Java IO流 文件传输基础
一、文件的编码
package com.study.io;
/**
* 测试文件编码
*/
public class EncodeDemo {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
String s="好好学习ABC";
byte[] bytes1=s.getBytes();//这是把字符串转换成字符数组,转换成的字节序列用的是项目默认的编码(这里为UTF-8)
for (byte b : bytes1) {
//把字节(转换成了int)以16进制的方式显示
System.out.print(Integer.toHexString(b & 0xff)+" ");//& 0xff是为了把前面的24个0去掉只留下后八位
}
System.out.println();
/*utf-8编码中中文占用3个字节,英文占用1个字节*/
byte[] bytes2 = s.getBytes("utf-8");//这里会有异常展示,我们就throw这个异常
for (byte b : bytes2) {
System.out.print(Integer.toHexString(b & 0xff)+" ");
}
System.out.println();
/*gbk编码中文占用2个字节,英文占用1个字节*/
byte[] bytes3 = s.getBytes("gbk");//这里会有异常展示,我们就throw这个异常
for (byte b : bytes3) {
System.out.print(Integer.toHexString(b & 0xff)+" ");
}
System.out.println();
/*utf-16be编码中文占用2个字节,英文占用2个字节*/
byte[] bytes4 = s.getBytes("utf-16be");//这里会有异常展示,我们就throw这个异常
for (byte b : bytes4) {
System.out.print(Integer.toHexString(b & 0xff)+" ");
}
System.out.println();
/*当你的字节序列是某种编码时,这个时候想把字节序列变成字符串,也需要用这种编码方式,否则会出现乱码*/
String str1=new String(bytes4);//这时会使用项目默认的编码来转换,可能出现乱码
System.out.println(str1);
//要使用字节序列的编码来进行转换
String str2=new String(bytes4,"utf-16be");
System.out.println(str2);
}
}
分析:
* 1. “& 0xff”的解释:
* 0xFF表示的是16进制(十进制是255),表示为二进制就是“11111111”。
* 那么&符表示的是按位数进行与(同为1的时候返回1,否则返回0)
* 2.字节byte与int类型转换:
* Integer.toHexString(b & 0xff)这里先把byte类型的b和0xff进行了运算,然后Integer.toHexString取得了十六进制字符串
* 可以看出b & 0xFF运算后得出的仍然是个int,那么为何要和 0xFF进行与运算呢?直接 Integer.toHexString(b);,将byte强转为int不行吗?答案是不行的.
* 其原因在于:1.byte的大小为8bits而int的大小为32bits;2.java的二进制采用的是补码形式
* Integer.toHexString的参数是int,如果不进行&0xff,那么当一个byte会转换成int时,由于int是32位,而byte只有8位这时会进行补位。。。。。。
* 所以,一个byte跟0xff相与会先将那个byte转化成整形运算,这样,结果中的高的24个比特就总会被清0,于是结果总是我们想要的。
* 3.utf-8编码:中文占用3个字节,英文占用1个字节
* gbk编码:中文占用2个字节,英文占用1个字节
* Java采用双字节编码(就是Java中的一个字符占两个字节)是utf-16be编码。中文占用2个字节,英文占用2个字节
*
* 4.当你的字节序列是某种编码时,这个时候想把字节序列变成字符串,也需要用这种编码方式,否则会出现乱码
* 5.文本文件 就是字节序列。可以是任意编码的字节序列。
* 如果我们在中文机器上直接创建文本文件,那么该文件只认识ANSI编码(例如直接在电脑中创建文本文件)

二、File类的使用
package com.study.io;
import java.io.File;
/**
* File类的使用
*/
public class FileDemo {
/*java.iO.File类表示文件或目录
File类只用于表示文件或目录的信息(名称,大小等),不能用于文件内容的访问。*/
public static void main(String[] args) {
File file=new File("D:\\111");//创建文件对象时指定目录需要用双斜杠,因为“\”是转义字符
/*目录的中间的分隔符可以用双斜杠,也可以用反斜杠,也可以用File.separator设置分隔符*/
// File file1=new File("d:"+File.separator);
// System.out.println(file.exists());//exists()判断文件或文件夹是否存在
if(!file.exists()){//如果文件不存在
file.mkdir();//创建文件夹mkdir(),还有mkdirs()创建多级目录
}else{
file.delete();//删除文件或文件夹
}
//判断是否是一个目录isDirectory,如果是目录返回true,如果不是目录或者目录不存在返回false
System.out.println(file.isDirectory());
//判断是否是一个文件isFile
System.out.println(file.isFile());
File file2=new File("D:\\222","123.txt");
//常用API:
System.out.println(file);//打印的是file.toString()的内容
System.out.println(file.getAbsolutePath());//获取绝对路径
System.out.println(file.getName());//获取文件名称
System.out.println(file2.getName());
System.out.println(file.getParent());//获取父级绝对路径
System.out.println(file2.getParentFile().getAbsolutePath());
}
}
运行结果:
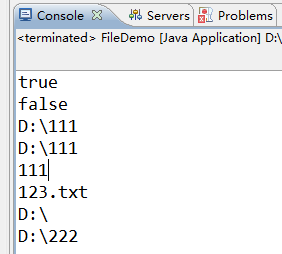
说明:
java.iO.File类表示文件或目录
File类只用于表示文件或目录的信息(名称,大小等),不能用于文件内容的访问。
常用的API:
1.创建File对象:File file=new File(String path);注意:File.seperater();获取系统分隔符,如:“\”.
2.boolean file.exists();是否存在.
3.file.mkdir();或者file.mkdirs();创建目录或多级目录。
4.file.isDirectory()判断是否是目录
file.isFile()判断是否是文件。
5.file.delete();删除文件或目录。
6.file.createNewFile();创建新文件。
7.file.getName()获取文件名称或目录绝对路径。
8.file.getAbsolutePath()获取绝对路径。
9.file.getParent();获取父级绝对路径。
1、遍历目录
package com.study.io;
import java.io.File;
import java.io.IOException;
/**
* File工具类
* 列出File类的常用操作,比如:过滤、遍历等操作
*/
public class FileUtils {
/**
* 列出指定目录下(包括其子目录)的所有文件
* @param dir
* @throws IOException
*/
public static void listDirectory(File dir) throws IOException{
if(!dir.exists()){//exists()方法用于判断文件或目录是否存在
throw new IllegalArgumentException("目录:"+dir+"不存在");
}
if(!dir.isDirectory()){//isDirectory()方法用于判断File类的对象是否是目录
throw new IllegalArgumentException(dir+"不是目录");
}
/*String[] fileNames = dir.list();//list()方法用于列出当前目录下的子目录和文件(直接是子目录的名称,不包含子目录下的内容),返回的是字符串数组
for (String string : fileNames) {
System.out.println(string);
}*/
//如果要遍历子目录下的内容就需要构造成File对象做递归操作,File提供了直接返回File对象的API
File[] listFiles = dir.listFiles();//返回的是直接子目录(文件)的抽象
if(listFiles !=null && listFiles.length >0){
for (File file : listFiles) {
/*System.out.println(file);*/
if(file.isDirectory()){
//递归
listDirectory(file);
}else{
System.out.println(file);
}
}
}
}
}
测试类:
public class FileUtilsTest {
public static void main(String[] args) throws IOException {
FileUtils.listDirectory(new File("D:\\ioStudy"));
}
}
运行结果:
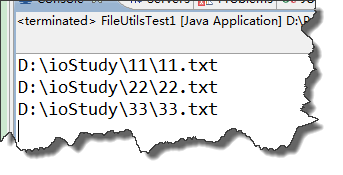
三、RandomAccessFile类的使用
RandomAccessFile:java提供的对文件内容的访问,既可以读文件,也可以写文件。
RandomAccessFile支持随机访问文件,可以访问文件的任意位置。
注意 Java文件的模型:
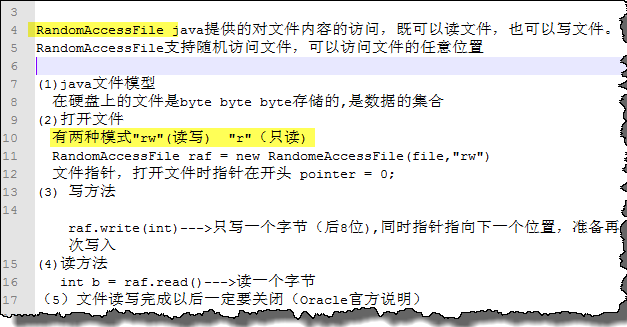
运行结果:
1
12
[65, 66, 127, -1, -1, -1, 127, -1, -1, -1, -42, -48]
7f
ff
ff
ff
7f
ff
ff
ff
d6
d0
四、字节流(FileInputStream、FileOutputStream)
IO流可分为输入流和输出流。
这里又可分为字节流和字符流。


代码示例:
package com.study.io;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* IO工具类
* ❤文件输入输出流:
* FileInputStream-->具体实现了在文件上读取数据
* FileOutputStream-->实现了向文件中写出byte数据的方法
* ❤数据输入输出流:
* DataOutputStream / DataInputStream:对"流"功能的扩展,可以更加方面的读取int,long,字符等类型数据
* DataOutputStream writeInt()/writeDouble()/writeUTF()
* ❤字节缓冲流:
* BufferedInputStream & BufferedOutputStream
* 这两个流类位IO提供了带缓冲区的操作,一般打开文件进行写入或读取操作时,都会加上缓冲,这种流模式提高了IO的性能
* 比如:从应用程序中把输入放入文件,相当于将一缸水倒入到另一个缸中:
FileOutputStream--->write()方法相当于一滴一滴地把水“转移”过去
DataOutputStream-->writeXxx()方法会方便一些,相当于一瓢一瓢把水“转移”过去
BufferedOutputStream--->write方法更方便,相当于一瓢一瓢先放入桶中(即缓存区),再从桶中倒入到另一个缸中,性能提高了
*/
public class IOUtil {
/**
* 读取指定文件内容,按照16进制输出到控制台
* 并且每输出10个byte换行
* @param fileName
* 单字节读取不适合大文件,大文件效率很低
*/
public static void printHex(String fileName)throws IOException{
//把文件作为字节流进行都操作
FileInputStream in=new FileInputStream(fileName);
int b;
int i=1;
while((b=in.read())!=-1){
/* 0xff换成2进制就是8个1,这样与的话,其实就是取到了字符的低8位。
* oxf就是15, 小于15的数会转换成一个16进制数,
* 你的代码里希望是固定的两个16进制数,所以当只会产生一个时要加个0*/
if(b <= 0xf){
//单位数前面补0
System.out.print("0");
}
//Integer.toHexString(b)将整型b转换为16进制表示的字符串
System.out.print(Integer.toHexString(b)+" ");
if(i++%10==0){
System.out.println();
}
}
in.close();//文件读写完成以后一定要关闭
}
/**
* 批量读取,对大文件而言效率高,也是我们最常用的读文件的方式
* @param fileName
* @throws IOException
*/
public static void printHexByByteArray(String fileName)throws IOException{
FileInputStream in = new FileInputStream(fileName);
byte[] buf = new byte[8 * 1024];
/*从in中批量读取字节,放入到buf这个字节数组中,
* 从第0个位置开始放,最多放buf.length个
* 返回的是读到的字节的个数
*/
/*int bytes = in.read(buf,0,buf.length);//一次性读完,说明字节数组足够大
int j = 1;
for(int i = 0; i < bytes;i++){
System.out.print(Integer.toHexString(buf[i] & 0xff)+" ");
if(j++%10==0){
System.out.println();
}
}*/
int bytes = 0;
int j = 1;
while((bytes = in.read(buf,0,buf.length))!=-1){
for(int i = 0 ; i < bytes;i++){
System.out.print(Integer.toHexString(buf[i] & 0xff)+" ");
/**
* & 0xff:byte类型8位,int类型32位,为了避免数据转换错误,通过&0xff将高24位清零
*/
if(j++%10==0){
System.out.println();
}
}
}
in.close();
}
/**
* 文件拷贝,字节批量读取
* @param srcFile
* @param destFile
* @throws IOException
*/
public static void copyFile(File srcFile, File destFile) throws IOException {
if (!srcFile.exists()) {
throw new IllegalArgumentException("文件:" + srcFile + "不存在");
}
if (!srcFile.isFile()) {
throw new IllegalArgumentException(srcFile + "不是文件");
}
FileInputStream in = new FileInputStream(srcFile);
FileOutputStream out = new FileOutputStream(destFile);//文件不存在时,会直接创建;如果存在,删除后建
byte[] buf = new byte[8 * 1024];//批量读写
int b;
while ((b = in.read(buf, 0, buf.length)) != -1) {//read(buf,0,buf.length)带参数的read返回的是字节的总长度;当全部读完后返回的是-1;
out.write(buf, 0, b);
out.flush();// 最好加上
}
in.close();
out.close();
}
/**
* 进行文件的拷贝,利用带缓冲的字节流
* @param srcFile
* @param destFile
* @throws IOException
*/
public static void copyFileByBuffer(File srcFile,File destFile)throws IOException{
if(!srcFile.exists()){
throw new IllegalArgumentException("文件:"+srcFile+"不存在");
}
if(!srcFile.isFile()){
throw new IllegalArgumentException(srcFile+"不是文件");
}
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(srcFile));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(destFile));
int c ;
while((c = bis.read())!=-1){
bos.write(c);
bos.flush();//刷新缓冲区
}
bis.close();
bos.close();
}
/**
* 单字节,不带缓冲进行文件拷贝
* @param srcFile
* @param destFile
* @throws IOException
*/
public static void copyFileByByte(File srcFile,File destFile)throws IOException{
if(!srcFile.exists()){
throw new IllegalArgumentException("文件:"+srcFile+"不存在");
}
if(!srcFile.isFile()){
throw new IllegalArgumentException(srcFile+"不是文件");
}
FileInputStream in = new FileInputStream(srcFile);
FileOutputStream out = new FileOutputStream(destFile);
int c ;
while((c = in.read())!=-1){//read()不带参数的read返回的是读到的字节内容;当全部读完后返回的都是是-1;
out.write(c);
out.flush();
}
in.close();
out.close();
}
}
测试类:
package com.study.io;
import java.io.File;
import java.io.IOException;
import org.junit.Test;
public class IOUtilTest {
@Test
public void testPrintHex() {
try {
IOUtil.printHex("D:\\Javaio\\FileUtils.java");
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void testPrintHexByByteArray() {
try {
long start = System.currentTimeMillis();//当前时间与协调世界时 1970 年 1 月 1 日午夜之间的时间差(以毫秒为单位测量)
//IOUtil.printHexByByteArray("e:\\javaio\\FileUtils.java");
//IOUtil.printHex("e:\\javaio\\1.mp3");
IOUtil.printHexByByteArray("e:\\javaio\\1.mp3");
System.out.println();
long end = System.currentTimeMillis();
System.out.println(end - start);
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void testCopyFile(){
try {
IOUtil.copyFile(new File("d:\\javaio\\1.txt"), new File("d:\\javaio\\1copy.txt"));
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void testCopyFileByBuffer(){
try {
long start = System.currentTimeMillis();
/*IOUtil.copyFileByByte(new File("e:\\javaio\\1.mp3"), new File(
"e:\\javaio\\2.mp3"));*/ //两万多毫秒
/*IOUtil.copyFileByBuffer(new File("e:\\javaio\\1.mp3"), new File(
"e:\\javaio\\3.mp3"));//一万多毫秒*/
IOUtil.copyFile(new File("e:\\javaio\\1.mp3"), new File(
"e:\\javaio\\4.mp3"));//7毫秒
long end = System.currentTimeMillis();
System.out.println(end - start );
} catch (IOException e) {
e.printStackTrace();
}
}
}
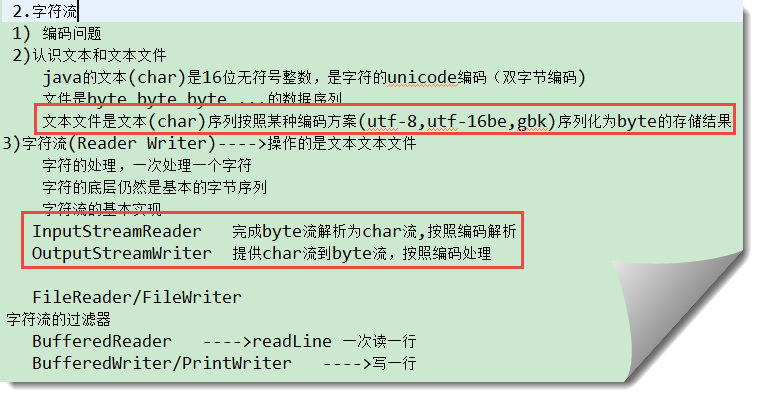
五、字符流
package com.study.io;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
public class IsrAndOswDemo {
public static void main(String[] args)throws IOException {
FileInputStream in = new FileInputStream("e:\\javaio\\utf8.txt");
InputStreamReader isr = new InputStreamReader(in,"utf-8");//默认项目的编码,操作的时候,要写文件本身的编码格式
FileOutputStream out = new FileOutputStream("e:\\javaio\\utf81.txt");
OutputStreamWriter osw = new OutputStreamWriter(out,"utf-8");
/*int c ;
while((c = isr.read())!=-1){
System.out.print((char)c);
}*/
char[] buffer = new char[8*1024];
int c;
/*批量读取,放入buffer这个字符数组,从第0个位置开始放置,最多放buffer.length个返回的是读到的字符的个数*/
while(( c = isr.read(buffer,0,buffer.length))!=-1){
String s = new String(buffer,0,c);
System.out.print(s);
osw.write(buffer,0,c);
osw.flush();
}
isr.close();
osw.close();
}
}
字符流之文件读写流(FileReader/FileWriter)

字符流的过滤器

六、对象的序列化和反序列化

示例:


注意:

相关推荐
-
浅析Java基于Socket的文件传输案例
本文实例介绍了Java基于Socket的文件传输案例,分享给大家供大家参考,具体内容如下 1.Java代码 package com.wf.demo.socket.socketfile; import java.net.*; import java.io.*; /** * 2.socket的Util辅助类 * * @author willson * */ public class ClientSocket { private String ip; private int port; private
-
Java基于Socket的文件传输实现方法
本文实例讲述了Java基于Socket的文件传输实现方法.分享给大家供大家参考,具体如下: 1. Java代码如下: package sterning; import java.io.BufferedInputStream; import java.io.DataInputStream; import java.io.DataOutputStream; import java.io.File; import java.io.FileInputStream; import java.net.Ser
-

Java基于TCP方式的二进制文件传输
一个基于Java Socket协议之上文件传输的完整示例,基于TCP通信完成. 除了基于TCP的二进制文件传输,还演示了JAVA Swing的一些编程技巧,Demo程序 实现主要功能有以下几点: 1.基于Java Socket的二进制文件传输(包括图片,二进制文件,各种文档work,PDF) 2.SwingWorker集合JProgressBar显示实时传输/接受完成的百分比 3.其它一些Swing多线程编程技巧 首先来看一下整个Dome的Class之间的关系图: 下面按照上图来详细解释各个类的
-
基于socket和javaFX简单文件传输工具
本文实例介绍了基于socket和javaFX简单文件传输工具,分享给大家供大家参考,具体内容如下 package application; import java.io.File; import org.james.component.ButtonBox; import org.james.component.FileReceiverGrid; import org.james.component.FileSenderGrid; import javafx.application.Applica
-
Java Socket实现文件传输示例代码
最近学Socket学上瘾了,就写了一个简单的文件传输程序. 客户端设计思路:客户端与服务端建立连接,选择客户端本地文件,先将文件名及大小等属性发送给服务端,再将文件通过流的方式传输给服务端.传输的进度打印到控制台中,直到传输完成. 服务端设计思路:服务端接收客户端的请求(阻塞式),每接收到一个客户端请求连接后,就新开一个处理文件的线程,开始写入流,将文件到服务器的指定目录下,并与传输过来的文件同名. 下面是客户端和服务端的代码实现: 客户端代码: import java.io.DataOutpu
-
java 实现局域网文件传输的实例
java 实现局域网文件传输的实例 本文主要实现局域网文件传输的实例,对java 的TCP知识,文件读写,Socket等知识的理解应用,很好的实例,大家参考下, 实现代码: ClientFile.java /** * 更多资料欢迎浏览凯哥学堂官网:http://kaige123.com * @author 小沫 */ package com.tcp.file; import java.io.File; import java.io.FileInputStream; import java.io.
-
Java IO流 文件传输基础
一.文件的编码 package com.study.io; /** * 测试文件编码 */ public class EncodeDemo { /** * @param args * @throws Exception */ public static void main(String[] args) throws Exception { String s="好好学习ABC"; byte[] bytes1=s.getBytes();//这是把字符串转换成字符数组,转换成的字节序列用的是
-
Java IO流 文件的编码实例代码
•文件的编码 package cn.test; import java.io.UnsupportedEncodingException; public class Demo15 { public static void main(String[] args) throws UnsupportedEncodingException { String str = "你好ABC123"; byte[] b1 = str.getBytes();//转换成字节系列用的是项目默认的编码 for (
-
java IO流文件的读写具体实例
引言: 关于java IO流的操作是非常常见的,基本上每个项目都会用到,每次遇到都是去网上找一找就行了,屡试不爽.上次突然一个同事问了我java文件的读取,我一下子就懵了第一反应就是去网上找,虽然也能找到,但自己总感觉不是很踏实,所以今天就抽空看了看java IO流的一些操作,感觉还是很有收获的,顺便总结些资料,方便以后进一步的学习... IO流的分类:1.根据流的数据对象来分:高端流:所有的内存中的流都是高端流,比如:InputStreamReader 低端流:所有的外界设备中的流都是低端流
-
Java Io File文件操作基础教程
目录 File 类概述 File对象文件操作 File静态方法 获取各种路径 路径整合 获取classpath路径 (常用) 获取Tomcat的bin目录 常用功能 创建目录 创建文件 判断文件或文件夹是否存在 判断是文件还是文件夹 判断是否是绝对路径 判断是否是隐藏文件 删除文件或者整个文件夹 File 类概述 Java IO API中的FIle类可以让你访问底层文件系统,通过File类,你可以做到以下几点: 检测文件是否存在 读取文件长度 重命名或移动文件 删除文件 检测某个路径是文件还是目
-
Java IO流学习总结之文件传输基础
一.Java IO流总览 二.File类 2.1 常用API package pkg1; import java.io.File; import java.io.IOException; /** * @author Administrator * @date 2021/4/2 */ public class FileDemo { public static void main(String[] args) { // 了解构造函数,可查看API File file = new File("d:\\
-
Java中IO流文件读取、写入和复制的实例
//构造文件File类 File f=new File(fileName); //判断是否为目录 f.isDirectory(); //获取目录下的文件名 String[] fileName=f.list(); //获取目录下的文件 File[] files=f.listFiles(); 1.Java怎么读取文件 package com.yyb.file; import java.io.File; import java.io.FileInputStream; import java.io.In
-
java IO流将一个文件拆分为多个子文件代码示例
文件分割与合并是一个常见需求,比如:上传大文件时,可以先分割成小块,传到服务器后,再进行合并.很多高大上的分布式文件系统(比如:google的GFS.taobao的TFS)里,也是按block为单位,对文件进行分割或合并. 看下基本思路: 如果有一个大文件,指定分割大小后(比如:按1M切割) step 1: 先根据原始文件大小.分割大小,算出最终分割的小文件数N step 2: 在磁盘上创建这N个小文件 step 3: 开多个线程(线程数=分割文件数),每个线程里,利用RandomAccessF
-
Java IO流之原理分类与节点流文件操作详解
目录 IO流简介 IO流原理 流的分类 IO 流体系 节点流和处理流 节点流操作 IO流简介 I/O是Input/Output的缩写, I/O技术是非常实用的技术,用于处理设备之间的数据传输.如读/写文件,网络通讯等. Java程序中,对于数据的输入/输出操作以"流(stream)" 的方式进行. java.io包下提供了各种"流"类和接口,用以获取不同种类的数据,并通过标准的方法输入或输出数据. IO流原理 输入input:读取外部数据(磁盘.光盘等存储设备的数据
-
Java IO流对文件File操作
目录 什么是文件 常用的文件操作 创建文件 获取文件信息 目录的操作和文件删除 什么是文件 文件,对我们并不陌生,文件是保存数据的地方,比如大家经常使用的word文档,txt文件,exce|文件..都是文件.它既可以保存一-张图片也可以保持视频,声音... 文件流 文件在程序中是以流的形式来操作的. 流:数据在数据源(文件)和程序(内存)之间经历的路径. 输入流:数据从数据源(文件)到程序(内存)的路径. 输出流:数据从程序(内存)到数据源(文件)的路径. 可以把上面的流比作人喝水 从杯子里的水