详解Python安装scrapy的正确姿势
运行平台:Windows
Python版本:Python3.x
IDE:Sublime text3
一、Scrapy简介
Scrapy是一个为了爬取网站数据提取结构性数据而编写的应用框架,可以应用于数据挖掘,信息处理或存储历史数据等一些列的程序中。Scrapy最初就是为了网络爬取而设计的。现在,Scrapy已经推出了曾承诺过的Python3.x版本。
为什么学习Scrapy呢?它能我们更好的完成爬虫任务,自己写Python爬虫程序好比孤军奋战,而使用了Scrapy就好比手底下有了千军万马。Scrapy可以起到事半功倍(甚至好几倍*.*)的效果。所以,学习Scrapy也就显得很有必要了。
二、Scrapy安装
1.直接使用指令pip3 install scrapy,发现有诸多错误。
- Failed building wheel for lxml
- Microsoft Visual C++ 10.0 is required
- Failed building twisted
- Unable to find vcvarsall.bat
遇到的错误,如下图所示:



2.解决办法
(1)在cmd中输入指令python,查看python的版本,如下:

从上图可以看出可以看出我的Python版本为Python3.5.2-64bit。
(2)登陆http://www.lfd.uci.edu/~gohlke/pythonlibs/,Ctrl+F搜索Lxml、Twisted、Scrapy,下载对应的版本,例如:lxml-3.7.3-cp35-cp35m-win_adm64.whl,表示lxml的版本为3.7.3,对应的python版本为3.5-64bit。我下载的版本如下图所示:
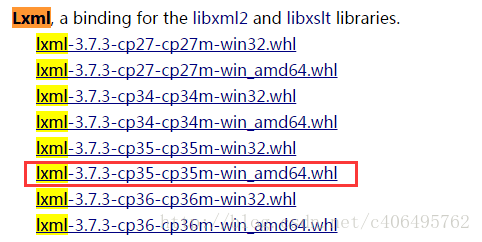
在cmd中输入DOS指令,进入下载好的whl文件夹下,例如我的三个whl文件放在了Scrapy文件夹下:

(4)依次执行如下命令:
a.pip3 install wheel

b.pip3 install lxml-3.7.3-cp35-cp35m-win_amd64.whl

c.pip3 install Twisted-17.1.0-cp35-cp35m-win_amd64.whl

d.pip3 install Scrapy-1.3.2-py2.py3-none-any.whl

这样Scrapy的安装就完成了,请忽略最后两行让我升级pip的信息。*.*
(5)Srapy已经安装成功,还要下载pywin32,找到对应版本下载,一路下一步安装即可。安装完成后,就可以正常使用Scrapy了。
URL:https://sourceforge.net/projects/pywin32/files/pywin32/Build%20220/

至此,大功告成,我们可以愉快的使用Scrapy了。
总结
以上所述是小编给大家介绍的Python安装scrapy的正确姿势,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-

基于python框架Scrapy爬取自己的博客内容过程详解
前言 python中常用的写爬虫的库常有urllib2.requests,对于大多数比较简单的场景或者以学习为目的,可以用这两个库实现.这里有一篇我之前写过的用urllib2+BeautifulSoup做的一个抓取百度音乐热门歌曲的例子,有兴趣可以看一下. 本文介绍用Scrapy抓取我在博客园的博客列表,只抓取博客名称.发布日期.阅读量和评论量这四个简单的字段,以求用较简单的示例说明Scrapy的最基本的用法. 环境配置说明 操作系统:Ubuntu 14.04.2 LTS Python:Pyth
-
Python使用Scrapy爬虫框架全站爬取图片并保存本地的实现代码
大家可以在Github上clone全部源码. Github:https://github.com/williamzxl/Scrapy_CrawlMeiziTu Scrapy官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html 基本上按照文档的流程走一遍就基本会用了. Step1: 在开始爬取之前,必须创建一个新的Scrapy项目. 进入打算存储代码的目录中,运行下列命令: scrapy startproject CrawlMe
-
详解python3 + Scrapy爬虫学习之创建项目
最近准备做一个关于scrapy框架的实战,爬取腾讯社招信息并存储,这篇博客记录一下创建项目的步骤 pycharm是无法创建一个scrapy项目的 因此,我们需要用命令行的方法新建一个scrapy项目 请确保已经安装了scrapy,twisted,pypiwin32 一:进入你所需要的路径,这个路径存储你创建的项目 我的将放在E盘的Scrapy目录下 二:创建项目:scrapy startproject ***(这个是项目名) 这样就创建好了一个名为tencent的项目 三:进入项目新建一个爬虫:
-
Python3安装Scrapy的方法步骤
本文介绍了Python3安装Scrapy的方法步骤,分享给大家,具体如下: 运行平台:Windows Python版本:Python3.x IDE:Sublime text3 一.Scrapy简介 Scrapy是一个为了爬取网站数据提取结构性数据而编写的应用框架,可以应用于数据挖掘,信息处理或存储历史数据等一些列的程序中.Scrapy最初就是为了网络爬取而设计的.现在,Scrapy已经推出了曾承诺过的Python3.x版本. 为什么学习Scrapy呢?它能我们更好的完成爬虫任务,自己写Pytho
-
浅析python实现scrapy定时执行爬虫
项目需要程序能够放在超算中心定时运行,于是针对scrapy写了一个定时爬虫的程序main.py ,直接放在scrapy的存储代码的目录中就能设定时间定时多次执行. 最简单的方法:直接使用Timer类 import time import os while True: os.system("scrapy crawl News") time.sleep(86400) #每隔一天运行一次 24*60*60=86400s或者,使用标准库的sched模块 import sched #初始化sch
-
Python3环境安装Scrapy爬虫框架过程及常见错误
Windows •安装lxml 最好的安装方式是通过wheel文件来安装,http://www.lfd.uci.edu/~gohlke/pythonlibs/,从该网站找到lxml的相关文件.假如是Python3.5版本,WIndows 64位系统,那就找到lxml‑3.7.2‑cp35‑cp35m‑win_amd64.whl 这个文件并下载,然后通过pip安装. 下载之后,运行如下命令安装: pip3 install wheel pip3 install lxml‑3.7.2‑cp35‑cp3
-
详解Python安装scrapy的正确姿势
运行平台:Windows Python版本:Python3.x IDE:Sublime text3 一.Scrapy简介 Scrapy是一个为了爬取网站数据提取结构性数据而编写的应用框架,可以应用于数据挖掘,信息处理或存储历史数据等一些列的程序中.Scrapy最初就是为了网络爬取而设计的.现在,Scrapy已经推出了曾承诺过的Python3.x版本. 为什么学习Scrapy呢?它能我们更好的完成爬虫任务,自己写Python爬虫程序好比孤军奋战,而使用了Scrapy就好比手底下有了千军万马.Scr
-
图文详解python安装Scrapy框架步骤
python书写爬虫的一个框架,它也提供了多种类型爬虫的基类,scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 首先要先安装python 安装完成以后,配置一下环境变量. 还需要安装一些组件pywin32,百度搜索下载安装 pywin32安装完成还要安转pip,百度搜索pip下载下来,解压通过cmd命令进行安装 我查看一下pip是否安装成功 执行pip install Scrapy进行安装Scrapy 测试一下Scrapy框架是否安装成功,不报错就说明安装成功了
-
详解python安装matplotlib库三种失败情况
(可能只有最后一句命令有用,可能全篇都没用) (小白方法,可能只适用于本人情况) 安装matplotlib时,出现的三种失败情况 1.read timed out 一开始我在pycharm终端使用pip install matplotlib时,出现的是下图所示情况,大致情况是安装时间太长,所以当时我用了清华镜像,将原来的命令改成了pip install -i https://mirrors.ustc.edu.cn/pypi/web/simple/ matplotlib,速度是上来了,但是还是安装
-
详解ubuntu安装opencv的正确方法
本文介绍的是如何安装ubuntu下C++接口的opencv 1.安装准备: 1.1安装cmake sudo apt-get install cmake 1.2依赖环境 sudo apt-get install build-essential libgtk2.0-dev libavcodec-dev libavformat-dev libjpeg-dev libswscale-dev libtiff5-dev sudo apt-get install libgtk2.0-dev sudo apt-
-
详解Python之Scrapy爬虫教程NBA球员数据存放到Mysql数据库
获取要爬取的URL 爬虫前期工作 用Pycharm打开项目开始写爬虫文件 字段文件items # Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class NbaprojectItem(scrapy.Item): # define the fields for yo
-
详解Python安装tesserocr遇到的各种问题及解决办法
Tesseract的安装及配置 在Python爬虫过程中,难免遇到各种各样的验证码问题,最简单的就是这种验证码了,那么在遇到验证码的时候该怎么办呢?我们就需要OCR技术了,OCR-即Optical Character Recognition光学字符识别,是指通过扫描字符,然后将其形状翻译成电子文本的过程.而tesserocr是Python的一个OCR识别库,所以在安装tesserocr之前,我们需要安装tesseract这个东西 下载地址:https://digi.bib.uni-mannhe
-
详解python环境安装selenium和手动下载安装selenium的方法
方法1:cmd环境下,用pip install selenium 可能会很慢 方法2:下载selenium安装包手动安装 下载地址:https://pypi.org/project/selenium/ 选择扩展名为gz的源码包进行下载 下载后解压,cmd环境进入到setup.py文件所在目录 运行 python setup.py install命令进行安装 安装完后用pip list可看到selenium的信息 此时就可以用import selenium引入selenium包了 到此这篇关于详解
-
详解Python的爬虫框架 Scrapy
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻量级的,简单轻巧,并且使用起来非常的方便. 一.概述 下图显示了Scrapy的大体架构,其中包含了它的主要组件及系统的数据处理流程(绿色箭头所示).下面就来一个个解释每个组件的作用及数据的处理过程(注:图片来自互联网). 二.组件 1.Scrapy Engine(Scrapy引擎) Scrapy引擎
-
详解Python遍历列表时删除元素的正确做法
一.问题描述 这是在工作中遇到的一段代码,原理大概和下面类似(判断某一个元素是否符合要求,不符合删除该元素,最后得到符合要求的列表): a = [1,2,3,4,5,6,7,8] for i in a: if i>5: pass else: a.remove(i) print(a) 运行结果: 二.问题分析 因为删除元素后,整个列表的元素会往前移动,而i却是在最初就已经确定了,是不断增大的,所以并不能得到想要的结果. 三.解决方法 1.遍历在新的列表操作,删除是在原来的列表操作 a = [1,2
-
详解Python Flask框架的安装及应用
目录 1.安装 1.1 创建虚拟环境 1.2 进入虚拟环境 1.3 安装 flask 2.上手 2.1 最小 Demo 2.2 基本知识 3.解构官网指导 Demo 3.1 克隆与代码架构分析 3.2 入口文件 init.py 3.3 数据库设置 3.4 蓝图和视图 4.其他 5.跑起 DEMO 1.安装 1.1 创建虚拟环境 mkdir myproject cd myproject python3 -m venv venv 1.2 进入虚拟环境 . venv/bin/activate 1.3