python爬取盘搜的有效链接实现代码
因为盘搜搜索出来的链接有很多已经失效了,影响找数据的效率,因此想到了用爬虫来过滤出有效的链接,顺便练练手~
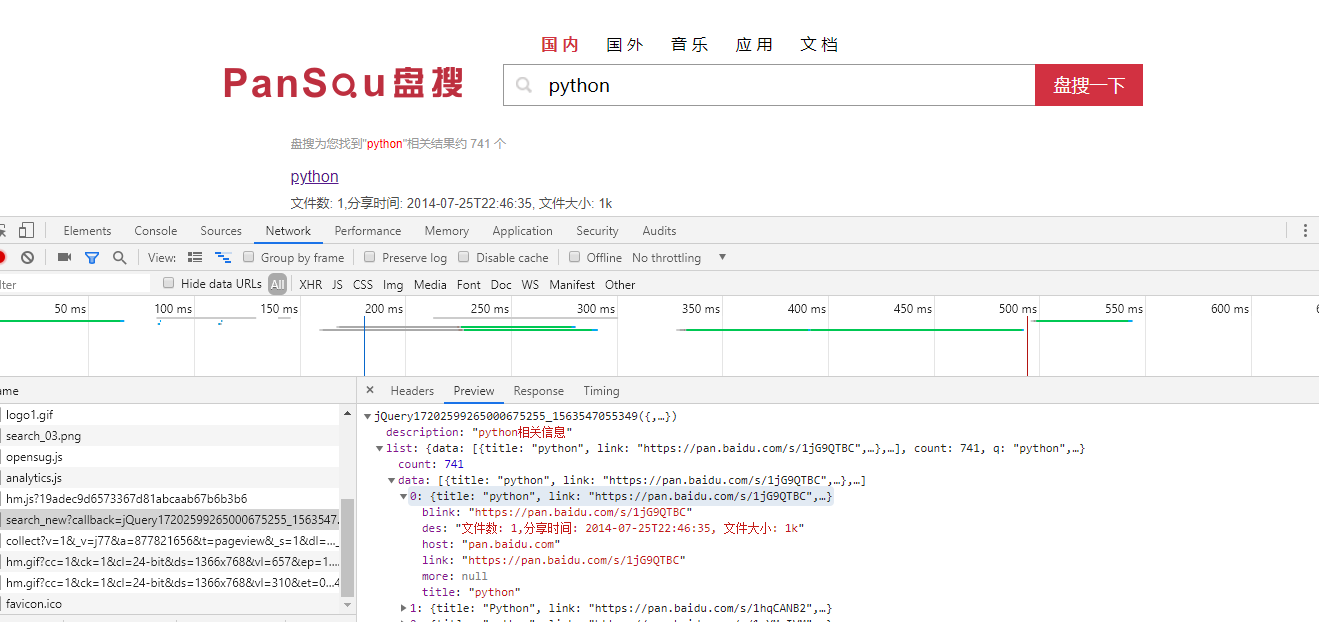
这是本次爬取的目标网址http://www.pansou.com,首先先搜索个python,之后打开开发者工具,
可以发现这个链接下的json数据就是我们要爬取的数据了,把多余的参数去掉,
剩下的链接格式为http://106.15.195.249:8011/search_new?q=python&p=1,q为搜索内容,p为页码
以下是代码实现:
import requests
import json
from multiprocessing.dummy import Pool as ThreadPool
from multiprocessing import Queue
import sys
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
q1 = Queue()
q2 = Queue()
urls = [] # 存取url列表
# 读取url
def get_urls(query):
# 遍历50页
for i in range(1,51):
# 要爬取的url列表,返回值是json数据,q参数是搜索内容,p参数是页码
url = "http://106.15.195.249:8011/search_new?&q=%s&p=%d" % (query,i)
urls.append(url)
# 获取数据
def get_data(url):
print("开始加载,请等待...")
# 获取json数据并把json数据转换为字典
resp = requests.get(url, headers=headers).content.decode("utf-8")
resp = json.loads(resp)
# 如果搜素数据为空就抛出异常停止程序
if resp['list']['data'] == []:
raise Exception
# 遍历每一页数据的长度
for num in range(len(resp['list']['data'])):
# 获取百度云链接
link = resp['list']['data'][num]['link']
# 获取标题
title = resp['list']['data'][num]['title']
# 访问百度云链接,判断如果页面源代码中有“失效时间:”这段话的话就表明链接有效,链接无效的页面是没有这段话的
link_content = requests.get(link, headers=headers).content.decode("utf-8")
if "失效时间:" in link_content:
# 把标题放进队列1
q1.put(title)
# 把链接放进队列2
q2.put(link)
# 写入csv文件
with open("wangpanziyuan.csv", "a+", encoding="utf-8") as file:
file.write(q1.get()+","+q2.get() + "\n")
print("ok")
if __name__ == '__main__':
# 括号内填写搜索内容
get_urls("python")
# 创建线程池
pool = ThreadPool(3)
try:
results = pool.map(get_data, urls)
except Exception as e:
print(e)
pool.close()
pool.join()
print("退出")
总结
以上所述是小编给大家介绍的python爬取盘搜的有效链接实现代码希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
Python爬取数据并写入MySQL数据库的实例
首先我们来爬取 http://html-color-codes.info/color-names/ 的一些数据. 按 F12 或 ctrl+u 审查元素,结果如下: 结构很清晰简单,我们就是要爬 tr 标签里面的 style 和 tr 下几个并列的 td 标签,下面是爬取的代码: #!/usr/bin/env python # coding=utf-8 import requests from bs4 import BeautifulSoup import MySQLdb print('连接到m
-
python爬虫爬取微博评论案例详解
前几天,杨超越编程大赛火了,大家都在报名参加,而我也是其中的一员. 在我们的项目中,我负责的是数据爬取这块,我主要是把对于杨超越 的每一条评论的相关信息. 数据格式:{"name":评论人姓名,"comment_time":评论时间,"comment_info":评论内容,"comment_url":评论人的主页} 以上就是我们需要的信息. 爬虫前的分析: 以上是杨超越的微博主页,这是我们首先需要获取到的内容. 因为我们需要等
-
实例讲解Python爬取网页数据
一.利用webbrowser.open()打开一个网站: >>> import webbrowser >>> webbrowser.open('http://i.firefoxchina.cn/?from=worldindex') True 实例:使用脚本打开一个网页. 所有Python程序的第一行都应以#!python开头,它告诉计算机想让Python来执行这个程序.(我没带这行试了试,也可以,可能这是一种规范吧) 1.从sys.argv读取命令行参数:打开一个新的文
-
Python 爬取携程所有机票的实例代码
打开携程网,查询机票,如广州到成都. 这时网址为:http://flights.ctrip.com/booking/CAN-CTU-day-1.html?DDate1=2018-06-15 其中,CAN 表示广州,CTU 表示成都,日期 "2018-06-15"就比较明显了.一般的爬虫,只有替换这几个值,就可以遍历了.但观察发现,有个链接可以看到当前网页的所有json格式的数据.如下 http://flights.ctrip.com/domesticsearch/search/Sear
-
使用python爬取B站千万级数据
Python(发音:英[?pa?θ?n],美[?pa?θɑ:n]),是一种面向对象.直译式电脑编程语言,也是一种功能强大的通用型语言,已经具有近二十年的发展历史,成熟且稳定.它包含了一组完善而且容易理解的标准库,能够轻松完成很多常见的任务.它的语法非常简捷和清晰,与其它大多数程序设计语言不一样,它使用缩进来定义语句. Python支持命令式程序设计.面向对象程序设计.函数式编程.面向切面编程.泛型编程多种编程范式.与Scheme.Ruby.Perl.Tcl等动态语言一样,Python具备垃圾回收
-
python爬取盘搜的有效链接实现代码
因为盘搜搜索出来的链接有很多已经失效了,影响找数据的效率,因此想到了用爬虫来过滤出有效的链接,顺便练练手~ 这是本次爬取的目标网址http://www.pansou.com,首先先搜索个python,之后打开开发者工具, 可以发现这个链接下的json数据就是我们要爬取的数据了,把多余的参数去掉, 剩下的链接格式为http://106.15.195.249:8011/search_new?q=python&p=1,q为搜索内容,p为页码 以下是代码实现: import requests impor
-

Python爬取京东的商品分类与链接
前言 本文主要的知识点是使用Python的BeautifulSoup进行多层的遍历. 如图所示.只是一个简单的哈,不是爬取里面的隐藏的东西. 示例代码 from bs4 import BeautifulSoup as bs import requests headers = { "host": "www.jd.com", "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWe
-
python爬取热搜制作词云
环境:win10,64位,mysql5.7数据库,python3.9.7,ancod 逻辑流程: 1.首先爬取百度热搜,至少间隔1小时 2.存入文件,避免重复请求,如果本1小时有了不再请求 3.存入数据库,供词云包使用 1.爬取热搜,首先拿到url,使用的包urllib,有教程说urllib2是python2的. '''读取页面''' def readhtml(self,catchUrl): catchUrl=self.catchUrl if not catchUrl else catchUrl
-
python 爬取B站原视频的实例代码
B站原视频爬取,我就不多说直接上代码.直接运行就好. B站是把视频和音频分开.要把2个合并起来使用.这个需要分析才能看出来.然后就是登陆这块是比较难的. import os import re import argparse import subprocess import prettytable from DecryptLogin import login '''B站类''' class Bilibili(): def __init__(self, username, password, **
-
Python爬取数据保存为Json格式的代码示例
python爬取数据保存为Json格式 代码如下: #encoding:'utf-8' import urllib.request from bs4 import BeautifulSoup import os import time import codecs import json #找到网址 def getDatas(): # 伪装 header={'User-Agent':"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.1
-
python爬取豆瓣电影排行榜(requests)的示例代码
''' 爬取豆瓣电影排行榜 设计思路: 1.先获取电影类型的名字以及特有的编号 2.将编号向ajax发送get请求获取想要的数据 3.将数据存放进excel表格中 ''' 环境部署: 软件安装: Python 3.7.6 官网地址:https://www.python.org/ 安装地址:https://www.python.org/ftp/python/3.7.6/python-3.7.6-amd64.exe PyCharm 2020.2.2
-
Python爬取网页的所有内外链的代码
项目介绍 采用广度优先搜索方法获取一个网站上的所有外链. 首先,我们进入一个网页,获取网页的所有内链和外链,再分别进入内链中,获取该内链的所有内链和外链,直到访问完所有内链未知. 代码大纲 1.用class类定义一个队列,先进先出,队尾入队,队头出队: 2.定义四个函数,分别是爬取网页外链,爬取网页内链,进入内链的函数,以及调函数: 3.爬取百度图片(https://image.baidu.com/),先定义两个队列和两个数组,分别来存储内链和外链:程序开始时,先分别爬取当前网页的内链和外链,再
-
使用python爬取抖音app视频的实例代码
记录一下如何用python爬取app数据,本文以爬取抖音视频app为例. 编程工具:pycharm app抓包工具:mitmproxy app自动化工具:appium 运行环境:windows10 思路: 假设已经配置好我们所需要的工具 1.使用mitmproxy对手机app抓包获取我们想要的内容 2.利用appium自动化测试工具,驱动app模拟人的动作(滑动.点击等) 3.将1和2相结合达到自动化爬虫的效果 一.mitmproxy/mitmdump抓包 确保已经安装好了mitmproxy,并
-
python爬取指定微信公众号文章
本文实例为大家分享了python爬取微信公众号文章的具体代码,供大家参考,具体内容如下 该方法是依赖于urllib2库来完成的,首先你需要安装好你的python环境,然后安装urllib2库 程序的起始方法(返回值是公众号文章列表): def openUrl(): print("启动爬虫,打开搜狗搜索微信界面") # 加载页面 url = 'http://weixin.sogou.com/weixin?type=1&s_from=input&query=要爬取的公众号名