深入讲解MySQL Innodb索引的原理
引言
回想四年前,我在学习mysql的索引这块的时候,老师在讲索引的时候,是像下面这么说的
索引就像一本书的目录。而当用户通过索引查找数据时,就好比用户通过目录查询某章节的某个知识点。这样就帮助用户有效地提高了查找速度。所以,使用索引可以有效地提高数据库系统的整体性能。
嗯,这么说其实也对。但是呢,大家看完这种说法,其实可能还是觉得太抽象了!因此呢,我还想再深入的细说一下,所以就有了此文!
需要说明的是,我说的内容只在Mysql的Innodb引擎中是成立的。在Sql Server、oracle、Mysql的Mysiam引擎中的正确性,不一定成立!
InnoDB是 MySQL最常用的存储引擎,了解InnoDB存储引擎的索引对于日常工作有很大的益处,索引的存在便是为了加速数据库行记录的检索。
什么是索引?
索引(index)翻译为一个目录,用于快速定位我们想要找的数据的位置。例如:我们把一个数据库比作一本书,而索引(index)就是书中的目录,此刻要找到书的某个感兴趣的内容,我们一般是不会整本书翻完再去确认该内容在哪里,而是通过书的目录,定位到该内容章节所在页数,最后直接翻到该页面。
我们来看看在数据库中的索引:
全表扫描 VS 索引扫描
以字典为例,全表扫描就是如果我们查找某个字时,那么通读一遍新华字典,然后找到我们想要找到的字,而跟全表扫描相对应的就是索引查找,索引查找就是在表的索引部分找到我们想要找的数据具体位置,然后会到表里面将我们想要找的数据全部查出。
OK,废话不多说,开始啰嗦!
正文
索引的科普
先引进聚簇索引和非聚簇索引的概念!
我们平时在使用的Mysql中,使用下述语句
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name [USING index_type] ON tbl_name (index_col_name,...) index_col_name: col_name [(length)] [ASC | DESC]
创建的索引,如复合索引、前缀索引、唯一索引,都是属于非聚簇索引,在有的书籍中,又将其称为辅助索引(secondary index)。在后文中,我们称其为非聚簇索引,其数据结构为B+树。
那么,这个聚簇索引,在Mysql中是没有语句来另外生成的。在Innodb中,Mysql中的数据是按照主键的顺序来存放的。那么聚簇索引就是按照每张表的主键来构造一颗B+树,叶子节点存放的就是整张表的行数据。由于表里的数据只能按照一颗B+树排序,因此一张表只能有一个聚簇索引。
在Innodb中,聚簇索引默认就是主键索引。
这个时候,机智的读者,应该要问我
如果我的表没建主键呢?
回答是,如果没有主键,则按照下列规则来建聚簇索引
没有主键时,会用一个唯一且不为空的索引列做为主键,成为此表的聚簇索引如果没有这样的索引,InnoDB会隐式定义一个主键来作为聚簇索引。
ps:大家还记得,自增主键和uuid作为主键的区别么?由于主键使用了聚簇索引,如果主键是自增id,,那么对应的数据一定也是相邻地存放在磁盘上的,写入性能比较高。如果是uuid的形式,频繁的插入会使innodb频繁地移动磁盘块,写入性能就比较低了。
索引原理介绍
先来一张带主键的表,如下所示,pId是主键
| pId | name | birthday |
|---|---|---|
| 5 | zhangsan | 2016-10-02 |
| 8 | lisi | 2015-10-04 |
| 11 | wangwu | 2016-09-02 |
| 13 | zhaoliu | 2015-10-07 |
画出该表的结构图如下

如上图所示,分为上下两个部分,上半部分是由主键形成的B+树,下半部分就是磁盘上真实的数据!那么,当我们, 执行下面的语句
select * from table where pId='11'
那么,执行过程如下

如上图所示,从根开始,经过3次查找,就可以找到真实数据。如果不使用索引,那就要在磁盘上,进行逐行扫描,直到找到数据位置。显然,使用索引速度会快。但是在写入数据的时候,需要维护这颗B+树的结构,因此写入性能会下降!
OK,接下来引入非聚簇索引!我们执行下面的语句
create index index_name on table(name);
此时结构图如下所示

大家注意看,会根据你的索引字段生成一颗新的B+树。因此, 我们每加一个索引,就会增加表的体积, 占用磁盘存储空间。然而,注意看叶子节点,非聚簇索引的叶子节点并不是真实数据,它的叶子节点依然是索引节点,存放的是该索引字段的值以及对应的主键索引(聚簇索引)。
如果我们执行下列语句
select * from table where name='lisi'
此时结构图如下所示
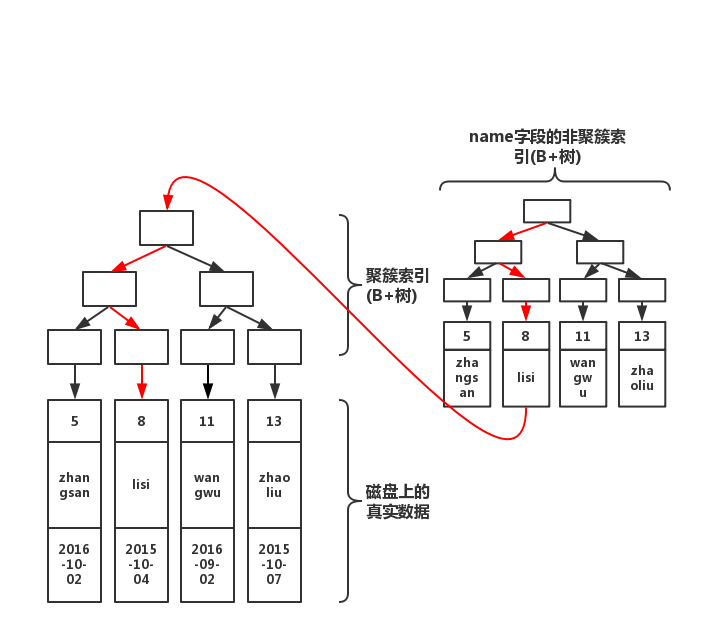
通过上图红线可以看出,先从非聚簇索引树开始查找,然后找到聚簇索引后。根据聚簇索引,在聚簇索引的B+树上,找到完整的数据!
那
什么情况不去聚簇索引树上查询呢?
还记得我们的非聚簇索引树上存着该索引字段的值么。如果,此时我们执行下面的语句
select name from table where name='lisi'
此时结构图如下
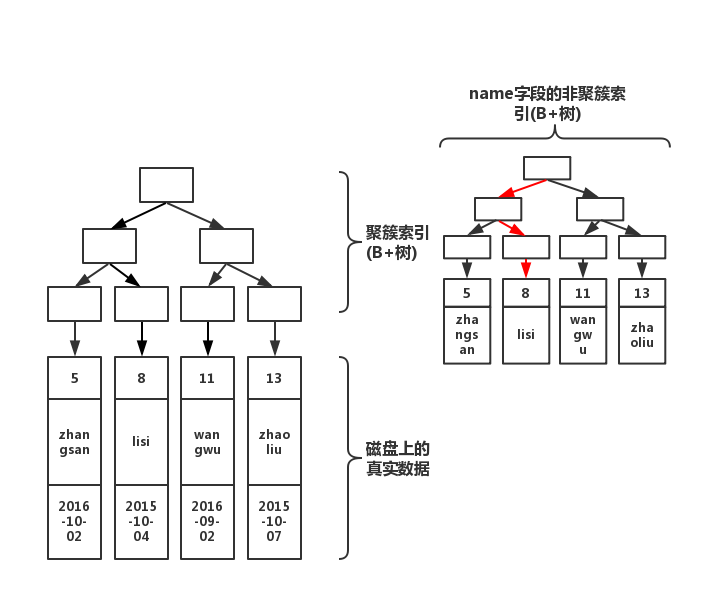
如上图红线所示,如果在非聚簇索引树上找到了想要的值,就不会去聚簇索引树上查询。还记得,博主在《select的正确姿势》提到的索引问题么:
当执行select col from table where col = ?,col上有索引的时候,效率比执行select * from table where col = ? 速度快好几倍!
看完上面的图,你应该对这句话有更深层的理解了。
那么这个时候,我们执行了下述语句,又会发生什么呢?
create index index_birthday on table(birthday);
此时结构图如下
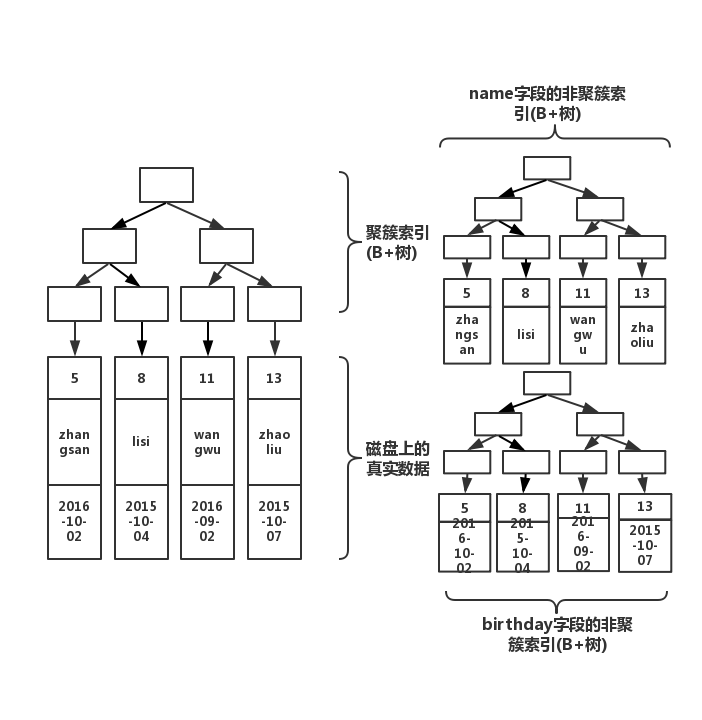
看到了么,多加一个索引,就会多生成一颗非聚簇索引树。因此,很多文章才说,索引不能乱加。因为,有几个索引,就有几颗非聚簇索引树!你在做插入操作的时候,需要同时维护这几颗树的变化!因此,如果索引太多,插入性能就会下降!
总结
讲到这里,大家应该清楚的明白索引的原理了!可能细节方面还不够严谨,但是我觉得一个研发,理解到这里可以了,够用了,毕竟我们也不是专业的DBA。
希望大家有所收获!
相关推荐
-
Mysql5.5 InnoDB存储引擎配置和优化
环境为CentOS系统,1G内存,Mysql5.5.30.在/etc/my.cnf内添加: 复制代码 代码如下: skip-external-lockingskip-name-resolvemax_connections = 1024query_cache_size = 16Msort_buffer_size = 1Mtable_cache = 256innodb_buffer_pool_size = 128Minnodb_additional_mem_pool_size = 4Minnodb_
-

MySQL Innodb表导致死锁日志情况分析与归纳
案例描述在定时脚本运行过程中,发现当备份表格的sql语句与删除该表部分数据的sql语句同时运行时,mysql会检测出死锁,并打印出日志.两个sql语句如下:(1)insert into backup_table select * from source_table(2)DELETE FROM source_table WHERE Id>5 AND titleWeight<32768 AND joinTime<'$daysago_1week'teamUser表的表结构如下:PRIMARY
-
MySQL不支持InnoDB的解决方法
G一下后,解决如下: /var/lib/mysql目录下,删除ibdata1.ib_logfile1. ib_logfile0,然后重启MySql让其重建以上文件: mysqladmin -uroot -p shutdown sudo mysqld_safe & 搞定! 下面是网络上的其它文章.大家也可以参考下.早上起来,到PHP站点去看了下,准备测试下别人写的一个CMS系统,高兴的下载了程序,然后把程序拷贝到所在目录.由于该程序没有install.php,里面只包含了一个*.sql的数据库语句
-
MySQL InnoDB 二级索引的排序示例详解
排序问题 最近看了极客时间上 <MySQL实战45讲>,纠正了一直以来对 InnoDB 二级索引的一个理解不到位,正好把相关内容总结下. PS:本文的所有测试基于 MySQL 8.0.13 . 先把问题抛出来,下面的 SQL 所创建的表,有两个查询语句,哪个索引是非必须的? CREATE TABLE `geek` ( `a` int(11) NOT NULL, `b` int(11) NOT NULL, `c` int(11) NOT NULL, `d` int(11) NOT NULL, P
-
可以改善mysql性能的InnoDB配置参数
而由于InnoDB是一个健壮的事务型存储引擎,已经有10多年的历史,一些重量级的互联网公司(Yahoo,Google Netease ,Taobao)也经常使用 我的日常工作也经常接触InnoDB,现在就InnoDB一部分可以改善性能的参数列举 1. innodb_additional_mem_pool_size 除了缓存表数据和索引外,可以为操作所需的其他内部项分配缓存来提升InnoDB的性能.这些内存就可以通过此参数来分配.推荐此参数至少设置为2MB,实际上,是需要根据项目的InnoDB表的
-
MySQL数据库INNODB表损坏修复处理过程分享
突然收到MySQL报警,从库的数据库挂了,一直在不停的重启,打开错误日志,发现有张表坏了.innodb表损坏不能通过repair table 等修复myisam的命令操作.现在记录下解决过程,下次遇到就不会这么手忙脚乱了. 处理过程: 一遇到报警之后,直接打开错误日志,里面的信息: InnoDB: Database page corruption on disk or a failed InnoDB: file read of page 30506. InnoDB: You may have t
-
mysql更改引擎(InnoDB,MyISAM)的方法
本文实例讲述了mysql更改引擎(InnoDB,MyISAM)的方法,分享给大家供大家参考.具体实现方法如下: mysql默认的数据库引擎是MyISAM,不支持事务和外键,也可使用支持事务和外键的InnoDB. 查看当前数据库的所支持的数据库引擎以及默认数据库引擎 数据库支持的引擎和默认数据库引擎代码: 复制代码 代码如下: show engines; 更改方式1:修改配置文件my.ini 我将my-small.ini另存为my.ini,在[mysqld]最后添加为上default-storag
-
探究MySQL中索引和提交频率对InnoDB表写入速度的影响
本次,我们来看看索引.提交频率对InnoDB表写入速度的影响,了解有哪些需要注意的. 先直接说几个结论吧: 1.关于索引对写入速度的影响: a.如果有自增列做主键,相对完全没索引的情况,写入速度约提升 3.11%: b.如果有自增列做主键,并且二级索引,相对完全没索引的情况,写入速度约降低 27.37%: 因此,InnoDB表最好总是有一个自增列做主键. 2.关于提交频率对写入速度的影响(以表中只有自增列做主键的场景,一次写入数据30万行数据为例): a.等待全部数据写入完成后,最后再执行com
-
深入讲解MySQL Innodb索引的原理
引言 回想四年前,我在学习mysql的索引这块的时候,老师在讲索引的时候,是像下面这么说的 索引就像一本书的目录.而当用户通过索引查找数据时,就好比用户通过目录查询某章节的某个知识点.这样就帮助用户有效地提高了查找速度.所以,使用索引可以有效地提高数据库系统的整体性能. 嗯,这么说其实也对.但是呢,大家看完这种说法,其实可能还是觉得太抽象了!因此呢,我还想再深入的细说一下,所以就有了此文! 需要说明的是,我说的内容只在Mysql的Innodb引擎中是成立的.在Sql Server.oracle.
-
MySQL Innodb索引机制详细介绍
1.什么是索引 索引是存储引擎用于快速找到记录的一种数据结构. 2.索引有哪些数据结构 顺序查找结构:这种查找效率很低,复杂度为O(n).大数据量的时候查询效率很低. 有序的数据排列:二分查找法又称折半查找法. 通过一次比较,将查找区间缩小一半.而MySQL中的数据并不是有序的序列. 二叉查找树:左子树的键值总是小于根的键值,右子树的键值总是大于根的键值.通过中序遍历得到的序列是有序序列,但如果二叉查找树构造的不好则跟顺序查找没什么区别 平衡二叉树:如果需要二叉查找树是平衡的,从而引出平衡二叉树
-
MySql InnoDB存储引擎之Buffer Pool运行原理讲解
目录 1. 前言 2. Buffer Pool 2.1 Buffer Pool结构 2.2 Free链表 2.3 缓冲页哈希表 2.4 Flush链表 2.5 LRU链表 2.6 多个实例 2.7 Buffer Pool状态信息 3. 总结 1. 前言 我们已经知道,对于InnoDB存储引擎而言,页是磁盘和内存交互的基本单位.哪怕你要读取一条记录,InnoDB也会将整个索引页加载到内存.哪怕你只改了1个字节的数据,该索引页就是脏页了,整个索引页都要刷新到磁盘.InnoDB是基于磁盘的存储引擎,如
-
图文并茂地讲解Mysql索引(index)
目录 前言 1. 索引概述 1.1 什么是索引? 1.2 使用索引和不使用索引的区别 1.3 索引的特点 2. 索引结构 2.1 概述 2.2 二叉树 2.3 B-Tree 2.4 B+Tree 2.5 Hash 3.索引分类 3.1 索引分类 3.2 聚集索引&二级索引 4. 索引语法 5. SQL性能分析 5.1 SQL执行频率 5.2 慢查询日志 5.3 profile详情 5.4 explain 6. 索引使用 6.1 验证索引效率 6.2 最左前缀法则 6.3 索引失效情况 6.3.1
-
Mysql使用索引的正确方法及索引原理详解
一 .介绍 为何要有索引? 一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句的优化显然是重中之重.说起加速查询,就不得不提到索引了. 什么是索引? 索引在MySQL中也叫做"键",是存储引擎用于快速找到记录的一种数据结构.索引对于良好的性能 非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要. 索引优化应该是对查询性能优化最有效的手段了.索引能
-
MySQL数据库优化之索引实现原理与用法分析
本文实例讲述了MySQL数据库优化之索引实现原理与用法.分享给大家供大家参考,具体如下: 索引 什么是索引 索引用来快速地寻找那些具有特定值的记录,所有MySQL索引都以B-树的形式保存.如果没有索引,执行查询时MySQL必须从第一个记录开始扫描整个表的所有记录,直至找到符合要求的记录.表里面的记录数量越多,这个操作的代价就越高.如果作为搜索条件的列上已经创建了索引,MySQL无需扫描任何记录即可迅速得到目标记录所在的位置.如果表有1000个记录,通过索引查找记录至少要比顺序扫描记录快100倍.
-
MySQL的索引原理以及查询优化详解
目录 一.介绍 1.什么是索引? 2.为什么要有索引呢? 二.索引的原理 一 索引原理 二 磁盘IO与预读 三.索引的数据结构 四.Mysql索引管理 一.功能 二.MySQL的索引分类 三. 索引的两大类型hash与btree 四.创建/删除索引的语法 五.测试索引 1.准备 2 .在没有索引的前提下测试查询速度 3. 加上索引 六.正确使用索引 一.覆盖索引 二.联合索引 三.索引合并 七.慢查询优化的基本步骤 总结 一.介绍 1.什么是索引? 一般的应用系统,读写比例在10:1左右,而且插
-
Mysql Innodb存储引擎之索引与算法
目录 一.概述 二.数据结构与算法 1.二分查找 2.二叉查找树和平衡二叉树 1)二叉查找树 2)平衡二叉树 三.B+树 1.B+树完整定义 2.关于 M 和 L的选定案例 四.B+树索引 1.聚集索引 2.辅助索引 五.关于 Cardinality 值 1.Cardinality定义 2.Cardinality的更新 六.B+树索引的使用 1.联合索引 2.覆盖索引 3.优化器选择不使用索引的情况 4.索引提示 5.Multi-Range Read 优化 (MRR) 6.Index Condi
-
Mysql简易索引方案讲解
目录 Mysql简易索引 一.没有索引的时候如何查找 在一个页中查找 在很多页中查找 二.一个简易索引 1. 下一页用户记录的主键值必须大于上一页的 2. 给所有的页建立一个目录项 三.简易索引暴露出的问题 Mysql简易索引 一.没有索引的时候如何查找 先忽略掉索引这个概念,如果现在直接要查某条记录,要如何查找呢? 在一个页中查找 如果表中的记录很少,一个页就够放,那么这时候有 2 种情况: 用主键为搜索条件:这时就是之前文章提过的方式,页面目录中用二分法快速定位到槽,然后遍历该槽对应分组的记
-
深入了解MySQL中索引优化器的工作原理
目录 本文导读 一.MySQL 优化器是如何选择索引的 1.MySQL数据库组成 2.MySQL数据库成本计算 二.MySQL查询成本 三.SELECT 执行过程 总结 本文导读 本文将解读MySQL数据库查询优化器(CBO)的工作原理.简单介绍了MySQL Server的组成,MySQL优化器选择索引额原理以及SQL成本分析,最后通过 select 查询总结整个查询过程. 一.MySQL 优化器是如何选择索引的 下面我们来看这张表,SUB_ODR_ID字段创建了相关的 2 个索引,根据我们前面