Kotlin中的惰性操作容器Sequence序列使用原理详解
目录
- Sequence序列
- 执行的顺序
- 只做最少的操作
- 序列可以是无限的
- 序列不会在每个步骤创建集合
- Sequence的基本使用
- 序列的创建
- 序列的操作
- Sequence源码分析
- Sequence是什么?
- 序列的创建方式分析
- 序列的惰性原理
- 总结
Sequence序列
Sequence 是Kotlin标准库提供的一种容器类型。它和Iterable一样具备对集合进行多步骤操作能力,但是却是采用了一种完全不同于Iterable的实现方式:
val map = (0..3).filter {
println("filter:$it")
it % 2 == 0
}.map {
println("map:$it")
it + 1
}
println(map)
上面的代码用来演示Iterable进行连续操作的情况。它的输出如下:
filter:0
filter:1
filter:2
filter:3
map:0
map:2
[1, 3]
像map和filter这些链式集合函数它们都会立即执行并创建中间临时集用来保存数据。当原始数据不多时,这并不会有什么影响。但是,当原始数据量非常大的时候。这就会变的非常低效。而此时,就可以借助Sequence提高效率。
val sequence = (0..3).asSequence().filter {
println("filter:$it")
it % 2 == 0
}.map {
println("map:$it")
it + 1
}
println("准备开始执行")
println(sequence.toList())
上面的代码执行结果如下:
准备开始执行
filter:0
map:0
filter:1
filter:2
map:2
filter:3
[1, 3]
对比Iterable和Sequence:
Iterable是即时的、Sequence是惰性的:前者会要求尽早的计算结果,因此在多步骤处理链的每一环都会有中间产物也就是新的集合产生;后者会尽可能的延迟计算结果,Sequence处理的中间函数不进行任何计算。相反,他们返回一个新Sequence的,用新的操作装饰前一个,所有的这些计算都只是在类似toList的终端操作期间进行。
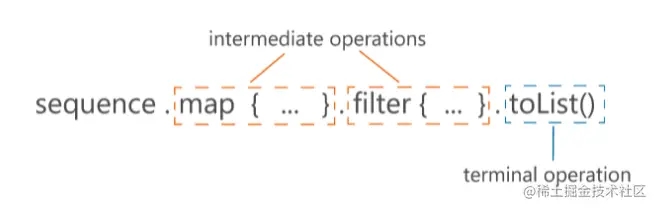
区分中间操作符和末端操作符的方式也很简单:如果操作符返回的是一个Sequence类型的数据,它就是中间操作符。
在操作的执行方式上也有所不同:Iterable每次都是在整个集合执行完操作后再进行下一步操作——采用第一个操作并将其应用于整个集合,然后移动到下一个操作,官方将其称呼为急切式或者按步骤执行(Eager/step-by-step);**而Sequence则是逐个对每个元素执行所有操作。是一种惰性顺序——取第一个元素并应用所有操作,然后取下一个元素,依此类推。**官方将其称呼为惰性式或者按元素执行(Lazy/element-by-element)
序列的惰性会带来一下几个优点:
- 它们的操作按照元素的自然顺序进行;
- 只做最少的操作;
- 元素可以是无限多个;
- 不需要在每一步都创建集合
Sequence可避免生成中间步骤的结果,从而提高了整个集合处理链的性能。但是,惰性性质也会带来一些运行开销。所以在使用时要权衡惰性开销和中间步骤开销,在Sequence和Iterable中选择更加合适的实现方式。
执行的顺序
sequenceOf(1,2,3)
.filter { print("F$it, "); it % 2 == 1 }
.map { print("M$it, "); it * 2 }
.forEach { print("E$it, ") }
// Prints: F1, M1, E2, F2, F3, M3, E6,
listOf(1,2,3)
.filter { print("F$it, "); it % 2 == 1 }
.map { print("M$it, "); it * 2 }
.forEach { print("E$it, ") }
// Prints: F1, F2, F3, M1, M3, E2, E6,
sequence的执行时按照元素进行的,依次对元素执行所有的操作,对一个元素而言,所有操作时依次全部执行的。而普通集合操作则是以操作步骤进行的,当所有的元素执行完当前操作后才会进入下一个操作。
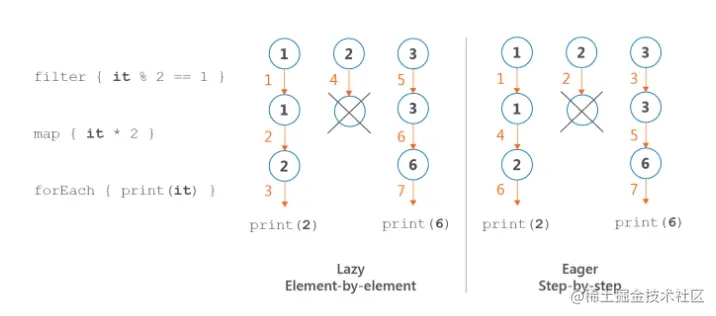
只做最少的操作
试想一下我们有一千万个数字,我们要经过几次变换取出20个,使用下面的代码对比一下序列和不同集合操作的性能:
fun main(){
val fFlow = FFlow()
fFlow.demoList()
fFlow.demoSequence()
}
fun demoSequence() {
val currentTimeMillis = System.currentTimeMillis()
val list =
(0..10000000).asSequence().map { it * 2 }.map { it - 1 }.take(20).toList()
println("demoSequence:${System.currentTimeMillis() - currentTimeMillis}:$list")
}
fun demoList() {
val currentTimeMillis = System.currentTimeMillis()
val list =
(0..10000000).map { it * 2 }.map { it - 1 }.take(20).toList()
println("demoList:${System.currentTimeMillis() - currentTimeMillis}:$list")
}
输出的结果如下:
demoSequence:20ms:[-1, 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37]
demoList:4106ms:[-1, 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37]
这就是只执行最少操作的意思,序列按照元素顺序执行,当取够29个元素之后便会立即停止计算。而不同的集合则不同,没有中间操作的概念。它的每次操作都会对整个数组中的所有元素执行完才会进行下一个——也就是前两个map都要执行一千万次。
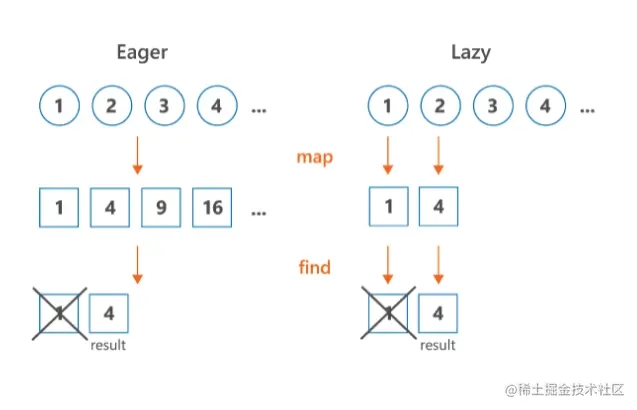
序列可以是无限的
看如下代码:
var list = emptyArray<Int>()
var i = 0
while(true){
list[i] = i++
}
list.take(10)
很明显,这段代码是没法正常运行的,因为这里有一个死循环。我们也无法创建一个无限长度的集合。但是:因为序列式按步骤依照需求进行处理的,所哟我们可以创建无限序列:
val noEnd = sequence {
var i = 1
while (true) {
yield(i)
i *= 2
}
}
noEnd.take(4).toList()
//输出:[1, 2, 4, 8]
但是一定要注意,我们虽然可以这么写,但是务必不能真的让while一直循环。我们不能直接使用toList。必须提供一个能结束循环的操作符,也就是不能取出所有元素(无限个)——要么使用类似take的操作来限制它们的数量,要么使用不需要所有元素的终端操作,例如first, find, any, all, indexOf等。
序列不会在每个步骤创建集合
普通的集合会在每次变换之后都会创建新的集合取存储所有变换后的元素。而每次创建集合和填入数据都会带来不小的性能开销。尤其是当我们处理大量或大量的集合时,性能问题会愈发凸显。而序列的按元素操作,则不会有这个问题。除非手动调用了终端操作符,否则不会生成新的集合。
Sequence的基本使用
Sequence序列的使用和普通的Iterable极其相似,实际上其内部也还是借助Iterable实现的。在研究它的内部实现原理之前,想从Sequence的创建和基本的序列操作来演示Sequence的基本用法。
序列的创建
创建Sequence的方式大概可以分为。分别是由元素创建、通过Iterable、借助函数以及由代码块创建。
由元素创建:通过调用顶级函数sequenceOf实现:
val ints = sequenceOf(1, 2, 3, 4, 5, 6, 7)
val strings = sequenceOf("a","b","c","d","e")
通过Iterable转化:借助Iterable的扩展函数asSequence实现:
val ints = listOf(1, 2, 3, 4, 5, 6, 7).asSequence()
val strings = listOf("a","b","c","d","e").asSequence()
通过generateSequence实现:该方法有三个:
generateSequence(seedFunction: () -> T?, nextFunction: (T) -> T?): Sequence<T> generateSequence(seed: T?, nextFunction: (T) -> T?): Sequence<T> generateSequence(nextFunction: () -> T?): Sequence<T>
最终都是通过GeneratorSequence实现的,这里先不进行源码分析。只讨论使用方式:
- 其中三个函数都有的形参nextFunction可以理解为元素生成器,序列里的元素都通过调用该函数生成,当它返回为null是,序列停止生成(所以,nextFunction必须要在某个情况下返回null,否则会因为序列元素是无限多个触发java.lang.OutOfMemoryError: Java heap space异常)。
- 而另外两个的seedFunction和seed形参都是为了确定数据初始值的。区别在于一个直接指明,一个通过调用函数获取。
分别用这三个函数生成0~100的序列,代码如下:
val generateSequenceOne = generateSequence {
if (i < 100) {
i++
} else {
null
}
}
val generateSequenceTwo = generateSequence(0) {
if (it < 100) {
it+1//此处的it是上一个元素
} else {
null
}
}
val generateSequenceThree = generateSequence({ 0 }) {
if (it < 100) {
it+1//此处的it是上一个元素
} else {
null
}
}
由代码块生成:借助sequence(block: suspend SequenceScope.() -> Unit)函数。该函数接受一个挂起函数,该函数会接受一个SequenceScope实例,这个实例无需我们创建(后面源码分析会讲到)。SequenceScope提供了yield和yieldAll方法复杂返回序列元素给调用者,并暂停序列的执行,直到使用者请求下一个元素。
用该函数生成0~100的序列,代码如下:
val ints = sequence {
repeat(100) {
yield(it)
}
}
序列的操作
对序列的操作可以分为中间操作和末端操作两种。它们只要有一下另种区别:
- 中间操作返回惰性生成的一个新的序列,而末端序列则为其他普通的数据类型;
- 中间操作不会立刻执行代码,仅当执行了末端操作序列才会开始执行。
常见的中间操作包括:map、fliter、first、last、take等;它们会序列提供数据变化过滤等增强功能基本上和kotlin提供的集合操作符有着相同的功能。
常见的末端操作有:toList、toMutableList、sum、count等。它们在提供序列操作功能的同时,还会触发序列的运行。
Sequence源码分析
上文对序列做了简单的入门介绍。接下来深入源码去了解一下Sequence的实现方式。
Sequence是什么?
Kotlin对的定义Sequence很简单:
public interface Sequence <out T> {
public operator fun iterator(): Iterator<T>
}
就是一个接口,定义了一个返回Iterator的方法。接口本身只定义了Sequence具有返回一个迭代器的能力。具体的功能实现还是靠它的实现类完成。
可以概括一些:序列就是一个具备提供了迭代器能力的类。
序列的创建方式分析
结合上文中提到的序列的四种创建方式,我们依次分析一下它的创建流程。
我们首先以比较常用的通过Iterable转化获取序列,它需要借助asSequence方法分析一下,使用listOf("a","b","c","d","e").asSequence()生成一个序列。调用链如下:
public fun <T> Iterable<T>.asSequence(): Sequence<T> {
return Sequence { this.iterator() }
}
public inline fun <T> Sequence(crossinline iterator: () -> Iterator<T>): Sequence<T> = object : Sequence<T> {
override fun iterator(): Iterator<T> = iterator()
}
流程很简单,一个扩展函数加一个内联函数。最终通过匿名内部类的方式创建一个Sequence并返回。代码很好理解,实际上它的实现逻辑等同于下面的代码:
val sequence = MySequence(listOf("a","b","c","d","e").iterator())
class MySequence<T>(private val iterator:Iterator<T>):Sequence<T>{
override fun iterator(): Iterator<T> {
return iterator
}
}
接着看一下通过调用顶级函数sequenceOf实现,以sequenceOf("a","b","c","d","e")为例,它的调用逻辑如下:
public fun <T> sequenceOf(vararg elements: T): Sequence<T> = if (elements.isEmpty()) emptySequence() else elements.asSequence()
可以看到依旧是借助asSequence实现的。
接下来看一下代码块和generateSequence的实现方式,这两个方式会比较复杂一点,毕竟前面两个都是借助List进行转换,而List本身就能提供迭代器Iterator。后面两个明显需要提供新的迭代器。 首先看一下代码看的实现方式:
val ints = sequence {
repeat(100) {
yield(it)
}
}
其中sequence的调用逻辑如下:
public fun <T> sequence(@BuilderInference block: suspend SequenceScope<T>.() -> Unit): Sequence<T> = Sequence { iterator(block) }
public fun <T> iterator(@BuilderInference block: suspend SequenceScope<T>.() -> Unit): Iterator<T> {
//创建迭代器
val iterator = SequenceBuilderIterator<T>()
iterator.nextStep = block.createCoroutineUnintercepted(receiver = iterator, completion = iterator)
return iterator
}
public inline fun <T> Sequence(crossinline iterator: () -> Iterator<T>): Sequence<T> = object : Sequence<T> {
override fun iterator(): Iterator<T> = iterator()
}
可以发现:该方法和asSequence一样最终也是通过匿名内部类的方式创建了一个Sequence。不过区别在于,该方法需要创建一个新的迭代器,也就是SequenceBuilderIterator 。同样以MySequence为例,它的创建流程等同于一下代码:
fun mian(){
create<Int> { myblock() }
}
suspend fun SequenceScope<Int>.myblock(){
repeat(100) {
yield(it)
}
}
fun <Int> create(block: suspend SequenceScope<Int>.() -> Unit):Sequence<Int>{
val iterator = SequenceBuilderIterator<Int>()
iterator.nextStep = block.createCoroutineUnintercepted(receiver = iterator, completion = iterator)
return MySequence(iterator)
}
当然,这是不可能实现的,因为SequenceBuilderIterator是被private修饰了,我们是无法直接访问的。这里强制写出来演示一下它的流程。
最后看一下通过generateSequence方法创建序列的源码,一共有三个:
public fun <T : Any> generateSequence(seedFunction: () -> T?, nextFunction: (T) -> T?): Sequence<T> =
GeneratorSequence(seedFunction, nextFunction)
public fun <T : Any> generateSequence(seed: T?, nextFunction: (T) -> T?): Sequence<T> =
if (seed == null)
EmptySequence
else
GeneratorSequence({ seed }, nextFunction)
public fun <T : Any> generateSequence(nextFunction: () -> T?): Sequence<T> {
return GeneratorSequence(nextFunction, { nextFunction() }).constrainOnce()
}
最终都是创建了GeneratorSequence的一个实例并返回,而GeneratorSequence实现了Sequence接口并重写了iterator()方法:
private class GeneratorSequence<T : Any>(private val getInitialValue: () -> T?, private val getNextValue: (T) -> T?) : Sequence<T> {
override fun iterator(): Iterator<T> = object : Iterator<T> {
var nextItem: T? = null
var nextState: Int = -2 // -2 for initial unknown, -1 for next unknown, 0 for done, 1 for continue
private fun calcNext() {
nextItem = if (nextState == -2) getInitialValue() else getNextValue(nextItem!!)
nextState = if (nextItem == null) 0 else 1
}
override fun next(): T {
if (nextState < 0)
calcNext()
if (nextState == 0)
throw NoSuchElementException()
val result = nextItem as T
// Do not clean nextItem (to avoid keeping reference on yielded instance) -- need to keep state for getNextValue
nextState = -1
return result
}
override fun hasNext(): Boolean {
if (nextState < 0)
calcNext()
return nextState == 1
}
}
}
总结一下Sequence的创建大致可以分为三类:
- 使用List自带的迭代器通过匿名的方式创建Sequence实例,
sequenceOf("a","b","c","d","e")和listOf("a","b","c","d","e").asSequence()就是这种方式; - 创建新的
SequenceBuilderIterator迭代器,并通过匿名的方式创建Sequence实例。例如使用代码块的创建方式。 - 创建
GeneratorSequence,通过重写iterator()方法,使用匿名的方式创建Iterator。GeneratorSequence方法就是采用的这种方式。
看完创建方式,也没什么奇特的,就是一个提供迭代器的普通类。还是看不出是如何惰性执行操作的。接下来就分析一下惰性操作的原理。
序列的惰性原理
以最常用的map操作符为例:普通的集合操作源码如下:
public inline fun <T, R> Iterable<T>.map(transform: (T) -> R): List<R> {
//出啊年一个新的ArrayList,并调用mapTo方法
return mapTo(ArrayList<R>(collectionSizeOrDefault(10)), transform)
}
public inline fun <T, R, C : MutableCollection<in R>> Iterable<T>.mapTo(destination: C, transform: (T) -> R): C {
//遍历原始的集合,进行变换操作,然后将变换后的数据依次加入到新创建的集合
for (item in this)
destination.add(transform(item))
//返回新集合
return destination
}
可以看到:当List.map被调用后,便会立即创建新的集合,然后遍历老数据并进行变换操作。最后返回一个新的数据。这印证了上面提到的普通集合的操作时按照步骤且会立刻执行的理论。
接下来看一下序列的map方法,它的源码如下:
public fun <T, R> Sequence<T>.map(transform: (T) -> R): Sequence<R> {
return TransformingSequence(this, transform)
}
internal class TransformingSequence<T, R>
constructor(private val sequence: Sequence<T>, private val transformer: (T) -> R) : Sequence<R> {
override fun iterator(): Iterator<R> = object : Iterator<R> {
//注释一:TransformingSequence的iterator持有上一个序列的迭代器
val iterator = sequence.iterator()
override fun next(): R {
//注释二:在开始执行迭代时,向上调用前一个序列的迭代器。
return transformer(iterator.next())
}
override fun hasNext(): Boolean {
return iterator.hasNext()
}
}
internal fun <E> flatten(iterator: (R) -> Iterator<E>): Sequence<E> {
return FlatteningSequence<T, R, E>(sequence, transformer, iterator)
}
}
代码并不复杂,它接收用户提供的变换函数和序列,然后创建了一个TransformingSequence并返回。TransformingSequence本身和上文中提到的序列没什么区别,唯一的区别在于它的迭代器:在通过next依次取数据的时候,并不是直接返回元素。而是先调用调用者提供的函数进行变换。返回变换后的数据——这也没什么新鲜的,和普通集合的map操作符和RxJava的Map都是同样的原理。
但是,这里却又有点不一样。操作符里没有任何开启迭代的代码,它只是对序列以及迭代进行了嵌套处理,并不会开启迭代.如果用户不手动调用(后者间接调用)迭代器的next函数,序列就不会被执行——这就是惰性执行的机制的原理所在。
而且,由于操作符返回的是一个Sequence类型的值,当你重复不断调用map时,例如下面的代码:
(0..10).asSequence().map{add(it)}.map{add(it)}.map{add(it)}.toList()
//等同于
val sequence1 = (0..10).asSequence()
val sequence2 = sequence1.map { it+1 }
val sequence3 = sequence2.map { it+1 }
sequence3.toList()
最终,序列sequence3的结构持有如下:sequence3-> sequence2 -> sequence1。而它们都有各自的迭代器。迭代器里都重写了各自的变换逻辑:
override fun next(): R {
return transformer(iterator.next())
}
//由于这里都是执行的+1操作,所以变换逻辑transformer可以认为等同于如下操作:
override fun next(): R {
return iterator.next()+1
}
而当我们通过sequence3.toList执行代码时,它的流程如下:
public fun <T> Sequence<T>.toList(): List<T> {
return this.toMutableList().optimizeReadOnlyList()
}
public fun <T> Sequence<T>.toMutableList(): MutableList<T> {
//末端操作符,此处才会开始创建新的集合
return toCollection(ArrayList<T>())
}
public fun <T, C : MutableCollection<in T>> Sequence<T>.toCollection(destination: C): C {
//执行迭代器next操作
//当调用(末端操作符)走到这里时,便会和普通结合的操作符一样
//此时为新创建的集合赋值
for (item in this) {
destination.add(item)
}
return destination
}
经过几次扩展函数调用,最终在toCollection里开始执行迭代(Iterator的典型的操作),也就是获取了sequence3的iterator实例,并不断通过next取出数据。而在上文中的TransformingSequence源码里可以看到,TransformingSequence会持有上一个迭代器的实例(代码注释一)。
并且在迭代开始后,在进行transformer操作(也就是执行+1操作)前,会调用上一个迭代器的next方法进行迭代(代码注释二)。这样不断的迭代,最终,最终会调用到sequence1的next方法。再结合上文中的序列创建里的分析——sequence1里所持有的迭代器就是就是原始数据里的迭代器。
那么当最终执行toList方法时,它会循环sequence3.iterator方法。而在每次循环内,都会首先执行sequence3所持有的sequence2.iterator的next方法。sequence2依次类推执行到sequence1的sequence1.iterator`方法,最终执行到我们原始数组的迭代器next方法:
整个流程如下:
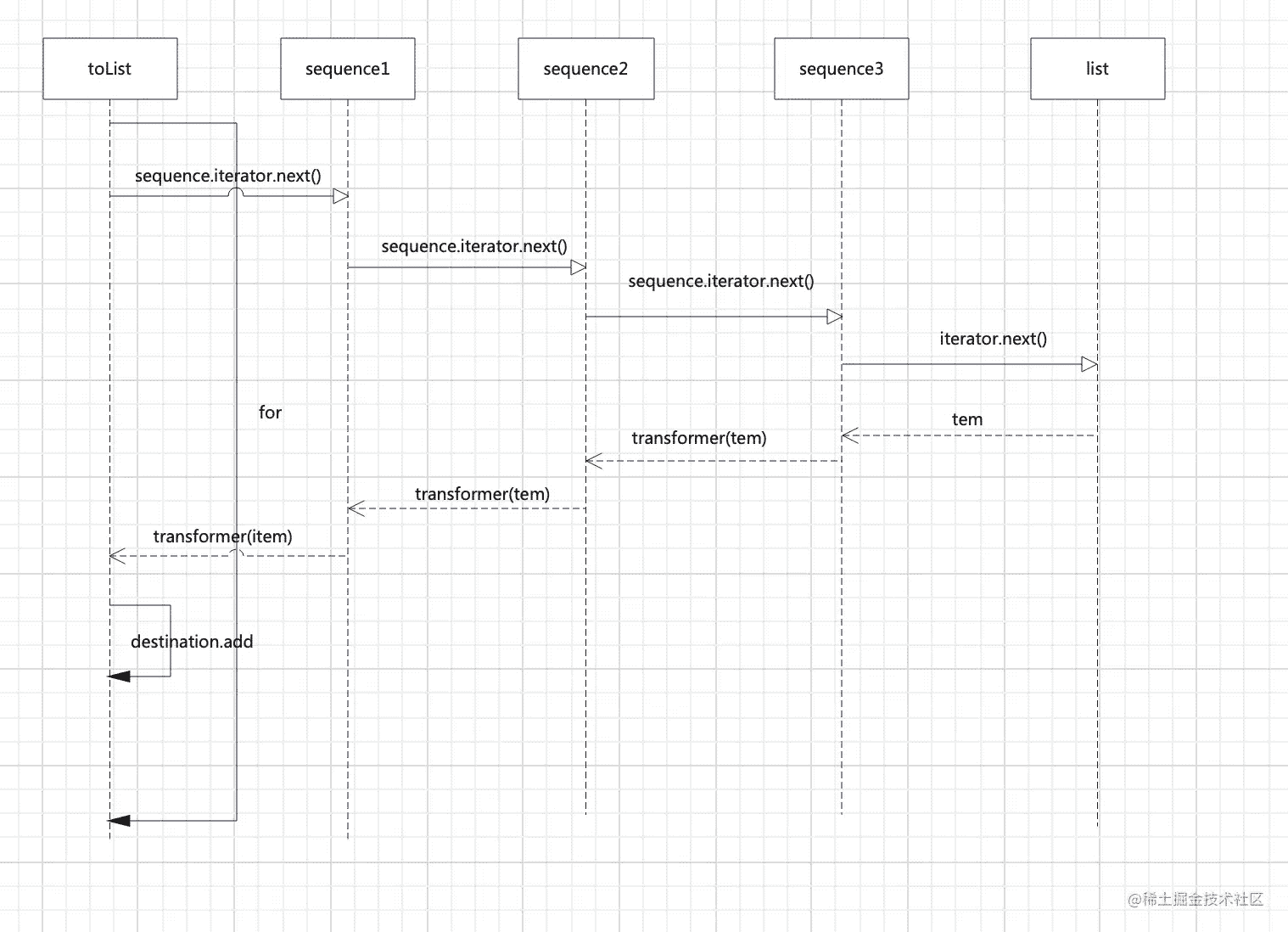
原理就是这么简单:中间操作符通过序列嵌套,实现对迭代器iterator的嵌套。这样在进行迭代的时候,会依次调用各个iterator迭代器直到调用到原始集合数据里的迭代器开始并返回元素。而当元素返回时,会依次执行各个迭代器持有变换操作方法实现对数据的变换。
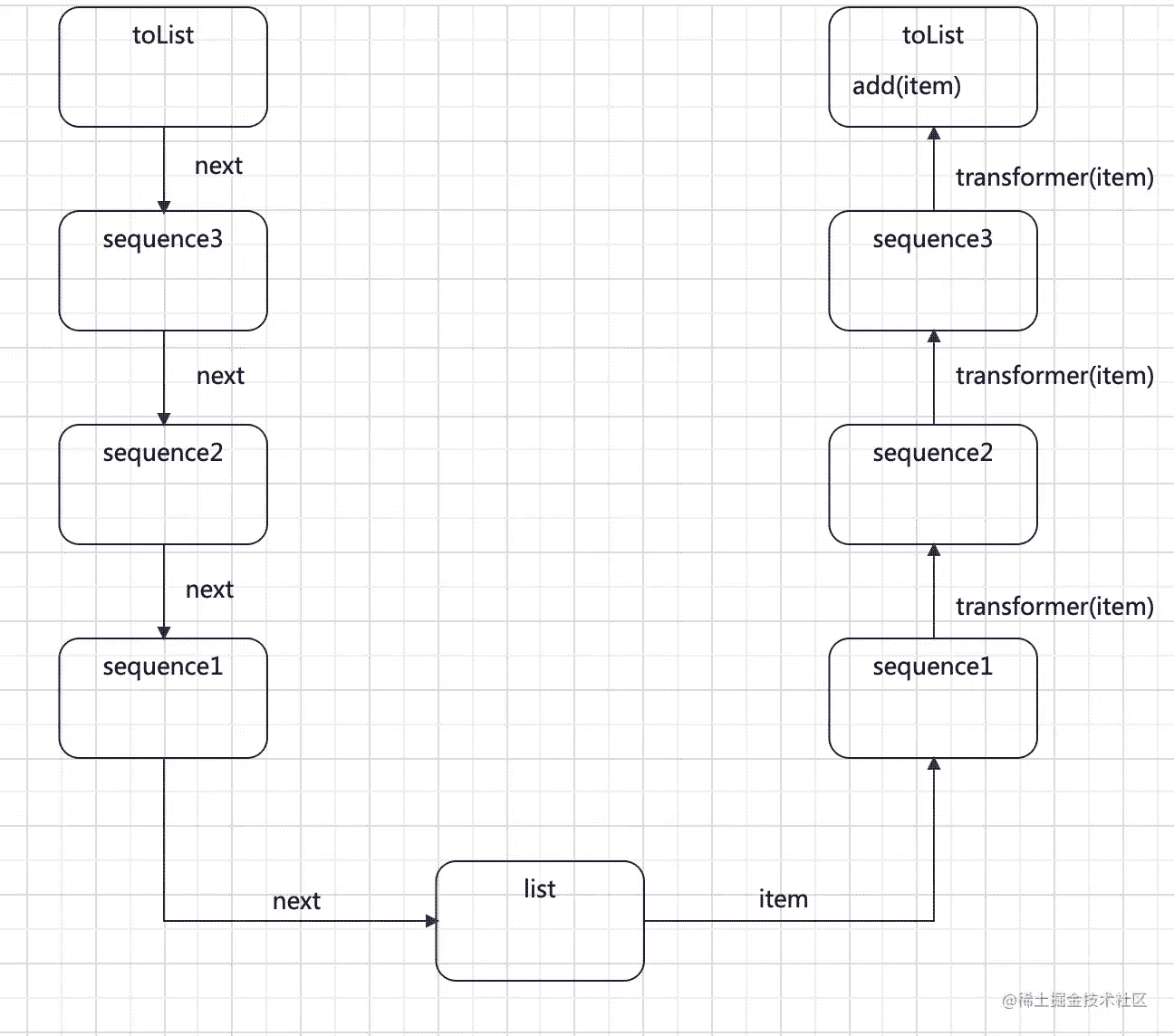
而其他操作符,也是遵循这个基本的规则。无非就是增加一些其他的操作。
总结
- 序列通过中间操作符对迭代器进行嵌套和复写,以此实现按元素操作执行变换;
- 中间操作符只负责根据需求创建并嵌套迭代器,并不负责开启迭代器。以此实现惰性操作且不产生临时集合;
- 末端操作符负责开启迭代,按照嵌套顺序执行迭代操作。依次获取操作后的数据,并且会创建新的集合用来存储最终数据;
- 序列不是万能的,因为要引入新的对象。在带来惰性和顺序执行的优势时,这些对象必然会带来性能开销。所以要依需求在集合和序列之间进行选择,使用合适的方式进行迭代。
以上就是Kotlin中的惰性操作容器Sequence序列使用原理详解的详细内容,更多关于Kotlin惰性容器Sequence的资料请关注我们其它相关文章!
相关推荐
-
Kotlin注解实现Parcelable序列化流程详解
目录 一. 概念介绍 1. 序列化 2. 反序列化 3. 实现序列化的条件 二. 序列化目的 三. 如何选择 四. 进入主题 一. 概念介绍 1. 序列化 由于存在于内存中的对象都是暂时的,无法长期驻存,为了把对象的状态保持下来,这时需要把对象写入到磁盘或者其他介质中,这个过程就叫做序列化. 2. 反序列化 反序列化恰恰是序列化的反向操作,也就是说,把已存在在磁盘或者其他介质中的对象,反序列化(读取)到内存中,以便后续操作,而这个过程就叫做反序列化. 3. 实现序列化的条件 在Jav
-
Kotlin惰性集合操作之Sequence序列使用示例
目录 集合操作函数 和 序列 序列中间和末端操作 创建序列 总结 集合操作函数 和 序列 在了解 Kotlin 惰性集合之前,先看一下 Koltin 标注库中的一些集合操作函数. 定义一个数据模型 Person 和 Book 类: data class Person(val name: String, val age: Int) data class Book(val title: String, val authors: List<String>) filter 和 map 操作: val
-
Kotlin的Collection与Sequence操作异同点详解
目录 前言 累计 遍历 最大最小 过滤(去除) 映射 元素 排序&逆序 Sequence 的常见操作 区别与对比 总结 前言 在Android开发中,集合是我们必备的容器,Kotlin的标准库中提供了很多处理集合的方法,而且还提供了两种基于容器的工作方式:Collection 和 Sequence. Collection 是我们常见的,而 Sequence 确是我们少见的,甚至很多人都没有听说过(是的,说的就是我 ) 本篇文章就来介绍一下常用的一些集合操作符,以及 Collection 与 Se
-
Kotlin中的惰性操作容器Sequence序列使用原理详解
目录 Sequence序列 执行的顺序 只做最少的操作 序列可以是无限的 序列不会在每个步骤创建集合 Sequence的基本使用 序列的创建 序列的操作 Sequence源码分析 Sequence是什么? 序列的创建方式分析 序列的惰性原理 总结 Sequence序列 Sequence 是Kotlin标准库提供的一种容器类型.它和Iterable一样具备对集合进行多步骤操作能力,但是却是采用了一种完全不同于Iterable的实现方式: val map = (0..3).filter { prin
-
Spring中的事务操作、注解及XML配置详解
事务 事务全称叫数据库事务,是数据库并发控制时的基本单位,它是一个操作集合,这些操作要么不执行,要么都执行,不可分割.例如我们的转账这个业务,就需要进行数据库事务的处理. 转账中至少会涉及到两条 SQL 语句: update Acoount set balance = balance - money where id = 'A'; update Acoount set balance = balance + money where id = 'B' 上面这两条 SQL 就可以要看成是一个事务,必
-
PostgreSQL Sequence序列的使用详解
PostgreSQL是一种关系型数据库,和Oracle.MySQL一样被广泛使用.平时工作主要使用的是PostgreSQL,所以有必要对其相关知识做一下总结和掌握,先总结下序列. 一. Sequence序列 Sequence是一种自动增加的数字序列,一般作为行或者表的唯一标识,用作代理主键. 1.Sequence的创建 例子:创建一个seq_commodity,最小值为1,最大值为9223372036854775807,从1开始,增量的步长为1,缓存为1的循环排序Sequence. SQL语句如
-
Java中字符串String的+和+=及循环操作String原理详解
String对象是不可变的:意思就是无论是对String的新增或修改,出现一个全新的String内容时,都意味着诞生了一个新的对象.但是如果内容不变的话,增加的只是对象的引用而已. 例如: String a = "ljh"; String b = "ljh"; String c = "ljh"; System.out.println(a==b); System.out.println(b==c); 结果都是true 但是这种不可变性会产生一些性能
-

浅谈js中几种实用的跨域方法原理详解
这里说的js跨域是指通过js在不同的域之间进行数据传输或通信,比如用ajax向一个不同的域请求数据,或者通过js获取页面中不同域的框架中(iframe)的数据.只要协议.域名.端口有任何一个不同,都被当作是不同的域. 下表给出了相对http://store.company.com/dir/page.html同源检测的结果: 要解决跨域的问题,我们可以使用以下几种方法: 一.通过jsonp跨域 在js中,我们直接用XMLHttpRequest请求不同域上的数据时,是不可以的.但是,在页面上引入不同
-
element中el-container容器与div布局区分详解
用于布局的容器组件,方便快速搭建页面的基本结构: el-container:外层容器.当子元素中包含 或 时,全部子元素会垂直上下排列,否则会水平左右排列. el-header:顶栏容器. el-aside:侧边栏容器. el-main:主要区域容器. el-footer:底栏容器. 以上组件采用了 flex 布局,elemen-ui官方文档链接: http://element-cn.eleme.io/#/zh-CN/component/container 此外,el-container 的子元
-
C++ 中字符串操作--宽窄字符转换的实例详解
C++ 中字符串操作--宽窄字符转换的实例详解 MultiByteToWideChar int MultiByteToWideChar( _In_ UINT CodePage, _In_ DWORD dwFlags, _In_ LPCSTR lpMultiByteStr, _In_ int cbMultiByte, _Out_opt_ LPWSTR lpWideCharStr, _In_ int cchWideChar ); 参数描述: CodePage:常用CP_ACP.CP_UTF8 dwF
-
Vue.js中对css的操作(修改)具体方式详解
使用v-bind:class或者v-bind:style或者直接通过操作dom来对其样式进行更改: 1.v-bind:class || v-bind:style 其中v-bind是指令,: 后面的class 和style是参数,而class之后的指在vue的官方文档里被称为'指令预期值'(这个不必深究,反正个人觉得初学知道他叫啥名有啥用就好了)同v-bind的大多数指令(部分特殊指令如V-for除外)一样,除了可以绑定字符串类型的变量外,还支持一个单一的js表达式,也就是说v-bind:clas
-
对pandas中两种数据类型Series和DataFrame的区别详解
1. Series相当于数组numpy.array类似 s1=pd.Series([1,2,4,6,7,2]) s2=pd.Series([4,3,1,57,8],index=['a','b','c','d','e']) print s2 obj1=s2.values # print obj1 obj2=s2.index # print obj2 # print s2[s2>4] # print s2['b'] 1.Series 它是有索引,如果我们未指定索引,则是以数字自动生成. 下面是一些例
-
python序列类型种类详解
python序列类型包括哪三种 python序列类型包括:列表.元组.字典 列表:有序可变序列 创建:userlist = [1,2,3,4,5,6] 修改:userlist[5] = 999 添加:userlist.append(777) 删除:userlist.remove(4) 或者 del(userlist[3]) pop方法:移除一个元素,默认为最后一个. userlist.pop(3)移除第三个元素,并且返回该值. 插入:userlist.insert(3,555) 排序:userl