python实现淘宝秒杀脚本
本文实例为大家分享了python实现淘宝秒杀脚本的具体代码,供大家参考,具体内容如下
1.安装pycharm。网上教程很多。
2.安装 Selenium 库。
Selenium支持很多浏览器,我选择的是Firefox浏览器。
因为我这里是Python3环境,自带的又pip,所以安装selenium直接使用pip安装
安装方法:
--打开cmd;
--输入命令进入Python36/Scripts(找到下图的目录)目录下;
--输入命令 pip install selenium;
--回车,等待自动安装;
--当最后一行代码出现Successfully install selenium-XX时,表示安装成功。


3.插件 FireBug
FireBug 是火狐浏览器的一款查看代码元素的插件,可以快速的定位元素,selenium的重点就是元素定位,只有定到位了,才能进行下一步操作。
安装方法:
--打开Firefox浏览器,点击右上角按钮
--点击附加组件
--点击扩展
--搜索firebug
--点击安装,重启浏览器
--测试安装成功,按F12出现如下画面,表示firebug已经安装成功了

4.安装 驱动安装 geckodriver(windows环境下)
文件链接在下方。
使用方法:
1、下载完成解压;
2、将 geckodriver 放到 该浏览器可执行文件的路径下
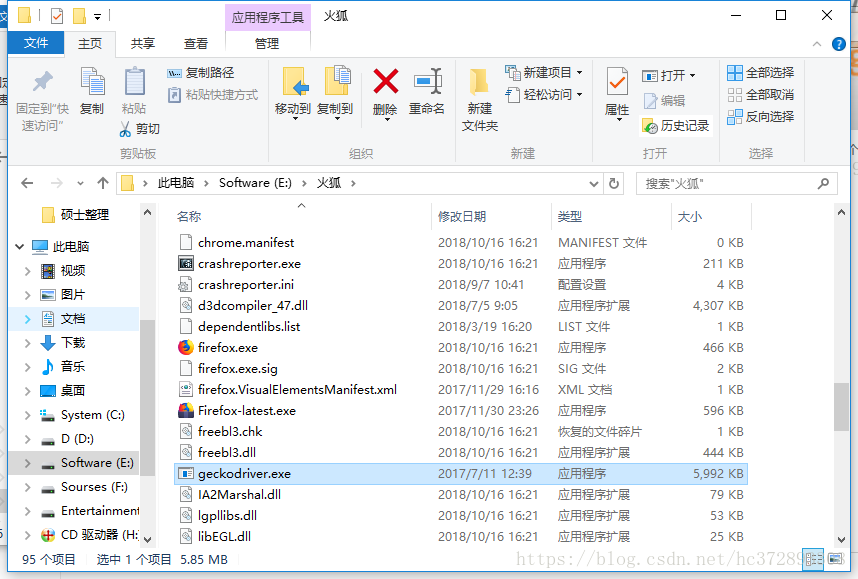
3、添加到环境变量中

5. 设置 pycharm
先创建一个工程
打开 pycharm -> 打开 file -> 点击 setting -> 点击最右边的设置按钮

点击 add, 在 Virtualenv Environment 和 System Interpreter 并选定找到本文给的 python 运行文件夹,Location 是自己建立的工作文件夹,里面为空,参考操作如下:
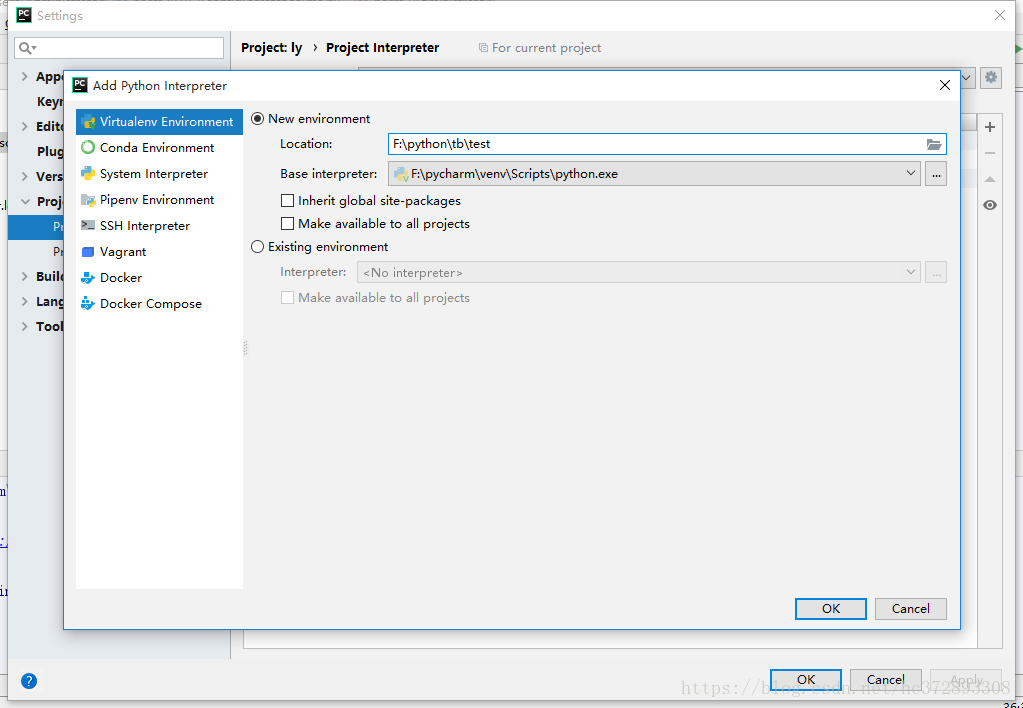
打开 pycharm -> 打开 file -> 点击 setting
将 project Interpreter 设置为 本文给的文件,或是自己本身的 python自带运行库

6. 新建一个python文件
输入以下程序:
# -*- coding: utf-8 -*- from selenium import webdriver driver = webdriver.Firefox() driver.get(https://www.baidu.com)
得到如下:

则成功搭建好环境。
7. 淘宝秒杀程序
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 2018/09/05
# 淘宝秒杀脚本,扫码登录版
import os
from selenium import webdriver
import datetime
import time
from os import path
from selenium.webdriver.common.action_chains import ActionChains
d = path.dirname(__file__)
abspath = path.abspath(d)
driver = webdriver.Firefox()
driver.maximize_window()
def login():
# 打开淘宝登录页,并进行扫码登录
driver.get("https://www.taobao.com")
time.sleep(3)
if driver.find_element_by_link_text("亲,请登录"):
driver.find_element_by_link_text("亲,请登录").click()
print("请在30秒内完成扫码")
time.sleep(30)
driver.get("https://cart.taobao.com/cart.htm")
time.sleep(3)
# 点击购物车里全选按钮
# if driver.find_element_by_id("J_CheckBox_939775250537"):
# driver.find_element_by_id("J_CheckBox_939775250537").click()
# if driver.find_element_by_id("J_CheckBox_939558169627"):
# driver.find_element_by_id("J_CheckBox_939558169627").click()
if driver.find_element_by_id("J_SelectAll1"):
driver.find_element_by_id("J_SelectAll1").click()
now = datetime.datetime.now()
print('login success:', now.strftime('%Y-%m-%d %H:%M:%S'))
def buy(buytime):
while True:
now = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')
# 对比时间,时间到的话就点击结算
if now > buytime:
try:
# 点击结算按钮
if driver.find_element_by_id("J_Go"):
driver.find_element_by_id("J_Go").click()
driver.find_element_by_link_text('提交订单').click()
except:
time.sleep(0.1)
print(now)
time.sleep(0.1)
if __name__ == "__main__":
# times = input("请输入抢购时间:")
# 时间格式:"2018-09-06 11:20:00.000000"
login()
buy("2018-10-22 18:55:00.000000")
以上程序是参照对应的 html 源码的对应元素所选择的。举例如下:

中对应的 J_SelectAll1 对应如下:

关于 selenium 和 html 源码的交互以后有时间再来研究。
资料链接如下:链接地址
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python 实现中值滤波、均值滤波的方法
红包: Lena椒盐噪声图片: # -*- coding: utf-8 -*- """ Created on Sat Oct 14 22:16:47 2017 @author: Don """ from tkinter import * from skimage import io import numpy as np im=io.imread('lena_sp.jpg', as_grey=True) im_copy_med = io.imrea
-

python实现五子棋小游戏
本文实例为大家分享了python实现五子棋小游戏的具体代码,供大家参考,具体内容如下 暑假学了十几天python,然后用pygame模块写了一个五子棋的小游戏,代码跟有缘人分享一下. import numpy as np import pygame import sys import traceback import copy from pygame.locals import * pygame.init() pygame.mixer.init() #颜色 background=(201,202
-
用Python和WordCloud绘制词云的实现方法(内附让字体清晰的秘笈)
环境及模块: Win7 64位 Python 3.6.4 WordCloud 1.5.0 Pillow 5.0.0 Jieba 0.39 目标: 绘制安徽省2018年某些科技项目的词云,直观展示热点. 思路: 先提取项目的名称,再用Jieba分词后提取词汇:过滤掉"研发"."系列"等无意义的词:最后用WordCloud 绘制词云. 扩展: 词云默认是矩形的,本代码采用图片作为蒙版,产生异形词云图.这里用的图片是安徽省地图. 秘笈: 用网上的常规方法绘制的词云,字体有
-
python中实现控制小数点位数的方法
前段时间遇到一个问题,python中怎么设置小数点位数,经过查资料,在这里整理了两种较为简单的方法: 法1:利用python内置的round()函数 a = 1.1314 a = 1.0000 a = 1.1267 b = round(a, 2) b = round(a, 2) b = round(a, 2) output: b=1.13 output: b=1.0 output: b=1.13 法2: a = 1.1314 a = 1.0000 a = 1.1267 b = '%.2f' %
-
Python下的Softmax回归函数的实现方法(推荐)
Softmax回归函数是用于将分类结果归一化.但它不同于一般的按照比例归一化的方法,它通过对数变换来进行归一化,这样实现了较大的值在归一化过程中收益更多的情况. Softmax公式 Softmax实现方法1 import numpy as np def softmax(x): """Compute softmax values for each sets of scores in x.""" pass # TODO: Compute and re
-
softmax及python实现过程解析
相对于自适应神经网络.感知器,softmax巧妙低使用简单的方法来实现多分类问题. 功能上,完成从N维向量到M维向量的映射 输出的结果范围是[0, 1],对于一个sample的结果所有输出总和等于1 输出结果,可以隐含地表达该类别的概率 softmax的损失函数是采用了多分类问题中常见的交叉熵,注意经常有2个表达的形式 经典的交叉熵形式:L=-sum(y_right * log(y_pred)), 具体 简单版本是: L = -Log(y_pred),具体 这两个版本在求导过程有点不同,但是结果
-
python 实现矩阵上下/左右翻转,转置的示例
python中没有二维数组,用一个元素为list的list(matrix)保存矩阵,row为行数,col为列数 1. 上下翻转:只需要把每一行的list交换即可 for i in range(row // 2): matrix[i], matrix[row-1-i] = matrix[row-1-i], matrix[i] 2. 左右翻转:需要逐个交换元素 for m in matrix: for j in range(col // 2): m[j], m[col-1-j] = m[col-1-
-
TensorFlow实现Softmax回归模型
一.概述及完整代码 对MNIST(MixedNational Institute of Standard and Technology database)这个非常简单的机器视觉数据集,Tensorflow为我们进行了方便的封装,可以直接加载MNIST数据成我们期望的格式.本程序使用Softmax Regression训练手写数字识别的分类模型. 先看完整代码: import tensorflow as tf from tensorflow.examples.tutorials.mnist imp
-
python实现淘宝秒杀脚本
本文实例为大家分享了python实现淘宝秒杀脚本的具体代码,供大家参考,具体内容如下 1.安装pycharm.网上教程很多. 2.安装 Selenium 库. Selenium支持很多浏览器,我选择的是Firefox浏览器. 因为我这里是Python3环境,自带的又pip,所以安装selenium直接使用pip安装 安装方法: --打开cmd: --输入命令进入Python36/Scripts(找到下图的目录)目录下: --输入命令 pip install selenium: --回车,等待自动
-
Python编写淘宝秒杀脚本
目录 添加火狐浏览器插件 安装geckodriver python代码 代码整体思路 使用方法 最近想抢冰墩墩的手办和钥匙圈,但是同志们抢的速度太快了,无奈,还是自己写脚本吧. 添加火狐浏览器插件 Omnibug是一个插件,可以简化web度量实现的开发.检查每个传出请求(由浏览器发送)的模式:如果出现匹配,URL将显示在开发人员工具面板中,并进行解码以显示请求的详细信息. 在火狐浏览器的插件中直接搜索.下载即可 安装geckodriver 在python中使用selenium爬取动态渲染网页,这
-
Python实现淘宝秒杀聚划算抢购自动提醒源码
说明 本实例能够监控聚划算的抢购按钮,在聚划算整点聚的时间到达时发出提醒(音频文件自己定义位置)并自动弹开页面(URL自己定义). 同时还可以通过命令行参数自定义刷新间隔时间(默认0.1s)和监控持续时间(默认1800s). 源码 # encoding: utf-8 ''''' @author: Techzero @email: techzero@163.com @time: 2014-5-18 下午5:06:29 ''' import cStringIO import getopt impor
-
Python实现淘宝秒杀功能的示例代码
1.安装 Selenium 模块 Selenium支持很多浏览器,我选择的是Firefox浏览器. 安装方法: ①打开cmd: ②输入命令 pip install selenium: ③回车,等待自动安装: ④当最后一行代码出现Successfully install selenium-XX时,表示安装成功. 2. 插件 FireBug FireBug 是火狐浏览器的一款查看代码元素的插件,可以快速的定位元素,selenium的重点就是元素定位,只有定到位了,才能进行下一步操作. 测试安装成功,
-
Python 实现淘宝秒杀的示例代码
新手学习Python,之前在网上看见一位朋友写的40行Python代码搞定京东秒杀,想在淘宝上帮女朋友抢玩偶,所以就照猫画虎的写了下淘宝的秒杀脚本,经自己实验可行.直接上代码: #-*- coding: UTF-8 -*- import os from selenium import webdriver import datetime import time chromedriver = "/usr/bin/chromedriver" os.environ["webdrive
-
淘宝秒杀python脚本 扫码登录版
本文实例为大家分享了python淘宝秒杀的具体代码,供大家参考,具体内容如下 # 淘宝秒杀脚本,扫码登录版 import os from selenium import webdriver import datetime import time from os import path driver = webdriver.Chrome() def login(url): # 打开淘宝登录页,并进行扫码登录 driver.get("https://www.taobao.com") tim
-
Python 实现毫秒级淘宝抢购脚本的示例代码
本篇文章主要介绍了Python 通过selenium实现毫秒级自动抢购的示例代码,通过扫码登录即可自动完成一系列操作,抢购时间精确至毫秒,可抢加购物车等待时间结算的,也可以抢聚划算的商品. 博主不提供任何服务器端程序,也不提供任何收费抢购软件.该文章仅作为学习selenium框架的一个示例代码.该思路可运用到其他任何网站,京东,天猫,淘宝均可使用,且不属于外挂或者软件之类,只属于一个自动化点击工具,如有侵犯到任何公司的合法权益,会第一时间将相关代码给予删除. 直接上源码: # !/usr/bin
-
备战618!用Python脚本帮你实现淘宝秒杀
selenium 安装与 chromedriver安装 我们前文提到,Python脚本中使用了selenium库,而selenium又通过chromedriver来控制浏览器的鼠标点击等操作.所以,我们的第一步,是正确的安装与配置selenium以及chromedriver. selenium的安装很简单,与其他Python三方库一样,我们直接用pip安装. pip install selenium chromedriver的安装,首先,chromedriver的版本很关键,我们需要选择的chr
-
自制Python淘宝秒杀抢购脚本双十一百分百中
大家好,我是不学前端的前端程序员, 事情是这个样子的,前几天不是双十一预购秒杀嘛 由于我女朋友比较笨,手速比较慢,就一直抢不到,她没抢到特价商品就不开心, 她不开心,我也就不能跟着开心,就别提看6号的全球总决赛了 为了解决这个问题,就决定写一个自动定时抢购的脚本. 第一步: 首先我的思路很简单,就是让"程序"帮我们自动打开浏览器,进入淘宝,然后到购物车等待抢购时间,自动购买并支付. 第二步: 导入模块,我们需要一个时间模块,抢购的时间,还有一个Python的自动化操作. 代码如下: i
-
Python淘宝秒杀的脚本实现
准备工作 我们需要把秒杀的商品加入购物车,因为脚本点击的是全选,所以不需要的商品要移出购物车. 过程分析 1.打开某宝网站: pq = webdriver.Chrome() pq.get("https://www.taobao.com") # 版权问题 time.sleep(3) sleep的原因是怕万一网速慢,网页加载慢. 2.扫码登陆: pq.find_element(By.LINK_TEXT, "亲,请登录").click() print(f"请尽快