彻底搞懂Python字符编码
不论你是有着多年经验的 Python 老司机还是刚入门 Python 不久,你一定遇到过UnicodeEncodeError、UnicodeDecodeError 错误,每当遇到错误我们就拿着 encode、decode 函数翻来覆去的转换,有时试着试着问题就解决了,有时候怎么试都没辙,只有借用 Google 大神帮忙,但似乎很少去关心问题的本质是什么,下次遇到类似的问题重蹈覆辙,那么你有没有想过一次性彻底把 Python 字符编码给搞懂呢?
完全理解字符编码 与 Python 的渊源前,我们有必要把一些基础概念弄清楚,虽然有些概念我们每天都在接触甚至在使用它,但并不一定真正理解它。比如:字节、字符、字符集、字符码、字符编码。
字节
字节(Byte)是计算机中数据存储的基本单元,一字节等于一个8位的比特,计算机中的所有数据,不论是保存在磁盘文件上的还是网络上传输的数据(文字、图片、视频、音频文件)都是由字节组成的。
字符
你正在阅读的这篇文章就是由很多个字符(Character)构成的,字符一个信息单位,它是各种文字和符号的统称,比如一个英文字母是一个字符,一个汉字是一个字符,一个标点符号也是一个字符。
字符集
字符集(Character Set)就是某个范围内字符的集合,不同的字符集规定了字符的个数,比如 ASCII 字符集总共有128个字符,包含了英文字母、阿拉伯数字、标点符号和控制符。而 GB2312 字符集定义了7445个字符,包含了绝大部分汉字字符。
字符码
字符码(Code Point)指的是字符集中每个字符的数字编号,例如 ASCII 字符集用 0-127 连续的128个数字分别表示128个字符,例如 "A" 的字符码编号就是65。
字符编码
字符编码(Character Encoding)是将字符集中的字符码映射为字节流的一种具体实现方案,常见的字符编码有 ASCII 编码、UTF-8 编码、GBK 编码等。某种意义上来说,字符集与字符编码有种对应关系,例如 ASCII 字符集对应 有 ASCII 编码。ASCII 字符编码规定使用单字节中低位的7个比特去编码所有的字符。例如"A" 的编号是65,用单字节表示就是0×41,因此写入存储设备的时候就是b'01000001'。
编码、解码
编码的过程是将字符转换成字节流,解码的过程是将字节流解析为字符。
理解了这些基本的术语概念后,我们就可以开始讨论计算机的字符编码的演进过程了。
从 ASCII 码说起
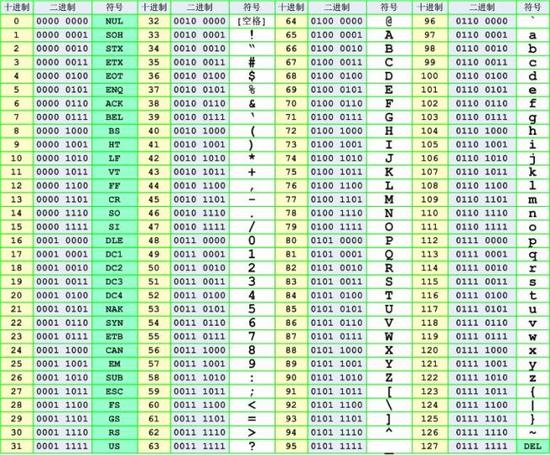
说到字符编码,要从计算机的诞生开始讲起,计算机发明于美国,在英语世界里,常用字符非常有限,26个字母(大小写)、10个数字、标点符号、控制符,这些字符在计算机中用一个字节的存储空间来表示绰绰有余,因为一个字节相当于8个比特位,8个比特位可以表示256个符号。于是美国国家标准协会ANSI制定了一套字符编码的标准叫 ASCII(American Standard Code for Information Interchange),每个字符都对应唯一的一个数字,比如字符 "A" 对应数字是65,"B" 对应 66,以此类推。最早 ASCII 只定义了128个字符编码,包括96个文字和32个控制符号,一共128个字符只需要一个字节的7位就能表示所有的字符,因此 ASCII 只使用了一个字节的后7位,剩下最高位1比特被用作一些通讯系统的奇偶校验。下图就是 ASCII 码字符编码的十进制、二进制和字符的对应关系表
扩展的 ASCII:EASCII(ISO/8859-1)
然而计算机慢慢地普及到其他西欧地区时,发现还有很多西欧字符是 ASCII 字符集中没有的,显然 ASCII 已经没法满足人们的需求了,好在 ASCII 字符只用了字节的7位 0×00~0x7F 共128个字符,于是他们在 ASCII 的基础上把原来的7位扩充到8位,把0×80-0xFF这后面的128个数字利用起来,叫 EASCII ,它完全兼容ASCII,扩展出来的符号包括表格符号、计算符号、希腊字母和特殊的拉丁符号。然而 EASCII 时代是一个混乱的时代,各个厂家都有自己的想法,大家没有统一标准,他们各自把最高位按照自己的标准实现了自己的一套字符编码标准,比较著名的就有 CP437 , CP437 是 始祖IBM PC、MS-DOS使用的字符编码,如下图:
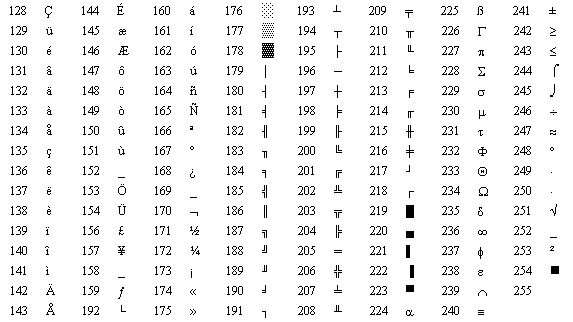
众多的 ASCII 扩充字符集之间互不兼容,这样导致人们无法正常交流,例如200在CP437字符集表示的字符是 È ,在 ISO/8859-1 字符集里面显示的就是 ╚,于是国际标准化组织(ISO)及国际电工委员会(IEC)联合制定的一系列8位字符集的标准 ISO/8859-1(Latin-1) ,它继承了 CP437 字符编码的128-159之间的字符,所以它是从160开始定义的,ISO-8859-1在 CP437 的基础上重新定义了 160~255之间的字符。

多字节字符编码 GBK
ASCII 字符编码是单字节编码,计算机进入中国后面临的一个问题是如何处理汉字,对于拉丁语系国家来说通过扩展最高位,单字节表示所有的字符已经绰绰有余,但是对于亚洲国家来说一个字节就显得捉襟见肘了。于是中国人自己弄了一套叫 GB2312 的双字节字符编码,又称GB0,1981 由中国国家标准总局发布。GB2312 编码共收录了6763个汉字,同时他还兼容 ASCII,GB 2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率,不过 GB2312 还是不能100%满足中国汉字的需求,对一些罕见的字和繁体字 GB2312 没法处理,后来就在GB2312的基础上创建了一种叫 GBK 的编码,GBK 不仅收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。同样 GBK 也是兼容 ASCII 编码的,对于英文字符用1个字节来表示,汉字用两个字节来标识。
Unicode 的问世
GBK仅仅只是解决了我们自己的问题,但是计算机不止是美国人和中国人用啊,还有欧洲、亚洲其他国家的文字诸如日文、韩文全世界各地的文字加起来估计也有好几十万,这已经大大超出了ASCII 码甚至GBK 所能表示的范围了,虽然各个国家可以制定自己的编码方案,但是数据在不同国家传输就会出现各种各样的乱码问题。如果只用一种字符编码就能表示地球甚至火星上任何一个字符时,问题就迎刃而解了。是它,是它,就是它,我们的小英雄,统一联盟国际组织提出了Unicode 编码,Unicode 的学名是"Universal Multiple-Octet Coded Character Set",简称为UCS。它为世界上每一种语言的每一个字符定义了一个唯一的字符码,Unicode 标准使用十六进制数字表示,数字前面加上前缀 U+,比如字母『A』的Unicode编码是 U+0041,汉字『中』的Unicode 编码是U+4E2D
Unicode有两种格式:UCS-2和UCS-4。UCS-2就是用两个字节编码,一共16个比特位,这样理论上最多可以表示65536个字符,不过要表示全世界所有的字符显示65536个数字还远远不过,因为光汉字就有近10万个,因此Unicode4.0规范定义了一组附加的字符编码,UCS-4就是用4个字节(实际上只用了31位,最高位必须为0)。理论上完全可以涵盖一切语言所用的符号。
Unicode 的局限
但是 Unicode 有一定的局限性,一个 Unicode 字符在网络上传输或者最终存储起来的时候,并不见得每个字符都需要两个字节,比如字符“A“,用一个字节就可以表示的字符,偏偏还要用两个字节,显然太浪费空间了。
第二问题是,一个 Unicode 字符保存到计算机里面时就是一串01数字,那么计算机怎么知道一个2字节的Unicode字符是表示一个2字节的字符呢,例如“汉”字的 Unicode 编码是 U+6C49,我可以用4个ascii数字来传输、保存这个字符;也可以用utf-8编码的3个连续的字节E6 B1 89来表示它。关键在于通信双方都要认可。因此Unicode编码有不同的实现方式,比如:UTF-8、UTF-16等等。Unicode就像英语一样,做为国与国之间交流世界通用的标准,每个国家有自己的语言,他们把标准的英文文档翻译成自己国家的文字,这是实现方式,就像utf-8。
具体实现:UTF-8
UTF-8(Unicode Transformation Format)作为 Unicode 的一种实现方式,广泛应用于互联网,它是一种变长的字符编码,可以根据具体情况用1-4个字节来表示一个字符。比如英文字符这些原本就可以用 ASCII 码表示的字符用UTF-8表示时就只需要一个字节的空间,和 ASCII 是一样的。对于多字节(n个字节)的字符,第一个字节的前n为都设为1,第n+1位设为0,后面字节的前两位都设为10。剩下的二进制位全部用该字符的unicode码填充。
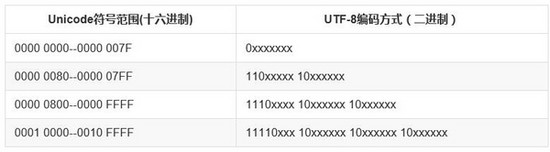
以『好』为例,『好』对应的 Unicode 是597D,对应的区间是 0000 0800--0000 FFFF,因此它用 UTF-8 表示时需要用3个字节来存储,597D用二进制表示是: 0101100101111101,填充到 1110xxxx 10xxxxxx 10xxxxxx 得到 11100101 10100101 10111101,转换成16进制是 e5a5bd,因此『好』的 Unicode 码 U+597D 对应的 UTF-8 编码是 "E5A5BD"。你可以用 Python 代码来验证:
>>> a = u"好"
>>> a
u'\u597d'
>>> b = a.encode('utf-8')
>>> len(b)
3
>>> b
'\xe5\xa5\xbd'
现在总算把理论说完了。再来说说 Python 中的编码问题。Python 的诞生时间比 Unicode 要早很多,Python2 的默认编码是ASCII,正因为如此,才导致很多的编码问题。
>>> import sys >>> sys.getdefaultencoding() 'ascii'
所以在 Python2 中,源代码文件必须显示地指定编码类型,否则但凡代码中出现有中文就会报语法错误
# coding=utf-8 或者是: # -*- coding: utf-8 -*-
Python2 字符类型
在 python2 中和字符串相关的数据类型有 str 和 unicode 两种类型,它们继承自 basestring,而 str 类型的字符串的编码格式可以是 ascii、utf-8、gbk等任何一种类型。
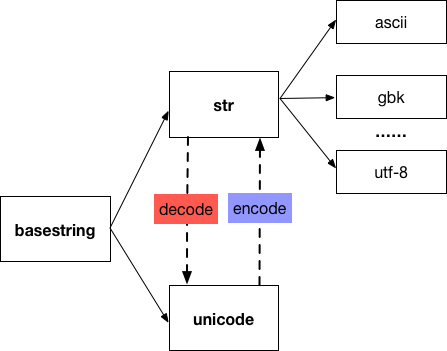
对于汉字『好』,用 str 表示时,它对应的 utf-8 编码 是'\xe5\xa5\xbd',对应的 gbk 编码是 '\xba\xc3',而用 unicode 表示时,他对应的符号就是u'\u597d',与u"好" 是等同的。
str 与 unicode 的转换
在 Python 中 str 和 unicode 之间是如何转换的呢?这两种类型的字符串之间的转换就是靠decode 和 encode 这两个函数。encode 负责将unicode 编码成指定的字符编码,用于存储到磁盘或传输到网络中。而 decode 方法是根据指定的编码方式解码后在应用程序中使用。
#从unicode转换到str用 encode
>>> b = u'好'
>>> c = b.encode('utf-8')
>>> type(c)
<type 'str'>
>>> c
'\xe5\xa5\xbd'
#从str类型转换到unicode用decode
>>> d = c.decode('utf-8')
>>> type(d)
<type 'unicode'>
>>> d
u'\u597d'
UnicodeXXXError 错误的原因
在字符编码转换操作时,遇到最多的问题就是 UnicodeEncodeError 和 UnicodeDecodeError 错误了,这些错误的根本原因在于 Python2 默认是使用 ascii 编码进行 decode 和 encode 操作,例如:
case 1
>>> s = '你好' >>> s.decode() Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
当把 s 转换成 unicode 类型的字符串时,decode 方法默认使用 ascii 编码进行解码,而 ascii 字符集中根本就没有中文字符『你好』,所以就出现了 UnicodeDecodeError,正确的方式是显示地指定 UTF-8 字符编码。
>>> s.decode('utf-8')
u'\u4f60\u597d'
同样地道理,对于 encode 操作,把 unicode字符串转换成 str类型的字符串时,默认也是使用 ascii 编码进行编码转换的,而 ascii 字符集找不到中文字符『你好』,于是就出现了UnicodeEncodeError 错误。
>>> a = u'你好' >>> a.encode() Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
case 2
str 类型与 unicode 类型的字符串混合使用时,str 类型的字符串会隐式地将 str 转换成 unicode字符串,如果 str字符串是中文字符,那么就会出现UnicodeDecodeError 错误,因为 python2 默认会使用 ascii 编码来进行 decode 操作。
>>> s = '你好' # str类型
>>> y = u'python' # unicode类型
>>> s + y # 隐式转换,即 s.decode('ascii') + u
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
正确地方式是显示地指定 UTF-8 字符编码进行解码
>>> s.decode('utf-8') +y
u'\u4f60\u597dpython'
乱码
所有出现乱码的原因都可以归结为字符经过不同编码解码在编码的过程中使用的编码格式不一致,比如:
# encoding: utf-8
>>> a='好'
>>> a
'\xe5\xa5\xbd'
>>> b=a.decode("utf-8")
>>> b
u'\u597d'
>>> c=b.encode("gbk")
>>> c
'\xba\xc3'
>>> print c
utf-8编码的字符‘好'占用3个字节,解码成Unicode后,如果再用gbk来解码后,只有2个字节的长度了,最后出现了乱码的问题,因此防止乱码的最好方式就是始终坚持使用同一种编码格式对字符进行编码和解码操作。

总结
以上所述是小编给大家介绍的Python字符编码,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
您可能感兴趣的文章:
- 跟老齐学Python之坑爹的字符编码
- Python中字符编码简介、方法及使用建议
- 在Python中使用base64模块处理字符编码的教程
- Python使用chardet判断字符编码
- Python获取系统默认字符编码的方法
- Python3如何解决字符编码问题详解
相关推荐
-

Python3如何解决字符编码问题详解
编码 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节.比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295. 由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母.数字和一些符号,这个编码表被称为ASC
-
在Python中使用base64模块处理字符编码的教程
Base64是一种用64个字符来表示任意二进制数据的方法. 用记事本打开exe.jpg.pdf这些文件时,我们都会看到一大堆乱码,因为二进制文件包含很多无法显示和打印的字符,所以,如果要让记事本这样的文本处理软件能处理二进制数据,就需要一个二进制到字符串的转换方法.Base64是一种最常见的二进制编码方法. Base64的原理很简单,首先,准备一个包含64个字符的数组: ['A', 'B', 'C', ... 'a', 'b', 'c', ... '0', '1', ... '+', '/']
-
Python中字符编码简介、方法及使用建议
1. 字符编码简介 1.1. ASCII ASCII(American Standard Code for Information Interchange),是一种单字节的编码.计算机世界里一开始只有英文,而单字节可以表示256个不同的字符,可以表示所有的英文字符和许多的控制符号.不过ASCII只用到了其中的一半(\x80以下),这也是MBCS得以实现的基础. 1.2. MBCS 然而计算机世界里很快就有了其他语言,单字节的ASCII已无法满足需求.后来每个语言就制定了一套自己的编码,由于单字节
-
Python获取系统默认字符编码的方法
本文实例讲述了Python获取系统默认字符编码的方法.分享给大家供大家参考.具体分析如下: 在Python代码中,普通字符串的编码方式与程序源文件编码方式一致的,而很多IDE在默认情况下,将程序源文件按照系统默认字符编码来保存的. 下面给出用Python获取系统默认编码的例子: #!/usr/bin/env python #coding=utf-8 """ 获取系统默认编码 """ import sys print sys.getdefaulte
-
跟老齐学Python之坑爹的字符编码
字符编码,在编程中,是一个让学习者比较郁闷的东西,比如一个str,如果都是英文,好说多了.但恰恰不是如此,中文是我们不得不用的.所以,哪怕是初学者,都要了解并能够解决字符编码问题. >>> name = '老齐' >>> name '\xe8\x80\x81\xe9\xbd\x90' 在你的编程中,你遇到过上面的情形吗?认识最下面一行打印出来的东西吗?看人家英文,就好多了 >>> name = "qiwsir" >>&g
-
Python使用chardet判断字符编码
本文实例讲述了Python使用chardet判断字符编码的方法.分享给大家供大家参考.具体分析如下: Python中chardet 用来实现字符串/文件编码检测模板 1.chardet下载与安装 下载地址:http://pypi.python.org/pypi/chardet 下载chardet后,解压chardet压缩包,直接将chardet文件夹放在应用程序目录下,就可以使用import chardet开始使用chardet了,也可以将chardet拷贝到Python系统目录下,这样你所有的
-
彻底搞懂Python字符编码
不论你是有着多年经验的 Python 老司机还是刚入门 Python 不久,你一定遇到过UnicodeEncodeError.UnicodeDecodeError 错误,每当遇到错误我们就拿着 encode.decode 函数翻来覆去的转换,有时试着试着问题就解决了,有时候怎么试都没辙,只有借用 Google 大神帮忙,但似乎很少去关心问题的本质是什么,下次遇到类似的问题重蹈覆辙,那么你有没有想过一次性彻底把 Python 字符编码给搞懂呢? 完全理解字符编码 与 Python 的渊源前,我们有
-
一篇文章彻底弄懂Python字符编码
目录 1. 字符编码简介 1.1. ASCII 1.2. MBCS 1.3. Unicode 2. Python2.x中的编码问题 2.1. str和unicode 2.2. 字符编码声明 2.3. 读写文件 2.4. 与编码相关的方法 3.建议 3.1.字符编码声明 3.2. 抛弃str,全部使用unicode. 3.3. 使用codecs.open()替代内置的open(). 3.4. 绝对需要避免使用的字符编码:MBCS/DBCS和UTF-16. 1. 字符编码简介 1.1. ASCII
-
彻底搞懂 python 中文乱码问题(深入分析)
前言 曾几何时 Python 中文乱码的问题困扰了我很多很多年,每次出现中文乱码都要去网上搜索答案,虽然解决了当时遇到的问题但下次出现乱码的时候又会懵逼,究其原因还是知其然不知其所以然.现在有的小伙伴为了躲避中文乱码的问题甚至代码中不使用中文,注释和提示都用英文,我曾经也这样干过,但这并不是解决问题,而是逃避问题,今天我们一起彻底解决 Python 中文乱码的问题. 基础知识ASCII 很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物.他们看到8个开关
-
一篇文章搞懂Python反斜杠的相关问题
大家在开发Python的过程中,一定会遇到很多反斜杠的问题,很多人被反斜杠的数量搞得头大. 首先我们写一段非常简单的Python代码,它的作用是把一个字段先转换为JSON格式的字符串,然后把这个字符串再转换为JSON格式的字符串: import json info = {'name': 'kingname', 'address': '杭州', 'salary': 99999} info_json = json.dumps(info) # 第一次转换以后,打印出来 print(info_json)
-
Python字符编码与函数的基本使用方法
一.Python2中的字符存在的解码编码问题 如果是现在正在用Python2的人应该都知道存在字符编码问题,就举一个最简单的例子吧:Python2是无法在命令行直接打印中文的,当然他也是不会报错的,顶多是一堆你看不懂的乱码.如果想在直接显示中文,我们是可以在Python2文件头部申明字符编码的格式.如下图 这里 #-*-coding:utf-8 -*- 是用来申明下面的代码是用什么编码来解释: 1.1.Python2中的解码和编码: 在编码和解码的世界中,我们得需要找一个大家都知道的文字.也可以
-
一篇文章搞懂python的转义字符及用法
什么是转义字符 转义字符是一个计算机专业词汇.在计算机当中,我们可以写出123 ,也可以写出字母abcd,但有些字符我们无法手动书写,比如我们需要对字符进行换行处理,但不能写出来换行符,当然我们也看不见换行符.像这种情况,我们需要在字符中使用特殊字符时,就需要用到转义字符,在python里用反斜杠\转义字符. 在交互式解释器中,输出的字符串用引号引起来,特殊字符用反斜杠\转义.虽然可能和输入看上去不太一样,但是两个字符串是相等的. 在python里,转义字符\可以转义很多字符,比如\n表示换行,
-
一文搞懂Python Sklearn库使用
目录 1.LabelEncoder 2.OneHotEncoder 3.sklearn.model_selection.train_test_split随机划分训练集和测试集 4.pipeline 5 perdict 直接返回预测值 6 sklearn.metrics中的评估方法 7 GridSearchCV 8 StandardScaler 9 PolynomialFeatures 4.10+款机器学习算法对比 4.1 生成数据 4.2 八款主流机器学习模型 4.3 树模型 - 随机森林 4.
-
一文带你搞懂Python中的文件操作
目录 一.文件的编码 二.文件的读取 2.1 open()打开函数 2.2 mode常用的三种基础访问模式 2.3 读操作相关方法 三.文件的写入 写操作快速入门 四.文件的追加 追加写入操作快速入门 五.文件操作综合案例 一.文件的编码 计算机中有许多可用编码: UTF-8 GBK Big5 等 UTF-8是目前全球通用的编码格式 除非有特殊需求,否则,一律以UTF-8格式进行文件编码即可. 二.文件的读取 2.1 open()打开函数 注意:此时的f是open函数的文件对象,对象是Pytho
-
一文搞懂Python中subprocess模块的使用
目录 简介 常用方法和接口 subprocess.run()解析 subprocess.Popen()解析 Popen 对象方法 subprocess.run()案例 subprocess.call()案例 subprocess.check_call()案例 subprocess.getstatusoutput()案例 subprocess.getoutput()案例 subprocess.check_output()案例 subprocess.Popen()综合案例 简介 subprocess
-
快速入手Python字符编码
前言 对于很多接触Python的人而言,字符的处理和语言整体的温顺可靠相比显得格外桀骜不驯难以驾驭. 文章针对Python 2.7,主要因为3对的编码已经有了很大的改善并且实际原理一样,更改一下操作命令即可. 了解完本文,你可以轻松解决文字处理,特殊平台(Windows?)下的编码,爬虫编码等问题. 阅读建议 本文分为如下几个部分: 1.原理 2.具体操作 3.建议的使用习惯 4.疑难问题解答 如果想要了解我给出的使用习惯,可以直接跳到建议的使用习惯. 如果只想要解决相关问题可以直接跳到疑难问题