关于CUDA out of memory的解决方案
目录
- 1 问题描述
- 2 问题的解决
- 1 如果你的显存真的比较小
- 2 如果你的cpu比较差
- 3 一个隐藏的设置
- 总结
1 问题描述
很多时候,我们在开始进行深度学习训练的时候,经常出现存储不够的信息,
诸如这样:
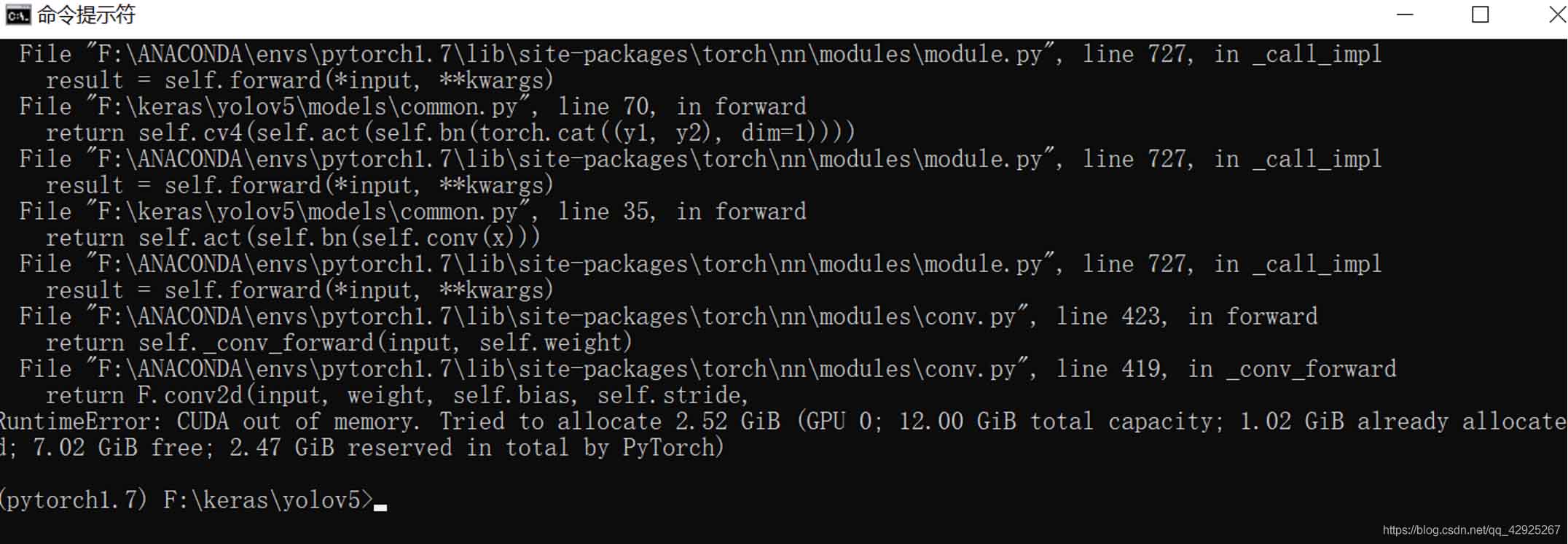
你可能会认为是自己的显卡显存不够,那就再掏钱去买个更大的显卡吧。
我的显卡是titan xp 12g显存。
其实对于绝大多数的网络都是够用的,那么这个问题该如何解决哪?
2 问题的解决
1 如果你的显存真的比较小
我的显卡是titan xp12g显存,举个例子我在训练模型时,设置的batch_size==16,也就是说,我可以同时处理16副图,我占用的显存是5.82个g,如果你的显存比我的小,或者你处理其他的图片占用的更大,那么,怎
么办哪?
你可以:
修改:batch_size==4
请尽量还是选用2的n次方来设置参数。这是深度学习二进制的本质。
修改后,你的显存占用会从5.82g降到0.81g,就算你的显存比较小,总有一天,你会满足自己的需求。
2 如果你的cpu比较差
我使用的是2017年的thinkpad x1carobon笔记本,外界显卡坞带titan xp显卡。
我的cpu是i7-7600,已经过了几年了,并不好,但说不定你比我的cpu更差,那么怎么办哪?
你可以:
修改:workers==1
很多模型训练的时候,默认的线程也就是workers==8,也许你的cpu无法承受8线程同时训练,那么你可以把这个并行线程数降下来,例如我上面的,将线程数降为1,那么又可以愉快的玩耍了,但是,你能承受本来我有i7的cpu,本来我有12g的显存,却不能完全使用,还要承受八倍奉还么!!
3 一个隐藏的设置
这个发现,我尚未在其他csdn的博客上见到过,或者我没搜到。
应该有很多像我一样的偏执狂。天天盯着存储看,c盘没多一点点,就开始删除垃圾,删除缓存,删除windows更新备份,删除windows注销文件(2个g),删除windows系统补丁,删除c盘之外其他盘的虚拟内存,后者把虚拟内存转移到其他盘!因为,我们的c盘真的不堪重负。。。
后面有时间,我再谈谈如何给c盘自由加容吧。
可能,就像我一样,我举个例子,我把项目放在了F盘,那么我把除c盘之外,其他盘的虚拟缓存给删掉了,导致F盘的虚拟内存为0,也会出现这个问题。
那么,该怎么办哪?
你可以:
修改:我的电脑——属性——高级系统设置——设置——虚拟内存
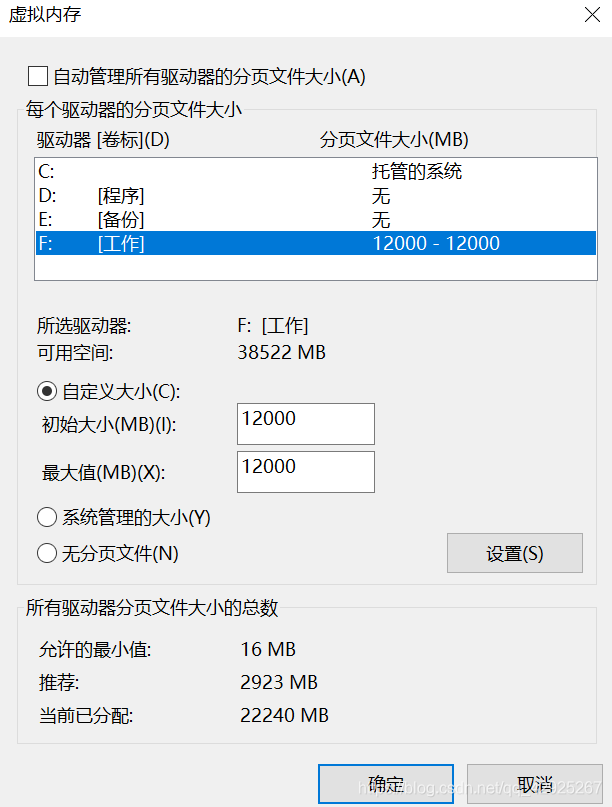
为了跟我的显存保持一致,我就把虚拟内存也设置为12g吧应该是1024x12.。
懒得修改了,一切OK!
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
解决Pytorch 训练与测试时爆显存(out of memory)的问题
Pytorch 训练时有时候会因为加载的东西过多而爆显存,有些时候这种情况还可以使用cuda的清理技术进行修整,当然如果模型实在太大,那也没办法. 使用torch.cuda.empty_cache()删除一些不需要的变量代码示例如下: try: output = model(input) except RuntimeError as exception: if "out of memory" in str(exception): print("WARNING: out of
-
粗暴解决CUDA out of memory的问题
小渣渣复现大佬project发现GPU跑不动,出现如下报错: RuntimeError: CUDA out of memory. 看下来最简单粗暴方法就是减少batch_size,慢是慢了不止一点点但至少跑得动了! 补充:Pytorch GPU显存充足却显示out of memory解决办法 今天在测试一个pytorch代码的时候显示显存不足,但是这个网络框架明明很简单,用CPU跑起来都没有问题,GPU却一直提示out of memory. 在网上找了很多方法都行不通,最后我想也许是pytorc
-

解决PyTorch与CUDA版本不匹配的问题
1.CUDA驱动和CUDA Toolkit对应版本 表一:CUDA驱动及CUDA Toolkit最高对应版本 最新可查阅官方文档 注:驱动是向下兼容的,其决定了可安装的CUDA Toolkit的最高版本. 2.CUDA Toolkit版本及其可用PyTorch对应版本(参考官网) 表二:CUDA Toolkit版本及可用PyTorch对应关系 CUDAToolkit版本 可用PyTorch版本 7.5 0.4.1 ,0.3.0, 0.2.0,0.1.12-0.1.6 8.0 1.1.0,1.0.
-
关于CUDA out of memory的解决方案
目录 1 问题描述 2 问题的解决 1 如果你的显存真的比较小 2 如果你的cpu比较差 3 一个隐藏的设置 总结 1 问题描述 很多时候,我们在开始进行深度学习训练的时候,经常出现存储不够的信息, 诸如这样: 你可能会认为是自己的显卡显存不够,那就再掏钱去买个更大的显卡吧. 我的显卡是titan xp 12g显存. 其实对于绝大多数的网络都是够用的,那么这个问题该如何解决哪? 2 问题的解决 1 如果你的显存真的比较小 我的显卡是titan xp12g显存,举个例子我在训练模型时,设置的bat
-
Pytorch测试神经网络时出现 RuntimeError:的解决方案
Pytorch测试神经网络时出现"RuntimeError: Error(s) in loading state_dict for Net" 解决方法: load_state_dict(torch.load('net.pth') 在前,增加 model = nn.DataParallel(model) 就可以了. 比如 net = NET() net.cuda() net = nn.DataParallel(net) net.load_state_dict(torch.load('ne
-
PyTorch训练LSTM时loss.backward()报错的解决方案
训练用PyTorch编写的LSTM或RNN时,在loss.backward()上报错: RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed. Specify retain_graph=True when calling backward the first time. 千万别改成loss.backward(retain_graph=Tru
-
pytorch使用指定GPU训练的实例
本文适合多GPU的机器,并且每个用户需要单独使用GPU训练. 虽然pytorch提供了指定gpu的几种方式,但是使用不当的话会遇到out of memory的问题,主要是因为pytorch会在第0块gpu上初始化,并且会占用一定空间的显存.这种情况下,经常会出现指定的gpu明明是空闲的,但是因为第0块gpu被占满而无法运行,一直报out of memory错误. 解决方案如下: 指定环境变量,屏蔽第0块gpu CUDA_VISIBLE_DEVICES = 1 main.py 这句话表示只有第1块
-
jupyter notebook参数化运行python方式
Updates (2019.8.14 19:53)吃饭前用这个方法实战了一下,吃完回来一看好像不太行:跑完一组参数之后,到跑下一组参数时好像没有释放之占用的 GPU,于是 notebook 上的结果,后面好几条都报错说 cuda out of memory. 现在改成:将 notebook 中的代码写在一个 python 文件中,然后用命令行运行这个文件,比如: # autorun.py import os # print(os.getcwd()) over = [ # 之前手工改参数跑完的参数
-
详解解决Python memory error的问题(四种解决方案)
昨天在用用Pycharm读取一个200+M的CSV的过程中,竟然出现了Memory Error!简直让我怀疑自己买了个假电脑,毕竟是8G内存i7处理器,一度怀疑自己装了假的内存条....下面说一下几个解题步骤....一般就是用下面这些方法了,按顺序试试. 一.逐行读取 如果你用pd.read_csv来读文件,会一次性把数据都读到内存里来,导致内存爆掉,那么一个想法就是一行一行地读它,代码如下: data = [] with open(path, 'r',encoding='gbk',errors
-
Pytorch 解决自定义子Module .cuda() tensor失败的问题
最近在刚从tensorflow转入pytorch,对于自定义的nn.Module 碰到了个问题,即使把模组 modle=Model().cuda(),里面的子Module的parameter都没有被放入cuda,导致输入是torch.cuda.FloatTensor,但是比如CNN的weight却还是torch.FloatTensor (当然最粗暴的方法就是直接在子模组里面都用了 .cuda() 但是问题并不在那,可能是调用子模组的时候,存在某些错误,导致父模组没有把子模组的parameter注
-
pytorch显存一直变大的解决方案
在代码中添加以下两行可以解决: torch.backends.cudnn.enabled = True torch.backends.cudnn.benchmark = True 补充:pytorch训练过程显存一直增加的问题 之前遇到了爆显存的问题,卡了很久,试了很多方法,总算解决了. 总结下自己试过的几种方法: **1. 使用torch.cuda.empty_cache() 在每一个训练epoch后都添加这一行代码,可以让训练从较低显存的地方开始,但并不适用爆显存的问题,随着epoch的增加
-
Mysql5.6启动内存占用过高解决方案
vps的内存为512M,安装好nginx,php等启动起来,mysql死活启动不起来看了日志只看到对应pid被结束了,后跟踪看发现是内存不足被killed; 调整my.cnf 参数,重新配置(系统默认配置太高直接占用400M内存,小玩家玩不起呢)即可 performance_schema_max_table_instances=200 table_definition_cache=200 table_open_cache=128 下面附一个相关的my.cnf配置文件的说明 [client] po