使用Pandas对数据进行筛选和排序的实现
筛选和排序是Excel中使用频率最多的功能,通过这个功能可以很方便的对数据表中的数据使用指定的条件进行筛选和计算,以获得需要的结果。在Pandas中通过.sort和.loc函数也可以实现这两 个功能。.sort函数可以实现对数据表的排序操作,.loc函数可以实现对数据表的筛选操作。本篇文章将介绍如果通过Pandas的这两个函数完成Excel中的筛选和排序操作。
首选导入需要使用的Pandas库和numpy库,读取并创建数据表,将数据表命名为lc。
import pandas as pd
import numpy as np
lc=pd.DataFrame(pd.read_csv('LoanStats3a.csv',header=1))
创建数据表后,开始使用Pandas的.sort函数对数据表进行排序操作,下面是Pandas官方对.sort函数语法和使用方法的说明。.sort函数主要包含6个参数,columns为要进行排序的列名称, ascending为排序的方式true为升序,False为降序,默认为true。axis为排序的轴,0表示index,1表示columns,当对数据列进行排序时,axis必须设置为0。inplace默认为False,表示对数据 表进行排序,不创建新实例。Kind可选择排序的方式,如快速排序等。na_position对NaN值的处理方式,可以选择first和last两种方式,默认为last,也就是将NaN值放在排序的结尾。

在了解了.sort函数的语法和使用方法后,我们开始使用这个函数对数据进行排序操作,数据源来自Lending Club 2017-2011年的公开数据。首先对单列数据进行排序。
对单列数据进行排序
升序
单列数据的排序的方法很简单,按照.sort函数中的介绍,写清楚要排序的数据表名称,以及要进行排序的列名称即可。具体的代码和排序结果如下所示,其中lc是前面我们读取并创建的数据表名称,loan_amnt是要进行排序的列名称。这里我们对lc数据表按loan_amnt列进行升序排列。这里需要说明的是ascending参数的默认值是True,也就是升序。因此下面的两种写法效果是一样的 。
lc.sort(["loan_amnt"]) lc.sort(["loan_amnt"],ascending=True)
降序
将ascending参数的值改为False就完成对数据表的降序排列工作。与升序排列的数据表相比可以发现升序排列将loan_amnt列的最小值放在了前面,因此我们可以判断loan_amnt的最小金额为500,与之相反,降序排列将最大值放在了前面,因此loan_amnt的最大金额应该为35000。这里我们没有设置na_position参数的值,因此按默认情况loan_amnt列的NaN值在排序的结尾显示。以下显示了降序排列的代码和结果。
lc.sort(["loan_amnt"],ascending=False)
对多列数据进行排序
除了对单列数据进行排序以外,.sort函数还可以对多列数据进行排序操作。下面我们分别对loan_amnt和int_rate字段进行降序排列,以下是具体的代码和排序结果,与单列数据排序的代码相比,这里只增加了一个新的列名称int_rate。
lc.sort(["loan_amnt","int_rate"],ascending=False)
我们将需要排序的两个列名称互换位置,再次执行降序排列操作。观察两次的排序结果可以发现,这次的结果与之前的结果有一些差异。Loan_amnt字段的排序结果有些混乱,有些较小的值排在了较大值的前面。这是因为第一次排序时loan_amnt是第一排序字段,int_rate是第二排序字段。两个字段交换位置第二次排序后,int_rate变成了第一排序字段,loan_amnt变成了第二排序字段 。
lc.sort(["int_rate","loan_amnt"],ascending=False)

获取金额最小前10项
在完成了对数据表排序的操作后,我们可以对数据表进行简单的筛选,例如获取loan_amnt金额最小的前10名数据。具体的方法是先对lc数据表按loan_amnt升序排列,然后取前10名的数据。NaN值默认在排序结果的结尾显示。以下是具体代码和结果。与前面单列升序排列的代码相比只在结尾增加了.head()函数。
lc.sort(["loan_amnt"],ascending=True).head(10)
获取金额最大前10项
获取金额最大前10项的代码与获取金额最小前10项略有差异,本来我们只需要复制前面的代码,然后将.head()函数改为tail()函数即可,但由于NaN值在排序的尾部,因此,我们将lc数据表按loan_amnt按降序排列,并取排名前10的数据。当然这并不是唯一的方法,我们还可以通过放弃NaN值的排序或者将NaN值在排序前部显示来解决这个问题。以下是具体的代码和执行结果。
lc.sort(["loan_amnt"],ascending=False).head(10)

介绍完排序功能后再来看下筛选,在筛选功能上Pandas使用的是.loc函数。以下是Pandas官方对.loc函数的语法和使用方法的说明。

单列数据筛选并排序
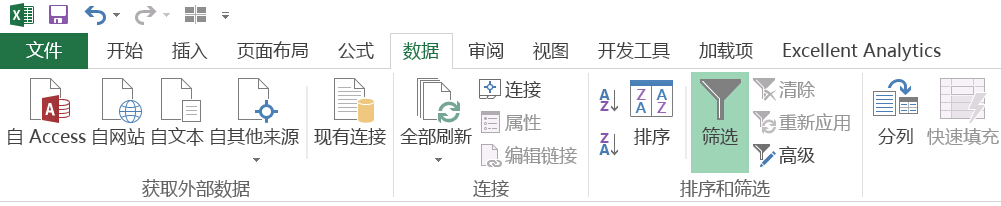
我们使用.loc对lc数据表中grade列为B值的数据条目进行了筛选操作,具体的代码和筛选结果如下。在代码中lc.loc[]是.loc函数的语法,lc[“grade”] == “B”是具体的筛选条件。由于数据表较大,因此在最后使用了head()函数只显示前5行筛选结果。从筛选结果来看grade列的值都为B。
lc.loc[lc["grade"] == "B"].head()
筛选条件除了”等于”(==)以外,还可以使用”不等于”(!=)来排除列中特定的值。我们使用”不等于”来筛选grade列中不是B值的数据条目。以下是具体的代码和筛选结果,可以看到筛选结果中的grade列里已经不包含B值了。
lc.loc[lc["grade"] != "B"].head()

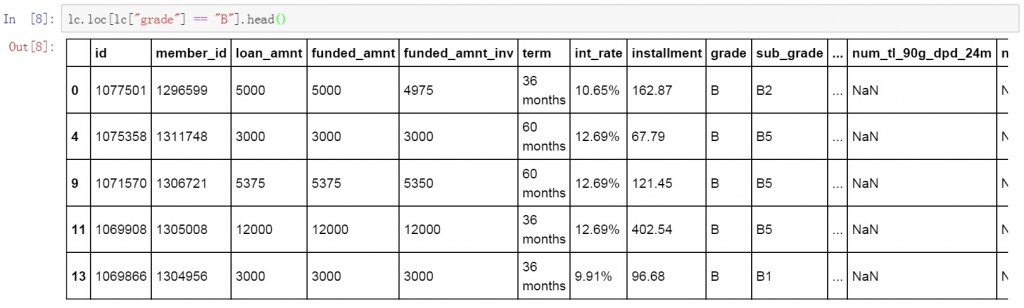
很多时候我们只关注数据表中某几列的数据,这时可以在前面筛选代码的基础上增加要显示的列名称和显示顺序。下面是具体的代码和筛选结果。代码部分与之前相比增加了要显示的列名称 [“member_id”, “loan_amnt”, “grade”]。其余部分均没有改变。在筛选结果的数据表中可以看到仅显示了我们在代码中列出的三列。
lc.loc[lc["grade"] == "B", ["member_id", "loan_amnt", "grade"]].head()
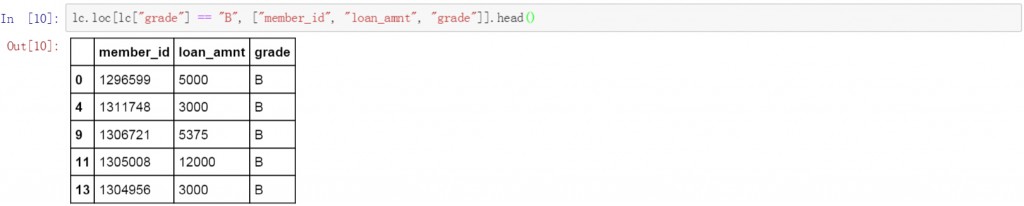
若要对筛选结果进行排序可以联合使用.loc函数和.sort函数。下面的代码中首先对数据表的grade列进行筛选,选择所有值为B的数据,并限定了结果中要显示的三列的名称。最后对筛选出的结果按loan_amnt的金额进行升序排序。
lc.loc[lc["grade"] == "B", ["member_id", "loan_amnt", "grade"]].sort(["loan_amnt"])
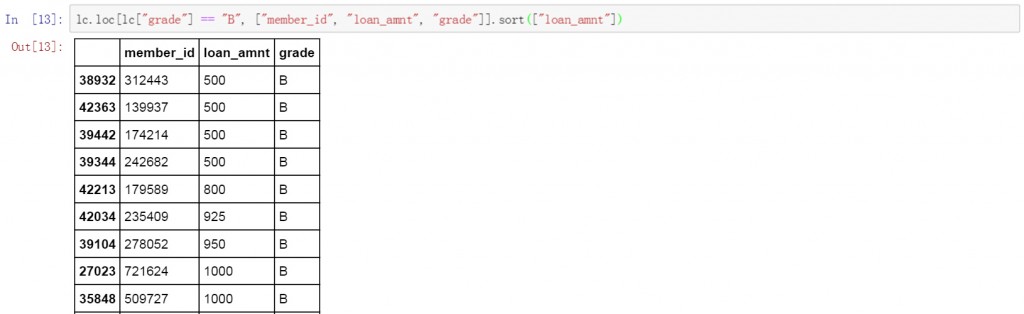
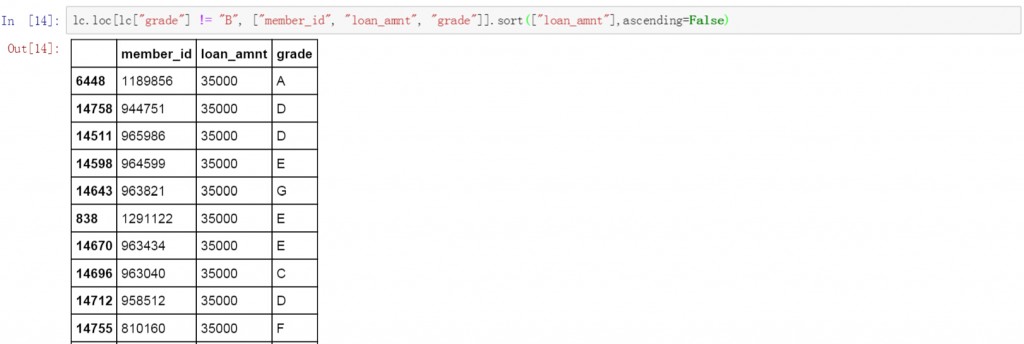
在代码后面增加ascending参数,并将值设置为False就可实现对筛选结果的降序排列。以下为具体的代码和筛选及排序结果。
lc.loc[lc["grade"] != "B", ["member_id", "loan_amnt", "grade"]].sort(["loan_amnt"],ascending=False)
多列数据筛选并排序
Pandas的.loc参数还可以同时对多列数据进行筛选,并且支持不同筛选条件逻辑组合。常用的筛选条件包括”等于”(==)”,不等于”(!),”大于”(>)”,小于”(<)”,大于等于”(>=)” ,小于等于”(<=)等等。逻辑组合包括”与”()和”或”()。下面我们将通过3条多列数据筛选代码逐一进行介绍。
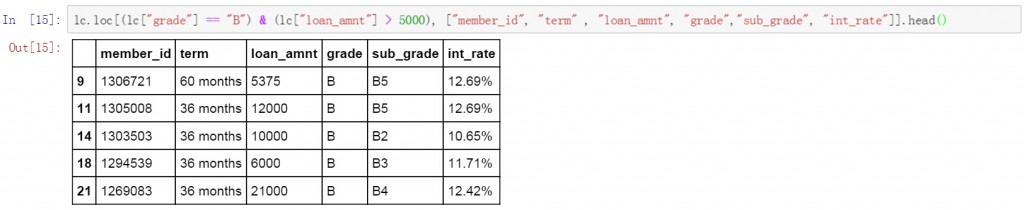
第一条代码使用”与”逻辑,筛选出了grade等于B,并且loan_amnt金额大于5000的数据。并限定了显示的列名称。从筛选结果中可以看出grade列的值都是B,loan_amnt的金额均大于5000。
lc.loc[(lc["grade"] == "B") & (lc["loan_amnt"]>5000), ["member_id", "term" , "loan_amnt", "grade","sub_grade", "int_rate"]].head()
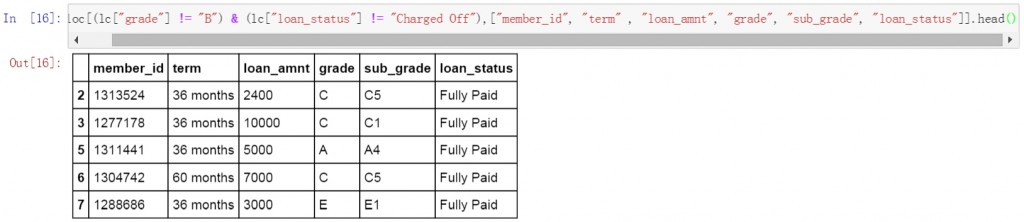
第二条代码也使用”与”逻辑,筛选出了grade不等于B,并且loan_status不等于Charged Off的数据,同时也限定了显示的列名称。从筛选结果中看grade列不包含B值,并且loan_status列不包含Charged Off值。
lc.loc[(lc["grade"] != "B") & (lc["loan_status"] != "Charged Off"),["member_id", "term" , "loan_amnt", "grade", "sub_grade", "loan_status"]].head()
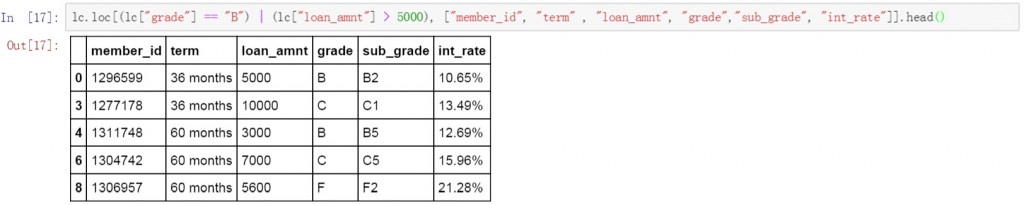
第三条代码使用了”或”逻辑,筛选出了grade列值为B,或loan_amnt列金额大于5000的数据,同时也限定了显示的列名称。从筛选结果来看,grade列除了B值以外还保留了其他的值,而这些值在loan_amnt列的金额均大于5000。换句话说,一条数据只要grade列或loan_amnt列任意之一符合筛选条件,这条数据就会被显示。
lc.loc[(lc["grade"] == "B") | (lc["loan_amnt"] > 5000), ["member_id", "term" , "loan_amnt", "grade","sub_grade", "int_rate"]].head()
多列筛选也可以进行排序,方法与单列筛选后排序基本一样,下面的代码对多列筛选后的结果按loan_amnt列进行升序排序。由于筛选条件中限定了loan_amnt列的值要大于5000,因此排序的结果从5020开始。
lc.loc[(lc["grade"] == "B") & (lc["loan_amnt"] > 5000), ["member_id", "term" , "loan_amnt", "grade","sub_grade", "int_rate"]].sort(["loan_amnt"])
对多列筛选结果进行降序排序只需在前面升序排序代码的基础上增加ascending参数,并将值设定为False即可。下面是多列筛选后降序排序的代码和结果。
lc.loc[(lc["grade"] == "B") & (lc["loan_amnt"] > 5000), ["member_id", "term" , "loan_amnt", "grade","sub_grade", "int_rate"]].sort(["loan_amnt"],ascending=False)

无论是”与”条件,还是”或”条件都可以在筛选后使用排序。下面代码是对使用了“或”逻辑条件的筛选结果进行降序排序的代码和结果。
lc.loc[(lc["grade"] == "B") | (lc["loan_amnt"] > 5000), ["member_id", "term" , "loan_amnt", "grade","sub_grade", "int_rate"]].sort(["loan_amnt"],ascending=False)
Pandas中的排序和筛选基本介绍完了,在实际的分析工作中,筛选只是分析过程中的一个步骤,很多时候我们还需要对筛选后的结果进行汇总,例如求和,计数,或计算均值等等。也就是Excel中常用的sumifs和countifs函数。
按筛选条件求和(sumif, sumifs)
在单列筛选的代码后增加求和条件就相当于Excel中的sumif函数的功能。下面的代码在单列筛选的代码后增加了.loan_amnt.sum()的求和字段,表示对数据表中所有grade列值为B的loan_amnt金额求和。
lc.loc[lc["grade"] == "B",].loan_amnt.sum()

除了包含条件外,也可以对排除某一条件的数据求和。下面的代码与之前的正好相反,对数据表中所有grade列值不为B的loan_amnt金额求和。
lc.loc[lc["grade"] != "B",].loan_amnt.sum()

增加一个筛选条件就变成了Excel中的sumifs函数的功能。下面的代码中分别使用了两个条件对数据表进行筛选,并对最后的loan_amnt金额进行求和。
lc.loc[(lc["grade"] == "B") & (lc["loan_amnt"] > 5000)].loan_amnt.sum()

按筛选条件计数(countif, countifs)
将前面的.sum()函数换为.count()函数就变成了Excel中的countif函数的功能,下面的代码对数据表中grade列值为B的loan_amnt笔数进行计数。
lc.loc[lc["grade"] == "B"].loan_amnt.count()

与前面代码相反,下面的代码对数据表中grade列值不为B的所有loan_amnt笔数进行计数。
lc.loc[lc["grade"] != "B"].loan_amnt.count()

增加筛选条件,变成了Excel中的countifs函数的功能,下面的代码对数据表中grade列值为B,并且loan_amnt金额额大于5000的loan_amnt笔数进行计数。
lc.loc[(lc["grade"] == "B") & (lc["loan_amnt"] > 5000)].loan_amnt.count()

按筛选条件计算均值(averageif, averageifs)
有了sumifs和countifs,当然也少不了averageifs,在Pandas中.mean()是用来计算均值的函数,将.sum()和.count()替换为.mean()。就是pandas版的averageif和averageifs。下面的代码中计算了数据表中grade列值为B的loan_amnt金额均值。相当于Excel中的averageif函数的功能。
lc.loc[lc["grade"] == "B"].loan_amnt.mean()

与前面的代码证号相反,下面的代码计算了数据表中所有grade列值不为B的loan_amnt金额均值。
lc.loc[lc["grade"] != "B"].loan_amnt.mean()

增加一个筛选条件变成了Excel中的averageifs,不过这里好像又有一些不同,Excel中的sumifs,countifs和averageifs的计算逻辑是满足满足所有指定条件时,才对这些单元格进行求和或计数。而在下面的代码中我们使用了或条件,就是说只要满足两个条件中的任意一个都会进行计算。
lc.loc[(lc["grade"] == "B") | (lc["loan_amnt"] > 5000)].loan_amnt.mean()

按筛选条件获取最大值和最小值
最后两个是Excel中没有的函数功能,就是对筛选后的数据表计算最大值和最小值。方法很简单,将之前的sum()和count()换成max()和min()函数即可。下面是具体的代码和结果。
这条代码是计算数据表中grade列值为B的loan_amnt最大金额。
lc.loc[lc["grade"] == "B"].loan_amnt.max()

这条代码是计算数据表中grade列值不为B的loan_amnt最小金额。
lc.loc[lc["grade"] != "B"].loan_amnt.min()

以上这些也同样支持多条筛选后的计算,在此就不逐一列出了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
pandas筛选某列出现编码错误的解决方法
如下所示: df = df[df['cityname']==u'北京市'] 记得,如果用的python2,一定要导入 import sys reload(sys) sys.setdefaultencoding('utf-8') 或者在中文前面加入u'表示unicode编码的,因为pandas对象中中文字符为unicode类型的. 以上这篇pandas筛选某列出现编码错误的解决方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
pandas数据处理基础之筛选指定行或者指定列的数据
pandas主要的两个数据结构是:series(相当于一行或一列数据机构)和DataFrame(相当于多行多列的一个表格数据机构). 本文为了方便理解会与excel或者sql操作行或列来进行联想类比 1.重新索引:reindex和ix 上一篇中介绍过数据读取后默认的行索引是0,1,2,3...这样的顺序号.列索引相当于字段名(即第一行数据),这里重新索引意思就是可以将默认的索引重新修改成自己想要的样子. 1.1 Series 比方说:data=Series([4,5,6],index=['a',
-
浅谈pandas筛选出表中满足另一个表所有条件的数据方法
今天记录一下pandas筛选出一个表中满足另一个表中所有条件的数据.例如: list1 结构:名字,ID,颜色,数量,类型. list1 = [['a',1,255,100,'03'],['a',2,481,50,'06'],['a',47,255,500,'03'],['b',3,1,50,'11']] list2结构:名字,类型,颜色. list2 = [['a','03',255],['a','06',481]] 如何在list1中找出所有与list2中匹配的元素?要得到下面的结果:lis
-
pandas数据筛选和csv操作的实现方法
1. 数据筛选 a b c 0 0 2 4 1 6 8 10 2 12 14 16 3 18 20 22 4 24 26 28 5 30 32 34 6 36 38 40 7 42 44 46 8 48 50 52 9 54 56 58 (1)单条件筛选 df[df['a']>30] # 如果想筛选a列的取值大于30的记录,但是之显示满足条件的b,c列的值可以这么写 df[['b','c']][df['a']>30] # 使用isin函数根据特定值筛选记录.筛选a值等于30或者54的记录 df
-
pandas按若干个列的组合条件筛选数据的方法
还是用图说话 A文件: 比如,我想筛选出"设计井别"."投产井别"."目前井别"三列数据都为11的数据,结果如下: 当然,这里的筛选条件可以根据用户需要自由调整,代码如下: # -*- coding: utf-8 -*- """ Created on Wed Nov 29 10:46:31 2017 @author: wq """ import pandas as pd #input.c
-
pandas系列之DataFrame 行列数据筛选实例
一.对DataFrame的认知 DataFrame的本质是行(index)列(column)索引+多列数据. 为了简化理解,我们不妨换个思路- 现实中,为了简化对一件事物的描述,我们会选择几个特征. 例如,从(性别.身高.学历.职业.爱好..)等角度去刻画一个人,这些"角度"即为"特征". 其中,不同的行表示不同的记录:列代表特征,不同记录因各个特征之间的差异而不同. DataFrame默认索引是序号(0,1,2-),可以理解成位置索引.一般我们用id标识不同记录,
-

使用Pandas对数据进行筛选和排序的实现
筛选和排序是Excel中使用频率最多的功能,通过这个功能可以很方便的对数据表中的数据使用指定的条件进行筛选和计算,以获得需要的结果.在Pandas中通过.sort和.loc函数也可以实现这两 个功能..sort函数可以实现对数据表的排序操作,.loc函数可以实现对数据表的筛选操作.本篇文章将介绍如果通过Pandas的这两个函数完成Excel中的筛选和排序操作. 首选导入需要使用的Pandas库和numpy库,读取并创建数据表,将数据表命名为lc. import pandas as pd impo
-
vue 数据遍历筛选 过滤 排序的应用操作
vue 中对v-for 遍历数据的处理方式 可以分为两类 : 一.对data 直接赋值(比较笨,但是比较直接) <div id="app"> <ul> <li v-for="item in list">{{item.n}}</li> </ul> </div> </body> <script> var app=new Vue({ el:'#app', data:{ list
-
pandas 按日期范围筛选数据的实现
pandas 是 python 中一个功能强大的库,这里就不再复述了,简单介绍下用日期范围筛选 pandas 数据. 日期转换 用来筛选的列是 date 类型,所以这里要把要筛选的日期范围从字符串转成 date 类型 比如我的数据包含列名为 trade_date,从 20050101 - 20190926 的数据,我要筛选出 20050606 - 20071016 的数据,那么,先如下转换数据类型: s_date = datetime.datetime.strptime('20050606',
-
pandas实现数据读取&清洗&分析的项目实践
目录 一.数据读取和写入 1.1 CSV和txt文件: 1.2 Excel文件: 1.3 MYSQL数据库: 二.数据清洗 2.1 清除不需要的行数据 2.2 清除不需要的列 2.3 调整列的展示顺序或列标签名 2.4 对行数据进行排序 2.5 空值的处理 2.6 数据去重处理 2.7 对指定列数据进行初步加工 2.8 对DataFrame内所有数据进行初步加工处理 2.9 设置数据格式 三.数据切片和筛选查询 3.1 行切片 3.2 列切片 3.3 数据筛选和查询 3.4 遍历 四.数据简单统
-
对pandas进行数据预处理的实例讲解
参加kaggle数据挖掘比赛,就第一个赛题Titanic的数据,学习相关数据预处理以及模型建立,本博客关注基于pandas进行数据预处理过程.包括数据统计.数据离散化.数据关联性分析 引入包和加载数据 import pandas as pd import numpy as np train_df =pd.read_csv('../datas/train.csv') # train set test_df = pd.read_csv('../datas/test.csv') # test set
-
Python Pandas实现数据分组求平均值并填充nan的示例
Python实现按某一列关键字分组,并计算各列的平均值,并用该值填充该分类该列的nan值. DataFrame数据格式 fillna方式实现 groupby方式实现 DataFrame数据格式 以下是数据存储形式: fillna方式实现 1.按照industryName1列,筛选出业绩 2.筛选出相同行业的Series 3.计算平均值mean,采用fillna函数填充 4.append到新DataFrame中 5.循环遍历行业名称,完成2,3,4步骤 factordatafillna = pd.
-
python 用pandas实现数据透视表功能
透视表是一种可以对数据动态排布并且分类汇总的表格格式.对于熟练使用 excel 的伙伴来说,一定很是亲切! pd.pivot_table() 语法: pivot_table(data, # DataFrame values=None, # 值 index=None, # 分类汇总依据 columns=None, # 列 aggfunc='mean', # 聚合函数 fill_value=None, # 对缺失值的填充 margins=False, # 是否启用总计行/列 dropna=True,
-
ant design pro中可控的筛选和排序实例
我就废话不多说了,大家还是直接看代码吧~ /** * Created by hao.cheng on 2017/4/15. */ import React from 'react'; import { Table, Button } from 'antd'; const data = [{ key: '1', name: '张三', age: 22, address: '浙江省温州市', }, { key: '2', name: '李四', age: 42, address: '湖南省湘潭市',
-
Pandas的数据过滤实现
作者|Amanda Iglesias Moreno 编译|VK 来源|Towards Datas Science 从数据帧中过滤数据是清理数据时最常见的操作之一.Pandas提供了一系列根据行和列的位置和标签选择数据的方法.此外,Pandas还允许你根据列类型获取数据子集,并使用布尔索引筛选行. 在本文中,我们将介绍从Pandas数据框中选择数据子集的最常见操作: 按标签选择单列 按标签选择多列 按数据类型选择列 按标签选择一行 按标签选择多行 按位置选择一行 按位置选择多行 同时选择行和列 选