Lucene fnm索引文件格式源码解析
目录
- 简介
- 版本
- 涉及的主要类
- 代码示例
- 文件结构全局示意图
- 字段描述
- Header
- FieldCount
- Field
- FieldName
- FieldNumber
- FieldBits
- IndexOptions
- DocValuesBits
- DocValuesGen
- Attributes
- PointDimensionCount
- PointNumBytes
- VectorDimension
- VectorSimilarityFunction
- Footer
简介
后缀为fnm文件是存储索引的字段的元信息,包含字段名称,字段类型,字段属性等信息。
版本
lucene 9.1.0
涉及的主要类
fnm索引文件的生成源码比较简单,不贴了,主要逻辑在:
org.apache.lucene.codecs.lucene90.Lucene90FieldInfosFormat
代码示例
FieldType fieldType = new FieldType();
fieldType.setStored(true);
fieldType.setStoreTermVectors(true);
fieldType.setStoreTermVectorOffsets(true);
fieldType.setStoreTermVectorPositions(true);
fieldType.setStoreTermVectorPayloads(true);
fieldType.setTokenized(true);
fieldType.setOmitNorms(true);
fieldType.setIndexOptions(IndexOptions.DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS);
Document doc = new Document();
doc.add(new Field("name", "maria", fieldType));
doc.add(new SortedDocValuesField("name", new BytesRef("maria")));
doc.add(new IntPoint("id", 1, 2, 3));
doc.add(new KnnVectorField("vector", new float[]{1.1f, 2.2f, 3.3f}, VectorSimilarityFunction.COSINE));
文件结构全局示意图

字段描述
Header
文件头部信息,主要是包括:
- 文件头魔数(同一lucene版本所有文件相同)
- 该文件使用的codec名称:Lucene90FieldInfos(codec可以理解成文件的布局格式,不同版本lucene相同后缀文件有不一样的版本格式)
- codec版本
- segment后缀名(一般为空)
- segment id(也是Segment_N文件中的N)
FieldCount
该索引的field总数
Field
记录字段的元信息
FieldName
字段名称,比如示例代码中的name,id,vector都是字段名称
FieldNumber
字段的编号
FieldBits
部分属性的位图信息,是一个组合值,描述字段是否具有以下属性:
- 是否存储词向量(termVector):0x1
- 是否要忽略norm值:0x2
- 是否带有payload:0x4
- 该字段是否是软删除字段(soft delete):0x8
示例代码中的name字段的FieldBits的值为:0x1 | 0x2 | 0x4 = 0x7
IndexOptions
字段的索引选项,表示在索引该字段的时候存储的倒排信息有哪些,所有的类型:
- 0:NONE
- 1:DOCS
- 2:DOCS_AND_FREQS
- 3:DOCS_AND_FREQS_AND_POSITIONS
- 4:DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS
DocValuesBits
官方文档描述的是由norm和docValue类型的组合值,但是从源码看只存储了docValue类型。
- 0:NONE
- 1:NUMERIC
- 2:BINARY
- 3:SORTED
- 4:SORTED_SET
- 5:SORTED_NUMERIC
DocValuesGen
可以理解为字段DocValues的版本号,通过IndexWriter.updateDocValues(...)会更新该版本号
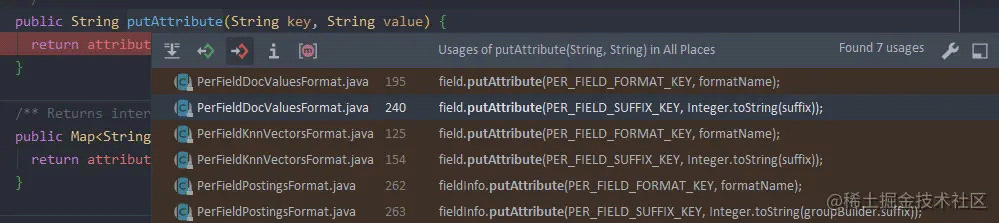
Attributes
可能的值有:
PointDimensionCount
如果字段是IntPoint,LongPoint等类型,则记录维数。
PointNumBytes
如果字段是IntPoint,LongPoint等类型,则记录每一维数据存储需要的字节个数。
VectorDimension
向量字段记录向量的维数
VectorSimilarityFunction
向量相似度衡量函数:
- EUCLIDEAN:欧式距离
- DOT_PRODUCT:点积
- COSINE:consine距离
Footer
文件尾,主要包括
- 文件尾魔数(同一个lucene版本所有文件一样)
- 0
- 校验码
以上就是Lucene fnm索引文件格式源码解析的详细内容,更多关于Lucene fnm索引文件格式的资料请关注我们其它相关文章!
相关推荐
-
Lucene源码系列多值编码压缩算法实例详解
目录 背景 特别说明 前置知识 总览 编解码 BulkOperation BulkOperationPacked 成员变量 构造器 编码 解码 BulkOperationPacked* 应用 PackedWriter 分段处理 AbstractBlockPackedWriter BlockPackedWriter MonotonicBlockPackedWriter DirectWriter DirectMonotonicWriter 总结 背景 在Lucene中,涉及到索引文件生成的时候,会看
-
Lucene单值编码压缩算法源码解析
目录 引言 VInt编码 编码原理 VInt编码1314 VInt编码10 VInt编码-10 源码实现 编码 解码 zigzag编码 编码原理 源码 编码 解码 ZFloat 编码原理 源码编码 解码 ZDouble 编码原理 源码编码 解码 TLong 编码原理 源码编码 解码 引言 本文收集了我在看Lucene源码中遇到的所有的对单值(int,long,float,double)的压缩算法,可能一种类型针对不同的场景会有多种不同的压缩策略,本文会随着我自己的源码阅读不断持续更新. 不管是什
-
Lucene fnm索引文件格式源码解析
目录 简介 版本 涉及的主要类 代码示例 文件结构全局示意图 字段描述 Header FieldCount Field FieldName FieldNumber FieldBits IndexOptions DocValuesBits DocValuesGen Attributes PointDimensionCount PointNumBytes VectorDimension VectorSimilarityFunction Footer 简介 后缀为fnm文件是存储索引的字段的元信息,包
-

.properties文件读取及占位符${...}替换源码解析
前言 我们在开发中常遇到一种场景,Bean里面有一些参数是比较固定的,这种时候通常会采用配置的方式,将这些参数配置在.properties文件中,然后在Bean实例化的时候通过Spring将这些.properties文件中配置的参数使用占位符"${}"替换的方式读入并设置到Bean的相应参数中. 这种做法最典型的就是JDBC的配置,本文就来研究一下.properties文件读取及占位符"${}"替换的源码,首先从代码入手,定义一个DataSource,模拟一下JDB
-
JAVA Vector源码解析和示例代码
第1部分 Vector介绍Vector 是矢量队列,它是JDK1.0版本添加的类.继承于AbstractList,实现了List, RandomAccess, Cloneable这些接口.Vector 继承了AbstractList,实现了List:所以,它是一个队列,支持相关的添加.删除.修改.遍历等功能.Vector 实现了RandmoAccess接口,即提供了随机访问功能.RandmoAccess是java中用来被List实现,为List提供快速访问功能的.在Vector中,我们即可以通过
-
Vue源码解析之数组变异的实现
力有不逮的对象 众所周知,在 Vue 中,直接修改对象属性的值无法触发响应式.当你直接修改了对象属性的值,你会发现,只有数据改了,但是页面内容并没有改变. 这是什么原因? 原因在于: Vue 的响应式系统是基于Object.defineProperty这个方法的,该方法可以监听对象中某个元素的获取或修改,经过了该方法处理的数据,我们称其为响应式数据.但是,该方法有一个很大的缺点,新增属性或者删除属性不会触发监听,举个栗子: var vm = new Vue({ data () { return
-
从vue源码解析Vue.set()和this.$set()
前言 最近死磕了一段时间vue源码,想想觉得还是要输出点东西,我们先来从Vue提供的Vue.set()和this.$set()这两个api看看它内部是怎么实现的. Vue.set()和this.$set()应用的场景 平时做项目的时候难免不会对 数组或者对象 进行这样的骚操作操作,结果发现,咦~~,他喵的,怎么页面没有重新渲染. const vueInstance = new Vue({ data: { arr: [1, 2], obj1: { a: 3 } } }); vueInstance.
-
Java源码解析之HashMap的put、resize方法详解
一.HashMap 简介 HashMap 底层采用哈希表结构 数组加链表加红黑树实现,允许储存null键和null值 数组优点:通过数组下标可以快速实现对数组元素的访问,效率高 链表优点:插入或删除数据不需要移动元素,只需要修改节点引用效率高 二.源码分析 2.1 继承和实现 public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
-
Python源码解析之List
一.列表结构体 创建列表C语言底层的结构体 lists = [] list.append('name') list.append('age') list.append('grade') typedef struct{ struct _object *_ob_next; struct _object *_ob_prev; // python内部将对象放在链表进行内存管理 Py_ssize_t ob_refcnt; // 引用计数器,就是多少变量用了它 PyObject **ob_item; //
-
Java1.7全网最深入HashMap源码解析
目录 存储结构 属性成员 构造函数: hash方法 Map中添加数据 put方法 流程图 源码 inflateTable方法 putForNullKey方法 addEntry方法 createEntry方法 扩容方法 resize方法 transfer方法 从HashMap中获取数据 get方法 从HashMap中删除数据 remove方法 对HashMap的其他操作 1.7和1.8版本区别 数据结构 hash值计算方式 扩容机制 存储结构 内部包含了一个 Entry 类型的数组 table.E
-
java中CopyOnWriteArrayList源码解析
目录 简介 继承体系 源码解析 属性 构造方法 add(Ee)方法 add(intindex,Eelement)方法 addIfAbsent(Ee)方法 get(intindex) remove(intindex)方法 size()方法 提问 总结 简介 CopyOnWriteArrayList是ArrayList的线程安全版本,内部也是通过数组实现,每次对数组的修改都完全拷贝一份新的数组来修改,修改完了再替换掉老数组,这样保证了只阻塞写操作,不阻塞读操作,实现读写分离. 继承体系 public
-
java编程ThreadLocal上下传递源码解析
目录 引导语 1.用法演示 2.类结构 2.1.类泛型 2.2.关键属性 2.2.1.ThreadLocalMap 3.ThreadLocal是如何做到线程之间数据隔离的 4.set方法 5.get方法 6.扩容 7.总结 引导语 ThreadLocal 提供了一种方式,让在多线程环境下,每个线程都可以拥有自己独特的数据,并且可以在整个线程执行过程中,从上而下的传递. 1.用法演示 可能很多同学没有使用过 ThreadLocal,我们先来演示下 ThreadLocal 的用法,demo 如下: