MySQL中的流式查询及游标查询方式
目录
- 一、业务场景
- 二、罗列一下三种处理方式
- 2.1 常规查询
- 2.2 流式查询
- 2.3 游标查询
- 三、RowData
- 3.1 RowDataStatic
- 3.2 RowDataDynamic
- 3.3 RowDataCursor
- 四、JDBC 通信原理
- 4.1 generalQuery 普通查询
- 4.2 streamQuery 流式查询
- 4.3 cursorQuery 游标查询
- 五、并发场景
- 六、总结
一、业务场景
现在业务系统需要从 MySQL 数据库里读取 500w 数据行进行处理
- 迁移数据
- 导出数据
- 批量处理数据
二、罗列一下三种处理方式
- 常规查询:一次性读取 500w 数据到 JVM 内存中,或者分页读取
- 流式查询:每次读取一条加载到 JVM 内存进行业务处理
- 游标查询:和流式一样,通过 fetchSize 参数,控制一次读取多少条数据
2.1 常规查询
默认情况下,完整的检索结果集会将其存储在内存中。在大多数情况下,这是最有效的操作方式,更易于实现。
假设单表 500w 数据量,没有人会一次性加载到内存中,一般会采用分页的方式。
在这里,测试demo中只是为了监控JVM,所以没有采用分页,一次性将数据载入内存中
@Test
public void generalQuery() throws Exception {
// 1核2G:查询一百条记录:47ms
// 1核2G:查询一千条记录:2050 ms
// 1核2G:查询一万条记录:26589 ms
// 1核2G:查询五万条记录:135966 ms
String sql = "select * from wh_b_inventory limit 10000";
ps = conn.prepareStatement(sql);
ResultSet rs = ps.executeQuery(sql);
int count = 0;
while (rs.next()) {
count++;
}
System.out.println(count);
}
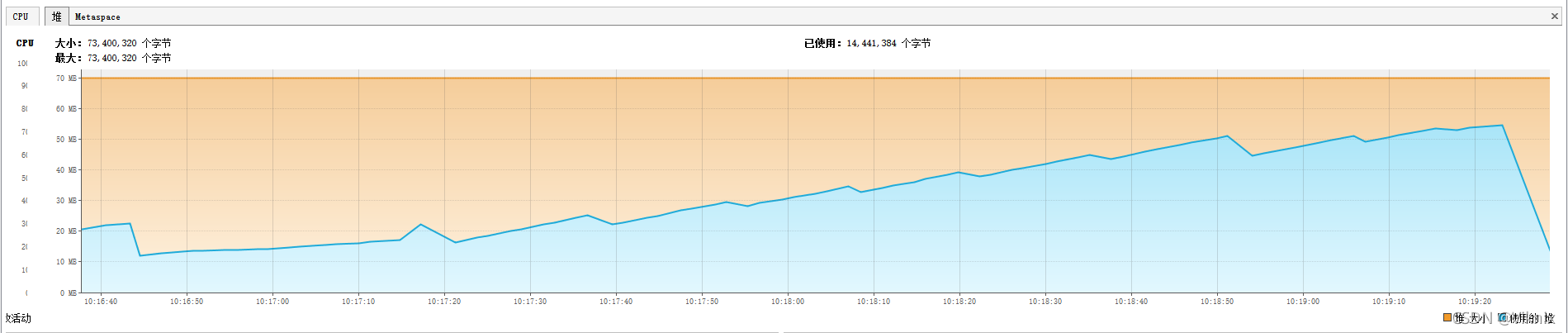
JVM监控
我们将对内存调小-Xms70m -Xmx70m
整个查询过程中,堆内存占用逐步增长,并且最终导致OOM:
java.lang.OutOfMemoryError: GC overhead limit exceeded
1、频繁触发GC
2、存在OOM隐患
2.2 流式查询
流式查询有一点需要注意:必须先读取(或关闭)结果集中的所有行,然后才能对连接发出任何其他查询,否则将引发异常,其 查询会独占连接。
从测试结果来看,流式查询并没有提升查询的速度
@Test
public void streamQuery() throws Exception {
// 1核2G:查询一百条记录:138ms
// 1核2G:查询一千条记录:2304 ms
// 1核2G:查询一万条记录:26536 ms
// 1核2G:查询五万条记录:135931 ms
String sql = "select * from wh_b_inventory limit 50000";
statement = conn.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
statement.setFetchSize(Integer.MIN_VALUE);
ResultSet rs = statement.executeQuery(sql);
int count = 0;
while (rs.next()) {
count++;
}
System.out.println(count);
}
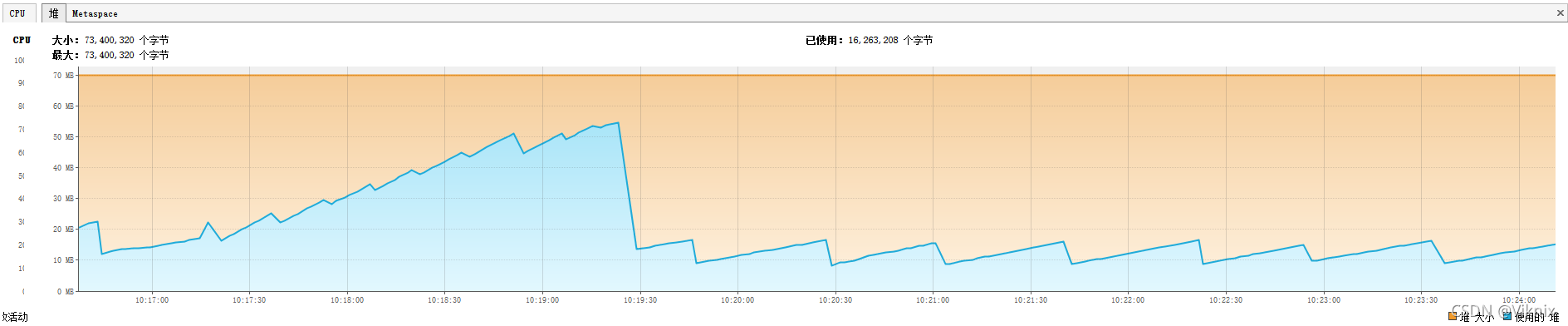
JVM监控
我们将堆内存调小-Xms70m -Xmx70m
我们发现即使堆内存只有70m,却依然没有发生OOM
2.3 游标查询
注意:
1、需要在数据库连接信息里拼接参数 useCursorFetch=true
2、其次设置 Statement 每次读取数据数量,比如一次读取 1000
从测试结果来看,游标查询在一定程度缩短了查询速度
@Test
public void cursorQuery() throws Exception {
Class.forName("com.mysql.jdbc.Driver");
// 注意这里需要拼接参数,否则就是普通查询
conn = DriverManager.getConnection("jdbc:mysql://101.34.50.82:3306/mysql-demo?useCursorFetch=true", "root", "123456");
start = System.currentTimeMillis();
// 1核2G:查询一百条记录:52 ms
// 1核2G:查询一千条记录:1095 ms
// 1核2G:查询一万条记录:17432 ms
// 1核2G:查询五万条记录:90244 ms
String sql = "select * from wh_b_inventory limit 50000";
((JDBC4Connection) conn).setUseCursorFetch(true);
statement = conn.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
statement.setFetchSize(1000);
ResultSet rs = statement.executeQuery(sql);
int count = 0;
while (rs.next()) {
count++;
}
System.out.println(count);
}
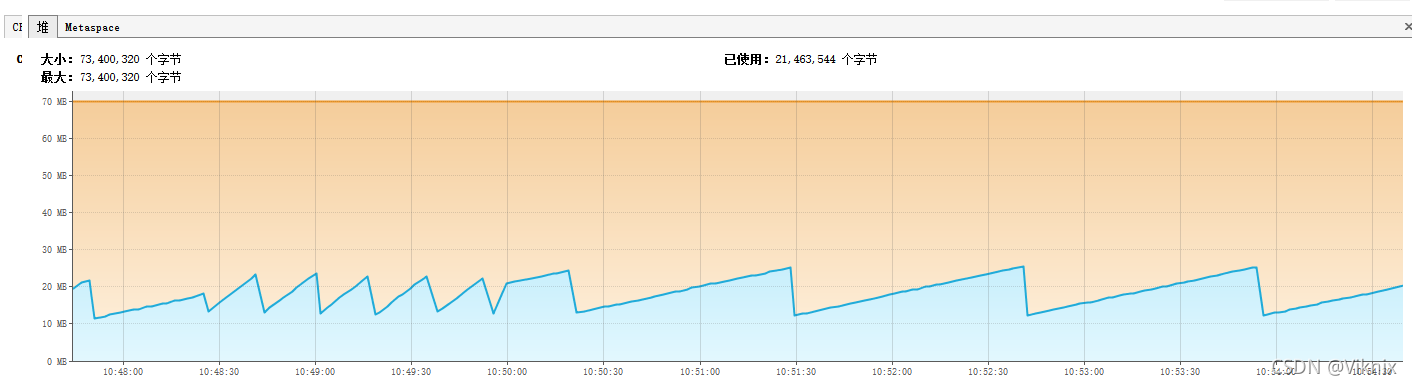
JVM监控
我们将堆内存调小-Xms70m -Xmx70m
我们发现在单线程情况下,游标查询和流式查询一样,都能很好的规避OOM,并且游标查询能够优化查询速度。
三、RowData
ResultSet.next() 的逻辑是实现类 ResultSetImpl 每次都从 RowData 获取下一行的数据。RowData 是一个接口,实现关系图如下

3.1 RowDataStatic
默认情况下 ResultSet 会使用 RowDataStatic 实例,在生成 RowDataStatic 对象时就会把 ResultSet 中所有记录读到内存里,之后通过 next() 再一条条从内存中读
3.2 RowDataDynamic
当采用流式处理时,ResultSet 使用的是 RowDataDynamic 对象,而这个对象 next() 每次调用都会发起 IO 读取单行数据
3.3 RowDataCursor
RowDataCursor 的调用为批处理,然后进行内部缓存,流程如下:
- 首先会查看自己内部缓冲区是否有数据没有返回,如果有则返回下一行
- 如果都读取完毕,向 MySQL Server 触发一个新的请求读取 fetchSize 数量结果
- 并将返回结果缓冲到内部缓冲区,然后返回第一行数据
总结来说就是:
默认的 RowDataStatic 读取全部数据到客户端内存中,也就是我们的 JVM;
RowDataDynamic 每次 IO 调用读取一条数据;
RowDataCursor 一次读取 fetchSize 行,消费完成再发起请求调用。
四、JDBC 通信原理
在 JDBC 与 MySQL 服务端的交互是通过 Socket 完成的,对应到网络编程,可以把 MySQL 当作一个 SocketServer,因此一个完整的请求链路应该是:
JDBC 客户端 -> 客户端 Socket -> MySQL -> 检索数据返回 -> MySQL 内核 Socket Buffer -> 网络 -> 客户端 Socket Buffer -> JDBC 客户端
4.1 generalQuery 普通查询
普通查询会将当次查询到的所有数据加载到JVM,然后再进行处理。
如果查询数据量过大,会不断经历 GC,然后就是内存溢出
4.2 streamQuery 流式查询
服务端准备好从第一条数据开始返回时,向缓冲区怼入数据,这些数据通过TCP链路,怼入客户端机器的内核缓冲区,JDBC会的inputStream.read()方法会被唤醒去读取数据,唯一的区别是开启了stream读取的时候,每次只是从内核中读取一个package大小的数据,只是返回一行数据,如果1个package无法组装1行数据,会再读1个package。
4.3 cursorQuery 游标查询
当开启游标的时候,服务端返回数据的时候,就会按照fetchSize的大小返回数据了,而客户端接收数据的时候每次都会把换缓冲区数据全部读取干净,假如数据有1亿数据,将FetchSize设置成1000的话,会进行10万次来回通信;
由于MySQL方不知道客户端什么时候将数据消费完,而自身的对应表可能会有DML写入操作,此时MySQL需要建立一个临时空间来存放需要拿走的数据。
因此对于当你启用useCursorFetch读取大表的时候会看到MySQL上的几个现象:
- 1.IOPS飙升
- 2.磁盘空间飙升
- 3.客户端JDBC发起SQL后,长时间等待SQL响应数据,这段时间就是服务端在准备数据
- 4.在数据准备完成后,开始传输数据的阶段,网络响应开始飙升,IOPS由“读写”转变为“读取”。
- IOPS (Input/Output Per Second):磁盘每秒的读写次数
- 5.CPU和内存会有一定比例的上升
五、并发场景
并发调用:Jmete 1 秒 10 个线程并发调用
流式查询内存性能报告如下
并发调用对于内存占用情况也很 OK,不存在叠加式增加
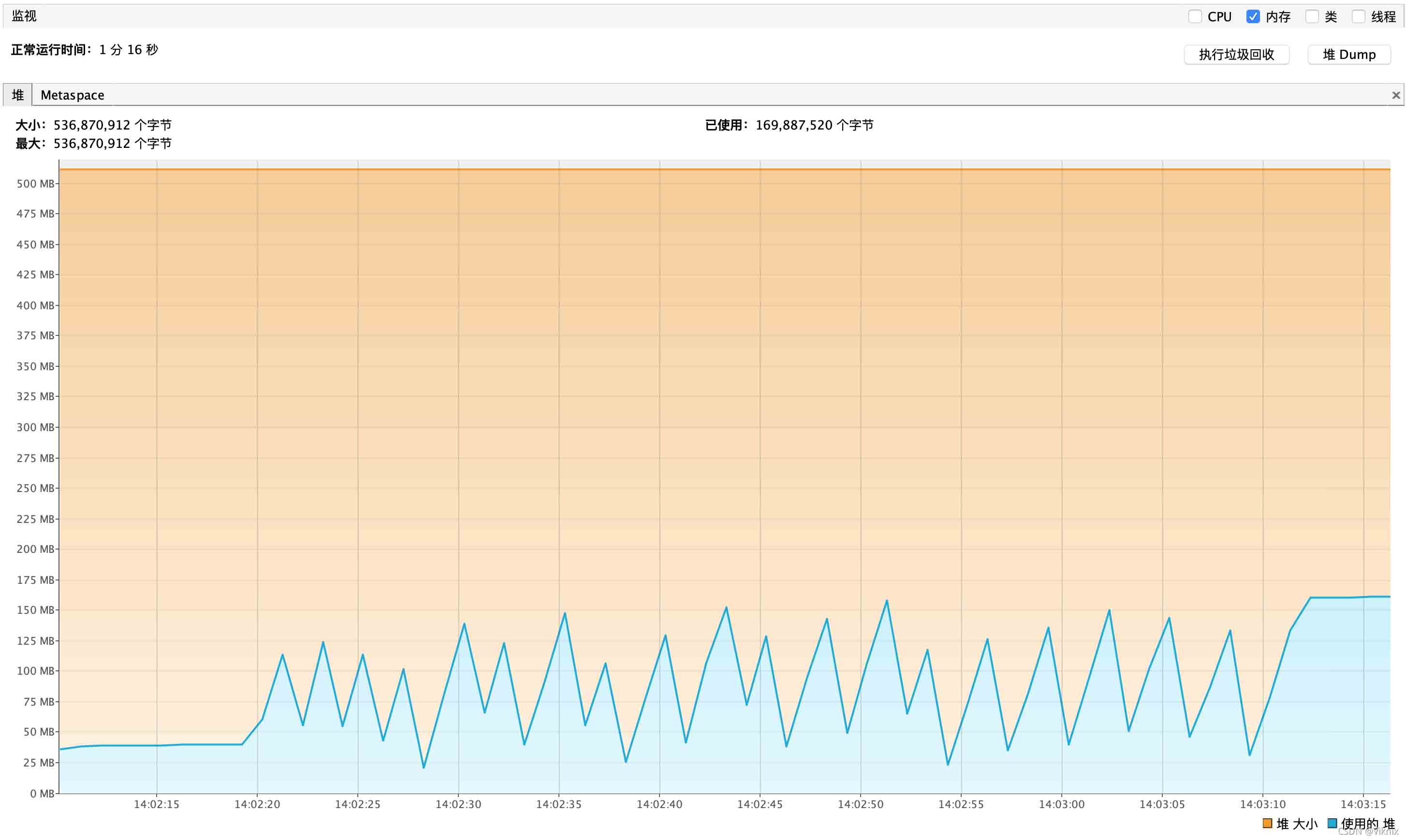
游标查询内存性能报告如下
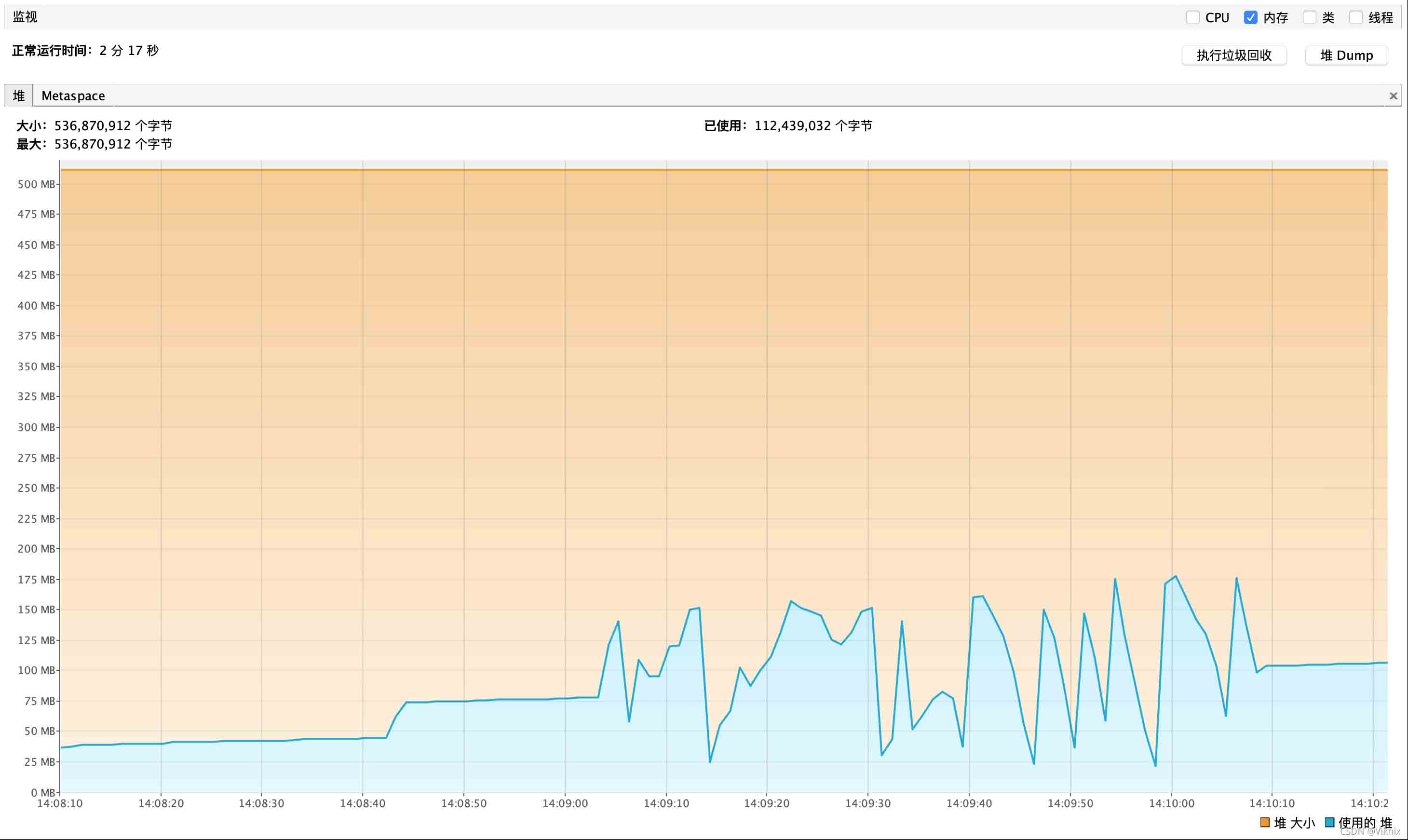
六、总结
1、游标查询和流式查询在单线程下都能够规避OOM的情况;
2、在查询速度上游标查询比流式查询更快,流式查询和普通查询相比并不能缩短查询时间;
3、在并发场景下,流式查询堆内存走势更加稳定,不存在叠加式增加。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

MySQL游标详细介绍
目录 1.什么是游标(或光标) 2.如何使用游标 1.声明游标 2.打开游标 3.使用游标 4.关闭游标 3.代码举例 4.小结 1.什么是游标(或光标) 虽然我们也可以通过筛选条件 WHERE 和 HAVING,或者是限定返回记录的关键字 LIMIT 返回一条记录,但是,却无法在结果集中像指针一样,向前定位一条记录.向后定位一条记录,或者是随意定位到某一条记录,并对记录的数据进行处理. 这个时候,就可以用到游标.游标,提供了一种灵活的操作方式,让我们能够对结果集中的每一条记录进行定位,并对指向
-
详解Mysql 游标的用法及其作用
[mysql游标的用法及作用] 例子: 当前有三张表A.B.C其中A和B是一对多关系,B和C是一对多关系,现在需要将B中A表的主键存到C中: 常规思路就是将B中查询出来然后通过一个update语句来更新C表就可以了,但是B表中有2000多条数据, 难道要执行2000多次?显然是不现实的:最终找到写一个存储过程然后通过循环来更新C表, 然而存储过程中的写法用的就是游标的形式. [简介] 游标实际上是一种能从包括多条数据记录的结果集中每次提取一条记录的机制. 游标充当指针的作用. 尽管游标能
-
MySQL中使用流式查询避免数据OOM
一.前言 程序访问MySQL数据库时,当查询出来的数据量特别大时,数据库驱动把加载到的数据全部加载到内存里,就有可能会导致内存溢出(OOM). 其实在MySQL数据库中提供了流式查询,允许把符合条件的数据分批一部分一部分地加载到内存中,可以有效避免OOM:本文主要介绍如何使用流式查询并对比普通查询进行性能测试. 二.JDBC实现流式查询 使用JDBC的PreparedStatement/Statement的setFetchSize方法设置为Integer.MIN_VALUE或者使用方法State
-
MySQL中的流式查询及游标查询方式
目录 一.业务场景 二.罗列一下三种处理方式 2.1 常规查询 2.2 流式查询 2.3 游标查询 三.RowData 3.1 RowDataStatic 3.2 RowDataDynamic 3.3 RowDataCursor 四.JDBC 通信原理 4.1 generalQuery 普通查询 4.2 streamQuery 流式查询 4.3 cursorQuery 游标查询 五.并发场景 六.总结 一.业务场景 现在业务系统需要从 MySQL 数据库里读取 500w 数据行进行处理 迁移数据
-
谈谈MySQL中的隐式转换
工作过程中会遇到比较多关于隐式转换的案例,隐式转换除了会导致慢查询,还会导致数据不准.本文通过几个生产中遇到的案例来. 基础知识 关于比较运算的原则,MySQL官方文档的描述: https://dev.mysql.com/doc/refman/5.6/en/type-conversion.html 如果 判断符号左右两边有一个为NULL,结果就是null,除非使用安全的等值判断 <=> (none) 05:17:16 >select null = null; +------------
-
ASP.NET Core SignalR中的流式传输深入讲解
前言 什么是流式传输? 流式传输是这一种以稳定持续流的形式传输数据的技术. 流式传输的使用场景 有些场景中,服务器返回的数据量较大,等待时间较长,客户端不得不等待服务器返回所有数据后,再进行相应的操作.这时候使用流式传输,可以将服务器数据碎片化,当每个数据碎片读取完成之后,就只传输完成的部分,而不需要等待所有数据都读取完成. SignalR SignalR是一个.NET Core/.NET Framework的开源实时框架. SignalR的可使用Web Socket, Server Sent
-
Mysql中一千万条数据怎么快速查询
目录 普通分页查询 如何优化 偏移量大 采用id限定方式 优化数据量大问题 普通分页查询 当我们在日常工作中遇到大数据查询的时候,第一反应就是使用分页查询. mysql支持limit语句来选取指定的条数数据,而oracle可以使用rownum来选取 mysql分页查询语句如下: SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset 第一个参数用来指定第一个返回记录行的偏移量 第二个参数指定返回记录行的最大数目 当相同的偏移量时
-
Java8中Stream流式操作指南之入门篇
目录 简介 正文 1. 流是什么 2. 老板,上栗子 3. 流的操作步骤 4. 流的特点 5. 流式操作和集合操作的区别: 总结 简介 流式操作也叫做函数式操作,是Java8新出的功能 流式操作主要用来处理数据(比如集合),就像泛型也大多用在集合中一样(看来集合这个小东西还是很关键的啊,哪哪都有它) 下面我们主要用例子来介绍下,流的基操(建议先看下lambda表达式篇,里面介绍的lambda表达式.函数式接口.方法引用等,下面会用到) 正文 1. 流是什么 流是一种以声明性的方式来处理数据的AP
-
flutter中使用流式布局示例详解
目录 简介 Flow和FlowDelegate Flow的应用 总结 简介 我们在开发web应用的时候,有时候为了适应浏览器大小的调整,需要动态对页面的组件进行位置的调整.这时候就会用到flow layout,也就是流式布局. 同样的,在flutter中也有流式布局,这个流式布局的名字叫做Flow.事实上,在flutter中,Flow通常是和FlowDelegate一起使用的,FlowDelegate用来设置Flow子组件的大小和位置,通过使用FlowDelegate.paintChildre可
-
Mybatis Plus中的流式查询案例
目录 Mybatis Plus流式查询 通用流式查询 Mybatis Plus大数据量流式查询 Mybatis Plus流式查询 mybatis plus 中自定义如下接口,就可以实现流式查询,mybatis 中同样适用. @Select("select * from t_xxx t ${ew.customSqlSegment}") @Options(resultSetType = ResultSetType.FORWARD_ONLY, fetchSize = 1000) @Resul
-
详解MySql基本查询、连接查询、子查询、正则表达查询
查询数据指从数据库中获取所需要的数据.查询数据是数据库操作中最常用,也是最重要的操作.用户可以根据自己对数据的需求,使用不同的查询方式.通过不同的查询方式,可以获得不同的数据.MySQL中是使用SELECT语句来查询数据的.在这一章中将讲解的内容包括. 1.查询语句的基本语法 2.在单表上查询数据 3.使用聚合函数查询数据 4.多表上联合查询 5.子查询 6.合并查询结果 7.为表和字段取别名 8.使用正则表达式查询 什么是查询? 怎么查的? 数据的准备如下: create table STUD
-
JDK1.8新特性Stream流式操作的具体使用
一. 前言 随着Java的发展,越来越多的企业开始使用JDK1.8 版本.JDK1.8 是自 JDK1.5之后最重要的版本,这个版本包含语言.编译器.库.工具.JVM等方面的十多个新特性.本次文章将着重学习Stream. Stream 是JDK1.8 中处理集合的关键抽象概念,Lambda 和 Stream 是JDK1.8新增的函数式编程最有亮点的特性了,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找.过滤和映射数据等操作.使用Stream API 对集合数据进行操作,就类似于使用SQ