Python 操作pdf pdfplumber读取PDF写入Exce
目录
- 1. Python 操作pdf(pdfplumber读取PDF写入Exce)
- 1.1 安装pdfplumber模块库
- 1.2 常用操作
- 1.2.1 Python读取pdf文件案例
- 1.2.2 Python读取pdf文件代码
- 1.2.3 Python读取pdf文件存入Excel代码
1. Python 操作pdf(pdfplumber读取PDF写入Exce)
1.1 安装pdfplumber模块库
安装pdfplumber:
pip install pdfplumber
pdfplumber.PDF类
pdfplumber.PDF类表示单个PDF ,并具有两个主要属性:
| 属性 | 说明 |
|---|---|
| pdf.metadata | 从PDF的Info中获取元数据键/值对字典。通常包括"CreationDate,“ModDater","Producer"等 |
| pdf.pages | 返回一个包含pdfplumber. Page实例的列表,每一一个实例代表PDF每一页的信息 |
pdfplumber.Page类
pdfplumber.Page类常用属性
| 属性page_ number | 说明 |
|---|---|
| .page_ number | 顺序页码,从1第一页开始,从第二页开始2 ,依此类推 |
| .width | 页面的宽度 |
| .height | 页面的高度 |
| .objects/ . chars/ .lines/ .rects/ . curves/ .figures/ . images | 这些属性中的每一个都是一 个列表, 每个列表包含一个字典 ,用于嵌入页面上的每个此类对象,有关详细信息,请参阅下面的“对象”。 |
常用方法:
| 方法名 | 说明 |
|---|---|
| .extract_ text( ) | 用来提页面中的文本,将页面的所有字符对象整理为的那个字符串 |
| .extract_ words( ) | 返回的是所有的单词及其相关信息 |
| . extract_ tables() | 提取页面的表格 |
| .to_ _image() | 用于可视化调试时,返回Pagelmage类的一个实例 |
| .close() | 默认情况下, Page对象缓存其布局和对象信息,以避免重新处理它, 但是在解析大型PDF时,这些缓存的属性可能需要大量内存。您可以使用此方法刷新缓存并释放内存。 |
1.2 常用操作
PDF是Portable Document Format的缩写,这类文件通常使用.pdf作为其扩展名。在日常开发工作中,最容易遇到的就是从PDF中读取文本内容以及用已有的内容生成PDF文档这两个任务。
- 1.读取pdf文档信息
- 2.输出总页数
- 3.读取第一页宽度、高度等信息
- 4.读取文本第一页
加载pdf:
- pdfplumber.open( "路径/文件名. pdf".pas sword="test "laparams={ "line_ _overlap'”0.7 })
- password : 要加载受密码保护的PDF ,请传递password关键字参数
- laparams :要将布局分析参数设置为pdfminer. six的布局引擎,请传递laparams关键字参数
1.2.1 Python读取pdf文件案例
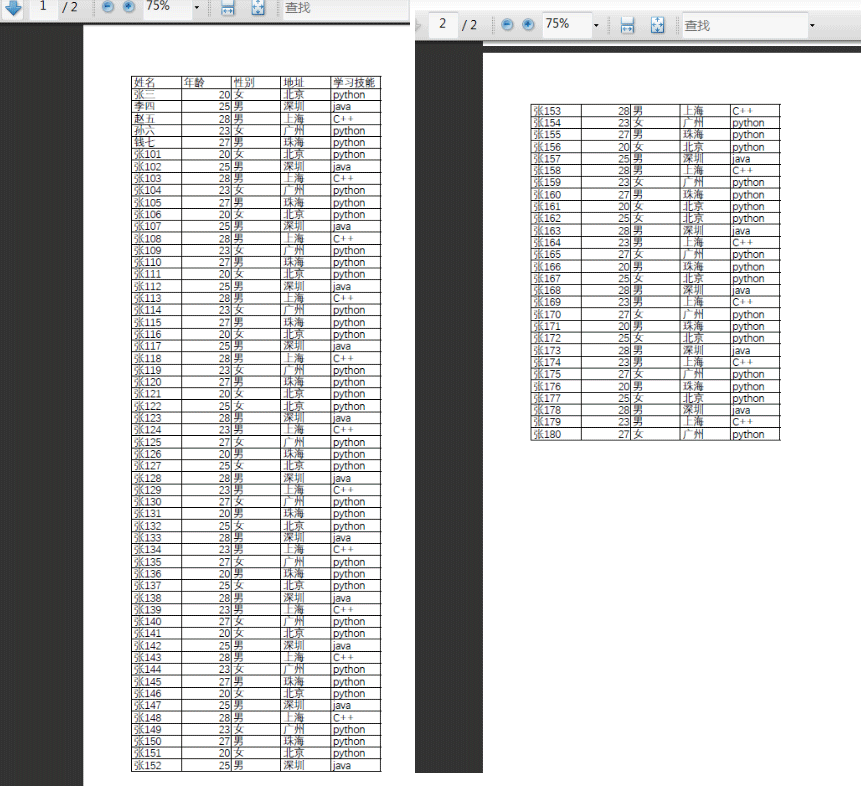
pdf文件如下:
1.2.2 Python读取pdf文件代码
import pdfplumber
# 加载pdf
path = "C:/Users/Administrator/Desktop/test08/test11 - 多页.pdf"
with pdfplumber.open(path) as pdf:
print(pdf)
print(type(pdf))
# 读取pdf文档信息
print("pdf文档信息:", pdf.metadata)
# 输出总页数
print("pdf文档总页数:", len(pdf.pages))
# 1.读取第一页宽度、高度等信息
first_page = pdf.pages[0] # pdfplumber.Page对象第一页
# 查看页码
print('pdf页码:', first_page.page_number)
# 查看页宽
print('pdf页宽:', first_page.width)
# 查看页高
print('pdf页高:', first_page.height)
# 2.读取文本第一页
first_page = pdf.pages[0] # pdfplumber.Page对象第一页
text = first_page.extract_text()
print(text)
执行结果:
"D:\Program Files1\Python\python.exe" D:/Pycharm-work/pythonTest/打卡/0811读取pdf.py
<pdfplumber.pdf.PDF object at 0x0000000002846278>
<class 'pdfplumber.pdf.PDF'>
pdf文档信息: {'Author': '', 'Comments': '', 'Company': '', 'CreationDate': "D:20220812102327+02'23'", 'Creator': 'WPS 表格', 'Keywords': '', 'ModDate': "D:20220812102327+02'23'", 'Producer': '', 'SourceModified': "D:20220812102327+02'23'", 'Subject': '', 'Title': '', 'Trapped': 'False'}
pdf文档总页数: 2
pdf页码: 1
pdf页宽: 595.25
pdf页高: 841.85
姓名 年龄 性别 地址 学习技能
张三 20 女 北京 python
李四 25 男 深圳 java
赵五 28 男 上海 C++
孙六 23 女 广州 python
钱七 27 男 珠海 python
张101 20 女 北京 python
.......
.......
张150 27 男 珠海 python
张151 20 女 北京 python
张152 25 男 深圳 javaProcess finished with exit code 0
1.2.3 Python读取pdf文件存入Excel代码
import pdfplumber
import xlwt
# 加载pdf
path = "C:/Users/Administrator/Desktop/test08/test11 - 多页.pdf"
with pdfplumber.open(path) as pdf:
page_1 = pdf.pages[0] # pdf第一页
table_1 = page_1.extract_table() # 读取表格数据
print(table_1)
# 1.创建Excel对象
workbook = xlwt.Workbook(encoding='utf8')
# 2.新建sheet表
worksheet = workbook.add_sheet('Sheet1')
# 3.自定义列名
clo1 = table_1[0]
# 4.将列表元组clo1写入sheet表单中的第一行
for i in range(0, len(clo1)):
worksheet.write(0, i, clo1[i])
# 5.将数据写进sheet表单中
for i in range(0, len(table_1[1:])):
data = table_1[1:][i]
for j in range(0, len(clo1)):
worksheet.write(i + 1, j, data[j])
# 保存Excel文件分两种
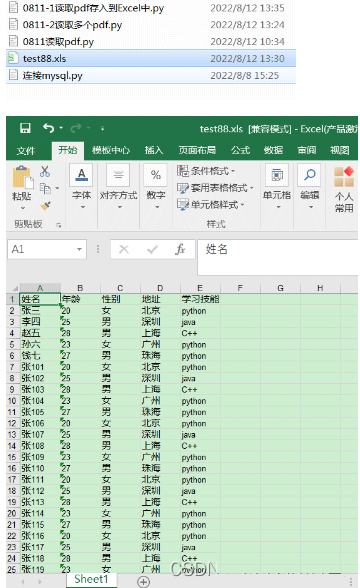
workbook.save('test88.xls')
执行结果:
到此这篇关于Python 操作pdf pdfplumber读取PDF写入Exce的文章就介绍到这了,更多相关Python 操作pdf内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python利用pdfplumber实现读取PDF写入Excel
目录 一.Python操作PDF 13大库对比 二.pdfplumber模块 1.安装 2. 加载PDF 3. pdfplumber.PDF类 4. pdfplumber.Page类 三.实战操作 1. 提取单个PDF全部页数 2. 批量提取多个PDF文件 一.Python操作PDF 13大库对比 PDF(Portable Document Format)是一种便携文档格式,便于跨操作系统传播文档.PDF文档遵循标准格式,因此存在很多可以操作PDF文档的工具,Python自然也不例外. Pyth
-
python用pdfplumber提取pdf表格数据并保存到excel文件中
目录 pdfplumber操作pdf文件 一.pdfplumber安装及导入 二.pdfplumber基础使用 1.基础知识 2.获取pdf基础信息 3.pdfplumber提取表格数据 三.提取pdf表格数据并保存到excel中 总结 pdfplumber操作pdf文件 python开源库pdfplumber,可以较为方便地获取pdf的各种信息,包含pdf的基本信息(作者.创建时间.修改时间…)及表格.文本.图片等信息,基本可以满足较为简单的格式转换功能. 一.pdfplumber安装及导入
-
Python实现将Excel内容批量导出为PDF文件
目录 序言 实现代码 序言 上一篇咱们实现了多个表格数据合并到一个表格,本次咱们来学习如何将表格数据分开导出为PDF文件. 部分数据 然后需要安装一下这个软件 wkhtmltopdf 不知道怎么下载的可以在电脑端左侧扫一下找到我要 效果展示 数据单独导出为一个PDF 实现代码 import pdfkit import openpyxl import os target_dir = '经销商预算' if not os.path.exists(target_dir): os.mkdir(target
-
Python读取pdf表格写入excel的方法
背景 今天突然想到之前被要求做同性质银行的数据分析.妈耶!十几个银行,每个银行近5年的财务数据,而且财务报表一般都是 pdf 的,我们将 pdf 中表的数据一个个的拷贝到 excel 中,再借助 excel 去进行求和求平均等聚合函数操作,完事了还得把求出来的结果再统一 CV 到另一张表中,进行可视化分析- 当然,那时风流倜傥的 老Amy 还熟练的玩转着 excel ,也是个秀儿~ 今天就思索着,如果当年我会 Python 是不是可以让我成为班级最靓的崽!用技术占领高地,HHH,所以今天我来了,
-
Python自动化办公实战案例详解(Word、Excel、Pdf、Email邮件)
目录 背景 实现过程 1)替换Word模板生成对应邀请函 2)将Word邀请函转化为Pdf格式 4)自动发送邮件 5)完整代码 总结 背景 想象一下,现在你有一份Word邀请函模板,然后你有一份客户列表,上面有客户的姓名.联系方式.邮箱等基本信息,然后你的老板现在需要替换邀请函模板中的姓名,然后将Word邀请函模板生成Pdf格式,之后编辑统一的邀请话术(邮件正文),再依次发送邀请函附件到客户邮箱,你会怎么做? 正常情况下,我们肯定是复制粘贴Excel表格中的客户姓名,之后挨个Word文档进行替换
-
python pdfplumber库批量提取pdf表格数据转换为excel
目录 需求 一.实现效果图 二.pdfplumber 库 三.代码实现 1.导入相关包 2.读取 pdf , 并获取 pdf 的页数 3.提取单个 pdf 文件,保存成 excel 4.提取文件夹下多个 pdf 文件,保存成 excel 小结 需求 想要提取 pdf 的数据,保存到 excel 中.虽然是可以直接利用 WPS 将 pdf 文件输出成 excel,但这个功能是收费的,而且如果将大量pdf转excel的时候,手动去输出是非常耗时的.我们可以利用 python 的三方工具库 pdfpl
-
Python 操作pdf pdfplumber读取PDF写入Exce
目录 1. Python 操作pdf(pdfplumber读取PDF写入Exce) 1.1 安装pdfplumber模块库 1.2 常用操作 1.2.1 Python读取pdf文件案例 1.2.2 Python读取pdf文件代码 1.2.3 Python读取pdf文件存入Excel代码 1. Python 操作pdf(pdfplumber读取PDF写入Exce) 1.1 安装pdfplumber模块库 安装pdfplumber: pip install pdfplumber pdfplumber
-
Python中文件的读取和写入操作
从文件中读取数据 读取整个文件 这里假设在当前目录下有一个文件名为'pi_digits.txt'的文本文件,里面的数据如下: 3.1415926535 8979323846 2643383279 with open('pi_digits.txt') as f: # 默认模式为'r',只读模式 contents = f.read() # 读取文件全部内容 print contents # 输出时在最后会多出一行(read()函数到达文件末会返回一个空字符,显示出空字符就是一个空行) print '
-
Python实现数据库并行读取和写入实例
这篇主要记录一下如何实现对数据库的并行运算来节省代码运行时间.语言是Python,其他语言思路一样. 前言 一共23w条数据,是之前通过自然语言分析处理过的数据,附一张截图: 要实现对news主体的读取,并且找到其中含有的股票名称,只要发现,就将这支股票和对应的日期.score写入数据库. 显然,几十万条数据要是一条条读写,然后在本机上操作,耗时太久,可行性极低.所以,如何有效并行的读取内容,并且进行操作,最后再写入数据库呢? 并行读取和写入 并行读取:创建N*max_process个进程,对数
-
使用Python操作PDF文件
从PDF读取文本内容和从已经有的文档生成新的PDF. 需要用到的模块是PyPDF2. mstamy2/PyPDF2: A utility to read and write PDFs with Python (github.com) 同时,还要关注较新的PyPDF4包,因为它很快就会取代PyPDF2. claird/PyPDF4: A utility to read and write PDFs with Python (github.com) 也可以看看pdfrw包,它也可以执行许多与PyPD
-
使用Python对Dicom文件进行读取与写入的实现
Pydicom 单张影像的读取 使用 pydicom.dcmread() 函数进行单张影像的读取,返回一个pydicom.dataset.FileDataset对象. import os import pydicom # 调用本地的 dicom file folder_path = r"D:\Files\Data\Materials" file_name = "PA1_0001.dcm" file_path = os.path.join(folder_path,fi
-
python pandas 解析(读取、写入)CSV 文件的操作方法
目录 1. 使用 pandas 读取 CSV 文件 2. 使用 pandas 写入 CSV 文件 1. 使用 pandas 读取 CSV 文件 原始数据包含了公司员工的数据: Name Hire Date Salary Sick Days remaining Graham Chapman 03/15/14 50000.00 10 John Cleese 06/01/15 65000.00 8 Eric Idle 05/12/14 45000.00 10 Terry Jones 11/01/13
-
一文教会你用Python读取PDF文件
目录 实战场景 Python PDF 实战编码 补充 实战场景 Python 工程师在日常的工作中,经常会碰到解析和处理PDF文件的情况,实战中需求主要分为如下情况: 提取 PDF 中的文字 将 PDF 中每页转换为图片 word 转换为PDF PDF生成,编辑,导入导出 PDF在线渲染 除了最后一项需要前端配合以外,其余内容都可以直接在 python 端进行实现. 本次实战选择 pdfplumber 库进行学习,可以提前安装该库,不过有一点需要注意,该库主要用于读取 PDF 进行操作,写入和编