python编写简单爬虫资料汇总
爬虫真是一件有意思的事儿啊,之前写过爬虫,用的是urllib2、BeautifulSoup实现简单爬虫,scrapy也有实现过。最近想更好的学习爬虫,那么就尽可能的做记录吧。这篇博客就我今天的一个学习过程写写吧。
一 正则表达式
正则表达式是一个很强大的工具了,众多的语法规则,我在爬虫中常用的有:
| . | 匹配任意字符(换行符除外) |
| * | 匹配前一个字符0或无限次 |
| ? | 匹配前一个字符0或1次 |
| .* | 贪心算法 |
| .*? | 非贪心算法 |
| (.*?) | 将匹配到的括号中的结果输出 |
| \d | 匹配数字 |
| re.S | 使得.可以匹配换行符 |
常用的方法有:find_all(),search(),sub()
对以上语法方法做以练习,代码见:https://github.com/Ben0825/Crawler/blob/master/re_test.py
二 urllib和urllib2
urllib和urllib2库是学习Python爬虫最基本的库,利用该库,我们可以得到网页的内容,同时,可以结合正则对这些内容提取分析,得到真正想要的结果。
在此将urllib和urllib2结合正则爬取了糗事百科中的作者点赞数内容。
代码见:https://github.com/Ben0825/Crawler/blob/master/qiubai_test.py
三 BeautifulSoup
BeautifulSoup是Python的一个库,最主要的功能是从网页抓取数据,官方介绍是这样的:
Beautiful Soup 提供一些简单的、python 式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup 自动将输入文档转换为 Unicode 编码,输出文档转换为 utf-8 编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup 就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup 已成为和 lxml、html6lib 一样出色的 python 解释器,为用户灵活地提供不同的解析策略或强劲的速度。
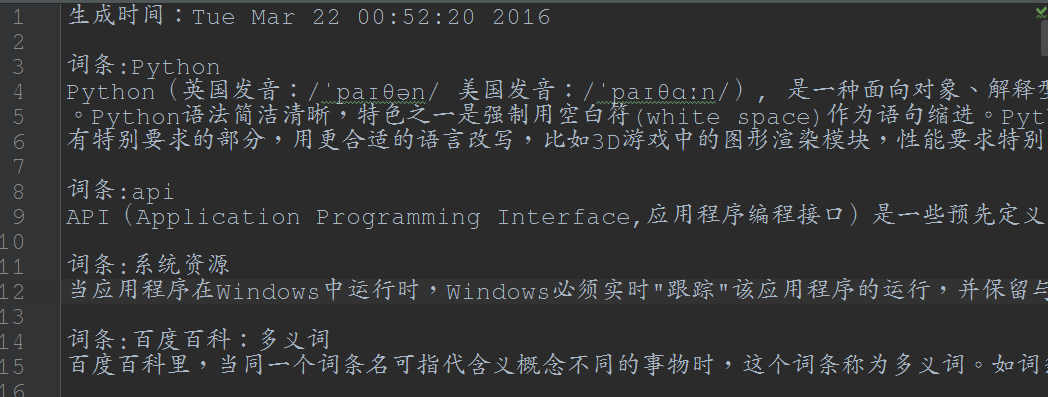
首先:爬取百度百科Python词条下相关的100个页面,爬取的页面值自己设定。
代码详见:https://github.com/Ben0825/Crawler/tree/master/python_baike_Spider
代码运行:
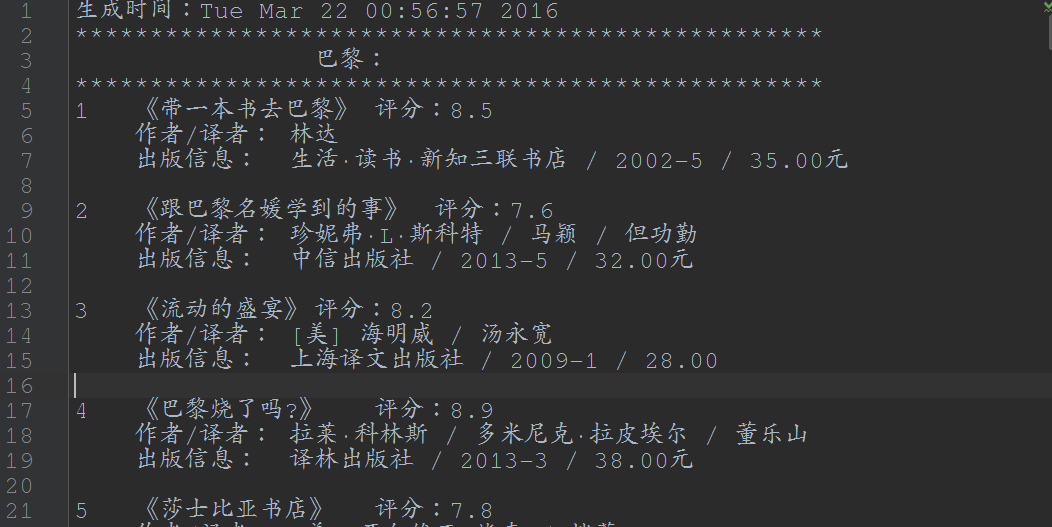
巩固篇,依据豆瓣中图书的标签得到一个书单,同样使用BeautifulSoup。
代码详见:https://github.com/Ben0825/Crawler/blob/master/doubanTag.py
运行结果:
以上就是今天学习的一些内容,爬虫真的很有意思啊,明天继续学scrapy!
相关推荐
-
python编写爬虫小程序
起因 深夜忽然想下载一点电子书来扩充一下kindle,就想起来python学得太浅,什么"装饰器"啊."多线程"啊都没有学到. 想到廖雪峰大神的python教程很经典.很著名.就想找找有木有pdf版的下载,结果居然没找到!!CSDN有个不完整的还骗走了我一个积分!!尼玛!! 怒了,准备写个程序直接去爬廖雪峰的教程,然后再html转成电子书. 过程 过程很有趣呢,用浅薄的python知识,写python程序,去爬python教程,来学习python.想想有点小激动--
-

使用Python编写简单网络爬虫抓取视频下载资源
我第一次接触爬虫这东西是在今年的5月份,当时写了一个博客搜索引擎,所用到的爬虫也挺智能的,起码比电影来了这个站用到的爬虫水平高多了! 回到用Python写爬虫的话题. Python一直是我主要使用的脚本语言,没有之一.Python的语言简洁灵活,标准库功能强大,平常可以用作计算器,文本编码转换,图片处理,批量下载,批量处理文本等.总之我很喜欢,也越用越上手,这么好用的一个工具,一般人我不告诉他... 因为其强大的字符串处理能力,以及urllib2,cookielib,re,threading这些
-
Python爬虫模拟登录带验证码网站
爬取网站时经常会遇到需要登录的问题,这是就需要用到模拟登录的相关方法.python提供了强大的url库,想做到这个并不难.这里以登录学校教务系统为例,做一个简单的例子. 首先得明白cookie的作用,cookie是某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据.因此我们需要用Cookielib模块来保持网站的cookie. 这个是要登陆的地址 http://202.115.80.153/ 和验证码地址 http://202.115.80.153/CheckCode.
-
python3简单实现微信爬虫
使用ghost.py 通过搜搜 的微信搜索来爬取微信公共账号的信息 # -*- coding: utf-8 -*- import sys reload(sys) import datetime import time sys.setdefaultencoding("utf-8") from ghost import Ghost ghost = Ghost(wait_timeout=20) url="http://weixin.sogou.com/gzh?openid=oIWs
-
python模拟新浪微博登陆功能(新浪微博爬虫)
1.主函数(WeiboMain.py): 复制代码 代码如下: import urllib2import cookielib import WeiboEncodeimport WeiboSearch if __name__ == '__main__': weiboLogin = WeiboLogin('×××@gmail.com', '××××')#邮箱(账号).密码 if weiboLogin.Login() == True: print "登陆成功!" 前
-
Python多线程爬虫简单示例
python是支持多线程的,主要是通过thread和threading这两个模块来实现的.thread模块是比较底层的模块,threading模块是对thread做了一些包装的,可以更加方便的使用. 虽然python的多线程受GIL限制,并不是真正的多线程,但是对于I/O密集型计算还是能明显提高效率,比如说爬虫. 下面用一个实例来验证多线程的效率.代码只涉及页面获取,并没有解析出来. # -*-coding:utf-8 -*- import urllib2, time import thread
-
Python实现抓取页面上链接的简单爬虫分享
除了C/C++以外,我也接触过不少流行的语言,PHP.java.javascript.python,其中python可以说是操作起来最方便,缺点最少的语言了. 前几天想写爬虫,后来跟朋友商量了一下,决定过几天再一起写.爬虫里重要的一部分是抓取页面中的链接,我在这里简单的实现一下. 首先我们需要用到一个开源的模块,requests.这不是python自带的模块,需要从网上下载.解压与安装: 复制代码 代码如下: $ curl -OL https://github.com/kennethreitz/
-
python抓取网页图片示例(python爬虫)
复制代码 代码如下: #-*- encoding: utf-8 -*-'''Created on 2014-4-24 @author: Leon Wong''' import urllib2import urllibimport reimport timeimport osimport uuid #获取二级页面urldef findUrl2(html): re1 = r'http://tuchong.com/\d+/\d+/|http://\w+(?<!photos).tuchong.co
-
Python爬虫抓取手机APP的传输数据
大多数APP里面返回的是json格式数据,或者一堆加密过的数据 .这里以超级课程表APP为例,抓取超级课程表里用户发的话题. 1.抓取APP数据包 方法详细可以参考这篇博文:Fiddler如何抓取手机APP数据包 得到超级课程表登录的地址:http://120.55.151.61/V2/StudentSkip/loginCheckV4.action 表单: 表单中包括了用户名和密码,当然都是加密过了的,还有一个设备信息,直接post过去就是. 另外必须加header,一开始我没有加header得
-
零基础写python爬虫之爬虫编写全记录
先来说一下我们学校的网站: http://jwxt.sdu.edu.cn:7777/zhxt_bks/zhxt_bks.html 查询成绩需要登录,然后显示各学科成绩,但是只显示成绩而没有绩点,也就是加权平均分. 显然这样手动计算绩点是一件非常麻烦的事情.所以我们可以用python做一个爬虫来解决这个问题. 1.决战前夜 先来准备一下工具:HttpFox插件. 这是一款http协议分析插件,分析页面请求和响应的时间.内容.以及浏览器用到的COOKIE等. 以我为例,安装在火狐上即可,效果如图:
-
零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻量级的,简单轻巧,并且使用起来非常的方便.使用Scrapy可以很方便的完成网上数据的采集工作,它为我们完成了大量的工作,而不需要自己费大力气去开发. 首先先要回答一个问题. 问:把网站装进爬虫里,总共分几步? 答案很简单,四步: 新建项目 (Project):新建一个新的爬虫项目 明确目标(Item
-
基python实现多线程网页爬虫
一般来说,使用线程有两种模式, 一种是创建线程要执行的函数, 把这个函数传递进Thread对象里,让它来执行. 另一种是直接从Thread继承,创建一个新的class,把线程执行的代码放到这个新的class里. 实现多线程网页爬虫,采用了多线程和锁机制,实现了广度优先算法的网页爬虫. 先给大家简单介绍下我的实现思路: 对于一个网络爬虫,如果要按广度遍历的方式下载,它是这样的: 1.从给定的入口网址把第一个网页下载下来 2.从第一个网页中提取出所有新的网页地址,放入下载列表中 3.按下载列表中的地
-
Python爬虫框架Scrapy安装使用步骤
一.爬虫框架Scarpy简介Scrapy 是一个快速的高层次的屏幕抓取和网页爬虫框架,爬取网站,从网站页面得到结构化的数据,它有着广泛的用途,从数据挖掘到监测和自动测试,Scrapy完全用Python实现,完全开源,代码托管在Github上,可运行在Linux,Windows,Mac和BSD平台上,基于Twisted的异步网络库来处理网络通讯,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片. 二.Scrapy安装指南 我们的安装步骤假设你已经安装一下内容:<1>