Python语言实现机器学习的K-近邻算法
写在前面
额、、、最近开始学习机器学习嘛,网上找到一本关于机器学习的书籍,名字叫做《机器学习实战》。很巧的是,这本书里的算法是用Python语言实现的,刚好之前我学过一些Python基础知识,所以这本书对于我来说,无疑是雪中送炭啊。接下来,我还是给大家讲讲实际的东西吧。
什么是K-近邻算法?
简单的说,K-近邻算法就是采用测量不同特征值之间的距离方法来进行分类。它的工作原理是:存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系,输入没有标签的新数据之后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取出样本集中特征最相似数据的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是K-近邻算法名称的由来。
提问:亲,你造K-近邻算法是属于监督学习还是无监督学习呢?
使用Python导入数据
从K-近邻算法的工作原理中我们可以看出,要想实施这个算法来进行数据分类,我们手头上得需要样本数据,没有样本数据怎么建立分类函数呢。所以,我们第一步就是导入样本数据集合。
建立名为kNN.py的模块,写入代码:
from numpy import * import operator def createDataSet(): group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) labels = ['A','A','B','B'] return group, labels
代码中,我们需要导入Python的两个模块:科学计算包NumPy和运算符模块。NumPy函数库是Python开发环境的一个独立模块,大多数Python版本里没有默认安装NumPy函数库,因此这里我们需要单独安装这个模块。
下载地址:http://sourceforge.net/projects/numpy/files/
有很多的版本,这里我选择的是numpy-1.7.0-win32-superpack-python2.7.exe。
实现K-近邻算法
K-近邻算法的具体思想如下:
(1)计算已知类别数据集中的点与当前点之间的距离
(2)按照距离递增次序排序
(3)选取与当前点距离最小的k个点
(4)确定前k个点所在类别的出现频率
(5)返回前k个点中出现频率最高的类别作为当前点的预测分类
Python语言实现K-近邻算法的代码如下:
# coding : utf-8
from numpy import *
import operator
import kNN
group, labels = kNN.createDataSet()
def classify(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistances = distances.argsort()
classCount = {}
for i in range(k):
numOflabel = labels[sortedDistances[i]]
classCount[numOflabel] = classCount.get(numOflabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
my = classify([0,0], group, labels, 3)
print my
运算结果如下:
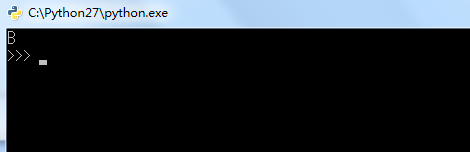
输出结果是B:说明我们新的数据([0,0])是属于B类。
代码详解
相信有很多朋友们对上面这个代码有很多不理解的地方,接下来,我重点讲解几个此函数的关键点,以方便读者们和我自己回顾一下这个算法代码。
classify函数的参数:
inX:用于分类的输入向量
dataSet:训练样本集合
labels:标签向量
k:K-近邻算法中的k
shape:是array的属性,描述一个多维数组的维度
tile(inX, (dataSetSize,1)):把inX二维数组化,dataSetSize表示生成数组后的行数,1表示列的倍数。整个这一行代码表示前一个二维数组矩阵的每一个元素减去后一个数组对应的元素值,这样就实现了矩阵之间的减法,简单方便得不让你佩服不行!
axis=1:参数等于1的时候,表示矩阵中行之间的数的求和,等于0的时候表示列之间数的求和。
argsort():对一个数组进行非降序排序
classCount.get(numOflabel,0) + 1:这一行代码不得不说的确很精美啊。get():该方法是访问字典项的方法,即访问下标键为numOflabel的项,如果没有这一项,那么初始值为0。然后把这一项的值加1。所以Python中实现这样的操作就只需要一行代码,实在是很简洁高效。
后话
K-近邻算法(KNN)原理以及代码实现差不多就这样了,接下来的任务就是更加熟悉它,争取达到裸敲的地步。
以上所述上就是本文的全部内容了,希望大家能够喜欢。
相关推荐
-

Python聚类算法之DBSACN实例分析
本文实例讲述了Python聚类算法之DBSACN.分享给大家供大家参考,具体如下: DBSCAN:是一种简单的,基于密度的聚类算法.本次实现中,DBSCAN使用了基于中心的方法.在基于中心的方法中,每个数据点的密度通过对以该点为中心以边长为2*EPs的网格(邻域)内的其他数据点的个数来度量.根据数据点的密度分为三类点: 核心点:该点在邻域内的密度超过给定的阀值MinPs. 边界点:该点不是核心点,但是其邻域内包含至少一个核心点. 噪音点:不是核心点,也不是边界点. 有了以上对数据点的划分,聚合可
-
简介二分查找算法与相关的Python实现示例
二分查找Binary Search的思想: 以有序表表示静态查找表时,查找函数可以用二分查找来实现. 二分查找(Binary Search)的查找过程是:先确定待查记录所在的区间,然后逐步缩小区间直到找到或找不到该记录为止. 1二分查找的时间复杂度是O(log(n)),最坏情况下的时间复杂度是O(n). 假设 low 指向区间下界,high 指向区间上界,mid 指向区间的中间位置,则 mid = (low + high) / 2; 具体过程: 1.先将关键字与 mid 指向的元素比较,如果相
-
python实现的DES加密算法和3DES加密算法实例
本文实例讲述了python实现的DES加密算法和3DES加密算法.分享给大家供大家参考.具体实现方法如下: ############################################################################# # Documentation # ############################################################################# # Author: Todd Whitema
-
Python聚类算法之凝聚层次聚类实例分析
本文实例讲述了Python聚类算法之凝聚层次聚类.分享给大家供大家参考,具体如下: 凝聚层次聚类:所谓凝聚的,指的是该算法初始时,将每个点作为一个簇,每一步合并两个最接近的簇.另外即使到最后,对于噪音点或是离群点也往往还是各占一簇的,除非过度合并.对于这里的"最接近",有下面三种定义.我在实现是使用了MIN,该方法在合并时,只要依次取当前最近的点对,如果这个点对当前不在一个簇中,将所在的两个簇合并就行: 单链(MIN):定义簇的邻近度为不同两个簇的两个最近的点之间的距离. 全链(MAX
-
Python实现的最近最少使用算法
本文实例讲述了Python实现的最近最少使用算法.分享给大家供大家参考.具体如下: # lrucache.py -- a simple LRU (Least-Recently-Used) cache class # Copyright 2004 Evan Prodromou <evan@bad.dynu.ca> # Licensed under the Academic Free License 2.1 # Licensed for ftputil under the revised BSD
-
python实现中文分词FMM算法实例
本文实例讲述了python实现中文分词FMM算法.分享给大家供大家参考.具体分析如下: FMM算法的最简单思想是使用贪心算法向前找n个,如果这n个组成的词在词典中出现,就ok,如果没有出现,那么找n-1个...然后继续下去.假如n个词在词典中出现,那么从n+1位置继续找下去,直到句子结束. import re def PreProcess(sentence,edcode="utf-8"): sentence = sentence.decode(edcode) sentence=re.s
-
python选择排序算法实例总结
本文实例总结了python选择排序算法.分享给大家供大家参考.具体如下: 代码1: def ssort(V): #V is the list to be sorted j = 0 #j is the "current" ordered position, starting with the first one in the list while j != len(V): #this is the replacing that ends when it reaches the end o
-
Python实现LRU算法的2种方法
LRU:least recently used,最近最少使用算法.它的使用场景是:在有限的空间中存储对象时,当空间满时,会按一定的原则删除原有的对象,常用的原则(算法)有LRU,FIFO,LFU等.在计算机的Cache硬件,以及主存到虚拟内存的页面置换,还有Redis缓存系统中都用到了该算法.我在一次面试和一个笔试时,也遇到过这个问题. LRU的算法是比较简单的,当对key进行访问时(一般有查询,更新,增加,在get()和set()两个方法中实现即可)时,将该key放到队列的最前端(或最后端)就
-
Python聚类算法之基本K均值实例详解
本文实例讲述了Python聚类算法之基本K均值运算技巧.分享给大家供大家参考,具体如下: 基本K均值 :选择 K 个初始质心,其中 K 是用户指定的参数,即所期望的簇的个数.每次循环中,每个点被指派到最近的质心,指派到同一个质心的点集构成一个.然后,根据指派到簇的点,更新每个簇的质心.重复指派和更新操作,直到质心不发生明显的变化. # scoding=utf-8 import pylab as pl points = [[int(eachpoint.split("#")[0]), in
-
Python基于DES算法加密解密实例
本文实例讲述了Python基于DES算法加密解密实现方法.分享给大家供大家参考.具体实现方法如下: #coding=utf-8 from functools import partial import base64 class DES(object): """ DES加密算法 interface: input_key(s, base=10), encode(s), decode(s) """ __ip = [ 58,50,42,34,26,18,
-
Python字符串匹配算法KMP实例
本文实例讲述了Python字符串匹配算法KMP.分享给大家供大家参考.具体如下: #!/usr/bin/env python #encoding:utf8 def next(pattern): p_len = len(pattern) pos = [-1]*p_len j = -1 for i in range(1, p_len): while j > -1 and pattern[j+1] != pattern[i]: j = pos[j] if pattern[j+1] == pattern