用好anyproxy提高公众号文章采集效率
影响因素主要会有以下几点:
1、网络环境不佳;
2、手机或模拟器中微信客户端崩溃;
3、其它一些网络传输错误;
因为我比较看重采集系统的运行成本,这个成本包括硬件投入,运算力投入和占用的人工精力。所以必须提高运行的稳定性。因此如果采集中断,必然增加人工精力的成本。所以针对这一点我对anyproxy做了一些进阶的改造,并且借助了其它一些工具提高了运行效率。以下就是具体的解决方法:
一、代码升级
1)微信浏览器白屏
解决方法:修改文件requestHandler.js,还是在rule_default.js同级目录下,(mac系统/usr/local/lib/node_modules/anyproxy/lib/;win系统评论区网友cnbattle提供C:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib)
在代码中找到proxyReq.on("error",function(e){这个函数,并修改内容
//userRes.end();//把这一行注释掉
userRes.end('<script>setTimeout(function(){window.location.reload();},2000);</script>');//插入这一行
这样当发生错误时,会返回一个刷新当前页面的js;这样程序就能继续下去了
2)替换所有图片,减轻浏览器负担
首先需要制作一张非常小的图片,我做的是1x1像素,png透明图;放到任意文件夹里。然后修改文件rule_default.js的代码:
在文件开头有许多var的位置加入以下代码
var fs = require("fs"),
img = fs.readFileSync("/Library/WebServer/Documents/space.png");//代码绝对路径替换成自己的
在下面的代码中找到shouldUseLocalResponse : function(req,reqBody){函数,在函数内插入代码:
if(/mmbiz\.qpic\.cn/i.test(req.url)){
req.replaceLocalFile = true;
return true;
}else{
return false;
}
继续在下面的代码中找到dealLocalResponse : function(req,reqBody,callback){函数,在函数内插入代码:
if(req.replaceLocalFile){
callback(200, {"content-type":"image/png"},img );
}
这三段代码就会将公众号里面的所有图片替换成本地图片,减轻网络传输压力和浏览器占用的内存,有效的提高运行效率;
3)禁止手机或模拟器访问一些无用的和会导致错误的网址
同样在rule_default.js里找到代码replaceRequestOption : function(req,option){函数,在函数内部插入代码:
var newOption = option;
if(/google|btrace/i.test(newOption.headers.host)){//这里面的正则可以替换成自己不希望访问的网址特征字符串,这里面的btrace是一个腾讯视频的域名,经过实践发现特别容易导致浏览器崩溃,所以加在里面了,继续添加可以使用|分割。
newOption.hostname = "127.0.0.1";//这个ip也可以替换成其他的
newOption.port = "80";
}
return newOption;
这个修改之前的文章也提到过了,在这里重新再详细介绍一下。他的用途很多,不同的手机和模拟器都有可能访问一些无用的地址导致设备变慢,通过这个代码就可以阻止访问。
二、使用pm2管理anyproxy进程
pm2 是一个带有负载均衡功能的Node应用的进程管理器.
当你要把你的独立代码利用全部的服务器上的所有CPU,并保证进程永远都活着,0秒的重载, PM2是完美的。它非常适合IaaS结构,但不要把它用于PaaS方案(随后将开发Paas的解决方案).
主要特性:
内建负载均衡(使用Node cluster 集群模块)
后台运行
0秒停机重载,我理解大概意思是维护升级的时候不需要停机.
具有Ubuntu和CentOS 的启动脚本
停止不稳定的进程(避免无限循环)
控制台检测
提供 HTTP API
远程控制和实时的接口API ( Nodejs 模块,允许和PM2进程管理器交互 )
测试过Nodejs v0.11 v0.10 v0.8版本,兼容CoffeeScript,基于Linux 和MacOS.
首先安装pm2
sudo npm install -g pm2
在pm2环境下运行anyproxy
sudo pm2 start anyproxy -x -- -i
现在anyproxy就在pm2的环境中运行了

之后还有几个pm2的命令可以帮助管理和监控anyproxy
//查看运行日志 sudo pm2 logs anyproxy [--lines 10] //关闭anyproxy sudo pm2 delete anyproxy //重启anyproxy sudo pm2 restart anyproxy //监控内存占用 sudo pm2 monit //监控运行状态 sudo pm2 list
特别提示:pm2运行后,终端窗口是可以关闭的。
使用pm2管理anyproxy进程,最重要的目的是:anyproxy因为错误而退出程序之后,pm2可以另anyproxy自动重启。
三、取消sudo密码,并使pm2开机自启
以下内容是在mac环境下的方法,windows也应该有类似的方法,如果了解的网友可以私信发给我。
1)首先取消sudo的密码
运行命令:
sudo visudo
找到代码:
%admin ALL = (ALL) ALL
修改为:
%admin ALL = (ALL) NOPASSWD: ALL
这样sudo的密码就取消掉了,然后就可以将pm2加入到开机自启动中了
2)设置开机自启
在终端中输入命令:
cd touch autoexec.sh vim autoexec.sh
然后进入编辑模式,按键盘字母i开始编辑,粘贴代码:
#!/bin/sh sudo pm2 start anyproxy -x -- -i sudo pm2 monit
编辑完之后,按esc,再键入命令wq保存退出编辑模式。
再执行命令:
chmod 755 autoexec.sh
这样一个可执行文件就建立好了
然后打开mac系统的“系统偏好设置”,找到“用户与群组”,在左侧选择当前用户,右侧选择登录项;然后点击+号,找到当前用户的根目录(可以按shift+command+h快捷键),选择autoexec.sh文件,添加到登录项中,就可以开机自启动了。
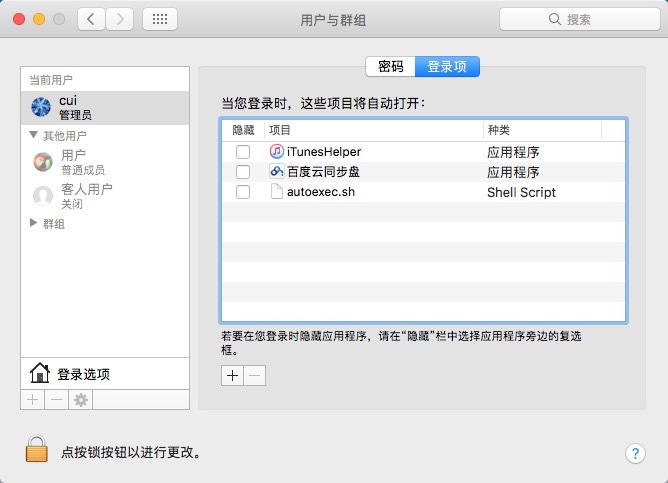
经过以上的几项设置之后,anyproxy系统就会比原来更加稳定,其实主要原因是模拟器或手机的不稳定导致的anyproxy发生的错误。经过实际测试,anyproxy目前可以长时间运行不崩溃。而微信客户端还是在运行大约6个小时之后崩溃,以2秒翻一页的速度,采集总数大约1万个页面。如果不采集阅读量,就可以是1万个公众号的历史消息页。
微信客户端的崩溃现象是退出微信浏览器,停留在查看公众号资料页面。所以如果希望再进一步提高自动化,也可以使用触动精灵之作自动化脚本,定时推出微信浏览器,再点击历史消息页。这样应该就可以实现长时间自动化采集了。
相关推荐
-

用好anyproxy提高公众号文章采集效率
影响因素主要会有以下几点: 1.网络环境不佳: 2.手机或模拟器中微信客户端崩溃: 3.其它一些网络传输错误: 因为我比较看重采集系统的运行成本,这个成本包括硬件投入,运算力投入和占用的人工精力.所以必须提高运行的稳定性.因此如果采集中断,必然增加人工精力的成本.所以针对这一点我对anyproxy做了一些进阶的改造,并且借助了其它一些工具提高了运行效率.以下就是具体的解决方法: 一.代码升级 1)微信浏览器白屏 解决方法:修改文件requestHandler.js,还是在rule_default
-
PHP写微信公众号文章页采集方法
通过搜狗搜索采集公众号历史消息有几个问题: 1.有验证码: 2.历史消息列表只有最近10条群发内容: 3.文章地址是有有效期的: 4.据说批量采集还要换ip: 通过我前面文章的方法就没有这些问题,虽然采集系统搭建不如传统采集器写个规则去爬就可以了那么简单.但是一次搭建好之后批量采集的效率还是可以的.而且采集的文章地址是永久有效的,并且可以采集到一个公众号所有的历史消息. 我们还是从一个公众号文章的链接地址开始看: 1.从微信右上角菜单复制到的链接地址: http://mp.weixin.qq.c
-
python采集微信公众号文章
本文实例为大家分享了python采集微信公众号文章的具体代码,供大家参考,具体内容如下 在python一个子目录里存2个文件,分别是:采集公众号文章.py和config.py. 代码如下: 1.采集公众号文章.py from urllib.parse import urlencode import pymongo import requests from lxml.etree import XMLSyntaxError from requests.exceptions import Connec
-
python爬取微信公众号文章的方法
最近在学习Python3网络爬虫开发实践(崔庆才 著)刚好也学习到他使用代理爬取公众号文章这里,但是照着他的代码写,出现了一些问题.在这里我用到了这本书的前面讲的一些内容进行了完善.(作者写这个代码已经是半年前的事了,但腾讯的网站在这半年前进行了更新) 下面我直接上代码: TIMEOUT = 20 from requests import Request, Session, PreparedRequest import requests from selenium import webdrive
-
Android仿微信公众号文章页面加载进度条
前言: 微信公众号文章详情页面加载的时候,WebView会在头部显示一个进度条,这样做的好处就是用户可以一边加载网页内容的同时也可浏览网页内容,不需要等完全加载完之后才全部显示出来.如何实现呢? 其实很简单,自定义一个WebView就可以实现了. 详细实现步骤如下 : 1.自定义一个ProgressWebView 继续 Webview @SuppressWarnings("deprecation") public class ProgressWebView extends WebVie
-
Python如何爬取微信公众号文章和评论(基于 Fiddler 抓包分析)
背景说明 感觉微信公众号算得是比较难爬的平台之一,不过一番折腾之后还是小有收获的.没有用Scrapy(估计爬太快也有反爬限制),但后面会开始整理写一些实战出来.简单介绍下本次的开发环境: python3 requests psycopg2 (操作postgres数据库) 抓包分析 本次实战对抓取的公众号没有限制,但不同公众号每次抓取之前都要进行分析.打开Fiddler,将手机配置好相关代理,为避免干扰过多,这里给Fiddler加个过滤规则,只需要指定微信域名mp.weixin.qq.com就好:
-
python爬取指定微信公众号文章
本文实例为大家分享了python爬取微信公众号文章的具体代码,供大家参考,具体内容如下 该方法是依赖于urllib2库来完成的,首先你需要安装好你的python环境,然后安装urllib2库 程序的起始方法(返回值是公众号文章列表): def openUrl(): print("启动爬虫,打开搜狗搜索微信界面") # 加载页面 url = 'http://weixin.sogou.com/weixin?type=1&s_from=input&query=要爬取的公众号名
-
python抓取搜狗微信公众号文章
初学python,抓取搜狗微信公众号文章存入mysql mysql表: 代码: import requests import json import re import pymysql # 创建连接 conn = pymysql.connect(host='你的数据库地址', port=端口, user='用户名', passwd='密码', db='数据库名称', charset='utf8') # 创建游标 cursor = conn.cursor() cursor.execute("sel
-
python爬取微信公众号文章
本文实例为大家分享了python爬取微信公众号文章的具体代码,供大家参考,具体内容如下 # -*- coding: utf-8 -*- import requests from bs4 import BeautifulSoup from requests.exceptions import RequestException import time import random import MySQLdb import threading import socket import math soc
-
通过微信公众平台获取公众号文章的方法示例
我之前自己维护了一个公众号,但因为个人关系很久没有更新了,今天上来缅怀一下,却偶然发现了一个获取微信公众号文章的方法. 之前获取方法有很多,通过搜狗.清博.网页端.客户端等等都还可以,这个可能并没有其他的优秀,但是操作简单,很容易理解. so. 首先需要有一个微信公众平台的账号 微信公众平台:https://mp.weixin.qq.com/ 登陆之后,进入首页,点击新建群发. 选择自建图文: 似乎像是公众号运营教学了 进入编辑页面之后,点击超链接 弹出选择框,我们在框中输入对应的公众号名字,即