详解hbase与hive数据同步
hive的表数据是可以同步到impala中去的。一般impala是提供实时查询操作的,像比较耗时的入库操作我们可以使用hive,然后再将数据同步到impala中。另外,我们也可以在hive中创建一张表同时映射hbase中的表,实现数据同步。
下面,笔者依次进行介绍。
一、impala与hive的数据同步
首先,我们在hive命令行执行showdatabases;可以看到有以下几个数据库:

然后,我们在impala同样执行showdatabases;可以看到:
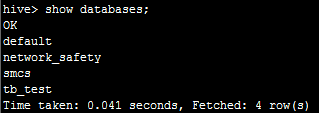
目前的数据库都是一样的。
下面,我们在hive里面执行create databaseqyk_test;创建一个数据库,如下:

然后,我们使用qyk_test这个数据库创建一张表,执行create table user_info(idbigint, account string, name string, age int) row format delimitedfields terminated by ‘\t';如下:

此时,我们已经在hive这边创建好了,然后直接在impala这边执行showdatabases;可以看到:
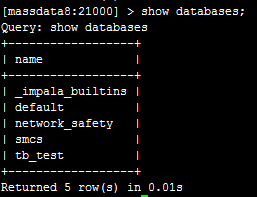
连qyk_test这个数据库都没有。
接下来,我们在impala执行INVALIDATEMETADATA;然后再查询可以看到:

数据库和表都会同步过来。
好了,笔者来做个总结:
如果在hive里面做了新增、删除数据库、表或者数据等更新操作,需要执行在impala里面执行INVALIDATEMETADATA;命令才能将hive的数据同步impala;
如果直接在impala里面新增、删除数据库、表或者数据,会自动同步到hive,无需执行任何命令。
二、hive与hbase的数据同步
首先,我们在hbase中创建一张表create ‘user_sysc', {NAME =>‘info'},然后,我们在hive中执行
CREATEEXTERNALTABLEuser_sysc(keyint,valuestring)ROWFORMATSERDE 'org.apache.hadoop.hive.hbase.HBaseSerDe'
STORED BY'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITHSERDEPROPERTIES( 'serialization.format'='\t','hbase.columns.mapping'=':key,info:value','field.delim'='\t')
TBLPROPERTIES ('hbase.table.name'='user_sysc')
创建一张外部表指向hbase中的表,然后,我们在hive执行insert into tableuser_sysc select id,name fromuser_info;入一步份数据到user_sysc可以看到:
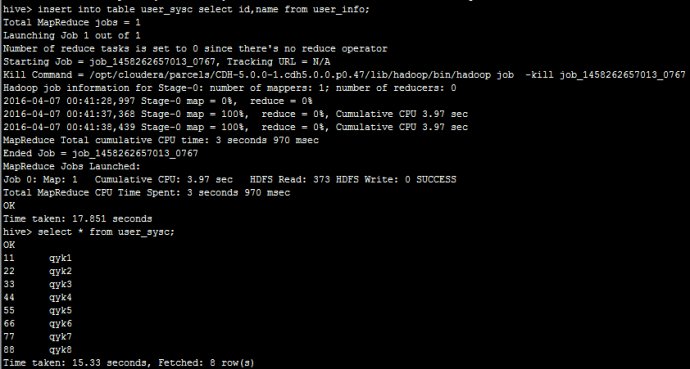
然后,我们在hbase里面执行scan‘user_sysc'可以看到:
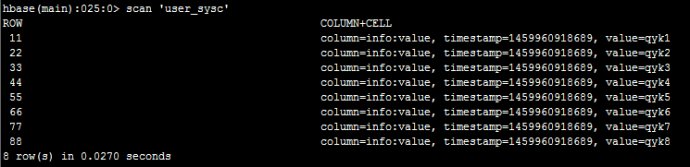
接下来,我们在hbase里面执行deleteall ‘user_sysc',‘11'删掉一条数据,如下:
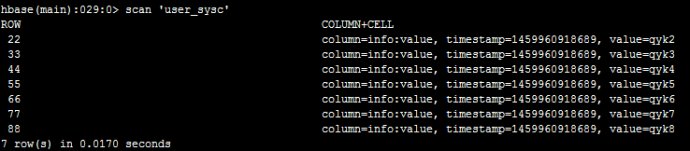
然后,我在hive里面查询看看,如下:

说明自动同步过来了。因此,只要创建hive表时,与hbase中的表做了映射,表名和字段名可以不一致,之后无论在hbase中新增删除数据还是在hive中,都会自动同步。
如果在hive里面是创建的外部表需要在hbase中先创建,内部表则会在hbase中自动创建指定的表名。
因为hive不支持删除等操作,而hbase里面比较方便,所以我们可以采用这种方式。
相关推荐
-
python操作 hbase 数据的方法
配置 thrift python使用的包 thrift 个人使用的python 编译器是pycharm community edition. 在工程中设置中,找到project interpreter, 在相应的工程下,找到package,然后选择 "+" 添加, 搜索 hbase-thrift (Python client for HBase Thrift interface),然后安装包. 安装服务器端thrift. 参考官网,同时也可以在本机上安装以终端使用. thrift Ge
-
基于HBase Thrift接口的一些使用问题及相关注意事项的详解
HBase对于非Java语言提供了Thrift接口支持,这里结合对HBase Thrift接口(HBase版本为0.92.1)的使用经验,总结其中遇到的一些问题及其相关注意事项.1. 字节的存放顺序HBase中,由于row(row key和column family.column qualifier.time stamp)是按照字典序进行排序的,因此,对于short.int.long等类型的数据,通过Bytes.toBytes(-)转换成byte数组后,必须按照大端模式(高字节在低地址,低字节在
-

hbase 简介
概述 HBase是一个构建在HDFS上的分布式列存储系统: HBase是基于GoogleBigTable模型开发的,典型的key/value系统: HBase是ApacheHadoop生态系统中的重要一员,主要用于海量结构化数据存储: 从逻辑上讲,HBase将数据按照表.行和列进行存储. 与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力. Hbase表的特点 大:一个表可以有数十亿行,上百万列: 无模式:每行都有一个可排序的主键和任意多的列,
-
hbase shell基础和常用命令详解
HBase是Google Bigtable的开源实现,它利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为协同服务. 1. 简介 HBase是一个分布式的.面向列的开源数据库,源于google的一篇论文<bigtable:一个结构化数据的分布式存储系统>.HBase是Google Bigtable的开源实现,它利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase
-
Asp.Net Couchbase Memcached图文安装调用开发
安装服务端 服务端下载地址:http://www.couchbase.com/download 选择适合自己的进行下载安装就可以了,我这里选择的是Win7 64. 在安装服务端如果发生如下所示的错误,我在win7 64安装的过程中就遇到了. 这个时候可以先撤销安装.通过CMD命令运行regedit.展开HKEY_LOCAL_MACHINE\Software\Microsoft\ Windows\ CurrentVersion分支,在窗口的右侧区域找到名为"ProgramFilesDir"
-
shell 命令行中操作HBase数据库实例详解
shell 命令行中操作HBase数据库 Shell控制 进入到shell命令行界面,执行hbase命令,并附加shell关键字: [grid@hdnode3 ~]$ hbase shell HBase Shell; enter ¨help¨ for list of supported commands. Type "exit" to leave the HBase Shell Version 0.90.5, r1212209, Fri Dec 9 05:40:36 UTC 2011
-
深入浅析hbase的优点
hbase是运行在Hadoop上的NoSQL数据库,它是一个分布式的和可扩展的大数据仓库,也就是说HBase能够利用HDFS的分布式处理模式,并从Hadoop的MapReduce程序模型中获益.这意味着在一组商业硬件上存储许多具有数十亿行和上百万列的大表.除去Hadoop的优势,HBase本身就是十分强大的数据库,它能够融合key/value存储模式带来实时查询的能力,以及通过MapReduce进行离线处理或者批处理的能力.总的来说,Hbase能够让你在大量的数据中查询记录,也可以从中获得综合分
-
详解hbase与hive数据同步
hive的表数据是可以同步到impala中去的.一般impala是提供实时查询操作的,像比较耗时的入库操作我们可以使用hive,然后再将数据同步到impala中.另外,我们也可以在hive中创建一张表同时映射hbase中的表,实现数据同步. 下面,笔者依次进行介绍. 一.impala与hive的数据同步 首先,我们在hive命令行执行showdatabases;可以看到有以下几个数据库: 然后,我们在impala同样执行showdatabases;可以看到: 目前的数据库都是一样的. 下面,我们
-
详解Mysql如何实现数据同步到Elasticsearch
目录 一.同步原理 二.logstash-input-jdbc 三.go-mysql-elasticsearch 四.elasticsearch-jdbc 五.logstash-input-jdbc实现同步 六.go-mysql-elasticsearch实现同步 七.elasticsearch-jdbc实现同步 一.同步原理 基于Mysql的binlog日志订阅:binlog日志是Mysql用来记录数据实时的变化 Mysql数据同步到ES中分为两种,分别是全量同步和增量同步 全量同步表示第一次
-
详解数据库中跨库数据表的运算
1. 简单合并(FROM) 所谓跨库数据表,是指逻辑上同一张数据表被分别存储在不同数据库中.其原因有可能是因为数据量太大,放在一个数据库难以处理,也可能在业务上就需要将生产库和历史库分开.而不同的数据库,可能只是部署在不同的机器上的同种数据库,也可能是连类型都不同的数据库系统. 在面对跨库数据表,特别是数据库类型都不相同的情况时,数据库自带的工具往往就力所不及了,一般都需要寻找能够很好地支持多数据源类型的第三方工具,而集算器,可以说是其中的佼佼者了.下面,我们就针对几种常见的跨库混合运算情况详细
-
详解vue父子组件状态同步的最佳方式
哈喽!大家好!我是木瓜太香,一位老牌儿前端工程师,平时我们在使用 vue 开发的时候,可能会遇到需要父组件与子组件某个状态需要同步的情况,通常这个是因为我们封装组件的时候有一个相同的状态外面要用,里面也要用,今天我们就来看看怎么优雅的解决这个问题吧! 一般来说我们实现这个功能,只需要父组件通过 props 传递给子组件就好了,但是理想很丰满,现实很骨感,如果我们直接在子组件更改传进来的 props ,不出意外浏览器会给你一坨大红色的报错,因为在 vue 中我们的数据流动是自上而下的,而子组件直接
-
C++详解多线程中的线程同步与互斥量
目录 线程同步 互斥量 线程同步 /* 使用多线程实现买票的案例. 有3个窗口,一共是100张票. */ #include <stdio.h> #include <pthread.h> #include <unistd.h> // 全局变量,所有的线程都共享这一份资源. int tickets = 100; void * sellticket(void * arg) { // 卖票 while(tickets > 0) { usleep(6000); //微秒 p
-
详解HBase表的数据模型
目录 表(Table) 1. rowkey行键 2. Column Family列族 3. Column列 4. cell单元格 5. Timestamp时间戳 理解数据模型各概念的图 HBase是运行在Hadoop集群上的一个数据库,与传统的数据库有严格的ACID(原子性.一致性.隔离性.持久性)要求不一样,HBase降低了这些要求从而获得更好的扩展性,它更适合存储一些非结构化和半结构化的数据. 下面给大家详细介绍HBase表的数据模型,内容如下所示: 表(Table) HBase 中的数据以
-
微信小程序 详解Page中data数据操作和函数调用
微信小程序 详解Page中data数据操作和函数调用 Page() 函数用来注册一个页面.接受一个 object 参数,其指定页面的初始数据.生命周期函数.事件处理函数等. //index.js <pre code_snippet_id="2049407" snippet_file_name="blog_20161214_1_1145312" name="code" class="javascript">Page(
-
实例详解Android文件存储数据方式
总体的来讲,数据存储方式有三种:一个是文件,一个是数据库,另一个则是网络.下面通过本文给大家介绍Android文件存储数据方式. 1.文件存储数据使用了Java中的IO操作来进行文件的保存和读取,只不过Android在Context类中封装好了输入流和输出流的获取方法. 创建的存储文件保存在/data/data/<package name>/files文件夹下. 2.操作. 保存文件内容:通过Context.openFileOutput获取输出流,参数分别为文件名和存储模式. 读取文件内容:通
-
详解Django中views数据查询使用locals()函数进行优化
优化场景 利用视图函数(views)查询数据之后可以通过上下文context.字典.列表等方式将数据传递给HTML模板,由template引擎接收数据并完成解析.但是通过context传递数据可能就存在在不同的视图函数中使用重复的查询语句,所以可以通过将重复查询语句设置全局变量,配合locals()函数进行数据查询与传递. 优化前 def index(request): threatname = '威胁情报展示' url = 'www.testtip.com' allthreat = Threa
-
详解MySQL中的数据类型和schema优化
最近在学习MySQL优化方面的知识.本文就数据类型和schema方面的优化进行介绍. 1. 选择优化的数据类型 MySQL支持的数据类型有很多,而如何选择出正确的数据类型,对于性能是至关重要的.以下几个原则能够帮助确定数据类型: 更小的通常更好 应尽可能使用可以正确存储数据的最小数据类型,够用就好.这样将占用更少的磁盘.内存和缓存,而在处理时也会耗时更少. 简单就好 当两种数据类型都能胜任一个字段的存储工作时,选择简单的那一方,往往是最好的选择.例如整型和字符串,由于整型的操作代价要小于字符,所