性能优化死锁监控知识点详解
目录 前言 死锁检测 线程Block状态 获取当前线程所请求的锁 通过锁获取当前持有的线程 线程启动 nativePeer 与 native Thread tid 与java Thread tid dlsym与调用 系统限制 死锁检测所有代码 总结 前言 “死锁”,这个从接触程序开发的时候就会经常听到的词,它其实也可以被称为一种“艺术”,即互斥资源访问循环的艺术,在Android中,如果主线程产生死锁,那么通常会以ANR结束app的生命周期,如果是两个子线程的死锁,那么就会白白浪费cpu的调度资
-
Android性能优化大图治理示例详解
目录 引言 1 自定义大图View 1.1 准备工作 1.2 图片宽高适配 1.3 BitmapRegionDecoder 2 大图View的手势事件处理 2.1 GestureDetector 2.2 双击放大效果处理 2.3 手指放大效果处理 引言 在实际的Android项目开发中,图片是必不可少的元素,几乎所有的界面都是由图片构成的:像列表页.查看大图页等,都是需要展示图片,而且这两者是有共同点的,列表展示的Item数量多,如果全部加载进来势必会造成OOM,因此列表页通常采用分页加载,加上
-
React性能优化的实现方法详解
目录 前言 遍历视图key使用 React.memo缓存组件 React.useCallback让函数保持相同的引用 避免使用内联对象 使用React.useMemo缓存计算结果或者组件 使用React.Fragment片段 组件懒加载 通过 CSS 加载和卸载组件 变与不变的地方做分离 总结 前言 想要写出高质量的代码,仅仅靠框架底层帮我们的优化还远远不够,在编写的过程中,需要我们自己去使用提高的 api,或者根据它底层的原理去做一些优化,以及规范. 相比于 Vue ,React 不会再框架源
-
tsc性能优化Project References使用详解
目录 什么是 Project References 示例项目结构 不使用 Project References 带来的问题 tsconfig.json 的 references 配置项 tsconfig.json 的 composite 配置项 使用 Project References 改造示例项目 全量构建 增量构建 对__test__测试代码的处理 总结 什么是 Project References 在了解一个东西是什么的时候,直接看其官方定义是最直观的 TypeScript: Docum
-
详解Android性能优化之启动优化
1.为什么要进行启动优化 网上流行一种说法,就是8秒定律,意思是说,如果用户在打开一个页面,在8秒的时间内还没有打开,那么用户大概的会放弃掉,意味着一个用户的流失.从这里就可以看出,启动优化的重要性了. 2.启动的分类 2.1 冷启动 先来看看冷启动的流程图 从图中可以看出,APP启动的过程是:ActivityManagerProxy 通过IPC来调用AMS(ActivityManagerService),AMS通过IPC启动一个APP进程,ApplicationThread通过反射来创建App
-
java接口性能从20s优化到500ms示例详解
目录 前言 1. 案发现场 2. 现状 3. 第一次优化 4. 第二次优化 5. 第三次优化 5.1 前端做分页 5.2 分批调用接口 前言 接口性能问题,对于从事后端开发的同学来说,是一个绕不开的话题.想要优化一个接口的性能,需要从多个方面着手. 其实,我之前也写过一篇接口性能优化相关的文章<java接口性能优化小技巧>,发表之后在全网广受好评,感兴趣的小伙们可以仔细看看. 本文将会接着接口性能优化这个话题,从实战的角度出发,聊聊我是如何优化一个慢查询接口的. 上周我优化了一下线上的批量评分
-
Android 打包三种方式实例详解
Android 打包三种方式实例详解 前言: 现在市场上很多app应用存在于各个不同的渠道,大大小小几百个,当我们想要在发布应用之后统计各个渠道的用户下载量,我们就要进行多渠道打包. 01.应用的打包签名什么是打包? 打包就是根据签名和其他标识生成安装包. 签名是什么? 1.在android应用文件(apk)中保存的一个特别字符串 2.用来标识不同的应用开发者:开发者A,开发者B 3.一个应用开发者开发的多款应用使用同一个签名 就好比是一个人写文章,签名就相当于作者的署名. 如果两个应用都是一