Java Http多次请求复用同一连接示例详解
目录
- 概述
- 复用的基本条件
- 理论基础
- 现实基础
- 获取HTTP资源常见方式
- Transfer-Encoding
- 简略实现
概述
注:
- 本文乃是最简单的实现,真实场景要复杂麻烦的多
- 旨在阐述清晰多次HTTP请求复用一个连接的底层逻辑
早在HTTP/1.0时代,每次HTTP请求都要创建一个连接,而创建连接的过程需要消耗资源和时间,代价相对昂贵,为了减少资源消耗,缩短响应时间,就需要重用连接。在后来的HTTP/1.1中,引入了连接复用的机制,Http Header中加入Connection: keep-alive来告诉对方这个请求响应完成后先不忙关闭,这也是本篇文章的由来。
复用的基本条件
理论基础
OSI是Open System Interconnection的缩写,意为开放式系统互联。国际标准化组织(ISO)制定了OSI模型,该模型定义了不同计算机互联的标准,是设计和描述计算机网络通信的基本框架。也就是如下七层模型:
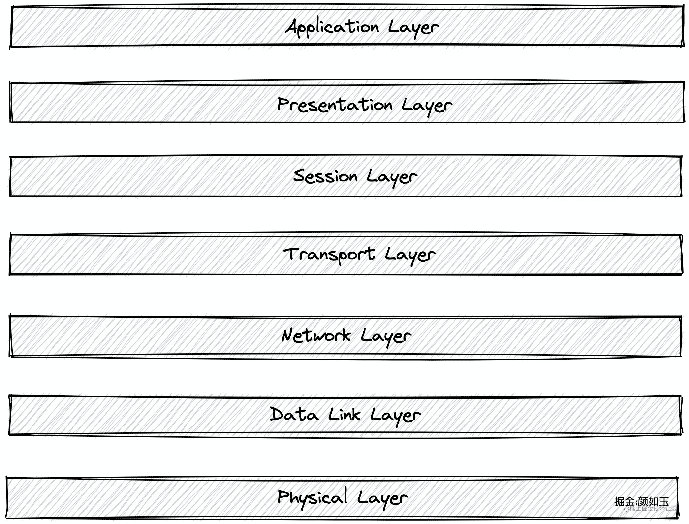
当然也有大家熟知的五层模型,也就是把会话层、表示层、应用层合称为应用层。耳熟能详的TCP、UDP属于数量稀少的传输层协议。在这之上的应用层协议百花齐放诸如:HTTP、SMTR、FTP......,然后很多中间件也自定义了通讯协议,比如Dubbo、Mysql。
读到这里大家可能就已经清醒的意识到,即使同属应用层的协议,是否支持长连接也不尽相同。笔者想要传达的一个认知:之所以能支持长连接,那是因为TCP经历三次握手建立连接之后,如果不出现其他意外是可以保证连接状态的。也就是说应用层协议是否属于长连接仅仅取决于成功建立TCP,发送一个请求之后,对该连接的处理策略:
- 如早期的HTTP每次发送请求,Server端回复完毕之后直接关闭则是短连接
- 如Mysql处理完一条SQL请求,然后继续执行下一个则是长连接
这其实就是我们的理论基础,HTTP有希望支持长连接的前提是TCP本身就是长连接。
现实基础
HTTP协议并非魔法,不是说新增一条规范,也不是简简单单的Header中加入Connection: keep-alive就能立马支持长连接了。想要达到这个目的需要Client、Server端共同努力。
客户端譬如Chrome浏览器,服务端譬如阿里OSS,像这样两端都支持了新的规范,HTTP才能快乐的成为长连接阵营中的一员。
获取HTTP资源常见方式
因为JDK提供了相关工具、且平台相关的第三方包也足够优秀,所以Java获取HTTP资源并非难事。
@Slf4j
public class SinaPicDownload {
/* 微博上某个画师的作品 */
static final String HTTP_URL = "https://wx3.sinaimg.cn/mw2000/006jQ3i8ly1h5k50zujydj35k0334kjo.jpg";
/* 下载之后放在颜如玉电脑的io文件下 */
static final String LOCAL = "/Users/admin/io/灵魂莲华-皎月.jpeg";
public static void main(String[] args) {
try (
InputStream in = new URL(HTTP_URL).openStream();
FileOutputStream out = new FileOutputStream(LOCAL)
) {
byte[] buffer = new byte[1024 << 2];
int read;
while ((read = in.read(buffer)) > -1) {
out.write(buffer, 0, read);
}
out.flush();
}
catch (Throwable e) {
log.error("获取HTTP资源失败:", e);
}
}
}
配合Java 7之后提供的try-with-resources语法糖,你甚至仅仅只需要不到二十行的代码就可以轻而易举的达到目的,但是缺点也显而易见,通过这种方法每次只能获取一个资源,用完之后只能完毕。我当时就在想,Java怎么实现一次连接多次请求呢?
Transfer-Encoding
笔者在上文提到的理论基础上推测到肯定可以使用Java提供的Socket建立TCP连接,关键问题是怎么跟Server端描述HTTP请求呢?

类比到现实生活中,两者能顺畅交流必然要求双方都可以听懂对方的语言。那HTTP有没有一种Client、Server都能解析的规范呢,HTTP Transfer-Encoding正是在这种背景下应运而生。通俗的来讲Transfer-Encoding就是一种双方都约定好的格式,我按照这个格式Encoding,你按照这个格式Decoding,ta大概长这个样子:

可想而知刚刚获取那张图片资源的是时候,我们肯定是这么跟新浪微博服务端说的:

声明:
- 真实的Request Line与图中一致
- Header其实复杂很多,配图做了简化
- 该请求Body为空,图中略过
简略实现
先声明一些常量,以备后用
@Slf4j
public class ReusableHttp {
/* 颜如玉公司的OSS服务域名 */
static final String HOST = "****.oss-cn-zhangjiakou.aliyuncs.com";
static final int PORT = 80;
/* 颜如玉在OSS上放置的几个资源 */
static final String[] URLS = new String[]{
"/context/reusable/gtyj.text",
"/context/reusable/tlyxqch.text",
"/context/reusable/yj.text",
"/context/reusable/ls.text"
};
/* CR = '\r'; LF = '\n'*/
static final byte[] CRLF = new byte[]{Chars.CR, Chars.LF};
static final String LOCAL_PATH = "/Users/admin/io/";
}
建立TCP连接,然后获得输出,输入流
public static void main(String[] args) {
try {
try (
Socket socket = new Socket(HOST, PORT);
OutputStream out = socket.getOutputStream();
InputStream in = socket.getInputStream()
) {
/* 复用连接,获取资源 */
reusable(out, in);
}
}
catch (IOException e) {
log.error("请求出现异常", e);
}
}
写出Request Line
/**
* Write Request Line
*
* RequestLine encoding规范
*
* **********************************************
* * method * sp * URL * sp * version * cr * lf *
* **********************************************
*/
static void writeRequestLine(OutputStream out, String url) throws IOException {
/* 注意空格一定要按照规定来摆放 */
out.write(("GET " + url + " HTTP/1.1").getBytes());
/* 最后再写入一个回车、换行符表示Request Line结束 */
out.write(CRLF);
}
写出Request Header
/**
* Write Request Header
*
* HeaderLine encoding规范
*
* *******************************************
* * header field name * : * value * cr * lf *
* *******************************************
* ....
* *******************************************
* * header field name * : * value * cr * lf *
* *******************************************
* ...
* ***********
* * cr * lf *
* ***********
* ***************
* * Entity Body *
* ***************
*/
static void writeHeaderLine(OutputStream out) throws IOException {
out.write("Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9".getBytes());
out.write(CRLF);
out.write("Accept-Encoding: gzip, deflate".getBytes());
out.write(CRLF);
out.write("Accept-Language: zh-CN,zh;q=0.9".getBytes());
out.write(CRLF);
out.write("Connection: keep-alive".getBytes());
out.write(CRLF);
out.write("Host: kuaimai-sheji.oss-cn-zhangjiakou.aliyuncs.com".getBytes());
out.write(CRLF);
/* 最后再写入一个回车、换行符表示Request Header结束 */
out.write(CRLF);
}
因为是简单的请求,所以直接省略Request Body。发出如上报文后,Server端会解析请求,然后回复。
/**
* 1.向Server端写出请求
* 2.接受Server端回复
* 3.写到颜如玉本地机器的io文件夹下
*
* @param out 往Server端写出流
* @param in Server端往Client端写入流
*/
static void reusable(OutputStream out, InputStream in) throws IOException {
for (int i = 0, s = URLS.length; i < s; i++) {
writeRequestLine(out, URLS[i]);
writeHeaderLine(out);
out.flush();
byte[] bytes = new byte[512];
in.read(bytes);
String file = LOCAL_PATH + i + ".text";
try (
FileOutputStream fo = new FileOutputStream(file)
) {
fo.write(bytes);
fo.flush();
}
catch (Throwable e) {
log.error("文件写入出现异常", e);
}
}
}

可以看到功能已经实现,同一连接我反复请求了四次,最终得到四个资源。
以上就是Java Http多次请求复用同一连接示例详解的详细内容,更多关于Java Http多请求复用的资料请关注我们其它相关文章!
相关推荐
-

利用Java实现调用http请求
目录 一.概述 二. Java调用第三方http接口的方式 2.1.通过JDK网络类Java.net.HttpURLConnection 2.2 通过apache common封装好的HttpClient 2.3 通过Apache封装好的CloseableHttpClient 2.4 通过SpringBoot-RestTemplate 2.5 通过okhttp 一.概述 在实际开发过程中,我们经常需要调用对方提供的接口或测试自己写的接口是否合适.很多项目都会封装规定好本身项目的接口规范,所以大多
-
java发起http请求调用post与get接口的方法实例
目录 一.java调用post接口 1.使用URLConnection或者HttpURLConnection 2.使用CloseableHttpClient 3.使用HttpCaller 二.java调用get接口 总结 一.java调用post接口 1.使用URLConnection或者HttpURLConnection java自带的,无需下载其他jar包 URLConnection方式调用,如果接口响应码被服务端修改则无法接收到返回报文,只能当响应码正确时才能接收到返回 public st
-
JAVA发送HTTP请求的四种方式总结
源代码:http://github.com/lovewenyo/HttpDemo 1. HttpURLConnection 使用JDK原生提供的net,无需其他jar包: HttpURLConnection是URLConnection的子类,提供更多的方法,使用更方便. package httpURLConnection; import java.io.BufferedReader; import java.io.InputStream; import java.io.InputStreamRe
-
JAVA发送HTTP请求的多种方式详细总结
目录 1. HttpURLConnection 2. HttpClient 3. CloseableHttpClient 4. okhttp 5. Socket 6. RestTemplate 总结 程序员日常工作中,发送http请求特别常见.本文以Java为例,总结发送http请求的多种方式. 1. HttpURLConnection 使用JDK原生提供的net,无需其他jar包,代码如下: import com.alibaba.fastjson.JSON; import java.io.Bu
-
解决Java处理HTTP请求超时的问题
在发送POST或GET请求时,返回超时异常处理办法: 捕获 SocketTimeoutException | ConnectTimeoutException | ConnectionPoolTimeout 异常 三种异常说明: SocketTimeoutException:是Java包下抛出的异常,这定义了Socket读数据的超时时间,即从server获取响应数据须要等待的时间:当读取或者接收Socket超时会抛出SocketTimeoutException. ConnectTimeoutExc
-
Java Http请求方式之RestTemplate常用方法详解
目录 引言 常见用法 简单Get\Post请求 Post提交常规表单 Post上传文件 配置项 请求添加Cookie\Header 配置请求工厂 超时.代理 配置拦截器.转换器,错误处理 错误重试(额外) SSL请求 基于RestTemplate一些工具 钉钉机器人通知 总结 引言 在开发中有时候经常需要一些Http请求,请求数据,下载内容,也有一些简单的分布式应用直接使用Http请求作为跨应用的交互协议. 在Java中有不同的Http请求方式,主要就是HttpURLConnection或者Ap
-
Java结构型设计模式之享元模式示例详解
目录 享元模式 概述 目的 应用场景 优缺点 主要角色 享元模式结构 内部状态和外部状态 享元模式的基本使用 创建抽象享元角色 创建具体享元角色 创建享元工厂 客户端调用 总结 享元模式实现数据库连接池 创建数据库连接池 使用数据库连接池 享元模式 概述 享元模式(Flyweight Pattern)又称为轻量级模式,是对象池的一种实现.属于结构型模式. 类似于线程池,线程池可以避免不停的创建和销毁多个对象,消耗性能.享元模式提供了减少对象数量从而改善应用所需的对象结构的方式. 享元模式尝试重用
-
Java实现超简单抖音去水印的示例详解
目录 一.前言 二.原理与步骤 三.代码实现 四.总结 一.前言 抖音去水印方法很简单,以前一直没有去研究,以为搞个去水印还要用到算法去除,直到动手的时候才发现这么简单,不用编程基础都能做. 二.原理与步骤 其实抖音它是有一个隐藏无水印地址的,只要我们找到那个地址就可以了 1.我们在抖音找一个想要去水印的视频链接 注意:这里一定要是https开头的,不是口令 打开浏览器访问: 访问之后会重定向到这个地址,后面有一串数字,这个就是视频的id,他是根据这个唯一id来找到视频播放的 按F12查看网络请
-
java中Servlet监听器的工作原理及示例详解
监听器就是一个实现特定接口的普通java程序,这个程序专门用于监听另一个java对象的方法调用或属性改变,当被监听对象发生上述事件后,监听器某个方法将立即被执行. 监听器原理 监听原理 1.存在事件源 2.提供监听器 3.为事件源注册监听器 4.操作事件源,产生事件对象,将事件对象传递给监听器,并且执行监听器相应监听方法 监听器典型案例:监听window窗口的事件监听器 例如:swing开发首先制造Frame**窗体**,窗体本身也是一个显示空间,对窗体提供监听器,监听窗体方法调用或者属性改变:
-
java面向对象设计原则之里氏替换原则示例详解
目录 概念 实现 拓展 概念 里氏替换原则是任何基类出现的地方,子类一定可以替换它:是建立在基于抽象.多态.继承的基础复用的基石,该原则能够保证系统具有良好的拓展性,同时实现基于多态的抽象机制,能够减少代码冗余. 实现 里氏替换原则要求我们在编码时使用基类或接口去定义对象变量,使用时可以由具体实现对象进行赋值,实现变化的多样性,完成代码对修改的封闭,扩展的开放.如:商城商品结算中,定义结算接口Istrategy,该接口有三个具体实现类,分别为PromotionalStrategy (满减活动,两
-
java EasyExcel面向Excel文档读写逻辑示例详解
目录 正文 1 快速上手 1.1 引入依赖 1.2 导入与导出 2 实现原理 2.1 @RequestExcel 与 @ResponseExcel 解析器 2.2 RequestMappingHandlerAdapter 后置处理器 3 总结 正文 EasyExcel是一款由阿里开源的 Excel 处理工具.相较于原生的Apache POI,它可以更优雅.快速地完成 Excel 的读写功能,同时更加地节约内存. 即使 EasyExcel 已经很优雅了,但面向 Excel 文档的读写逻辑几乎千篇一
-
java接口性能从20s优化到500ms示例详解
目录 前言 1. 案发现场 2. 现状 3. 第一次优化 4. 第二次优化 5. 第三次优化 5.1 前端做分页 5.2 分批调用接口 前言 接口性能问题,对于从事后端开发的同学来说,是一个绕不开的话题.想要优化一个接口的性能,需要从多个方面着手. 其实,我之前也写过一篇接口性能优化相关的文章<java接口性能优化小技巧>,发表之后在全网广受好评,感兴趣的小伙们可以仔细看看. 本文将会接着接口性能优化这个话题,从实战的角度出发,聊聊我是如何优化一个慢查询接口的. 上周我优化了一下线上的批量评分
-
在Android环境下WebView中拦截所有请求并替换URL示例详解
需求背景 接到这样一个需求,需要在 WebView 的所有网络请求中,在请求的url中,加上一个xxx=1的标志位. 例如 http://www.baidu.com 加上标志位就变成了 http://www.baidu.com?xxx=1 寻找解决方案 从 Android API 11 (3.0) 开始,WebView 开始在 WebViewClient 内提供了这样一条 API ,如下: public WebResourceResponse shouldInterceptRequest(Web
-
java中常见的6种线程池示例详解
之前我们介绍了线程池的四种拒绝策略,了解了线程池参数的含义,那么今天我们来聊聊Java 中常见的几种线程池,以及在jdk7 加入的 ForkJoin 新型线程池 首先我们列出Java 中的六种线程池如下 线程池名称 描述 FixedThreadPool 核心线程数与最大线程数相同 SingleThreadExecutor 一个线程的线程池 CachedThreadPool 核心线程为0,最大线程数为Integer. MAX_VALUE ScheduledThreadPool 指定核心线程数的定时
-
java面向对象设计原则之接口隔离原则示例详解
目录 概念 实现 拓展 概念 小接口原则,即每个接口中不存在子类用不到却必须实现的方法,如果不然,就要将接口拆分.如下图所示定义了一个接口,包含了5个方法,实现类A用到了3个方法.实现类B用到了3个方法,类图如下: 类A没有方法4.方法5,却要实现它:类B没有方法2.方法3,但还是要实现这两个方法,不符合接口隔离原则.改造为将其拆分为三个接口,实现方式改为下图所示,符合接口隔离原则: 实现 面向对象机制中一个类可以实现多个接口,通过多重继承分离,通过接口多继承(实现)来实现客户的需求,代码更加清
-
java设计模式七大原则之开闭原则示例详解
目录 1.什么是开闭原则? 2.违反Ocp代码案例 3.遵守Ocp代码案例 1.什么是开闭原则? 开闭原则(Open Closed Principle)是编程中最基础.最重要的设计原则.一个软件实体如类,模块和函数应该对扩展开放(对提供方),对修改关闭(对使用方).用抽象构建框架,用实现扩展细节.当软件需要变化时,尽量通过扩展软件实体的行为来实现变化,而不是通过修改已有的代码来实现变化.编程中遵循其它原则,以及使用设计模式的目的就是遵循开闭原则. 2.违反Ocp代码案例 package com.