python利用requests库模拟post请求时json的使用教程
我们都见识过requests库在静态网页的爬取上展现的威力,我们日常见得最多的为get和post请求,他们最大的区别在于安全性上:
1、GET是通过URL方式请求,可以直接看到,明文传输。
2、POST是通过请求header请求,可以开发者工具或者抓包可以看到,同样也是明文的。 3.GET请求会保存在浏览器历史纪录中,还可能会保存在Web的日志中。
两者用法上也有显著差异(援引自知乎):
1、GET用于从服务器端获取数据,包括静态资源(HTML|JS|CSS|Image等等)、动态数据展示(列表数据、详情数据等等)。
2、POST用于向服务器提交数据,比如增删改数据,提交一个表单新建一个用户、或修改一个用户等。
对于Post请求,我们可以通过浏览器开发者工具或者其他外部工具来进行抓包,得到请求的URL、请求头(request headers)以及请求的表单data信息,这三样恰恰是我们用requests模拟post请求时需要的,典型的写法如下:
response=requests.post(url=url,headers=headers,data=data_search)
由于post请求很多时候是配合Ajax(异步加载)技术一起使用的,我们抓包时,可以直接选择XHR(XmlHttpRequest)-ajax的一种对象,帮助我们滤掉其他的一些html、css、js类文件,如下图所示(截取自Chrome):
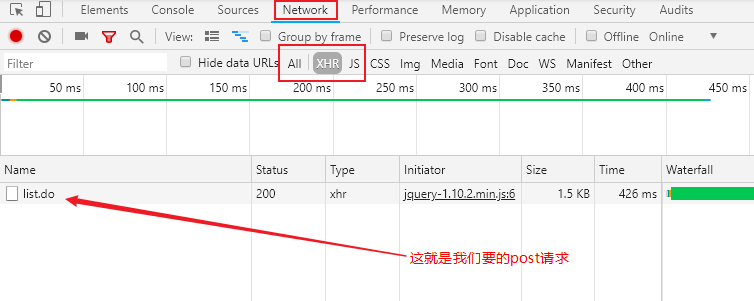
双击点开,就可以在页面右边的Headers页下看到General、Response Headers、Request Headers、Form Data几个模块,
其中General模块能看到请求的方法和请求的URL以及服务器返回的状态码(200(成功) 服务器已成功处理了请求。通常,这表示服务器提供了请求的网页。)
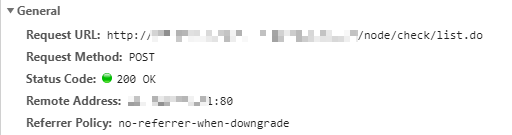
而Response Headers部分,可以看到缓存控制、服务器类型、返回内容格式、有效期等参数(笔者截图所示,返回的为json文件):
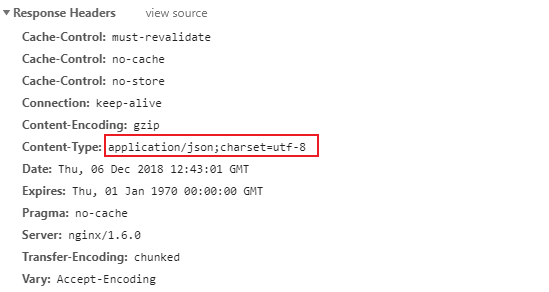
Request Header模块是非常重要的,可以有效地将我们的爬取行为模拟成浏览器行为,应对常规的服务器反爬机制:
其中Content-Type、Cookie以及User-Agent字段较为重要,需要我们构造出来(其他字段大多数时候,不是必须)
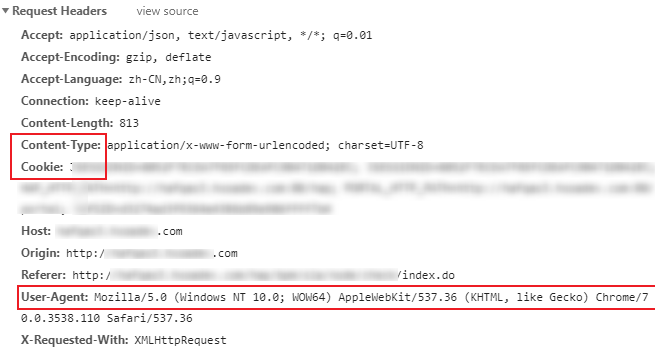
由于Cookie字段记录了用户的登陆信息,每次都不同,且同一个cookie存在一定有效期,当我们结合Selenium来组合爬取页面信息时,可以通过selenium完成网页的登陆校验,然后利用selenium提取出cookie,再转换为浏览器能识别的cookie格式,通常代码如下所示:
cookies = driver.get_cookies() #利用selenium原生方法得到cookies ret='' for cookie in cookies: cookie_name=cookie['name'] cookie_value=cookie['value'] ret=ret+cookie_name+'='+cookie_value+';' #ret即为最终的cookie,各cookie以“;”相隔开
紧接着,我们需要构造headers部分(即请求头),我们挑重点的几个字段进行构造:
headers={
'Host':'**********.com',
'Referer':'http://****************/check/index.do',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
'X-Requested-With':'XMLHttpRequest',
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie':ret #需要登陆后捕获cookie并调用
}
我们在网页中点击“确定”按钮,网页则会异步加载,后台发出post请求,取到json文件并渲染到网页表单中,比如我们根据需求填写了部分字段(这些就是我们post请求的data信息),然后观察后台的form data信息:
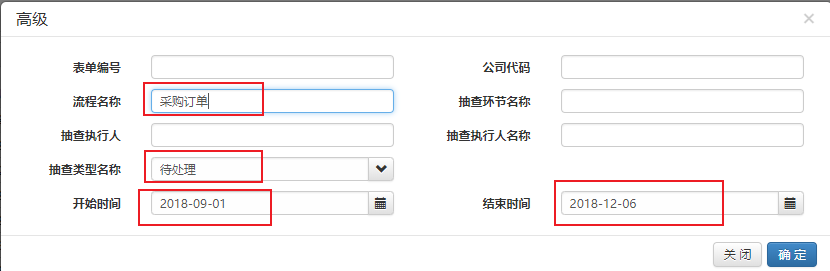
后台Form data 捕获到的data参数如图:
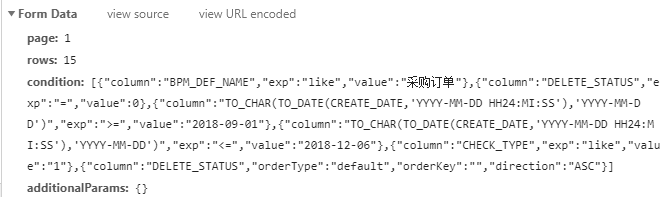
类似于字典格式,其中condition键对应的value较为复杂——列表中包含字典,字典中还有部分函数,其中字符串中既有单引号又有双引号交错。属于关键信息,page决定了网页的翻页在第几页,而rows则表示每次请求的数据限定的最大行数。
本例中问题的关键是,如何把想要的信息(譬如来源于excel配置文件)传递到condition字段对应的值内,确保Form data信息灵活可配置,大抵用法如下:
data_search={
'page':1,
'rows':15,
'condition':
"""[\
{"column":"BPM_DEF_NAME","exp":"like","value":""},\
{"column":"DELETE_STATUS","exp":"=","value":0},\
{"column":"TO_CHAR(TO_DATE(CREATE_DATE,'YYYY-MM-DD HH24:MI:SS'),'YYYY-MM-DD')","exp":">=","value":"YYYY-MM-DD"},\
{"column":"TO_CHAR(TO_DATE(CREATE_DATE,'YYYY-MM-DD HH24:MI:SS'),'YYYY-MM-DD')","exp":"<=","value":"YYYY-MM-DD"},\
{"column":"CHECK_TYPE","exp":"like","value":"2"},\
{"column":"LOCKED_STATUS","exp":"=","value":0},\
{"column":"DELETE_STATUS","orderType":"default","orderKey":"","direction":"ASC"}\
]""", #考虑到该字段已经有单引号、双引号,所以只能用三引号来包住这部分代表字符串
'additionalParams':'{}'
}
data_search_condition=json.loads(data_search['condition']) #将字符串转为列表,方便更新列表(列表中每个元素都是一个单个字典)元素
#刷新字典
data_search_condition[0]['value']=businessName
data_search_condition[2]['value']=str(startDate)
data_search_condition[3]['value']=str(endDate)
data_search['condition']=json.dumps(data_search_condition) #将列表重新转回字符串,作为data_search字典中键“condition”对应的“value”,然后更新字典
上述代码中,data_search其实为字典对象,其键“condition”对应的值(三引号包住部分)为字符串,本质是json格式,我们如何对这部分动态传参呢?
这里需要用到python json包中常用的loads和dumps方法:
1、json.loads()是将json格式对象,转化Python可识别的字典对象。解码python json格式,可以用这个模块的json.loads()函数的解析方法。
2、json.dumps()是将一个Python数据类型列表进行json格式的编码解析,可以将一个list列表对象,进行了json格式的编码转换。
3、json.dump和json.dumps很不同,json.dump主要用来json文件读写,和json.load函数配合使用。
上面实例中,就是将data_search['condition'](json,字符串)转换为列表,然后根据列表定位到底层的每个dict字典,最后根据dict[Key]=value的方法进行更新(传参),更新完之后的列表,再通过json.dumps反向转回字符串,这样整个data_search字典中参数就可以灵活配置,通过外部引入了。
剩下的工作就很简单,交给强大的Requests包完成就好,示例代码如下:
def get_page(data_search,url): #定义页面解析的函数,返回值为json格式
try:
response=requests.post(url=url,headers=headers,data=data_search)
if response.status_code==200:
return response.json()
except requests.ConnectionError as e:
print('Error',e.args)
我们还可以把json格式内容存到本地(data.json)格式文件或者txt文本,并按照特定缩进(indent=4)进行规则排版,格式化内容,此时要用到json.dump()方法,示例代码如下:
for pageNum in range(1,1000):
data_search['page']=str(pageNum)
pageContent=get_page(data_search=data_search,url=url)
with open('data.json','w',encoding="utf-8") as json_file:
json.dump(pageContent,json_file,ensure_ascii = False,indent=4)
if pageContent==None:
print("无符合条件的单据!")
time.sleep(3)
sys.exit(0)
格式化后的json看上去直观不少:
最后感慨一句:爬虫是门技术活,任何一个技术理解地不够透彻,碰到复杂的问题,可能就要花上很长时间去试错,譬如本文示例中的字典、json包几个功能的使用,稍微出错,就无法请求到对的数据!
PS:特别强调一点,有的时候requests.post()方法中data字段不填或者填写有误,服务器有时也会返回200状态码以及相应内容。这种情况下,我们一定要与手工操作得到的json文件进行对比,看看我们的传参(多测试几组不同的参数,看返回json内容是否不同)是否真的起到作用,以免空欢喜一场!
总结
以上所述是小编给大家介绍的python利用requests库模拟post请求时json的使用教程 ,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
Python使用requests发送POST请求实例代码
本文研究的主要是Python使用requests发送POST请求的相关内容,具体介绍如下. 一个http请求包括三个部分,为别为请求行,请求报头,消息主体,类似以下这样: 请求行 请求报头 消息主体 HTTP协议规定post提交的数据必须放在消息主体中,但是协议并没有规定必须使用什么编码方式.服务端通过是根据请求头中的Content-Type字段来获知请求中的消息主体是用何种方式进行编码,再对消息主体进行解析.具体的编码方式包括: application/x-www-form-urlencode
-
Python requests发送post请求的一些疑点
前言 在Python爬虫中,使用requests发送请求,访问指定网站,是常见的做法.一般是发送GET请求或者POST请求,对于GET请求没有什么好说的,而发送POST请求,有很多朋友不是很清楚,主要是因为容易混淆 POST提交的方式 .今天在微信交流群里,就有朋友遇到了这种问题,特地讲解一下. 在HTTP协议中,post提交的数据必须放在消息主体中,但是协议中并没有规定必须使用什么编码方式,从而导致了 提交方式 的不同.服务端根据请求头中的 Content-Type 字段来获知请求中的消息主体
-
Python requests库用法实例详解
本文实例讲述了Python requests库用法.分享给大家供大家参考,具体如下: requests是Python中一个第三方库,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库.它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测试需求.接下来将记录一下requests的使用: 安装 要使用requests库必须先要安装: pip install requests 创建请求 通过requests库发出一个请求非常简单,首先我们先导入
-
python中requests和https使用简单示例
requests 是一个非常小巧全面的库,应用它可以很容易写出与服务器进行交互的程序,今天遇到了一个问题,与服务器交互时,url都是https开头的,都进行了ssl加密处理,这样一来,就不能像之前那样访问http开头的url那样进行处理了. 查了一些资料,可以配置ssl进行验证的文件,方式如下 res = requests.get('https://127.0.0.1:5503/login',cert=('./server.crt', './server.key.unsecure')) 可运行后
-
Python脚本完成post接口测试的实例
一个post类型的接口怎么编写脚本实现 1.打开网页,在fiddler上获取到接口的URL 2.用Python的requests库实现 import requests new_url="http://10.31.143.2:8989/system/systemOrgan/list" params = {"access_token": "807ad226-cbcc-4620-9544-8f53e1d51405"} payload = { "
-
python requests.post带head和body的实例
如下所示: # coding = utf-8 import requests import json host = "http://47.XX.XX.XX:30000" endpoint=r"/api/v1/carXX/addCarXX" url = ''.join([host,endpoint]) headers = \ { "X-Member-Id": "23832170000", "X-Region"
-
python利用requests库模拟post请求时json的使用教程
我们都见识过requests库在静态网页的爬取上展现的威力,我们日常见得最多的为get和post请求,他们最大的区别在于安全性上: 1.GET是通过URL方式请求,可以直接看到,明文传输. 2.POST是通过请求header请求,可以开发者工具或者抓包可以看到,同样也是明文的. 3.GET请求会保存在浏览器历史纪录中,还可能会保存在Web的日志中. 两者用法上也有显著差异(援引自知乎): 1.GET用于从服务器端获取数据,包括静态资源(HTML|JS|CSS|Image等等).动态数据展示(列表
-
python采用requests库模拟登录和抓取数据的简单示例
如果你还在为python的各种urllib和urlibs,cookielib 头疼,或者还还在为python模拟登录和抓取数据而抓狂,那么来看看我们推荐的requests,python采集数据模拟登录必备利器! 这也是python推荐的HTTP客户端库: 本文就以一个模拟登录的例子来加以说明,至于采集大家就请自行发挥吧. 代码很简单,主要是展现python的requests库的简单至极,代码如下: s = requests.session() data = {'user':'用户名','pass
-
python利用requests库进行接口测试的方法详解
前言 之前介绍了接口测试中需要关注得测试点,现在我们来看看如何进行接口测试,现在接口测试工具有很多种,例如:postman,soapui,jemter等等,对于简单接口而言,或者我们只想调试一下,使用工具是非常便捷而且快速得,但是对于更复杂得场景,这些工具虽然也能实现,但是难度要比写代码更大,而且定制化受到工具得功能影响,会 遇到一些障碍,当然我们还要实现自动化等等,鉴于以上因素,我们还是要学会使用代码进行接口测试,便于维护与扩展,或者算是我们知识得补充把~ requests库是python用来
-

python接口自动化使用requests库发送http请求
目录 前言 一.requests库 二.HTTP 请求方法 三.发送GET请求 四.发送POST请求 五.获取响应数据 六.高级操作 6.1文件下载 6.2文件上传 6.3SSL证书验证 6.4保持会话 6.5requests封装 总结 前言 今天笔者想和大家来聊聊python接口自动化如何使用requests库发送http请求,废话呢笔者就不多说了,直接进入正题. 一.requests库 什么是Requests ?Requests 是⽤Python语⾔编写,基于urllib,采⽤Apache2
-
Python3 利用requests 库进行post携带账号密码请求数据的方法
如下所示: import urllib,json,requests url = 'http://127.0.0.1:8000/account/login' headers = {} data = {'username':'asd','pwd':'123456$'} request = requests.post(url=url, data=data,json=True,headers=headers) response = request.content.decode() #需要携带请求头信息的
-
Python爬虫Requests库的使用详情
目录 一.Requests库的7个主要的方法 二.Response对象的属性 三.爬取网页通用代码 四.Resquests库的常见异常 五.Robots协议展示 六.案例展示 一.Requests库的7个主要的方法 1.request() 构造请求,支撑以下的基础方法 2.get() 获取HTML页面的主要方法,对应于http的get 3.head() 获取HTML页面的头部信息的主要方法,对应于http的head -以很少的流量获取索要信息的概要内容 4.post() 向HTML提
-
python 利用浏览器 Cookie 模拟登录的用户访问知乎的方法
首先在火狐浏览器上登录知乎,然后使用火狐浏览器插件 Httpfox 获取 GET 请求的Cookie,这里注意使用状态值为 200(获取成功)的某次GET. 将 Cookies 复制出来,注意这一行非常长,不要人为添加换行符.而且 Cookie 中使用了双引号,最后复制到代码里使用单引号包起来. 使用下边代码检验是否是模拟了登录的用户的请求: import requests import re headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT
-
Python利用PyExecJS库执行JS函数的案例分析
在Web渗透流程的暴力登录场景和爬虫抓取场景中,经常会遇到一些登录表单用DES之类的加密方式来加密参数,也就是说,你不搞定这些前端加密,你的编写的脚本是不可能Login成功的.针对这个问题,现在有三种解决方式: ①看懂前端的加密流程,然后用脚本编写这些方法(或者找开源的源码),模拟这个加密的流程.缺点是:不懂JS的话,看懂的成本就比较高了: ②selenium + Chrome Headless.缺点是:因为是模拟点击,所以效率相对①.③低一些: ③使用语言调用JS引擎来执行JS函数.缺点是
-
python爬虫---requests库的用法详解
requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多 因为是第三方库,所以使用前需要cmd安装 pip install requests 安装完成后import一下,正常则说明可以开始使用了. 基本用法: requests.get()用于请求目标网站,类型是一个HTTPresponse类型 import requests response = requests.get('http://www.baidu.com')print(response.status_c
-
python中requests库+xpath+lxml简单使用
python的requests 它是python的一个第三方库,处理URL比urllib这个库要方便的多,并且功能也很丰富. [可以先看4,5表格形式的说明,再看前面的] 安装 直接用pip安装,anconda是自带这个库的. pip install requests 简单使用 requests的文档 1.简单访问一个url: import requests url='http://www.baidu.com' res = requests.get(url) res.text res.statu