Python3利用Dlib实现摄像头实时人脸检测和平铺显示示例
1. 引言
在某些场景下,我们不仅需要进行实时人脸检测追踪,还要进行再加工;这里进行摄像头实时人脸检测,并对于实时检测的人脸进行初步提取;
单个/多个人脸检测,并依次在摄像头窗口,实时平铺显示检测到的人脸;
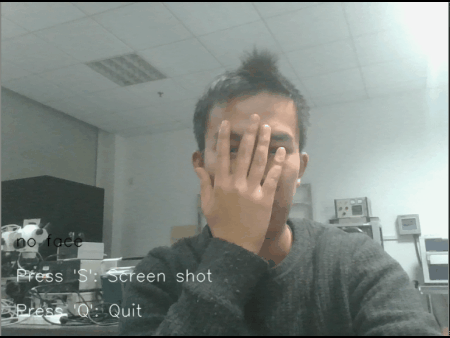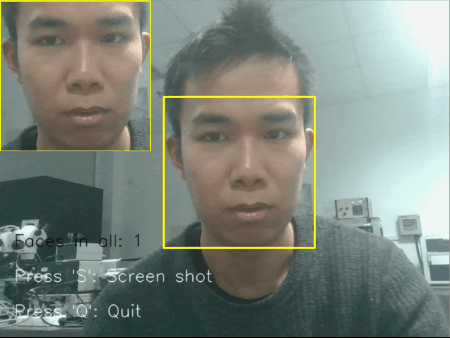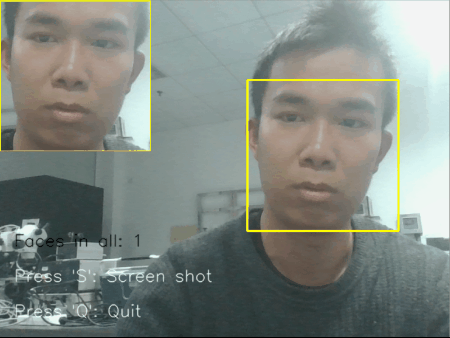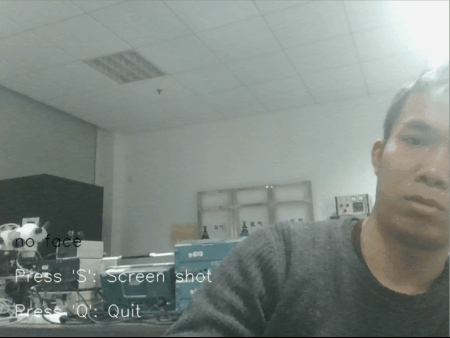
图 1 动态实时检测效果图
检测到的人脸矩形图像,会依次平铺显示在摄像头的左上方;
当多个人脸时候,也能够依次铺开显示;
左上角窗口的大小会根据捕获到的人脸大小实时变化;
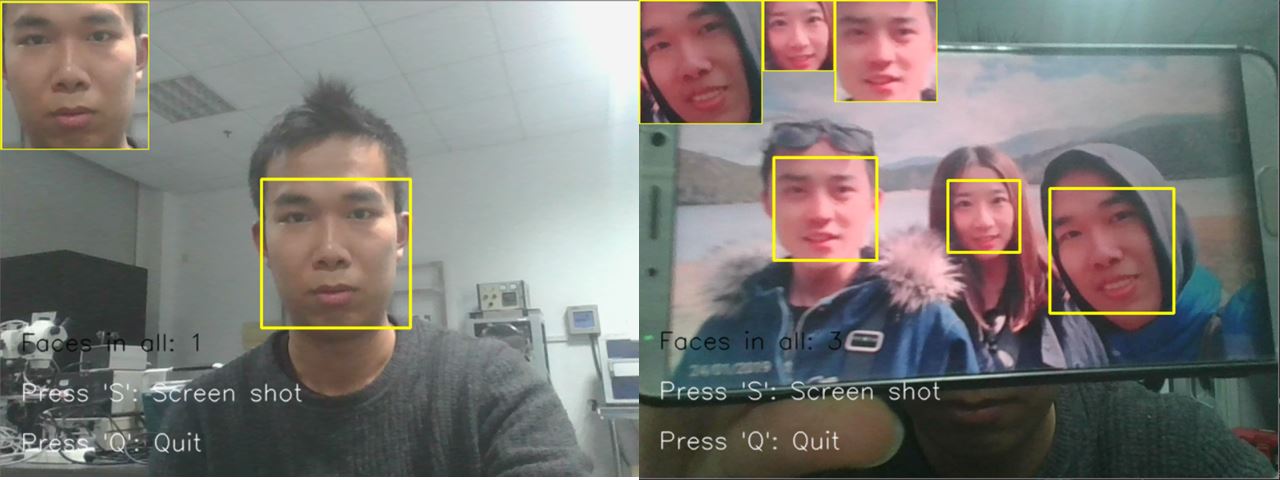
图 2 单个/多个人脸情况下摄像头识别显示结果
2. 代码实现
主要分为三个部分:
摄像头调用,利用 OpenCv 里面的cv2.VideoCapture();
人脸检测,这里利用开源的 Dlib 框架,Dlib 中人脸检测具体可以参考Python 3 利用 Dlib 19.7 进行人脸检测;
图像填充,剪切部分可以参考Python 3 利用 Dlib 实现人脸检测和剪切;
2.1 摄像头调用
Python 中利用 OpenCv 调用摄像头的一个例子how_to_use_camera.py:
# OpenCv 调用摄像头
# 默认调用笔记本摄像头
# Author: coneypo
# Blog: http://www.cnblogs.com/AdaminXie
# GitHub: https://github.com/coneypo/Dlib_face_cut
# Mail: coneypo@foxmail.com
import cv2
cap = cv2.VideoCapture(0)
# cap.set(propId, value)
# 设置视频参数: propId - 设置的视频参数, value - 设置的参数值
cap.set(3, 480)
# cap.isOpened() 返回 true/false, 检查摄像头初始化是否成功
print(cap.isOpened())
# cap.read()
"""
返回两个值
先返回一个布尔值, 如果视频读取正确, 则为 True, 如果错误, 则为 False;
也可用来判断是否到视频末尾;
再返回一个值, 为每一帧的图像, 该值是一个三维矩阵;
通用接收方法为:
ret,frame = cap.read();
ret: 布尔值;
frame: 图像的三维矩阵;
这样 ret 存储布尔值, frame 存储图像;
若使用一个变量来接收两个值, 如:
frame = cap.read()
则 frame 为一个元组, 原来使用 frame 处需更改为 frame[1]
"""
while cap.isOpened():
ret_flag, img_camera = cap.read()
cv2.imshow("camera", img_camera)
# 每帧数据延时 1ms, 延时为0, 读取的是静态帧
k = cv2.waitKey(1)
# 按下 's' 保存截图
if k == ord('s'):
cv2.imwrite("test.jpg", img_camera)
# 按下 'q' 退出
if k == ord('q'):
break
# 释放所有摄像头
cap.release()
# 删除建立的所有窗口
cv2.destroyAllWindows()
2.2 人脸检测
利用 Dlib 正向人脸检测器,dlib.get_frontal_face_detector();
对于本地人脸图像文件,一个利用 Dlib 进行人脸检测的例子:
face_detector_v2_use_opencv.py:
# created at 2017-11-27
# updated at 2018-09-06
# Author: coneypo
# Dlib: http://dlib.net/
# Blog: http://www.cnblogs.com/AdaminXie/
# Github: https://github.com/coneypo/Dlib_examples
# create object of OpenCv
# use OpenCv to read and show images
import dlib
import cv2
# 使用 Dlib 的正面人脸检测器 frontal_face_detector
detector = dlib.get_frontal_face_detector()
# 图片所在路径
# read image
img = cv2.imread("imgs/faces_2.jpeg")
# 使用 detector 检测器来检测图像中的人脸
# use detector of Dlib to detector faces
faces = detector(img, 1)
print("人脸数 / Faces in all: ", len(faces))
# Traversal every face
for i, d in enumerate(faces):
print("第", i+1, "个人脸的矩形框坐标:",
"left:", d.left(), "right:", d.right(), "top:", d.top(), "bottom:", d.bottom())
cv2.rectangle(img, tuple([d.left(), d.top()]), tuple([d.right(), d.bottom()]), (0, 255, 255), 2)
cv2.namedWindow("img", 2)
cv2.imshow("img", img)
cv2.waitKey(0)
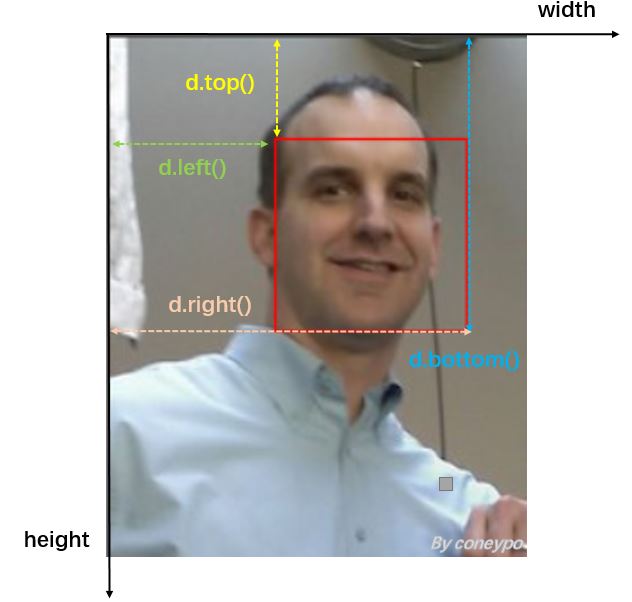
图 3 参数 d.top(), d.right(), d.left(), d.bottom() 位置坐标说明
2.3 图像裁剪
如果想访问图像的某点像素,对于 opencv 对象可以利用索引 img [height] [width]:
存储像素其实是一个三维数组,先高度 height,然后宽度 width;
返回的是一个颜色数组(0-255,0-255,0-255),按照(B,G,R)的顺序;
比如蓝色就是(255,0,0),红色是(0,0,255);
所以要做的就是对于检测到的人脸,要依次平铺填充到摄像头显示的实时帧 img_rd 中;
所以进行图像裁剪填充这块的代码如下(注意要防止截切平铺的图像不能超出 640x480 ):
# 检测到人脸
if len(faces) != 0:
# 记录每次开始写入人脸像素的宽度位置
faces_start_width = 0
for face in faces:
# 绘制矩形框
cv2.rectangle(img_rd, tuple([face.left(), face.top()]), tuple([face.right(), face.bottom()]),
(0, 255, 255), 2)
height = face.bottom() - face.top()
width = face.right() - face.left()
### 进行人脸裁减 ###
# 如果没有超出摄像头边界
if (face.bottom() < 480) and (face.right() < 640) and \
((face.top() + height) < 480) and ((face.left() + width) < 640):
# 填充
for i in range(height):
for j in range(width):
img_rd[i][faces_start_width + j] = \
img_rd[face.top() + i][face.left() + j]
# 更新 faces_start_width 的坐标
faces_start_width += width
记得要更新faces_start_width的坐标,达到依次平铺的效果:
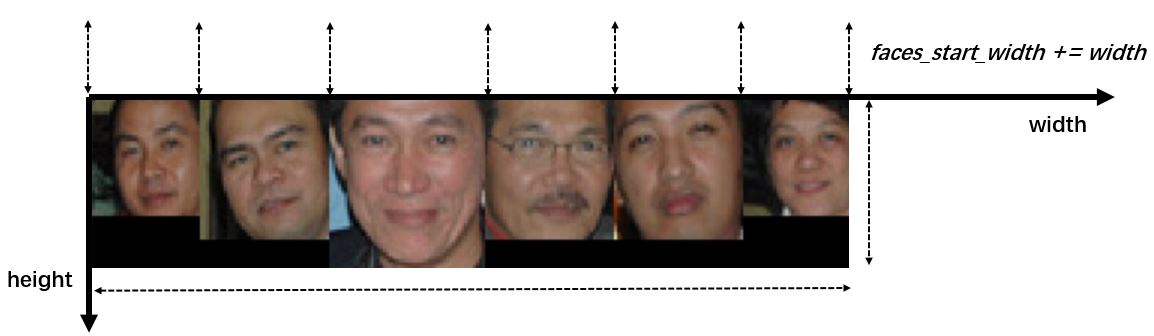
图 4 平铺显示的人脸
2.4. 完整源码
# 调用摄像头实时单个/多个人脸检测,并依次在摄像头窗口,实时平铺显示检测到的人脸;
# Author: coneypo
# Blog: http://www.cnblogs.com/AdaminXie
# GitHub: https://github.com/coneypo/Dlib_face_cut
import dlib
import cv2
import time
# 储存截图的目录
path_screenshots = "data/images/screenshots/"
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor('data/dlib/shape_predictor_68_face_landmarks.dat')
# 创建 cv2 摄像头对象
cap = cv2.VideoCapture(0)
# 设置视频参数,propId 设置的视频参数,value 设置的参数值
cap.set(3, 960)
# 截图 screenshots 的计数器
ss_cnt = 0
while cap.isOpened():
flag, img_rd = cap.read()
# 每帧数据延时 1ms,延时为 0 读取的是静态帧
k = cv2.waitKey(1)
# 取灰度
img_gray = cv2.cvtColor(img_rd, cv2.COLOR_RGB2GRAY)
# 人脸数
faces = detector(img_gray, 0)
# 待会要写的字体
font = cv2.FONT_HERSHEY_SIMPLEX
# 按下 'q' 键退出
if k == ord('q'):
break
else:
# 检测到人脸
if len(faces) != 0:
# 记录每次开始写入人脸像素的宽度位置
faces_start_width = 0
for face in faces:
# 绘制矩形框
cv2.rectangle(img_rd, tuple([face.left(), face.top()]), tuple([face.right(), face.bottom()]),
(0, 255, 255), 2)
height = face.bottom() - face.top()
width = face.right() - face.left()
### 进行人脸裁减 ###
# 如果没有超出摄像头边界
if (face.bottom() < 480) and (face.right() < 640) and \
((face.top() + height) < 480) and ((face.left() + width) < 640):
# 填充
for i in range(height):
for j in range(width):
img_rd[i][faces_start_width + j] = \
img_rd[face.top() + i][face.left() + j]
# 更新 faces_start_width 的坐标
faces_start_width += width
cv2.putText(img_rd, "Faces in all: " + str(len(faces)), (20, 350), font, 0.8, (0, 0, 0), 1, cv2.LINE_AA)
else:
# 没有检测到人脸
cv2.putText(img_rd, "no face", (20, 350), font, 0.8, (0, 0, 0), 1, cv2.LINE_AA)
# 添加说明
img_rd = cv2.putText(img_rd, "Press 'S': Screen shot", (20, 400), font, 0.8, (255, 255, 255), 1, cv2.LINE_AA)
img_rd = cv2.putText(img_rd, "Press 'Q': Quit", (20, 450), font, 0.8, (255, 255, 255), 1, cv2.LINE_AA)
# 按下 's' 键保存
if k == ord('s'):
ss_cnt += 1
print(path_screenshots + "screenshot" + "_" + str(ss_cnt) + "_" + time.strftime("%Y-%m-%d-%H-%M-%S",
time.localtime()) + ".jpg")
cv2.imwrite(path_screenshots + "screenshot" + "_" + str(ss_cnt) + "_" + time.strftime("%Y-%m-%d-%H-%M-%S",
time.localtime()) + ".jpg",
img_rd)
cv2.namedWindow("camera", 1)
cv2.imshow("camera", img_rd)
# 释放摄像头
cap.release()
# 删除建立的窗口
cv2.destroyAllWindows()
这个代码就是把之前做的人脸检测,图像拼接几个结合起来,代码量也很少,只有100行,如有问题可以参考之前博客:
Python 3 利用 Dlib 进行人脸检测
Python 3 利用 Dlib 实现人脸检测和剪切
人脸检测对于机器性能占用不高,但是如果要进行实时的图像裁剪拼接,计算量可能比较大,所以可能会出现卡顿;
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python+opencv+caffe+摄像头做目标检测的实例代码
首先之前已经成功的使用Python做图像的目标检测,这回因为项目最终是需要用摄像头的, 所以实现摄像头获取图像,并且用Python调用CAFFE接口来实现目标识别 首先是摄像头请选择支持Linux万能驱动兼容V4L2的摄像头, 因为之前用学ARM的时候使用的Smart210,我已经确认我的摄像头是支持的, 我把摄像头插上之後自然就在 /dev 目录下看到多了一个video0的文件, 这个就是摄像头的设备文件了,所以我就没有额外处理驱动的部分 一.检测环境 再来在开始前因为之前按着国嵌的指导手册安
-

树莓派+摄像头实现对移动物体的检测
在上一篇文章中实现了树莓派下对摄像头的调用,有兴趣的可以看一下:python+opencv实现摄像头调用的方法 接下来,我们将使用python+opencv实现对移动物体的检测 一.环境变量的配置 我们可以参照上一篇文章对我们的树莓派进行环境的配置 当我们将cv2的库安装之后,就可以实现对摄像头的操作 二.摄像头的连接 在此实验中,我使用的为usb摄像头 当我们连接摄像头之后,终端输入 ls /dev/video* 如果终端提示如下: 则表示摄像头连接成功 三.编码实现对移动物体的检测 使用py
-
Python OpenCV利用笔记本摄像头实现人脸检测
本文实例为大家分享了Python OpenCV利用笔记本摄像头实现人脸检测的具体代码,供大家参考,具体内容如下 1.安装opencv 首先参考其他文章安装pip. 之后以管理员身份运行命令提示符,输入以下代码安装opencv pip install --user opencv-python 可以使用以下代码测试安装是否成功 #导入opencv模块 import cv2 #捕捉帧,笔记本摄像头设置为0即可 capture = cv2.VideoCapture(0) #循环显示帧 while(Tru
-
Python3利用Dlib实现摄像头实时人脸检测和平铺显示示例
1. 引言 在某些场景下,我们不仅需要进行实时人脸检测追踪,还要进行再加工:这里进行摄像头实时人脸检测,并对于实时检测的人脸进行初步提取: 单个/多个人脸检测,并依次在摄像头窗口,实时平铺显示检测到的人脸: 图 1 动态实时检测效果图 检测到的人脸矩形图像,会依次平铺显示在摄像头的左上方: 当多个人脸时候,也能够依次铺开显示: 左上角窗口的大小会根据捕获到的人脸大小实时变化: 图 2 单个/多个人脸情况下摄像头识别显示结果 2. 代码实现 主要分为三个部分: 摄像头调用,利用 OpenCv 里面
-
Android 中使用 dlib+opencv 实现动态人脸检测功能
1 概述 完成 Android 相机预览功能以后,在此基础上我使用 dlib 与 opencv 库做了一个关于人脸检测的 demo.该 demo 在相机预览过程中对人脸进行实时检测,并将检测到的人脸用矩形框描绘出来.具体实现原理如下: 采用双层 View,底层的 TextureView 用于预览,程序从 TextureView 中获取预览帧数据,然后调用 dlib 库对帧数据进行处理,最后将检测结果绘制在顶层的 SurfaceView 中. 2 项目配置 由于项目中用到了 dlib 与 open
-
教你用YOLOv5实现多路摄像头实时目标检测功能
目录 前言 一.YOLOV5的强大之处 二.YOLOV5部署多路摄像头的web应用 1.多路摄像头读取 2.模型封装 3.Flask后端处理 4.前端展示 总结 前言 YOLOV5模型从发布到现在都是炙手可热的目标检测模型,被广泛运用于各大场景之中.因此,我们不光要知道如何进行yolov5模型的训练,而且还要知道怎么进行部署应用.在本篇博客中,我将利用yolov5模型简单的实现从摄像头端到web端的部署应用demo,为读者提供一些部署思路. 一.YOLOV5的强大之处 你与目标检测高手之差一个Y
-
Matlab控制电脑摄像实现实时人脸检测和识别详解
目录 一.理论基础 二.核心程序 三.仿真测试结果 一.理论基础 人脸识别过程主要由四个阶段组成:人脸检测.图像预处理.面部特征提取和特征识别.首先系统从视频或者相机中捕获图像,检测并分割出其中的人脸区域:接下来通过归一化.对齐.滤波等方法改善图像的质量,这里的质量主要由最终的人脸识别率决定:特征提取(降维)环节尤为重要,其初衷是减少数据量从而减轻计算负担,但良好的特征选取可以降低噪音和不相关数据在识别中的贡献度,从而提高识别精度:特征识别阶段需要根据提取的特征训练一个分类器,对于给定的测试样本
-
利用python打开摄像头及颜色检测方法
最近两周由于忙于个人项目,一直未发言了,实在是太荒凉了....,上周由于项目,见到Python的应用极为广泛,用起来也特别顺手,于是小编也开始着手学习Python,-下面我就汇报下今天的学习成果吧 小编运行环境unbuntu 14.0.4 首先我们先安装一下Python呗,我用的2.7,其实特别简单,一行指令就OK sudo apt-get install python-dev 一般安装系统的时候其实python已经自带了,这步基本可以不用做,OK,我们继续往下走吧,安装python-openc
-
python使用dlib进行人脸检测和关键点的示例
#!/usr/bin/env python # -*- coding:utf-8-*- # file: {NAME}.py # @author: jory.d # @contact: dangxusheng163@163.com # @time: 2020/04/10 19:42 # @desc: 使用dlib进行人脸检测和人脸关键点 import cv2 import numpy as np import glob import dlib FACE_DETECT_PATH = '/home/b
-
python利用opencv调用摄像头实现目标检测
目录 使用到的库 实现思路 实现代码 2020/4/26更新:FPS计算 FPS记录的原理 FPS实现代码 使用到的库 好多人都想了解一下如何对摄像头进行调用,然后进行目标检测,于是我做了这个小BLOG. opencv-python==4.1.2.30 Pillow==6.2.1 numpy==1.17.4 这些都是通用的库,版本不同问题应该也不大. 实现思路 利用opencv调用摄像头,读取每一帧传入目标检测网络检测,将检测结果呈现. 由于本文所用的检测格式为RGB格式,CV2读取的时候会使用
-
Python3.6.0+opencv3.3.0人脸检测示例
网上有很多关于Python+opencv人脸检测的例子,并大都附有源程序.但是在实际使用时依然会遇到这样或者那样的问题,在这里给出常见的两种问题及其解决方法. 先给出源代码:(如下) import cv2 import numpy as np cv2.namedWindow("test") cap=cv2.VideoCapture(0) success,frame=cap.read() classifier=cv2.CascadeClassifier("haarcascade
-
opencv+mediapipe实现人脸检测及摄像头实时示例
目录 单张人脸关键点检测 单张图像人脸检测 摄像头实时关键点检测 单张人脸关键点检测 定义可视化图像函数 导入三维人脸关键点检测模型 导入可视化函数和可视化样式 读取图像 将图像模型输入,获取预测结果 BGR转RGB 将RGB图像输入模型,获取预测结果 预测人人脸个数 可视化人脸关键点检测效果 绘制人来脸和重点区域轮廓线,返回annotated_image 绘制人脸轮廓.眼睫毛.眼眶.嘴唇 在三维坐标中分别可视化人脸网格.轮廓.瞳孔 import cv2 as cv import mediapi