python自动化测试之DDT数据驱动的实现代码
时隔已久,再次冒烟,自动化测试工作仍在继续,自动化测试中的数据驱动技术尤为重要,不然咋去实现数据分离呢,对吧,这里就简单介绍下与传统unittest自动化测试框架匹配的DDT数据驱动技术。
话不多说,先撸一波源码,其实整体代码并不多
# -*- coding: utf-8 -*-
# This file is a part of DDT (https://github.com/txels/ddt)
# Copyright 2012-2015 Carles Barrobés and DDT contributors
# For the exact contribution history, see the git revision log.
# DDT is licensed under the MIT License, included in
# https://github.com/txels/ddt/blob/master/LICENSE.md
import inspect
import json
import os
import re
import codecs
from functools import wraps
try:
import yaml
except ImportError: # pragma: no cover
_have_yaml = False
else:
_have_yaml = True
__version__ = '1.2.1'
# These attributes will not conflict with any real python attribute
# They are added to the decorated test method and processed later
# by the `ddt` class decorator.
DATA_ATTR = '%values' # store the data the test must run with
FILE_ATTR = '%file_path' # store the path to JSON file
UNPACK_ATTR = '%unpack' # remember that we have to unpack values
index_len = 5 # default max length of case index
try:
trivial_types = (type(None), bool, int, float, basestring)
except NameError:
trivial_types = (type(None), bool, int, float, str)
def is_trivial(value):
if isinstance(value, trivial_types):
return True
elif isinstance(value, (list, tuple)):
return all(map(is_trivial, value))
return False
def unpack(func):
"""
Method decorator to add unpack feature.
"""
setattr(func, UNPACK_ATTR, True)
return func
def data(*values):
"""
Method decorator to add to your test methods.
Should be added to methods of instances of ``unittest.TestCase``.
"""
global index_len
index_len = len(str(len(values)))
return idata(values)
def idata(iterable):
"""
Method decorator to add to your test methods.
Should be added to methods of instances of ``unittest.TestCase``.
"""
def wrapper(func):
setattr(func, DATA_ATTR, iterable)
return func
return wrapper
def file_data(value):
"""
Method decorator to add to your test methods.
Should be added to methods of instances of ``unittest.TestCase``.
``value`` should be a path relative to the directory of the file
containing the decorated ``unittest.TestCase``. The file
should contain JSON encoded data, that can either be a list or a
dict.
In case of a list, each value in the list will correspond to one
test case, and the value will be concatenated to the test method
name.
In case of a dict, keys will be used as suffixes to the name of the
test case, and values will be fed as test data.
"""
def wrapper(func):
setattr(func, FILE_ATTR, value)
return func
return wrapper
def mk_test_name(name, value, index=0):
"""
Generate a new name for a test case.
It will take the original test name and append an ordinal index and a
string representation of the value, and convert the result into a valid
python identifier by replacing extraneous characters with ``_``.
We avoid doing str(value) if dealing with non-trivial values.
The problem is possible different names with different runs, e.g.
different order of dictionary keys (see PYTHONHASHSEED) or dealing
with mock objects.
Trivial scalar values are passed as is.
A "trivial" value is a plain scalar, or a tuple or list consisting
only of trivial values.
"""
# Add zeros before index to keep order
index = "{0:0{1}}".format(index + 1, index_len)
if not is_trivial(value):
return "{0}_{1}".format(name, index)
try:
value = str(value)
except UnicodeEncodeError:
# fallback for python2
value = value.encode('ascii', 'backslashreplace')
test_name = "{0}_{1}_{2}".format(name, index, value)
return re.sub(r'\W|^(?=\d)', '_', test_name)
def feed_data(func, new_name, test_data_docstring, *args, **kwargs):
"""
This internal method decorator feeds the test data item to the test.
"""
@wraps(func)
def wrapper(self):
return func(self, *args, **kwargs)
wrapper.__name__ = new_name
wrapper.__wrapped__ = func
# set docstring if exists
if test_data_docstring is not None:
wrapper.__doc__ = test_data_docstring
else:
# Try to call format on the docstring
if func.__doc__:
try:
wrapper.__doc__ = func.__doc__.format(*args, **kwargs)
except (IndexError, KeyError):
# Maybe the user has added some of the formating strings
# unintentionally in the docstring. Do not raise an exception
# as it could be that user is not aware of the
# formating feature.
pass
return wrapper
def add_test(cls, test_name, test_docstring, func, *args, **kwargs):
"""
Add a test case to this class.
The test will be based on an existing function but will give it a new
name.
"""
setattr(cls, test_name, feed_data(func, test_name, test_docstring,
*args, **kwargs))
def process_file_data(cls, name, func, file_attr):
"""
Process the parameter in the `file_data` decorator.
"""
cls_path = os.path.abspath(inspect.getsourcefile(cls))
data_file_path = os.path.join(os.path.dirname(cls_path), file_attr)
def create_error_func(message): # pylint: disable-msg=W0613
def func(*args):
raise ValueError(message % file_attr)
return func
# If file does not exist, provide an error function instead
if not os.path.exists(data_file_path):
test_name = mk_test_name(name, "error")
test_docstring = """Error!"""
add_test(cls, test_name, test_docstring,
create_error_func("%s does not exist"), None)
return
_is_yaml_file = data_file_path.endswith((".yml", ".yaml"))
# Don't have YAML but want to use YAML file.
if _is_yaml_file and not _have_yaml:
test_name = mk_test_name(name, "error")
test_docstring = """Error!"""
add_test(
cls,
test_name,
test_docstring,
create_error_func("%s is a YAML file, please install PyYAML"),
None
)
return
with codecs.open(data_file_path, 'r', 'utf-8') as f:
# Load the data from YAML or JSON
if _is_yaml_file:
data = yaml.safe_load(f)
else:
data = json.load(f)
_add_tests_from_data(cls, name, func, data)
def _add_tests_from_data(cls, name, func, data):
"""
Add tests from data loaded from the data file into the class
"""
for i, elem in enumerate(data):
if isinstance(data, dict):
key, value = elem, data[elem]
test_name = mk_test_name(name, key, i)
elif isinstance(data, list):
value = elem
test_name = mk_test_name(name, value, i)
if isinstance(value, dict):
add_test(cls, test_name, test_name, func, **value)
else:
add_test(cls, test_name, test_name, func, value)
def _is_primitive(obj):
"""Finds out if the obj is a "primitive". It is somewhat hacky but it works.
"""
return not hasattr(obj, '__dict__')
def _get_test_data_docstring(func, value):
"""Returns a docstring based on the following resolution strategy:
1. Passed value is not a "primitive" and has a docstring, then use it.
2. In all other cases return None, i.e the test name is used.
"""
if not _is_primitive(value) and value.__doc__:
return value.__doc__
else:
return None
def ddt(cls):
"""
Class decorator for subclasses of ``unittest.TestCase``.
Apply this decorator to the test case class, and then
decorate test methods with ``@data``.
For each method decorated with ``@data``, this will effectively create as
many methods as data items are passed as parameters to ``@data``.
The names of the test methods follow the pattern
``original_test_name_{ordinal}_{data}``. ``ordinal`` is the position of the
data argument, starting with 1.
For data we use a string representation of the data value converted into a
valid python identifier. If ``data.__name__`` exists, we use that instead.
For each method decorated with ``@file_data('test_data.json')``, the
decorator will try to load the test_data.json file located relative
to the python file containing the method that is decorated. It will,
for each ``test_name`` key create as many methods in the list of values
from the ``data`` key.
"""
for name, func in list(cls.__dict__.items()):
if hasattr(func, DATA_ATTR):
for i, v in enumerate(getattr(func, DATA_ATTR)):
test_name = mk_test_name(name, getattr(v, "__name__", v), i)
test_data_docstring = _get_test_data_docstring(func, v)
if hasattr(func, UNPACK_ATTR):
if isinstance(v, tuple) or isinstance(v, list):
add_test(
cls,
test_name,
test_data_docstring,
func,
*v
)
else:
# unpack dictionary
add_test(
cls,
test_name,
test_data_docstring,
func,
**v
)
else:
add_test(cls, test_name, test_data_docstring, func, v)
delattr(cls, name)
elif hasattr(func, FILE_ATTR):
file_attr = getattr(func, FILE_ATTR)
process_file_data(cls, name, func, file_attr)
delattr(cls, name)
return cls
ddt源码
通过源码的说明,基本可以了解个大概了,其核心用法就是利用装饰器来实现功能的复用及扩展延续,以此来实现数据驱动,现在简单介绍下其主要函数的基本使用场景。
1. @ddt(cls) ,其服务于unittest类装饰器,主要功能是判断该类中是否具有相应 ddt 装饰的方法,如有则利用自省机制,实现测试用例命名 mk_test_name、 数据回填 _add_tests_from_data 并通过 add_test 添加至unittest的容器TestSuite中去,然后执行得到testResult,流程非常清晰。
def ddt(cls):
for name, func in list(cls.__dict__.items()):
if hasattr(func, DATA_ATTR):
for i, v in enumerate(getattr(func, DATA_ATTR)):
test_name = mk_test_name(name, getattr(v, "__name__", v), i)
test_data_docstring = _get_test_data_docstring(func, v)
if hasattr(func, UNPACK_ATTR):
if isinstance(v, tuple) or isinstance(v, list):
add_test(
cls,
test_name,
test_data_docstring,
func,
*v
)
else:
# unpack dictionary
add_test(
cls,
test_name,
test_data_docstring,
func,
**v
)
else:
add_test(cls, test_name, test_data_docstring, func, v)
delattr(cls, name)
elif hasattr(func, FILE_ATTR):
file_attr = getattr(func, FILE_ATTR)
process_file_data(cls, name, func, file_attr)
delattr(cls, name)
return cls
2. @file_data(PATH) ,其主要是通过 process_file_data 方法实现数据解析,这里通过 _add_tests_from_data 实现测试数据回填,通过源码可以得知目前文件只支持 Yaml 和 JSON 数据文件,想扩展其它文件比如 xml 等直接改源码就行
def process_file_data(cls, name, func, file_attr):
"""
Process the parameter in the `file_data` decorator.
"""
cls_path = os.path.abspath(inspect.getsourcefile(cls))
data_file_path = os.path.join(os.path.dirname(cls_path), file_attr)
def create_error_func(message): # pylint: disable-msg=W0613
def func(*args):
raise ValueError(message % file_attr)
return func
# If file does not exist, provide an error function instead
if not os.path.exists(data_file_path):
test_name = mk_test_name(name, "error")
test_docstring = """Error!"""
add_test(cls, test_name, test_docstring,
create_error_func("%s does not exist"), None)
return
_is_yaml_file = data_file_path.endswith((".yml", ".yaml"))
# Don't have YAML but want to use YAML file.
if _is_yaml_file and not _have_yaml:
test_name = mk_test_name(name, "error")
test_docstring = """Error!"""
add_test(
cls,
test_name,
test_docstring,
create_error_func("%s is a YAML file, please install PyYAML"),
None
)
return
with codecs.open(data_file_path, 'r', 'utf-8') as f:
# Load the data from YAML or JSON
if _is_yaml_file:
data = yaml.safe_load(f)
else:
data = json.load(f)
_add_tests_from_data(cls, name, func, data)
3. @date(* value ),简单粗暴的直观实现数据驱动,直接将可迭代对象传参,进行数据传递,数据之间用逗号“ , ”隔离,代表一组数据,此时如果实现 unpack, 则更加细化的实现数据驱动,切记每组数据对应相应的形参。
def unpack(func):
"""
Method decorator to add unpack feature.
"""
setattr(func, UNPACK_ATTR, True)
return func
def data(*values):
"""
Method decorator to add to your test methods.
Should be added to methods of instances of ``unittest.TestCase``.
"""
global index_len
index_len = len(str(len(values)))
return idata(values)
def idata(iterable):
"""
Method decorator to add to your test methods.
Should be added to methods of instances of ``unittest.TestCase``.
"""
def wrapper(func):
setattr(func, DATA_ATTR, iterable)
return func
return wrapper
4. 实例
# -*- coding: utf-8 -*-
__author__ = '暮辞'
import time,random
from ddt import ddt, data, file_data, unpack
import unittest
import json
from HTMLTestRunner import HTMLTestRunner
@ddt
class Demo(unittest.TestCase):
@file_data("./migrations/test.json")
def test_hello(self, a, **b):
'''
测试hello
'''
print a
print b
#print "hello", a, type(a)
if isinstance(a, list):
self.assertTrue(True, "2")
else:
self.assertTrue(True, "3")
@data([1, 2, 3, 4])
def test_world(self, *b):
'''
测试world
'''
print b
self.assertTrue(True)
@data({"test1":[1, 2], "test2":[3, 4]}, {"test1":[1, 2],"test2":[3, 4]})
@unpack
def test_unpack(self, **a):
'''
测试unpack
'''
print a
self.assertTrue(True)
if __name__ == "__main__":
suit = unittest.TestSuite()
test = unittest.TestLoader().loadTestsFromTestCase(Demo)
suit.addTests(test)
#suit.addTests(test)
with open("./migrations/Demo.html", "w") as f:
result = HTMLTestRunner(stream=f, description=u"Demo测试报告", title=u"Demo测试报告")
result.run(suit)
测试结果:
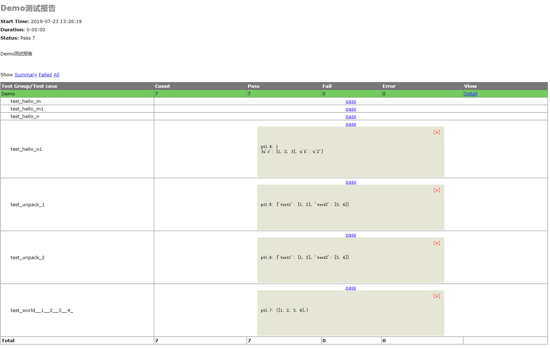
至此关于ddt的数据驱动暂时告一段落了,后面还会介绍基于excel、sql等相关的数据驱动内容,并进行对比总结,拭目以待~
总结
以上所述是小编给大家介绍的python自动化测试之DDT数据驱动的实现代码,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
python ddt数据驱动最简实例代码
在接口自动化测试中,往往一个接口的用例需要考虑 正确的.错误的.异常的.边界值等诸多情况,然后你需要写很多个同样代码,参数不同的用例.如果测试接口很多,不但需要写大量的代码,测试数据和代码柔合在一起,可维护性也会变的很差.数据驱动可以完美的将代码和测试数据分开,将代码进行分装,提高复用性,测试数据维护在本地文件或数据库. 使用python做接口自动化,首要任务是搭建一个自动化测试框架,其中unittest+ddt是一个不错的选择,下文主要介绍ddt在unittest下的使用. ddt包含两个方法
-

利用Python如何实现数据驱动的接口自动化测试
前言 大家在接口测试的过程中,很多时候会用到对CSV的读取操作,本文主要说明Python3对CSV的写入和读取.下面话不多说了,来一起看看详细的介绍吧. 1.需求 某API,GET方法,token,mobile,email三个参数 token为必填项 mobile,email 必填其中1项 mobile为手机号,email为email格式 2.方案 针对上面的API,在做接口测试时,需要的测试用例动辄会多达10+, 这个时候采用数据驱动的方式将共性的内容写入配置文件或许会更合适. 这里考虑把AP
-
python unittest实现api自动化测试
项目测试对于一个项目的重要性,大家应该都知道吧,写python的朋友,应该都写过自动化测试脚本. 最近正好负责公司项目中的api测试,下面写了一个简单的例子,对API 测试进行梳理. 首先,编写restful api接口文件 testpost.py,包含了get,post,put方法 #!/usr/bin/env python # -*- coding: utf-8 -*- from flask import request from flask_restful import Resource
-
Python http接口自动化测试框架实现方法示例
本文实例讲述了Python http接口自动化测试框架实现方法.分享给大家供大家参考,具体如下: 一.测试需求描述 对服务后台一系列的http接口功能测试. 输入:根据接口描述构造不同的参数输入值 输出:XML文件 eg:http://xxx.com/xxx_product/test/content_book_list.jsp?listid=1 二.实现方法 1.选用Python脚本来驱动测试 2.采用Excel表格管理测试数据,包括用例的管理.测试数据录入.测试结果显示等等,这个需要封装一个E
-
selenium+python自动化测试之使用webdriver操作浏览器的方法
WebDriver简介 selenium从2.0开始集成了webdriver的API,提供了更简单,更简洁的编程接口.selenium webdriver的目标是提供一个设计良好的面向对象的API,提供了更好的支持进行web-app测试.从这篇博客开始,将学习使用如何使用python调用webdriver框架对浏览器进行一系列的操作 打开浏览器 在selenium+python自动化测试(一)–环境搭建中,运行了一个测试脚本,脚本内容如下: from selenium import webdri
-
selenium python 实现基本自动化测试的示例代码
安装selenium 打开命令控制符输入:pip install -U selenium 火狐浏览器安装firebug:www.firebug.com,调试所有网站语言,调试功能 Selenium IDE 是嵌入到Firefox 浏览器中的一个插件,实现简单的浏览器操 作的录制与回放功能,IDE 录制的脚本可以可以转换成多种语言,从而帮助我们快速的开发脚本,下载地址:https://addons.mozilla.org/en-US/firefox/addon/selenium-ide/ 如何使用
-
python3+selenium自动化测试框架详解
背景 为了更好的发展自身的测试技能,应对测试行业以及互联网行业的迭代变化.自学python以及自动化测试. 虽然在2017年已经开始接触了selenium,期间是断断续续执行自动化测试,因为还有其他测试任务,培训任务要执行- 前期建议大家能够学习python基本语法(python基础教程) 任务 搭建自动化测试框架,并能有效方便的进行测试,维护成本也要考虑其中. 过程 我的自动化框架可能不成熟,因为是自学的.请多包涵.也请大佬指导~ common 包含:基本的公共方法类,比如HTML报告.Log
-
python自动化测试之DDT数据驱动的实现代码
时隔已久,再次冒烟,自动化测试工作仍在继续,自动化测试中的数据驱动技术尤为重要,不然咋去实现数据分离呢,对吧,这里就简单介绍下与传统unittest自动化测试框架匹配的DDT数据驱动技术. 话不多说,先撸一波源码,其实整体代码并不多 # -*- coding: utf-8 -*- # This file is a part of DDT (https://github.com/txels/ddt) # Copyright 2012-2015 Carles Barrobés and DDT con
-
python自动化测试之连接几组测试包实例
本文实例讲述了python自动化测试之连接几组测试包的方法,分享给大家供大家参考.具体方法如下: 具体代码如下: class RomanNumeralConverter(object): def __init__(self): self.digit_map = {"M":1000, "D":500, "C":100, "L":50, "X":10, "V":5, "I"
-
python自动化测试之setUp与tearDown实例
本文实例讲述了python自动化测试之setUp与tearDown的用法,分享给大家供大家参考.具体如下: 实例代码如下: class RomanNumeralConverter(object): def __init__(self): self.digit_map = {"M":1000, "D":500, "C":100, "L":50, "X":10, "V":5, "I
-
Python自动化测试之异常处理机制实例详解
目录 一.前言 二.异常处理合集 2.1 异常处理讲解 2.2 异常捕获 2.3 异常捕获原理 2.4 特定异常捕获 2.5 异常捕获的处理 2.6 except.Exception与BaseException 2.7 finally用法 2.8 异常信息的打印输出 三.总结 一.前言 今天笔者还是想要讲python中的基础,主要讲解Python中异常介绍.捕获.处理相关知识点内容,只有学好了这些才能为后续自动化测试框架搭建及日常维护做铺垫,废话不多说我们直接进入主题吧. 二.异常处理合集 2.
-
Python自动化测试之登录脚本的实现
目录 环境准备 1.安装selenium模块 2.安装浏览器驱动器 代码 1.登录代码 2.xpath定位元素标签 环境准备 前提已经安装好python.pycharm,配置了对应的环境变量. 1.安装selenium模块 文件–>设置—>项目:script---->python解释器---->+selenium 2.安装浏览器驱动器 以谷歌浏览器为例下载地址:https://chromedriver.chromium.org/downloads(1)先查看谷歌浏览器版本:(2)下
-
python自动化测试之从命令行运行测试用例with verbosity
本文实例讲述了python自动化测试之从命令行运行测试用例with verbosity,分享给大家供大家参考.具体如下: 实例文件recipe3.py如下: class RomanNumeralConverter(object): def __init__(self, roman_numeral): self.roman_numeral = roman_numeral self.digit_map = {"M":1000, "D":500, "C"
-
python自动化测试之异常及日志操作实例分析
本文实例讲述了python自动化测试之异常及日志操作.分享给大家供大家参考,具体如下: 为了保持自动化测试用例的健壮性,异常的捕获及处理,日志的记录对掌握自动化测试执行情况尤为重要,这里便详细的介绍下在自动化测试中使用到的异常及日志,并介绍其详细的用法. 一.日志 打印日志是很多程序的重要需求,良好的日志输出可以帮我们更方便的检测程序运行状态.Python标准库提供了logging模块,切记Logger从来不直接实例化,其好处不言而喻,接下来慢慢讲解Logging模块提供了两种记录日志的方式.
-
微软开源最强Python自动化神器Playwright(不用写一行代码)
相信玩过爬虫的朋友都知道selenium,一个自动化测试的神器工具.写个Python自动化脚本解放双手基本上是常规的操作了,爬虫爬不了的,就用自动化测试凑一凑. 虽然selenium有完备的文档,但也需要一定的学习成本,对于一个纯小白来讲还是有些门槛的. 最近,微软开源了一个项目叫「playwright-python」,简直碉堡了!这个项目是针对Python语言的纯自动化工具,连代码都不用写,就能实现自动化功能. 可能你会觉得有点不可思议,但它就是这么厉害.下面我们一起看下这个神器. 1. Pl
-
selenium+python自动化测试之环境搭建
最近由于公司有一个向谷歌网站上传文件的需求,需要进行web的自动化测试,选择了selenium这个自动化测试框架,以前没有接触过这门技术,所以研究了一下,使用python来实现自动化脚本,从环境搭建到实现脚本运行. selenium是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等.支持自动录制动作和自动
-
selenium+python自动化测试之页面元素定位
上一篇博客selenium+python自动化测试(二)–使用webdriver操作浏览器讲解了使用webdriver操作浏览器的各种方法,可以实现对浏览器进行操作了,接下来就是对浏览器页面中的元素进行操作,操作页面元素,首先要找到操作的元素,对元素进行定位 查看页面源码 要定位页面元素,需要找到页面的源码,IE浏览器中,打开页面后,在页面上点击鼠标右键,会有"查看源代码"的选项,点击后就会进入页面源码页面,在这里就可以找到页面的所有元素 使用Chrome浏览器打开页面后,在浏览器的地