Python爬虫实例_利用百度地图API批量获取城市所有的POI点
上篇关于爬虫的文章,我们讲解了如何运用Python的requests及BeautifuiSoup模块来完成静态网页的爬取,总结过程,网页爬虫本质就两步:
1、设置请求参数(url,headers,cookies,post或get验证等)访问目标站点的服务器;
2、解析服务器返回的文档,提取需要的信息。
而API的工作机制与爬虫的两步类似,但也有些许不同:
1、API一般只需要设置url即可,且请求方式一般为“get”方式
2、API服务器返回的通常是json或xml格式的数据,解析更简单
也许到这你就明白了,API简直就是开放的“爬虫”呀,可以告诉你,基本就是这个意思。好的,言归正传,本篇我们就演示如何运用Python结合百度地图API来批量获取POI(兴趣点)。
所谓POI(兴趣点),指的是人们感兴趣,比较常去的地方,比如银行、医院、学校等,利用城市的POI的空间属性可以做非常多的事情,至于什么事情呢,此处省略10000字。。。
说干就干,Let's go!
(1)创建百度地图应用
访问百度地图API需要一个信令(AK),打开百度地图开放平台,点击右上角“API控制台”,即进入了百度地图的开发界面。
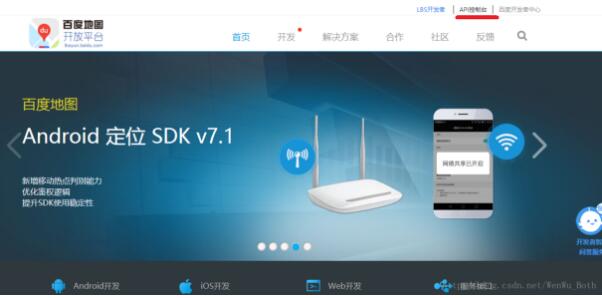
选择“创建应用”-应用类型勾选“浏览器端”–勾选所用到的服务(一般全选即可),此时就创建好了应用账号,得到“AK”
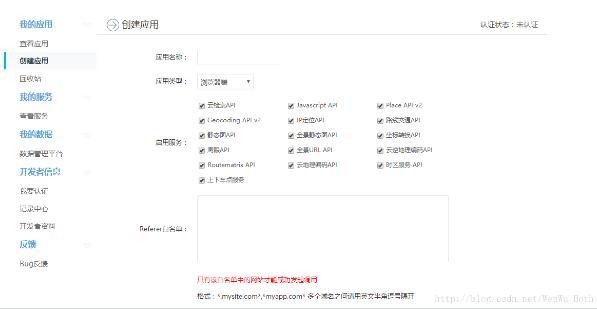
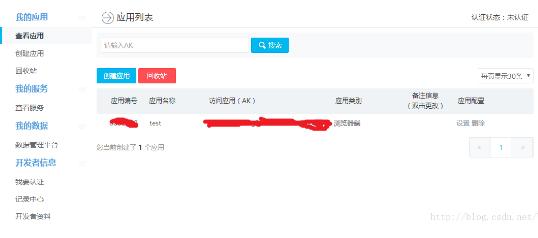
(2)Place API 及Web服务API
打开百度地图API的POI模块,网址:http://lbsyun.baidu.com/index.php?title=webapi/guide/webservice-placeapi,这个页面详细介绍了Place API的请求参数及返回数据的情况。
可以看到,Place API 提供区域检索POI服务与POI详情服务。
1. 区域检索POI服务提供三种区域检索方法:
a.城市内检索(对应JavaScriptAPI的Search方法)
b.矩形检索(对应JavaScript API的SearchInBound方法)
c.圆形区域检索(对应JavaScript的SearchNearBy方法)。
2. POI详情服务提供查询单个POI的详情信息,如好评。
并给出了请求的一个示例,设置检索城市为北京,检索关键字为“饭店”,检索后返回10条数据:
http://api.map.baidu.com/place/v2/search?q=饭店®ion=北京&output=json&ak=您的AK
将上述url粘贴到浏览器里,返回的数据如下:
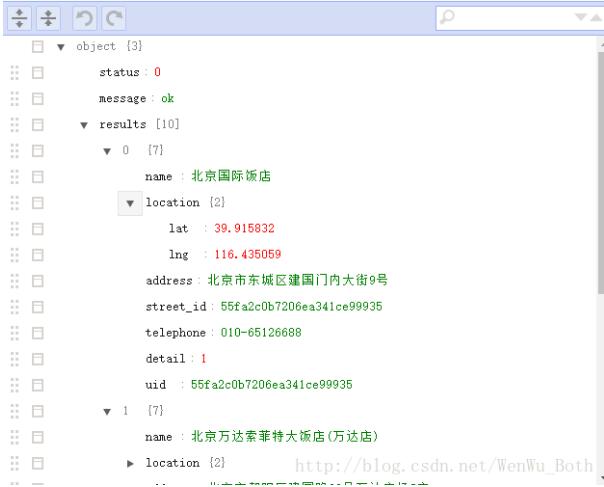
上图是将返回的json数据解析之后的结果,可以看到,服务器返回了10条北京市的饭店的信息,包括饭店名称、经纬度、地址、联系电话等。
具体的参数设置,自行去该网页去看吧,这里就不再赘述,这里我们主要利用“矩形检索”的方式来获取整个城市的特定POI信息,其url格式如下:
http://api.map.baidu.com/place/v2/search?query=美食&page_size=10&page_num=0&scope=1&bounds=39.915,116.404,39.975,116.414&output=json&ak={您的密钥}

通过实验可以发现,一个矩阵区域最多返回400(20*20)个POI点,即page_size = 20 & page_total = 20,虽然官方文档里说一个区域返回760+都不成问题的,但是测试了一下,发现并没有这么多,最多400个。

显然,整个城市不可能仅400个特定描述的POI点,所以我们需要对整个城市进行分片操作,然后每片进行访问,通过Python的循环实现。
(3)获取城市特定POI点集合
比如:我们想获取北京市四环以内所有饭店的信息,即可通过上述步骤借助Python快速实现,废话不多说,直接上代码:
# -*- coding: utf-8 -*-
# Python 2.7
# 提取城市的POI点信息并将其保存至MongoDB数据库
import urllib2
import json
from pymongo import MongoClient
left_bottom = [116.282387,39.835862]; # 设置区域左下角坐标(百度坐标系)
right_top = [116.497405,39.996569]; # 设置区域右上角坐标(百度坐标系)
part_n = 2; # 设置区域网格(2*2)
client = MongoClient('localhost',27001)
db = client.transdata
db.authenticate("user", "password")
col = db.taxi; # 连接集合
url0 = 'http://api.map.baidu.com/place/v2/search?';
x_item = (right_top[0]-left_bottom[0])/part_n;
y_item = (right_top[1]-left_bottom[1])/part_n;
query = '饭店'; #搜索关键词设置
ak = 'xxxxxxxxxxxxxxxxxxxxxx'; #百度地图api信令
n = 0; # 切片计数器
for i in range(part_n):
for j in range(part_n):
left_bottom_part = [left_bottom[0]+i*x_item,left_bottom[1]+j*y_item]; # 切片的左下角坐标
right_top_part = [right_top[0]+i*x_item,right_top[1]+j*y_item]; # 切片的右上角坐标
for k in range(20):
url = url0 + 'query=' + query + '&page_size=20&page_num=' + str(k) + '&scope=1&bounds=' + str(left_bottom_part[1]) + ',' + str(left_bottom_part[0]) + ','+str(right_top_part[1]) + ',' + str(right_top_part[0]) + '&output=json&ak=' + ak;
data = urllib2.urlopen(url);
hjson = json.loads(data.read());
if hjson['message'] == 'ok':
results = hjson['results'];
for m in range(len(results)): # 提取返回的结果
col.insert_one(results[m]);
n += 1;
print '第',str(n),'个切片入库成功'
执行为上述代码,运行结果如下:
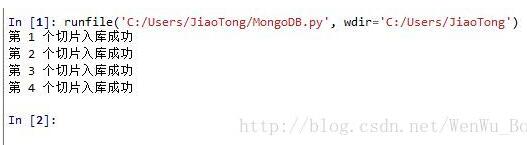

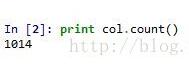
可以看到,我们将北京市四环以内区域分成4个切片来进行处理,之所以分切片处理,主要是单个区域访问最多返回400个结果,当区域较大的时候,区域内往往不止400个,所以讲大区域进行切片处理,最后,我们通过数据聚合操作,发现返回的结果总共1014个。(理论上应该返回1600,实际返回1014,说明切片的数量是合适的)
好的,我们本篇的分享到这里就要结束了,最后只想说,API真的是个好东西,科学地使用它我们可以做出很多炫酷的应用,像现在比较活跃的数据型应用,其数据接口基本都是基于API形式的,后面的分享我们还会用到更多API的,大家一起期待吧,哈哈,今天就到这里了,各位回见。
相关推荐
-

python爬虫入门教程--利用requests构建知乎API(三)
前言 在爬虫系列文章 优雅的HTTP库requests中介绍了 requests 的使用方式,这一次我们用 requests 构建一个知乎 API,功能包括:私信发送.文章点赞.用户关注等,因为任何涉及用户操作的功能都需要登录后才操作,所以在阅读这篇文章前建议先了解Python模拟知乎登录 .现在假设你已经知道如何用 requests 模拟知乎登录了. 思路分析 发送私信的过程就是浏览器向服务器发送一个 HTTP 请求,请求报文包括请求 URL.请求头 Header.还有请求体 Body,只要把
-
Python 爬虫学习笔记之多线程爬虫
XPath 的安装以及使用 1 . XPath 的介绍 刚学过正则表达式,用的正顺手,现在就把正则表达式替换掉,使用 XPath,有人表示这太坑爹了,早知道刚上来就学习 XPath 多省事 啊.其实我个人认为学习一下正则表达式是大有益处的,之所以换成 XPath ,我个人认为是因为它定位更准确,使用更加便捷.可能有的人对 XPath 和正则表达式的区别不太清楚,举个例子来说吧,用正则表达式提取我们的内容,就好比说一个人想去天安门,地址的描述是左边有一个圆形建筑,右边是一个方形建筑,你去找吧,而使
-
Python3多线程爬虫实例讲解代码
多线程概述 多线程使得程序内部可以分出多个线程来做多件事情,充分利用CPU空闲时间,提升处理效率.python提供了两个模块来实现多线程thread 和threading ,thread 有一些缺点,在threading 得到了弥补.并且在Python3中废弃了thread模块,保留了更强大的threading模块. 使用场景 在python的原始解释器CPython中存在着GIL(Global Interpreter Lock,全局解释器锁),因此在解释执行python代码时,会产生互斥锁来限
-
python爬虫爬取快手视频多线程下载功能
环境: python 2.7 + win10 工具:fiddler postman 安卓模拟器 首先,打开fiddler,fiddler作为http/https 抓包神器,这里就不多介绍. 配置允许https 配置允许远程连接 也就是打开http代理 电脑ip: 192.168.1.110 然后 确保手机和电脑是在一个局域网下,可以通信.由于我这边没有安卓手机,就用了安卓模拟器代替,效果一样的. 打开手机浏览器,输入192.168.1.110:8888 也就是设置的代理地址,安装证书之后才能
-
Python多线程爬虫简单示例
python是支持多线程的,主要是通过thread和threading这两个模块来实现的.thread模块是比较底层的模块,threading模块是对thread做了一些包装的,可以更加方便的使用. 虽然python的多线程受GIL限制,并不是真正的多线程,但是对于I/O密集型计算还是能明显提高效率,比如说爬虫. 下面用一个实例来验证多线程的效率.代码只涉及页面获取,并没有解析出来. # -*-coding:utf-8 -*- import urllib2, time import thread
-
Python多线程、异步+多进程爬虫实现代码
安装Tornado 省事点可以直接用grequests库,下面用的是tornado的异步client. 异步用到了tornado,根据官方文档的例子修改得到一个简单的异步爬虫类.可以参考下最新的文档学习下. pip install tornado 异步爬虫 #!/usr/bin/env python # -*- coding:utf-8 -*- import time from datetime import timedelta from tornado import httpclient, g
-
Python多线程爬取豆瓣影评API接口
爬虫库 使用简单的requests库,这是一个阻塞的库,速度比较慢. 解析使用XPATH表达式 总体采用类的形式 多线程 使用concurrent.future并发模块,建立线程池,把future对象扔进去执行即可实现并发爬取效果 数据存储 使用Python ORM sqlalchemy保存到数据库,也可以使用自带的csv模块存在CSV中. API接口 因为API接口存在数据保护情况,一个电影的每一个分类只能抓取前25页,全部评论.好评.中评.差评所有分类能爬100页,每页有20个数据,即最多为
-
python爬虫之百度API调用方法
调用百度API获取经纬度信息. import requests import json address = input('请输入地点:') par = {'address': address, 'key': 'cb649a25c1f81c1451adbeca73623251'} url = 'http://restapi.amap.com/v3/geocode/geo' res = requests.get(url, par) json_data = json.loads(res.text) g
-
Python爬虫实例_利用百度地图API批量获取城市所有的POI点
上篇关于爬虫的文章,我们讲解了如何运用Python的requests及BeautifuiSoup模块来完成静态网页的爬取,总结过程,网页爬虫本质就两步: 1.设置请求参数(url,headers,cookies,post或get验证等)访问目标站点的服务器: 2.解析服务器返回的文档,提取需要的信息. 而API的工作机制与爬虫的两步类似,但也有些许不同: 1.API一般只需要设置url即可,且请求方式一般为"get"方式 2.API服务器返回的通常是json或xml格式的数据,解析更简
-
利用百度地图API获取当前位置信息的实例
利用百度地图API可以做很多事情,个人感觉最核心也是最基础的就是定位功能了.这里分享一个制作的JS可以实现登录网页后定位: <script type="text/javascript"> var map; var gpsPoint; var baiduPoint; var gpsAddress; var baiduAddress; var x; var y; function getLocation() { //根据IP获取城市 var myCity = new BMap.
-
Python爬虫实例_城市公交网络站点数据的爬取方法
爬取的站点:http://beijing.8684.cn/ (1)环境配置,直接上代码: # -*- coding: utf-8 -*- import requests ##导入requests from bs4 import BeautifulSoup ##导入bs4中的BeautifulSoup import os headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML,
-
JS使用百度地图API自动获取地址和经纬度操作示例
本文实例讲述了JS使用百度地图API自动获取地址和经纬度操作.分享给大家供大家参考,具体如下: 在实际工作中我们经常会遇到这样的问题,但是当我们去看百度API的时候往往又达不到我们的要求. 故此,本篇博文讲述如何使用百度地图API自动获取地址和经纬度: 1.HTML代码如下 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xht
-
python通过百度地图API获取某地址的经纬度详解
前言 这几天比较空闲,就接触了下百度地图的API(开发者中心链接地址:http://developer.baidu.com),发现调用还是挺方便的,本文将给大家详细的介绍关于python通过百度地图API获取某地址的经纬度的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 申请百度API 1.打开网页 http://lbsyun.baidu.com/index.php?title=首页 选择功能与服务中的地图,点击左边的获取密匙,然后按照要求申请即可,需要手机和百度账号
-
AngularJs 利用百度地图API 定位当前位置 获取地址信息
第一.申请百度密钥 很简单的几步就搞定 第二.引入文件 <!-- 百度地图定位 --> <script src="http://api.map.baidu.com/components?ak=WUfZTjKPuZ2G5RmgD0Psejv6XOmIEQVQ"></script> <script type="text/javascript" src="http://api.map.baidu.com/api?v=2
-
利用python和百度地图API实现数据地图标注的方法
如题,先上效果图: 主要分为两大步骤 使用python语句,通过百度地图API,对已知的地名抓取经纬度 使用百度地图API官网的html例程,修改数据部分,实现呈现效果 一.使用python语句,通过百度地图API,获取经纬度读取文件信息 import pandas as pd data = pd.read_excel('test_baidu.xlsx') data 图中可以看出,原始数据并没有经纬度. 2. 构建抓取经纬度函数 import json from urllib.request i
-
Android百度地图定位后获取周边位置的实现代码
本文实例讲解Android百度地图定位后获取周边位置的实现代码,分享给大家供大家参考,具体内容如下 效果图: 具体代码: 1.布局文件 <?xml version="1.0" encoding="utf-8"?> <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" android:orientation="vertical&q
-
Python利用百度地图获取两地距离(附demo)
目录 百度地图开放平台 介绍需要用到的API 编写Python程序 1.获取对应地点的经纬度 2.获取两地之间的距离 3.合并函数调用 4.进行简单的功能测试 5.对Excel中的批量地点计算距离 百度地图开放平台 进入百度地图开放平台后,登陆用户,点击上方的控制台,按照提示进行激活后创建服务端类型的应用,应用名任意设置,其中白名单校验不做任何限制可以填写0.0.0.0/0.创建成功后画面应如下图所示,其中访问应用(AK)即途中红色方框圈起来的部分一定要注意不要随意泄漏,后面需要使用到,这是后面
-
Python爬虫实现爬取百度百科词条功能实例
本文实例讲述了Python爬虫实现爬取百度百科词条功能.分享给大家供大家参考,具体如下: 爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成.爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件.爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列.然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页