Sqlserver 高并发和大数据存储方案
随着用户的日益递增,日活和峰值的暴涨,数据库处理性能面临着巨大的挑战。下面分享下对实际10万+峰值的平台的数据库优化方案。与大家一起讨论,互相学习提高!
案例:游戏平台.
1、解决高并发
当客户端连接数达到峰值的时候,服务端对连接的维护与处理这里暂时不做讨论。当多个写请求到数据库的时候,这时候需要对多张表进行插入,尤其一些表 达到每天千万+的存储,随着时间的积累,传统的同步写入数据的方式显然不可取,经过试验,通过异步插入的方式改善了许多,但与此同时,对读取数据的实时性也需要做一定的牺牲。
异步的方式有很多,目前采取的方式是通过作业每隔一段时间(5min、10min..看需求设定)将临时表的数据转到真实表。
1. 已有原始表A 也是在读取的时候真正用到的表。
2. 建立与原始表A同结构的B和C,用来作数据的中转处理,同步流程是C->B->A。
3. 建立同步数据的作业Job1和记录Job1运行状态的表,在同步的时候比较关键的是需要检查Job1的当前状态,如果当前正在将B的数据同步到A,则把服务端过来的数据存到C,然后再把数据导入到B,等到下一次Job执行的时候再将这批数据转到A。如图1:
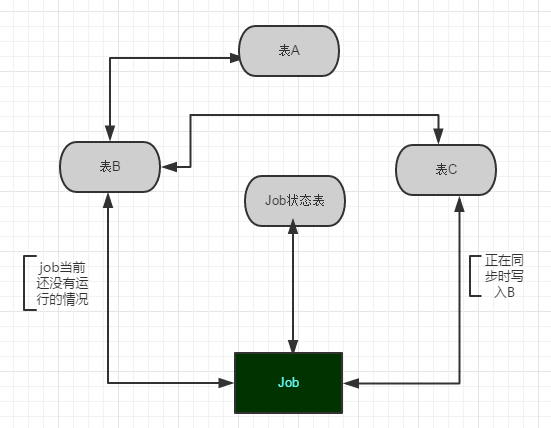
图1
同时,为保万无一失和便于排查问题,应该用一个记录整个数据库实例的存储过程,在较短的时间检查作业执行结果,如果遇到异常失败的,应该及时通过其他方式通知到相关人员。如写入到发邮件和短信表,让一个Tcp的通知程序定时读取发送等等。
注:如果一天的数据达到几十个G,如果又对这个表有查询要求(分区下面会提到),下策之一:
可将B同时同步到多台服务器分担下查询压力,减少资源的竞争。因为整个数据库的资源是有限的,如插入操作,会先获得一个共享锁,然后通过聚集索引定位到某一行数据,再升级为意向锁,而sqlserver对锁的维护根据数据的大小需要申请不同的内存,造成了资源的竞争。所以应该尽可能的将读和写分开,可根据业务模型分,可根据设定的规则分;在平台性的项目中应该优先保证数据能有效的插入。
在不可避免的查询大数据肯定会耗用大量的资源,如遇到批量删除的时候,可以换成以循环分批次(如一次2000条)的方式,这样不至于这个进程导致整个库挂掉,衍生出一些无法预计的bug。经实践,有效可行,只是牺牲了存储空间。也可根据查询需求将表里数据量大的字段拆分出来到新表,当然这些也要根据每个业务场景结合需求来设定,设计出适合而并不需要华丽的方案即可。
2、解决存储问题
如果每天单表的数据都达到了几十个G,改善存储方案自然迫不及待了。现分享下自有的方案,在暴涨的数据摧残之下,仍坚守在一线!现举例对自有环境分享拙见:
现有数据表A,单表每天新增数据30G,在存储的时候采用异步将数据同步的方式,有的不能清除数据的表,在分区后还可分文件组,将文件组分配到不同的磁盘中,减少IO资源的竞争,保障现有资源的正常运行。现结合需求保留历史数据5天:
1. 这时需要通过作业job根据分区函数去生成分区方案,如根据userid或者时间字段来分区;
2. 将表分区后,查询可以通过对应的索引,快速定位到某一段分区;
3. 通过作业合并分区将不要的分区数据转移到相同结构和索引的表,然后清除这个表的数据。
如图2:
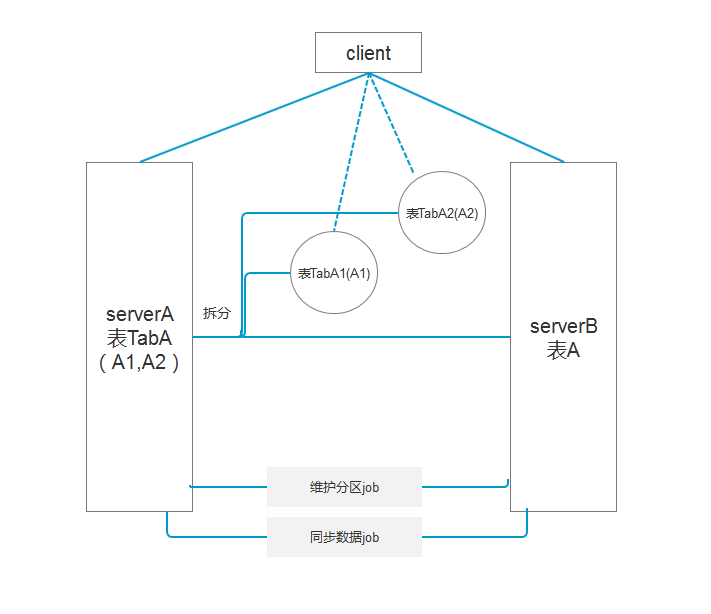
图2
通过sql查询跟踪捕捉到查询耗时长的,以及通过sql自带的存储过程sp_lock或视图dm_tran_locks、dblockinfo查看当前实例存在的锁的类型和粒度。
定位到具体的查询语句或者存储过程之后,对症下药!药到病除!
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,同时也希望多多支持我们!
相关推荐
-

sqlServer实现去除字符串空格
说起去除字符串首尾空格大家肯定第一个想到trim()函数,不过在sqlserver中是没有这个函数的,却而代之的是ltrim()和rtrim()两个函数.看到名字所有人都 知道做什么用的了,ltrim()去除字符串左边的空格,rtrim()去除字符串右边的空格,要去除首尾空格同时使用这个两个函数就好了. 测试: select ltrim(' test ') --去除左边的空格 select rtrim(' test ') --去除右边的空格 select ltrim(rtrim(' test '
-
浅谈sqlserver下float的不确定性
很多时候,大家都知道,浮点型这个东西,本身存储就是一个不确定的数值,你永远无法知道,它是 0 = 0.00000000000000123 还是 0 = 0.00000000000999这样的东西.也许一开始使用的时候没有问题,但是有时候做统计的时候,就会看出端倪 简单的举个例子,就知道统计的时候,有可能出现意外的效果,导致可能需要存储过程或者接收程序的代码左额外的取舍数位的处理,所以在此其实我是推荐使用Numeric来替代float进行一个替代使用,避免一个sum ,然后明明明细看每一条数据都是
-
SqlServer 在事务中获得自增ID的实例代码
SqlServer 在事务中获得自增ID实例代码 在sqlserver 中插入数据时,如何返回自增的主键ID,方式有很多,这里提供一种. 代码如下: USE tempdb go CREATE TABLE table1 ( id INT, employee VARCHAR(32) ) go INSERT INTO table1 VALUES(1, 'one') INSERT INTO table1 VALUES(2, 'two') INSERT INTO table1 VALUES(3, 't
-
SqlServer中模糊查询对于特殊字符的处理方法
今天在处理sql查询的时候遇到了like查询不到的问题,于是对问题进行剖析 问题: select * from v_workflow_rt_task_circulate where Name like '%[admin]请假申请[2017-02-13至2017-02-13]%' 查询不到,但是在数据库中是存在在这一条数据的. 修改后: select * from v_workflow_rt_task_circulate where Name like '%[[]admin]请假申请[[]2017
-
SQLServer中防止并发插入重复数据的方法详解
SQLServer中防止并发插入重复数据,大致有以下几种方法: 1.使用Primary Key,Unique Key等在数据库层面让重复数据无法插入. 2.插入时使用条件 insert into Table(****) select **** where not exists(select 1 from Table where ****); 3.使用SERIALIZABLE隔离级别,并且使用updlock或者xlock锁提示(等效于在默认隔离级别下使用(updlock,holdlock)或(xl
-
Sqlserver 高并发和大数据存储方案
随着用户的日益递增,日活和峰值的暴涨,数据库处理性能面临着巨大的挑战.下面分享下对实际10万+峰值的平台的数据库优化方案.与大家一起讨论,互相学习提高! 案例:游戏平台. 1.解决高并发 当客户端连接数达到峰值的时候,服务端对连接的维护与处理这里暂时不做讨论.当多个写请求到数据库的时候,这时候需要对多张表进行插入,尤其一些表 达到每天千万+的存储,随着时间的积累,传统的同步写入数据的方式显然不可取,经过试验,通过异步插入的方式改善了许多,但与此同时,对读取数据的实时性也需要做一定的牺牲. 异步的
-
详解Mysql数据库平滑扩容解决高并发和大数据量问题
目录 1 停机方案 2 停写方案 3 平滑扩容之双写方案(中小型数据) 4 平滑扩容之2N方案大数据量问题解决 4.1 扩容问题 4.2 解决方案 4.3 双主架构思想 4.4 环境部署 5 数据库秒级平滑2N扩容实践 5.1 新增数据库VIP 5.2 应用服务增加动态数据源 5.3 解除原双主同步 5.4 安装MariaDB扩容服务器 5.5 增加KeepAlived服务实现高可用 5.6 清理数据并验证 1 停机方案 发布公告 停止服务 离线数据迁移(拆分,重新分配数据) 数据校验 更改配置
-
PHP高并发和大流量解决方案整理
一.高并发的概念 在互联网时代,并发,高并发通常是指并发访问.也就是在某个时间点,有多少个访问同时到来. 二.高并发架构相关概念 1.QPS (每秒查询率) : 每秒钟请求或者查询的数量,在互联网领域,指每秒响应请求数(指HTTP请求) 2.PV(Page View):综合浏览量,即页面浏览量或者点击量,一个访客在24小时内访问的页面数量 --注:同一个人浏览你的网站的同一页面,只记做一次pv 3.吞吐量(fetches/sec) :单位时间内处理的请求数量 (通常由QPS和并发数决定) 4.响
-
SqlServer高版本数据备份还原到低版本
最近遇见一个问题: 想要将Sqlserver高版本备份的数据还原到低版本SqlServer上去,但是这在SqlServer中是没法直接还原数据库的,所以经过一系列的请教总结出来一下可用方法. 首先.你得在电脑上装有你将要操作的高版本以及低版本的SqlServer或者你能够连上SqlServer高版本所在的数据库(便于后面拷贝数据), 第二步.打开高版本数据库中你需要备份的数据库,将你备份的数据库相关的登录名或者用户删除.右键数据库->任务->生成脚本.在生成脚本的"选择对象"
-
Java开发者必备10大数据工具和框架
当今IT开发人员面对的最大挑战就是复杂性,硬件越来越复杂,OS越来越复杂,编程语言和API越来越复杂,我们构建的应用也越来越复杂.根据外媒的一项调查报告,中软卓越专家列出了Java程序员在过去12个月内一直使用的一些工具或框架,或许会对你有意义. 先来看看大数据的概念.根据维基百科,大数据是庞大或复杂的数据集的广义术语,因此传统的数据处理程序不足以支持如此庞大的体量. 在许多情况下,使用SQL数据库存储/检索数据都是很好的选择.而现如今的很多情况下,它都不再能满足我们的目的,这一切都取决于用例的
-
Python使用shelve模块实现简单数据存储的方法
本文实例讲述了Python使用shelve模块实现简单数据存储的方法.分享给大家供大家参考.具体分析如下: Python的shelve模块提供了一种简单的数据存储方案,以dict(字典)的形式来操作数据. #!/usr/bin/python import sys, shelve def store_person(db): """ Query user for data and store it in the shelf object """ pi
-
为什么入门大数据选择Python而不是Java?
马云说:"未来最大的资源就是数据,不参与大数据十年后一定会后悔."毕竟出自wuli马大大之口,今年二月份我开始了学习大数据的道路,直到现在对大数据的学习脉络和方法也渐渐清晰.今天我们就来谈谈学习大数据入门语言的选择.当然并不只是我个人之见,此外我搜集了各路大神的见解综合起来跟大家做个讨论. java和python的区别到底在哪里? 官方解释:Java是一门面向对象编程语言,不仅吸收了C++语言的各种优点,还摒弃了C++里难以理解的多继承.指针等概念,因此Java语言具有功能强大和简单易
-
详解java解决分布式环境中高并发环境下数据插入重复问题
java 解决分布式环境中 高并发环境下数据插入重复问题 前言 原因:服务器同时接受到的重复请求 现象:数据重复插入 / 修改操作 解决方案 : 分布式锁 对请求报文生成 摘要信息 + redis 实现分布式锁 工具类 分布式锁的应用 package com.nursling.web.filter.context; import com.nursling.nosql.redis.RedisUtil; import com.nursling.sign.SignType; import com.nu
-
大数据量高并发的数据库优化详解
如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能.所以,在一个系统开始实施之前,完备的数据库模型的设计是必须的. 一.数据库结构的设计 在一个系统分析.设计阶段,因为数据量较小,负荷较低.我们往往只注意到功能的实现,而很难注意到性能的薄弱之处,等到系统投入实际运行一段时间后,才发现系统的性能在降低,这时再来考虑提高系统性能则要花费更多的人力物力,而整个系统也不可避免的形成了一个打补丁工程. 所以在考虑整个系统的流程的时候,我们必须
-
PHP解决高并发的优化方案实例
我们通常衡量一个Web系统的吞吐率的指标是QPS(Query Per Second,每秒处理请求数),解决每秒数万次的高并发场景,这个指标非常关键.举个例子,我们假设处理一个业务请求平均响应时间为100ms,同时,系统内有20台Apache的Web服务器,配置MaxClients为500个(表示Apache的最大连接数目). 那么,我们的Web系统的理论峰值QPS为(理想化的计算方式): 20*500/0.1 = 100000 (10万QPS) 咦?我们的系统似乎很强大,1秒钟可以处理完10万的