一文带你全面了解Java Hashtable
目录
- 概述
- 介绍和使用
- 核心机制
- 实现机制
- 扩容机制
- 源码解析
- 成员变量
- 构造函数
- put方法
- get方法
- remove方法
- 总结
概述
HashTable是jdk 1.0中引入的产物,基本上现在很少使用了,但是会在面试中经常被问到,你都知道吗:
- HashTable底层的实现机制是什么?
- HashTable的扩容机制是什么?
- HashTable和HashMap的区别是什么?
介绍和使用
和HashMap一样,Hashtable也是一个散列表,它存储的内容是键值对(key-value)映射, 重要特点如下:
- 存储key-value键值对格式
- 是无序的
- 底层通过数组+链表的方式实现
- 通过synchronized关键字实现线程安全
- key、value都不可以为null(为null时将抛出NullPointerException)

以上是Hashtable的类结构图:
- 实现了Map接口,提供了键值对增删改查等基础操作
- 继承了Dictionary字典类,Dictionary是声明了操作"键值对"函数接口的抽象类。
- 实现了Cloneable接口,实现数据的浅拷贝
- 实现了Serializable接口,标记Hashtable支持序列化
使用案例:
@Test
public void test() {
Hashtable<String, String> table=new Hashtable<>();
Hashtable<String, String> table1=new Hashtable<>(16);
Hashtable<String, String> table2=new Hashtable<>(16, 0.75f);
table.put("T1", "1");
table.put("T2", "2");
System.out.println(table);
// 报空指针异常
table.put(null, "3");
}
运行结果:

核心机制
实现机制
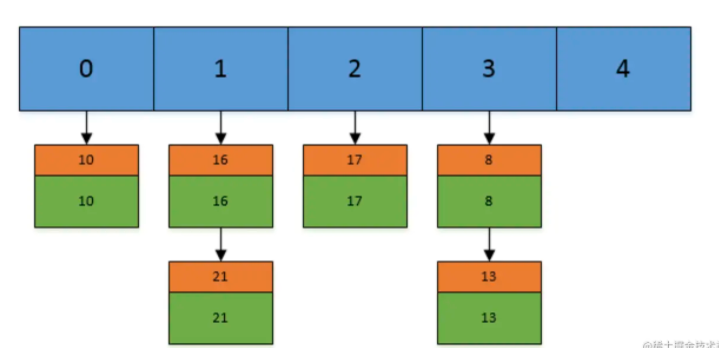
和HashMap相似,Hashtable底层采用数组+链表的数据结构,根据key找到数组对应的桶,相同的key通过链表维护,当数组桶的使用到达阈值后,会进行动态扩容。但是和HashMap不同的是,链表不会转换为红黑树。
扩容机制
扩容机制依赖两个成员变量,初始容量 和 加载因子。他们可以通过构造函数设置。
容量是值哈希表中桶的数量,初始容量就是哈希表创建时的容量。当容量达到阈值的时候,会进行扩容操作,每次扩容是原来容量的2倍加1,然后重新为hashtable中的每个元素重新分配桶的位置。
那阈值是多少呢,Hashtable的阈值,用于判断是否需要调整Hashtable的容量,等于"Hashtable当前的容量*加载因子"。
通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查找某个条目的时间。
源码解析
成员变量
// 内部采用Entry数组存储键值对数据,Entry实际为单向链表的表头 private transient Entry<?,?>[] table; // HashTable里键值对个数 private transient int count; // 扩容阈值,当超过这个值时,进行扩容操作,计算方式为:数组容量*加载因子 private int threshold; // 加载因子 private float loadFactor; // 修改次数,用于快速失败机制 private transient int modCount = 0;
Entry的数据结构如下:
private static class Entry<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Entry<K,V> next;
protected Entry(int hash, K key, V value, Entry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
......
}
Entry是单向链表节点,next指向下一个entry
构造函数
// 设置指定容量和加载因子,初始化HashTable
public Hashtable(int initialCapacity, float loadFactor) {
// 非法参数校验
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
// 非法参数校验
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
// 容量最小为1
initialCapacity = 1;
this.loadFactor = loadFactor;
// 初始化数组
table = new Entry<?,?>[initialCapacity];
// 初始扩容阈值
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}
// 设置指定容量初始HashTable,加载因子为0.75
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
// 手动指定数组初始容量为11,加载因子为0.75
public Hashtable() {
this(11, 0.75f);
}
put方法
// 方法synchronized修饰,线程安全
public synchronized V put(K key, V value) {
// 如果value为空,直接空指针
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
// 得到key的哈希值
int hash = key.hashCode();
// 得到该key存在到数组中的下标
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
// 得到该下标对应的Entry
Entry<K,V> entry = (Entry<K,V>)tab[index];
// 如果该下标的Entry不为null,则进行链表遍历
for(; entry != null ; entry = entry.next) {
// 遍历链表,如果存在key相等的节点,则替换这个节点的值,并返回旧值
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
// 如果数组下标对应的节点为空,或者遍历链表后发现没有和该key相等的节点,则执行插入操作
addEntry(hash, key, value, index);
return null;
}
private void addEntry(int hash, K key, V value, int index) {
// 修改次数+1
modCount++;
Entry<?,?> tab[] = table;
// 判断是否需要扩容
if (count >= threshold) {
// 如果count大于等于扩容阈值,则进行扩容
rehash();
tab = table;
// 扩容后,重新计算该key在扩容后table里的下标
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
// 采用头插的方式插入,index位置的节点为新节点的next节点
// 新节点取代inde位置节点
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
// count+1
count++;
}
扩容rehash源码如下:
protected void rehash() {
// 暂存旧的table和容量
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// 新容量为旧容量的2n+1倍
int newCapacity = (oldCapacity << 1) + 1;
// 判断新容量是否超过最大容量
if (newCapacity - MAX_ARRAY_SIZE > 0) {
// 如果旧容量已经是最大容量大话,就不扩容了
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
// 新容量最大值只能是MAX_ARRAY_SIZE
newCapacity = MAX_ARRAY_SIZE;
}
// 用新容量创建一个新Entry数组
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
// 模数+1
modCount++;
// 重新计算下次扩容阈值
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
// 将新Entry数组赋值给table
table = newMap;
// 遍历数组和链表,进行新table赋值操作
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}
rehash()方法中我们可以看到容量扩大两倍+1,同时需要将原来HashTable中的元素,重新计算索引位置一一复制到新的Hashtable中,这个过程是比较消耗时间的。
Hashtable的索引求值公式是: hash&0x7FFFFFFF%newCapacity。hash&0x7FFFFFF是为了保证正数,因为hashCode的值有可能为负值。
get方法
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
// 根据key哈希得到index,遍历链表取值
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}
remove方法
public synchronized V remove(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
// 获取key对应的index
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
// 遍历链表,如果找到key相等的节点,则改变前继和后继节点的关系,并删除相应引用,让GC回收
Entry<K,V> e = (Entry<K,V>)tab[index];
for(Entry<K,V> prev = null ; e != null ; prev = e, e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
modCount++;
if (prev != null) {
prev.next = e.next;
} else {
tab[index] = e.next;
}
count--;
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
return null;
}
总结
本文主要讲解了Hashtable的基本功能和源码解析,虽然Hashtable本身不常用了,但是它的直接子类Properties目前还在被大量使用当中,所以学习它还是有一定价值的。下面在总结下Hashtable和HashMap的区别:
1.线程是否安全:HashMap是线程不安全的,HashTable是线程安全的;HashTable内部的方法基本都经过 synchronized修饰; 如果想要线程安全的Map容器建议使用ConcurrentHashMap,性能更好。
2.对Null key 和Null value的支持:HashMap中,null可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为null;HashTable中key和value都不能为null,否则抛出空指针异常;
3.初始容量大小和每次扩充容量大小的不同:
- 创建时如果不指定容量初始值,Hashtable默认的初始大小为11,之后每次扩容,容量变为原来的2n+1。HashMap默认的初始化大小为16。之后每次扩充,容量变为原来的2倍;
- 创建时如果给定了容量初始值,那么Hashtable会直接使用你给定的大小,而HashMap会将其扩充 为2的幂次方大小。
4.底层数据结构:JDK1.8及以后的HashMap在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树,以减少搜索时间,Hashtable没有这样的机制。
到此这篇关于一文带你全面了解Java Hashtable的文章就介绍到这了,更多相关Java Hashtable内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Java Hashtable机制深入了解
目录 概述 介绍和使用 核心机制 实现机制 扩容机制 源码解析 成员变量 构造函数 put方法 get方法 remove方法 总结 概述 HashTable是jdk 1.0中引入的产物,基本上现在很少使用了,但是会在面试中经常被问到,你都知道吗: HashTable底层的实现机制是什么? HashTable的扩容机制是什么? HashTable和HashMap的区别是什么? 介绍和使用 和HashMap一样,Hashtable也是一个散列表,它存储的内容是键值对(key-value)映射, 重要
-
Java HashTable与Collections.synchronizedMap源码深入解析
目录 一.类继承关系图 二.HashTable介绍 三.HashTable和HashMap的对比 1.线程安全 2.插入null 3.容量 4.Hash映射 5.扩容机制 6.结构区别 四.Collections.synchronizedMap解析 1.Collections.synchronizedMap是怎么实现线程安全的 2.SynchronizedMap源码 一.类继承关系图 二.HashTable介绍 HashTable的操作几乎和HashMap一致,主要的区别在于HashTable为
-
Java Collections类操作集合详解
Collections 类是 Java 提供的一个操作 Set.List 和 Map 等集合的工具类.Collections 类提供了许多操作集合的静态方法,借助这些静态方法可以实现集合元素的排序.查找替换和复制等操作.下面介绍 Collections 类中操作集合的常用方法. 1) 排序(Sort) 使用sort方法可以根据元素的自然顺序,对指定列表进行排序.列表中的所有元素都必须实现 Comparable 接口.或此列表内的所有元素都必须是使用指定比较器可相互比较的 Collec
-

Java中Hashtable集合的常用方法详解
目录 public Object clone() public Enumeration<V> elements() 总结 public Object clone() 返回Hashtable的副本 public Enumeration<V> elements() 返回此哈希表中的值的枚举 其他的方法都是实现Map集合的方法 //www.jb51.net/article/227296.htm 总结 本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
-
Java使用Collections.sort()排序的方法
Java中Collections.sort()的使用 在日常开发中,很多时候都需要对一些数据进行排序的操作.然而那些数据一般都是放在一个集合中如:Map ,Set ,List 等集合中.他们都提共了一个排序方法 sort(),要对数据排序直接使用这个方法就行,但是要保证集合中的对象是 可比较的. 怎么让一个对象是 可比较的,那就需要该对象实现 Comparable<T> 接口啦.然后重写里面的 compareTo()方法.我们可以看到Java中很多类都是实现类这个接口的 如:Integer,L
-
详解Java集合类之HashTable,Properties篇
目录 1.基本介绍 2.HashTable底层 3.HashTable扩容机制 4.HashMap和HashTable的对比 5.Properties 6.集合选型规则 1.基本介绍 HashTable的键和值都不能为空,否则会抛出一个异常 使用方法基本与HashMap一致 HashTable是线程安全的,HashMap是线程不安全的 2.HashTable底层 先上代码: Hashtable hashtable = new Hashtable(); hashtable.put("john&qu
-
详解Java中的HashTable
概论 HashTable是遗留类,很多映射的常用功能与HashMap类似,不同的是它承自Dictionary类,并且是线程安全的,并发性不如ConcurrentHashMap,因为ConcurrentHashMap引入了分段锁. Hashtable不建议在新代码中使用,不需要线程安全的场合可以用HashMap替换,需要线程安全的场合可以用ConcurrentHashMap替换. 对比HashMap 的初始容量 默认11 的初始容量 需要注意的是Hashtable的默认初始容量大小是11,而Has
-
一文带你全面了解Java Hashtable
目录 概述 介绍和使用 核心机制 实现机制 扩容机制 源码解析 成员变量 构造函数 put方法 get方法 remove方法 总结 概述 HashTable是jdk 1.0中引入的产物,基本上现在很少使用了,但是会在面试中经常被问到,你都知道吗: HashTable底层的实现机制是什么? HashTable的扩容机制是什么? HashTable和HashMap的区别是什么? 介绍和使用 和HashMap一样,Hashtable也是一个散列表,它存储的内容是键值对(key-value)映射, 重要
-
一文带你彻底理解Java序列化和反序列化
Java序列化是什么? Java序列化是指把Java对象转换为字节序列的过程,Java反序列化是指把字节序列恢复为Java对象的过程. 反序列化: 客户端重文件,或者网络中获取到文件以后,在内存中重构对象. 序列化: 对象序列化的最重要的作用是传递和保存对象的时候,保证对象的完整性和可传递性.方便字节可以在网络上传输以及保存在本地文件. 为什么需要序列化和反序列化 实现分布式 核心在于RMI,可以利用对象序列化运行远程主机上的服务,实现运行的时候,就像在本地上运行Java对象一样. 实现递归保存
-
一文带你深入了解Java泛型
目录 什么是Java泛型 泛型的使用 泛型类 泛型接口 泛型方法 泛型的底层实现机制 ArrayList源码解析 什么是泛型擦除 泛型的边界 ?:无界通配符 extends 上边界通配符 super 下边界通配符 PECS原则 泛型是怎么擦除的 擦除类定义中的无限制类型参数 擦除类定义中的有限制类型擦除 擦除方法定义中的类型参数 桥接方法和泛型的多态 泛型擦除带来的限制与局限 泛型不适用基本数据类型 无法创建具体类型的泛型数组 反射其实可以绕过泛型的限制 什么是Java泛型 Java 泛型(ge
-
一文带你真正理解Java中的内部类
目录 概述 内部类介绍和分类 常规内部类 局部内部类 匿名内部类 静态内部类 静态内部类和普通内部类的区别 内部类的作用 概述 不知道大家在平时的开发过程中或者源码里是否留意过内部类,那有思考过为什么要有内部类,内部类都有哪几种形式,静态内部类和普通内部类有什么区别呢?本篇文章主要带领大家理解下这块内容. 内部类介绍和分类 顾名思义,内部类是指一个类在另外一个类的内部,是定义在另一个类中的类.根据类的位置和属性不同,可以分为下面几种. 常规内部类 @Data public class Tree
-
一文带你玩转Java异常处理
目录 1.前言 2. Exception 类的层次 2.1 Exception 类的层次简介 3. Java 内置异常类 3.1 Java 内置异常类简介 3.2 非检查异常类举例 3.3 检查性异常类表 4. 异常方法 4.1 Throwable 类的主要方法 5. 捕获异常 5.1 捕获异常简介 5.2 try/catch语法如下 5.3 多重捕获块语法说明 6. throws/throw 关键字 6.1 throws/throw 关键字简介 6.2 代码实例 7. finally关键字 7
-
一文带你搞懂Java中的泛型和通配符
目录 概述 泛型介绍和使用 泛型类 泛型方法 类型变量的限定 通配符使用 无边界通配符 通配符上界 通配符下界 概述 泛型机制在项目中一直都在使用,比如在集合中ArrayList<String, String>, Map<String,String>等,不仅如此,很多源码中都用到了泛型机制,所以深入学习了解泛型相关机制对于源码阅读以及自己代码编写有很大的帮助.但是里面很多的机制和特性一直没有明白,特别是通配符这块,对于通配符上界.下界每次用每次百度,经常忘记,这次我就做一个总结,加
-
一文带你深入剖析Java线程池的前世今生
目录 由线程到线程池 线程在做什么 为什么需要线程池 线程池实现原理 总结 由线程到线程池 线程在做什么 灵魂拷问:写了那么多代码,你能够用一句话简练描述线程在干啥吗? public class Demo01 { public static void main(String[] args) { var thread = new Thread(() -> { System.out.println("Hello world from a Java thread"
-
一文带你搞懂Java中Get和Post的使用
目录 1 Get请求数据 1.1 Controller 1.2 Service 1.3 Application 1.4 Postman 2 Post接收数据 2.1 Controller 2.2 Service 2.3 Application 2.4 Postman 3 Post发送数据 3.1 Controller 3.2 Service 3.3 ResponseResult 3.4 Config 3.5 Application 3.6 Postman 1 Get请求数据 项目地址:https
-
一文带你深入了解Java中延时任务的实现
目录 概述 JAVA DelayQueue DelayQueue的实现原理 DelayQueue实现延时队列的优缺点 时间轮算法 时间轮的具体实现 进阶优化版时间轮算法 时间轮算法的应用 小结 redis延时队列 mq延时队列 rocketmq延时消息 rocketmq的精准延时消息 总结 概述 延时任务相信大家都不陌生,在现实的业务中应用场景可以说是比比皆是.例如订单下单15分钟未支付直接取消,外卖超时自动赔付等等.这些情况下,我们该怎么设计我们的服务的实现呢? 笨一点的方法自然是定时任务去数
-
一文带你搞懂Java中的递归
目录 概述 递归累加求和 计算1 ~ n的和 代码执行图解 递归求阶乘 递归打印多级目录 综合案例 文件搜索 文件过滤器优化 Lambda优化 概述 递归:指在当前方法内调用自己的这种现象. 递归的分类: 递归分为两种,直接递归和间接递归. 直接递归称为方法自身调用自己. 间接递归可以A方法调用B方法,B方法调用C方法,C方法调用A方法. 注意事项: 递归一定要有条件限定,保证递归能够停止下来,否则会发生栈内存溢出. 在递归中虽然有限定条件,但是递归次数不能太多.否则也会发生栈内存溢出. 构造方