针对Pandas的总结以及数据读取_pd.read_csv()的使用详解
目录
- 1. FilePathOrBuffer
- 2. sep
- 3. delim_whitespace(不常用)
- 4. header 和 names
- 5. index_col
- 6. usecols
- 7. mangle_dupe_cols
- 8. prefix
- 9. dtype
- 10. engine
- 11. converters
- 12. true_values和false_value
- 13. skiprows
- 14. skipfooter
- 15. nrows
- 16. na_values
- 17. keep_default_na
- 18. na_filter
- 19. skip_blank_lines
- 20. parse_dates
- 21. date_parser
- 22. infer_datetime_format
- 23. iterator
- 24. chunksize
- 25. compression
- 26. thousands
- 27. encoding
- 28. error_bad_lines和warn_bad_lines
使用pandas进行数据读取,最常读取的数据格式如下:
| NO | 数据类型 | 说明 | 使用方法 |
| 1 | csv, tsv, txt | 可以读取纯文本文件 | pd.read_csv |
| 2 | excel | 可以读取.xls .xlsx 文件 | pd.read_excel |
| 3 | mysql | 读取关系型数据库 | pd.read_sql |
本文主要介绍pd.read_csv() 的用法:
pd.read_csv
pandas对纯文本的读取提供了非常强力的支持,参数有四五十个。这些参数中,有的很容易被忽略,但是在实际工作中却用处很大。pd.read_csv() 的格式如下:
read_csv( reader: FilePathOrBuffer, *, sep: str = ..., delimiter: str | None = ..., header: int | Sequence[int] | str = ..., names: Sequence[str] | None = ..., index_col: int | str | Sequence | Literal[False] | None = ..., usecols: int | str | Sequence | None = ..., squeeze: bool = ..., prefix: str | None = ..., mangle_dupe_cols: bool = ..., dtype: str | Mapping[str, Any] | None = ..., engine: str | None = ..., converters: Mapping[int | str, (*args, **kwargs) -> Any] | None = ..., true_values: Sequence[Scalar] | None = ..., false_values: Sequence[Scalar] | None = ..., skipinitialspace: bool = ..., skiprows: Sequence | int | (*args, **kwargs) -> Any | None = ..., skipfooter: int = ..., nrows: int | None = ..., na_values=..., keep_default_na: bool = ..., na_filter: bool = ..., verbose: bool = ..., skip_blank_lines: bool = ..., parse_dates: bool | List[int] | List[str] = ..., infer_datetime_format: bool = ..., keep_date_col: bool = ..., date_parser: (*args, **kwargs) -> Any | None = ..., dayfirst: bool = ..., cache_dates: bool = ..., iterator: Literal[True], chunksize: int | None = ..., compression: str | None = ..., thousands: str | None = ..., decimal: str | None = ..., lineterminator: str | None = ..., quotechar: str = ..., quoting: int = ..., doublequote: bool = ..., escapechar: str | None = ..., comment: str | None = ..., encoding: str | None = ..., dialect: str | None = ..., error_bad_lines: bool = ..., warn_bad_lines: bool = ..., delim_whitespace: bool = ..., low_memory: bool = ..., memory_map: bool = ..., float_precision: str | None = ...)
1. FilePathOrBuffer
可以是文件路径,可以是网页上的文件,也可以是文件对象,实例如下:
# 文件路径读取
file_path=r"E:\VSCODE\2_numpy_pandas\pandas\Game_Data.csv"
f_df = pd.read_csv(file_path,sep=",|:|;",engine="python",header=0,encoding='gbk')
print(f_df)
# 网页上的文件读取
f_df = pd.read_csv("http://localhost/data.csv")
# 文件对象读取
f = open(r"E:\VSCODE\2_numpy_pandas\pandas\Game_Data.csv", encoding="gbk")
f_df = pd.read_csv(f)
2. sep
读取csv文件时指定的分隔符,默认为逗号。注意:“csv文件的分隔符” 和 “我们读取csv文件时指定的分隔符” 一定要一致。多个分隔符时,应该使用 | 将不同的分隔符隔开;例如:
f_df = pd.read_csv(file_path,sep=":|;",engine="python",header=0)
3. delim_whitespace(不常用)
所有的空白字符,都可以用此来作为间隔,该值默认为False, 若我们将其更改为 True 则所有的空白字符:空格,\t, \n 等都会被当做分隔符;和sep功能相似;
4. header 和 names
这两个功能相辅相成,header 用来指定列名,例如header =0,则指定第一行为列名;若header =1 则指定第二行为列名;有时,我们的数据里没有列名,只有数据,这时候就需要names=[], 来指定列名;详细说明如下:
csv文件有表头并且是第一行,那么names和header都无需指定;csv文件有表头、但表头不是第一行,可能从下面几行开始才是真正的表头和数据,这个时候指定header即可;csv文件没有表头,全部是纯数据,那么我们可以通过names手动生成表头;csv文件有表头、但是这个表头你不想用,这个时候同时指定names和header。先用header选出表头和数据,然后再用names将表头替换掉,其实就等价于将数据读取进来之后再对列名进行rename;
举例如下:
names 没有被赋值,header 也没赋值:
file_path=r"E:\VSCODE\2_numpy_pandas\pandas\Game_Data.csv" df=pd.read_csv(file_path,sep=",|:|;",engine="python",header=0,encoding='gbk') print(df) # 我们说这种情况下,header为变成0,即选取文件的第一行作为表头

names 没有被赋值,header 被赋值:
pd.read_csv(file_path,sep=",|:|;",engine="python",header=1,encoding='gbk') # 不指定names,指定header为1,则选取第二行当做表头,第二行下面的是数据

names 被赋值,header 没有被赋值
pd.read_csv(file_path,sep=",|:|;",engine="python",encoding='gbk',names=["编号", "英雄", "游戏", "发行日期"])

names适用于没有表头的情况,指定names没有指定header,那么header相当于None。一般来说,读取文件会有一个表头的,一般是第一行,但是有的文件只是数据而没有表头,那么这个时候我们就可以通过names手动指定、或者生成表头,而文件里面的数据则全部是内容。所以这里"编号", “角色”, “源于”, “发行日” 也当成是一条记录了,本来它是表头的,但是我们指定了names,所以它就变成数据了,表头是我们在names里面指定的
names和header都被赋值:
pd.read_csv(file_path,sep=",|:|;",engine="python",encoding='gbk',names=["编号", "英雄", "游戏", "发行日期"],header=0)

这个相当于先不看names,只看header,我们说header等于0代表什么呢?显然是把第一行当做表头,下面的当成数据,好了,然后再把表头用names给替换掉。
5. index_col
我们在读取文件之后,生成的 DataFrame 的索引默认是0 1 2 3…,我们当然可以 set_index,但是也可以在读取的时候就指定某个列为索引。
pd.read_csv(file_path,engine="python",encoding='gbk',header=0,index_col="角色")
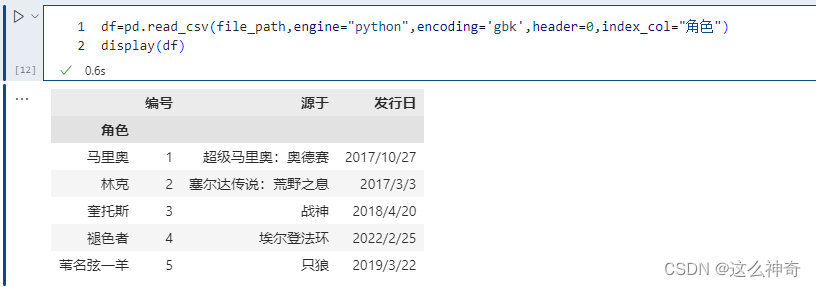
这里指定 “name” 作为索引,另外除了指定单个列,还可以指定多个列,比如 [“id”, “name”]。并且我们除了可以输入列的名字之外,还可以输入对应的索引。比如:“id”、“name”、“address”、“date” 对应的索引就分别是0、1、2、3。
6. usecols
如果列有很多,而我们不想要全部的列、而是只要指定的列就可以使用这个参数。
pd.read_csv(file_path,encoding='gbk',usecols=["角色", "发行日"])

同 index_col 一样,除了指定列名,也可以通过索引来选择想要的列,比如:usecols=[1, 3] 也会选择 “角色” 和 “发行日” 两列,因为 “角色” 这一列对应的索引是 1、“发行日” 对应的索引是 3。
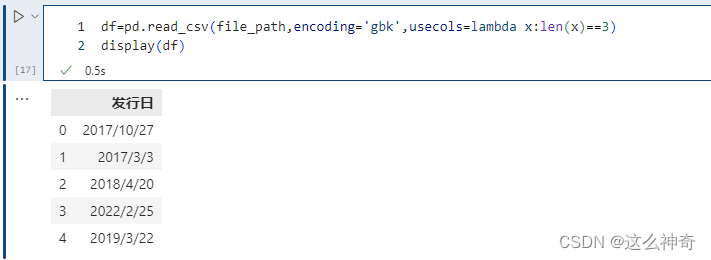
此外 use_cols 还有一个比较好玩的用法,就是接收一个函数,会依次将列名作为参数传递到函数中进行调用,如果返回值为真,则选择该列,不为真,则不选择。
# 选择列名的长度等于 3 的列,显然此时只会选择 发行日 这一列 pd.read_csv(file_path,encoding='gbk',usecols=lambda x:len(x)==3)
7. mangle_dupe_cols
实际生产用的数据会很复杂,有时导入的数据会含有重名的列。参数 mangle_dupe_cols 默认为 True,重名的列导入后面多一个 .1。如果设置为 False,会抛出不支持的异常:
# ValueError: Setting mangle_dupe_cols=False is not supported yet
8. prefix
prefix 参数,当导入的数据没有 header 时,设置此参数会自动加一个前缀。比如:
pd.read_csv(file_path,encoding='gbk',header=None,prefix="角色")

9. dtype
有时候,工作人员的id都是以0开头的,比如0100012521,这是一个字符串。但是在读取的时候解析成整型了,结果把开头的0给丢了。这个时候我们就可以通过dtype来指定某个列的类型,就是告诉pandas:你在解析的时候不要自以为是,直接按照老子指定的类型进行解析就可以了,我不要你觉得,我要我觉得。
df=pd.read_csv(file_path,encoding='gbk',dtype={"编号": str})df["编号"]=df["编号"]*4

10. engine
pandas解析数据时用的引擎,pandas 目前的解析引擎提供两种:c、python,默认为 c,因为 c 引擎解析速度更快,但是特性没有 python 引擎全。如果使用 c 引擎没有的特性时,会自动退化为 python 引擎。
比如使用分隔符进行解析,如果指定分隔符不是单个字符、或者"\s+“,那么c引擎就无法解析了。我们知道如果分隔符为空白字符的话,那么可以指定delim_whitespace=True,但是也可以指定sep=r”\s+"。
df=pd.read_csv(file_path,encoding='gbk',dtype={"编号": str})
df["编号"]=df["编号"]*4
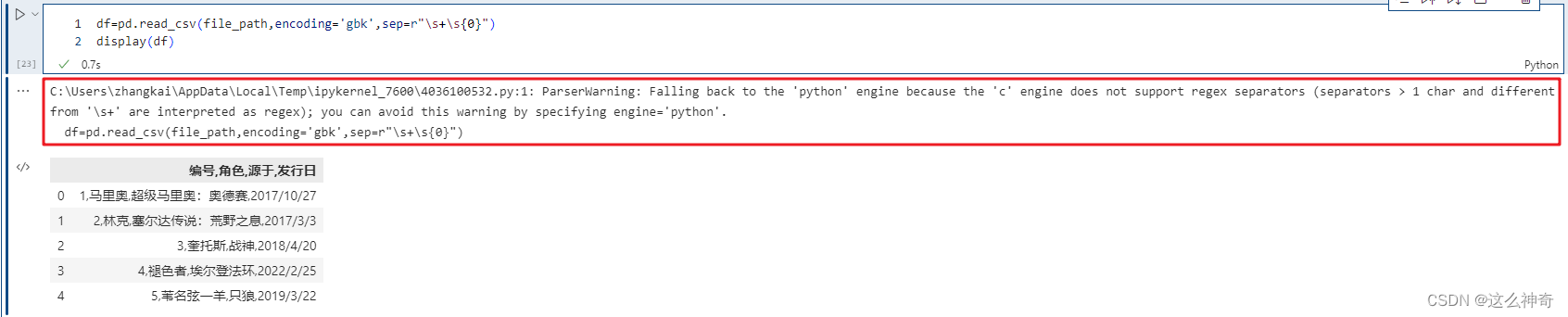
我们看到虽然自动退化,但是弹出了警告,这个时候需要手动的指定engine="python"来避免警告。这里面还用到了encoding参数,这个后面会说,因为引擎一旦退化,在Windows上不指定会读出乱码。这里我们看到sep是可以支持正则的,但是说实话sep这个参数都会设置成单个字符,原因是读取的csv文件的分隔符是单个字符。
11. converters
可以在读取的时候对列数据进行变换:
pd.read_csv(file_path,encoding='gbk', converters={<!--{C}%3C!%2D%2D%20%2D%2D%3E-->"编号": lambda x: int(x) + 10})

将id增加10,但是注意 int(x),在使用converters参数时,解析器默认所有列的类型为 str,所以需要显式类型转换。
12. true_values和false_value
指定哪些值应该被清洗为True,哪些值被清洗为False。
pd.read_csv(file_path,encoding='gbk',true_values=["林克","奎托斯","褪色者","苇名弦一羊"],false_values=["马里奥"])

注意这里的替换规则,只有当某一列的数据全部出现在true_values + false_values里面,才会被替换。例如执行以下内容,不会发生变化;
pd.read_csv(file_path,encoding='gbk',true_values=["林克"],false_values=["马里奥"])

13. skiprows
skiprows 表示过滤行,想过滤掉哪些行,就写在一个列表里面传递给skiprows即可。注意的是:这里是先过滤,然后再确定表头,比如:
pd.read_csv(file_path,encoding='gbk',skiprows=[0])

我们把第一行过滤掉了,但是第一行是表头,所以过滤掉之后,第二行就变成表头了。如果过滤掉第二行,那么只相当于少了一行数据,但是表头还是原来的第一行。
当然里面除了传入具体的数值,来表明要过滤掉哪些行,还可以传入一个函数。
pd.read_csv(file_path,encoding='gbk',skiprows=lambda x:x>0 and x%2==1)
由于索引从0开始,凡是索引2等于1的记录都过滤掉。索引大于0,是为了保证表头不被过滤掉。

14. skipfooter
从文件末尾过滤行,解析引擎退化为 Python。这是因为 C 解析引擎没有这个特性。
pd.read_csv(file_path,encoding='gbk',skipfooter=2)

如果不想报以上的Warning, 可以将Engine 指定为Python, 如下:

skipfooter接收整型,表示从结尾往上过滤掉指定数量的行,因为引擎退化为python,那么要手动指定engine=“python”,不然会警告。
15. nrows
nrows 参数设置一次性读入的文件行数,它在读入大文件时很有用,比如 16G 内存的PC无法容纳几百 G 的大文件。
pd.read_csv(file_path,encoding='gbk',nrows=4)

很多时候我们只是想看看大文件内部的字段长什么样子,所以这里通过nrows指定读取的行数。
16. na_values
na_values 参数可以配置哪些值需要处理成 NaN,这个是非常常用的。
pd.read_csv(file_path,encoding='gbk',na_values=['马里奥','战神'])

我们看到将 ‘马里奥’ 和 ‘战神’ 设置成了NaN,当然我们这里不同的列,里面包含的值都是不相同的。但如果两个列中包含相同的值,而我们只想将其中一个列的值换成NaN该怎么做呢?通过字典实现只对指定的列进行替换。以下的例子可以看到,战神并没有被替换成NaN, 因为在角色里没有这个值;/
pd.read_csv(file_path,encoding='gbk',na_values={<!--{C}%3C!%2D%2D%20%2D%2D%3E-->"角色":['马里奥','战神'],'编号':[2]})

17. keep_default_na
我们知道,通过 na_values 参数可以让 pandas 在读取 CSV 的时候将一些指定的值替换成空值,但除了 na_values 指定的值之外,还有一些默认的值也会在读取的时候被替换成空值,这些值有: “-1.#IND”、“1.#QNAN”、“1.#IND”、“-1.#QNAN”、“#N/A N/A”、“#N/A”、“N/A”、“NA”、“#NA”、“NULL”、“NaN”、“-NaN”、“nan”、“-nan”、“” 。尽管这些值在 CSV 中的表现形式是字符串,但是 pandas 在读取的时候会替换成空值(真正意义上的 NaN)。不过有些时候我们不希望这么做,比如有一个具有业务含义的字符串恰好就叫 “NA”,那么再将它替换成空值就不对了。
这个时候就可以将 keep_default_na 指定为 False,默认为 True,如果指定为 False,那么 pandas 在读取时就不会擅自将那些默认的值转成空值了,它们在 CSV 中长什么样,pandas 读取出来之后就还长什么样,即使单元格中啥也没有,那么得到的也是一个空字符串。但是注意,我们上面介绍的 na_values 参数则不受此影响,也就是说即便 keep_default_na 为 False,na_values 参数指定的值也依旧会被替换成空值。举个栗子,假设某个 CSV 中存在 “NULL”、“NA”、以及空字符串,那么默认情况下,它们都会被替换成空值。但 “NA” 是具有业务含义的,我们希望保留原样,而 “NULL” 和空字符串,我们还是希望 pandas 在读取的时候能够替换成空值,那么此时就可以在指定 keep_default_na 为 False 的同时,再指定 na_values 为 ["NULL", ""]
18. na_filter
是否进行空值检测,默认为 True,如果指定为 False,那么 pandas 在读取 CSV 的时候不会进行任何空值的判断和检测,所有的值都会保留原样。因此,如果你能确保一个 CSV 肯定没有空值,则不妨指定 na_filter 为 False,因为避免了空值检测,可以提高大型文件的读取速度。另外,该参数会屏蔽 keep_default_na 和 na_values,也就是说,当 na_filter 为 False 的时候,这两个参数会失效。
从效果上来说,na_filter 为 False 等价于:不指定 na_values、以及将 keep_default_na 设为 False。
19. skip_blank_lines
skip_blank_lines 默认为 True,表示过滤掉空行,如为 False 则解析为 NaN。
20. parse_dates
指定某些列为时间类型,这个参数一般搭配下面的date_parser使用。
21. date_parser
是用来配合parse_dates参数的,因为有的列虽然是日期,但没办法直接转化,需要我们指定一个解析格式:
from datetime import datetime pd.read_csv(file_path,encoding='gbk',parse_dates=['发行日'],date_parser=lambda x:datetime.strptime(x,'%Y/%m/%d'))

22. infer_datetime_format
infer_datetime_format 参数默认为 False。如果设定为 True 并且 parse_dates 可用,那么 pandas 将尝试转换为日期类型,如果可以转换,转换方法并解析,在某些情况下会快 5~10 倍。
23. iterator
iterator 为 bool类型,默认为False。如果为True,那么返回一个 TextFileReader 对象,以便逐块处理文件。这个在文件很大、内存无法容纳所有数据文件时,可以分批读入,依次处理。
df=pd.read_csv(file_path,encoding='gbk',iterator=True)
display(df.get_chunk(2))
"""
编号 角色 源于 发行日
0 1 马里奥 超级马里奥:奥德赛 2017/10/27
1 2 林克 塞尔达传说:荒野之息 2017/3/3
"""
print(chunk.get_chunk(1))
"""
编号 角色 源于 发行日
2 3 奎托斯 战神 2018/4/20
"""
# 文件还剩下三行,但是我们指定读取10,那么也不会报错,不够指定的行数,那么有多少返回多少
print(chunk.get_chunk(10))
"""
编号 角色 源于 发行日
3 4 褪色者 埃尔登法环 2022/2/25
4 5 苇名弦一羊 只狼 2019/3/22
"""
try:
# 但是在读取完毕之后,再读的话就会报错了
chunk.get_chunk(5)
except StopIteration as e:
print("读取完毕")
# 读取完毕
24. chunksize
chunksize 整型,默认为 None,设置文件块的大小。
chunk = pd.read_csv(file_path, sep="\t", chunksize=2)
# 还是返回一个类似于迭代器的对象
# 调用get_chunk,如果不指定行数,那么就是默认的chunksize
print(chunk.get_chunk())
"""
编号 角色 源于 发行日
0 1 马里奥 超级马里奥:奥德赛 2017/10/27
1 2 林克 塞尔达传说:荒野之息 2017/3/3
"""
# 但也可以指定
print(chunk.get_chunk(100))
"""
编号 角色 源于 发行日
2 3 奎托斯 战神 2018/4/20
3 4 褪色者 埃尔登法环 2022/2/25
4 5 苇名弦一羊 只狼 2019/3/22
"""
try:
chunk.get_chunk(5)
except StopIteration as e:
print("读取完毕")
# 读取完毕
25. compression
compression 参数取值为 {‘infer’, ‘gzip’, ‘bz2’, ‘zip’, ‘xz’, None},默认 ‘infer’,这个参数直接支持我们使用磁盘上的压缩文件。
# 直接将上面的.csv添加到压缩文件,打包成game_data.zip
pd.read_csv('game_data.zip', compression="zip",encoding='gbk')
26. thousands
千分位分割符,如 , 或者 .,默认为None。
27. encoding
encoding 指定字符集类型,通常指定为 ‘utf-8’。根据情况也可能是’ISO-8859-1’,本文中所有的encoding='gbk' ,主要原因为:我的数据是用Excel 保存成.CSV的,默认的编码格式为GBK;
28. error_bad_lines和warn_bad_lines
如果一行包含过多的列,假设csv的数据有5列,但是某一行却有6个数据,显然数据有问题。那么默认情况下不会返回DataFrame,而是会报错。
我们在某一行中多加了一个数据,结果显示错误。因为girl.csv里面有5列,但是有一行却有6个数据,所以报错。
在小样本读取时,这个错误很快就能发现。但是如果样本比较大、并且由于数据集不可能那么干净,会很容易出现这种情况,那么该怎么办呢?而且这种情况下,Excel基本上是打不开这么大的文件的。这个时候我们就可以将error_bad_lines设置为False(默认为True),意思是遇到这种情况,直接把这一行给我扔掉。同时会设置 warn_bad_lines 设置为True,打印剔除的这行。
pd.read_csv(file_path,encoding='gbk',error_bad_lines=False, warn_bad_lines=True)

以上两参数只能在C解析引擎下使用。
以上就是针对Pandas的总结以及数据读取_pd.read_csv()的使用详解的详细内容,更多关于pandas总结的资料请关注我们其它相关文章!
相关推荐
-
Pandas.DataFrame时间序列数据处理的实现
目录 如何将一列现有数据指定为DatetimeIndex 读取CSV时如何指定DatetimeIndex 关于pandas.Series 将pandas.DataFrame,pandas.Series的索引设置为datetime64 [ns]类型时,将其视为DatetimeIndex,并且可以使用各种处理时间序列数据的函数. 可以按年或月指定行,并按切片指定提取周期,这在处理包含日期和时间信息(例如日期和时间)的数据时非常方便. 在此,将对以下内容进行描述. 如何将一列现有数据指定为Dateti
-
Pandas merge合并两个DataFram的实现
目录 Pandas merge 保留左边的DataFram Pandas merge pandas.merge()是pandas库中用于合并两个或多个DataFrame对象的函数,其常用的参数有以下几个: left:要合并的左侧DataFrame. right:要合并的右侧DataFrame. how:指定合并方式,包括‘left’.‘right’.‘outer’和‘inner’四种. on:指定按照哪些列进行合并,可以是单个列名或包含多个列名的列表. left_on和right_on:指定左侧
-
Pandas中MultiIndex选择并提取任何行和列
目录 选择并提取带有loc的任何行或列 特殊切片规范:slice(),pd.IndexSlice [] xs方法 给选择赋值 使用多索引(分层索引)可以方便地对pandas.DataFrame和pandas.Series的索引进行分层配置,以便可以为每个层次结构计算统计信息,例如总数和平均值. 以下csv数据为例.每个索引列都命名为level_x. import pandas as pd df = pd.read_csv('./data/25/sample_multi.csv', index_c
-
pandas中按行或列的值对数据排序的实现
目录 一. 按列的值对数据排序 1.按某一列的值对数据排序 2. 按多列的值对数据排序 3. key 参数:设置排序时的数据变换函数 4. 修改原数据 二. 按行的值对数据排序 参考 在处理表格型数据时,常会用到排序,比如,按某一行或列的值对表格排序,要怎么做呢? 这就要用到 pandas 中的 sort_values() 函数. 一. 按列的值对数据排序 先来看最常见的情况. 1.按某一列的值对数据排序 以下面的数据为例. import pandas as pd df_col = pd.Dat
-
pandas.DataFrame中提取特定类型dtype的列
目录 select_dtypes()的基本用法 指定要提取的类型:参数include 指定要排除的类型:参数exclude pandas.DataFrame为每一列保存一个数据类型dtype. 要仅提取(选择)特定数据类型为dtype的列,请使用pandas.DataFrame的select_dtypes()方法. 以带有各种数据类型的列的pandas.DataFrame为例. import pandas as pd df = pd.DataFrame({'a': [1, 2, 1, 3],
-
Pandas通过index选择并获取行和列
目录 获取pandas.DataFrame的列 列名称:将单个列作为pandas.Series获得 列名称的列表:将单个或多个列作为pandas.DataFrame获得 获取pandas.DataFrame的行 行名・行号的切片:将单行或多行作为pandas.DataFrame获得 获取pandas.Series的值 标签名称:获取每种类型的单个元素的值 标签名称/数字切片:将单个元素或多个元素的值作为pandas.Series获得 获取pandas.DataFrame元素的值 行名/列名是整数
-
pandas读取Excel批量转换时间戳的实践
目录 一.安装 二. 代码如下 python将GPS时间戳批量转换为日期时间(年月日时分秒) 一.安装 pip install pandas 如果出报错,不能运行,可以安装 pip install xlrd 二. 代码如下 import pandas as pd import time,datetime file_path = r'C:\Users\Administrator\Desktop\携号转网测试\admin_log.xls' df = pd.read_excel(file_path,
-
Spark中的数据读取保存和累加器实例详解
目录 数据读取与保存 Text文件 Sequence文件 Object对象文件 累加器 累加器概念 系统累加器 数据读取与保存 Text文件 对于 Text文件的读取和保存 ,其语法和实现是最简单的,因此我只是简单叙述一下这部分相关知识点,大家可以结合demo具体分析记忆. 1)基本语法 (1)数据读取:textFile(String) (2)数据保存:saveAsTextFile(String) 2)实现代码demo如下: object Operate_Text { def main(args
-
对python pandas读取剪贴板内容的方法详解
我使用的Python3.5,32版本win764位系统,pandas0.19版本,使用df=pd.read_clipboard()的时候读不到数据,百度查找解决方法,找到了一个比较靠谱的 打开site-packages\pandas\io\clipboard.py 在 text = clipboard_get() 后面一行 加入这句: text = text.decode('UTF-8') 保存,然后就可以使用了 df=pd.read_clipboard() #变成正常的了 下次可以在其他地方复
-
对pandas写入读取h5文件的方法详解
1.引言 通过参考相关博客对hdf5格式简要介绍. hdf5在存储的是支持压缩,使用的方式是blosc,这个是速度最快的也是pandas默认支持的. 使用压缩可以提磁盘利用率,节省空间. 开启压缩也没有什么劣势,只会慢一点点. 压缩在小数据量的时候优势不明显,数据量大了才有优势. 同时发现hdf读取文件的时候只能是一次写,写的时候可以append,可以put,但是写完成了之后关闭文件,就不能再写了, 会覆盖. 另外,为什么单独说pandas,主要因为本人目前对于h5py这个包的理解不是很深入,不
-

Python Pandas中合并数据的5个函数使用详解
目录 join 索引一致 索引不一致 merge concat 纵向拼接 横向拼接 append combine 前几天在一个群里面,看到一位朋友,说到自己的阿里面试,被问了一些关于pandas的使用.其中一个问题是:pandas中合并数据的5中方法. 今天借着这个机会,就为大家盘点一下pandas中合并数据的5个函数.但是对于每个函数,我这里不打算详细说明,具体用法大家可以参考pandas官当文档. join主要用于基于索引的横向合并拼接: merge主要用于基于指定列的横向合并拼接: con
-
SparkSQL读取hive数据本地idea运行的方法详解
环境准备: hadoop版本:2.6.5 spark版本:2.3.0 hive版本:1.2.2 master主机:192.168.100.201 slave1主机:192.168.100.201 pom.xml依赖如下: <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="
-
pandas数据合并之pd.concat()用法详解
目录 一.简介 二 .代码 例1:上下堆叠拼接 例2:axis=1 左右拼接 一.简介 pd.concat()函数可以沿着指定的轴将多个dataframe或者series拼接到一起. 基本语法: pd.concat( objs, axis=0, join=‘outer’, join_axes=None,ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=None, copy=Tr
-
对pandas中两种数据类型Series和DataFrame的区别详解
1. Series相当于数组numpy.array类似 s1=pd.Series([1,2,4,6,7,2]) s2=pd.Series([4,3,1,57,8],index=['a','b','c','d','e']) print s2 obj1=s2.values # print obj1 obj2=s2.index # print obj2 # print s2[s2>4] # print s2['b'] 1.Series 它是有索引,如果我们未指定索引,则是以数字自动生成. 下面是一些例
-
oracle数据匹配merge into的实例详解
oracle数据匹配merge into的实例详解 前言: 很久之前,估计在2010年左右在使用Oralce,当时有个需求就是需要对两个表的数据进行匹配,这两个表的数据结构一致,一个是正式表,一个是临时表,这两表数据量还算是比较大几百M.业务需求是用临时表中的数据和正式表的匹配,所有字段都需要一一匹配,而且两表还没有主键,这是一个比较麻烦和糟糕的事情. 场景: 1.如果两表所有字段值都一致则不处理: 2.如果有部分字段不一致则更新: 3.如果正式表中数据在临时表中不存在,则需要删除: 满足上面场
-
numpy库与pandas库axis=0,axis= 1轴的用法详解
对数据进行操作时,经常需要在横轴方向或者数轴方向对数据进行操作,这时需要设定参数axis的值: axis = 0 代表对横轴操作,也就是第0轴: axis = 1 代表对纵轴操作,也就是第1轴: numpy库中横轴.纵轴 axis 参数实例详解: In [1]: import numpy as np #生成一个3行4列的数组 In [2]: a = np.arange(12).reshape(3,4) In [3]: a Out[3]: array([[ 0, 1, 2, 3], [ 4, 5,
-
vue 界面刷新数据被清除 localStorage的使用详解
localStorage是html5新增的一个本地存储API,它有5M的大小空间,通过(key,value)的方式存储在浏览器中 window.localStorage.setItem('key', value); //储存文件 window.localStorage.getItem('key'); //读取文件 window.localStorage.removeItem('key'); //清除文件 vue中使用方法: 1.新建一个store.js文件 localStorage只能存储字符串