Druid之连接创建及销毁示例详解
目录
- 前言
- 正文
- 一. DruidDataSource连接创建
- 二. DruidDataSource连接销毁
- 总结
前言
Druid是阿里开源的数据库连接池,是阿里监控系统Dragoon的副产品,提供了强大的可监控性和基于Filter-Chain的可扩展性。
本篇文章将对Druid数据库连接池的连接创建和销毁进行分析。分析Druid数据库连接池的源码前,需要明确几个概念。
- Druid数据库连接池中可用的连接存放在一个数组connections中;
- Druid数据库连接池做并发控制,主要靠一把可重入锁以及和这把锁关联的两个Condition对象;
public DruidAbstractDataSource(boolean lockFair) {
lock = new ReentrantLock(lockFair);
notEmpty = lock.newCondition();
empty = lock.newCondition();
}
- 连接池没有可用连接时,应用线程会在notEmpty上等待,连接池已满时,生产连接的线程会在empty上等待;
- 对连接保活,就是每间隔一定时间,对达到了保活间隔周期的连接进行有效性校验,可以将无效连接销毁,也可以防止连接长时间不与数据库服务端通信。
Druid版本:1.2.11
正文
一. DruidDataSource连接创建
DruidDataSource连接的创建由CreateConnectionThread线程完成,其run() 方法如下所示。
public void run() {
initedLatch.countDown();
long lastDiscardCount = 0;
int errorCount = 0;
for (; ; ) {
try {
lock.lockInterruptibly();
} catch (InterruptedException e2) {
break;
}
long discardCount = DruidDataSource.this.discardCount;
boolean discardChanged = discardCount - lastDiscardCount > 0;
lastDiscardCount = discardCount;
try {
// emptyWait为true表示生产连接线程需要等待,无需生产连接
boolean emptyWait = true;
// 发生了创建错误,且池中已无连接,且丢弃连接的统计没有改变
// 此时生产连接线程需要生产连接
if (createError != null
&& poolingCount == 0
&& !discardChanged) {
emptyWait = false;
}
if (emptyWait
&& asyncInit && createCount < initialSize) {
emptyWait = false;
}
if (emptyWait) {
// 池中已有连接数大于等于正在等待连接的应用线程数
// 且当前是非keepAlive场景
// 且当前是非连续失败
// 此时生产连接的线程在empty上等待
// keepAlive && activeCount + poolingCount < minIdle时会在shrink()方法中触发emptySingal()来添加连接
// isFailContinuous()返回true表示连续失败,即多次(默认2次)创建物理连接失败
if (poolingCount >= notEmptyWaitThreadCount
&& (!(keepAlive && activeCount + poolingCount < minIdle))
&& !isFailContinuous()
) {
empty.await();
}
// 防止创建超过maxActive数量的连接
if (activeCount + poolingCount >= maxActive) {
empty.await();
continue;
}
}
} catch (InterruptedException e) {
// 省略
} finally {
lock.unlock();
}
PhysicalConnectionInfo connection = null;
try {
connection = createPhysicalConnection();
} catch (SQLException e) {
LOG.error("create connection SQLException, url: " + jdbcUrl
+ ", errorCode " + e.getErrorCode()
+ ", state " + e.getSQLState(), e);
errorCount++;
if (errorCount > connectionErrorRetryAttempts
&& timeBetweenConnectErrorMillis > 0) {
// 多次创建失败
setFailContinuous(true);
// 如果配置了快速失败,就唤醒所有在notEmpty上等待的应用线程
if (failFast) {
lock.lock();
try {
notEmpty.signalAll();
} finally {
lock.unlock();
}
}
if (breakAfterAcquireFailure) {
break;
}
try {
Thread.sleep(timeBetweenConnectErrorMillis);
} catch (InterruptedException interruptEx) {
break;
}
}
} catch (RuntimeException e) {
LOG.error("create connection RuntimeException", e);
setFailContinuous(true);
continue;
} catch (Error e) {
LOG.error("create connection Error", e);
setFailContinuous(true);
break;
}
if (connection == null) {
continue;
}
// 把连接添加到连接池
boolean result = put(connection);
if (!result) {
JdbcUtils.close(connection.getPhysicalConnection());
LOG.info("put physical connection to pool failed.");
}
errorCount = 0;
if (closing || closed) {
break;
}
}
}
CreateConnectionThread的run() 方法整体就是在一个死循环中不断的等待,被唤醒,然后创建线程。当一个物理连接被创建出来后,会调用DruidDataSource#put方法将其放到连接池connections中,put() 方法源码如下所示。
protected boolean put(PhysicalConnectionInfo physicalConnectionInfo) {
DruidConnectionHolder holder = null;
try {
holder = new DruidConnectionHolder(DruidDataSource.this, physicalConnectionInfo);
} catch (SQLException ex) {
// 省略
return false;
}
return put(holder, physicalConnectionInfo.createTaskId, false);
}
private boolean put(DruidConnectionHolder holder,
long createTaskId, boolean checkExists) {
// 涉及到连接池中连接数量改变的操作,都需要加锁
lock.lock();
try {
if (this.closing || this.closed) {
return false;
}
// 池中已有连接数已经大于等于最大连接数,则不再把连接加到连接池并直接返回false
if (poolingCount >= maxActive) {
if (createScheduler != null) {
clearCreateTask(createTaskId);
}
return false;
}
// 检查重复添加
if (checkExists) {
for (int i = 0; i < poolingCount; i++) {
if (connections[i] == holder) {
return false;
}
}
}
// 连接放入连接池
connections[poolingCount] = holder;
// poolingCount++
incrementPoolingCount();
if (poolingCount > poolingPeak) {
poolingPeak = poolingCount;
poolingPeakTime = System.currentTimeMillis();
}
// 唤醒在notEmpty上等待连接的应用线程
notEmpty.signal();
notEmptySignalCount++;
if (createScheduler != null) {
clearCreateTask(createTaskId);
if (poolingCount + createTaskCount < notEmptyWaitThreadCount
&& activeCount + poolingCount + createTaskCount < maxActive) {
emptySignal();
}
}
} finally {
lock.unlock();
}
return true;
}
put() 方法会先将物理连接从PhysicalConnectionInfo中获取出来并封装成一个DruidConnectionHolder,DruidConnectionHolder就是Druid连接池中的连接。新添加的连接会存放在连接池数组connections的poolingCount位置,然后poolingCount会加1,也就是poolingCount代表着连接池中可以获取的连接的数量。
二. DruidDataSource连接销毁
DruidDataSource连接的销毁由DestroyConnectionThread线程完成,其run() 方法如下所示。
public void run() {
// run()方法只要执行了,就调用initedLatch#countDown
initedLatch.countDown();
for (; ; ) {
// 每间隔timeBetweenEvictionRunsMillis执行一次DestroyTask的run()方法
try {
if (closed || closing) {
break;
}
if (timeBetweenEvictionRunsMillis > 0) {
Thread.sleep(timeBetweenEvictionRunsMillis);
} else {
Thread.sleep(1000);
}
if (Thread.interrupted()) {
break;
}
// 执行DestroyTask的run()方法来销毁需要销毁的连接
destroyTask.run();
} catch (InterruptedException e) {
break;
}
}
}
DestroyConnectionThread的run() 方法就是在一个死循环中每间隔timeBetweenEvictionRunsMillis的时间就执行一次DestroyTask的run() 方法。DestroyTask#run方法实现如下所示。
public void run() {
// 根据一系列条件判断并销毁连接
shrink(true, keepAlive);
// RemoveAbandoned机制
if (isRemoveAbandoned()) {
removeAbandoned();
}
}
在DestroyTask#run方法中会调用DruidDataSource#shrink方法来根据设定的条件来判断出需要销毁和保活的连接。DruidDataSource#shrink方法如下所示。
// checkTime参数表示在将一个连接进行销毁前,是否需要判断一下空闲时间
public void shrink(boolean checkTime, boolean keepAlive) {
// 加锁
try {
lock.lockInterruptibly();
} catch (InterruptedException e) {
return;
}
// needFill = keepAlive && poolingCount + activeCount < minIdle
// needFill为true时,会调用empty.signal()唤醒生产连接的线程来生产连接
boolean needFill = false;
// evictCount记录需要销毁的连接数
// keepAliveCount记录需要保活的连接数
int evictCount = 0;
int keepAliveCount = 0;
int fatalErrorIncrement = fatalErrorCount - fatalErrorCountLastShrink;
fatalErrorCountLastShrink = fatalErrorCount;
try {
if (!inited) {
return;
}
// checkCount = 池中已有连接数 - 最小空闲连接数
// 正常情况下,最多能够将前checkCount个连接进行销毁
final int checkCount = poolingCount - minIdle;
final long currentTimeMillis = System.currentTimeMillis();
// 正常情况下,需要遍历池中所有连接
// 从前往后遍历,i为数组索引
for (int i = 0; i < poolingCount; ++i) {
DruidConnectionHolder connection = connections[i];
// 如果发生了致命错误(onFatalError == true)且致命错误发生时间(lastFatalErrorTimeMillis)在连接建立时间之后
// 把连接加入到保活连接数组中
if ((onFatalError || fatalErrorIncrement > 0)
&& (lastFatalErrorTimeMillis > connection.connectTimeMillis)) {
keepAliveConnections[keepAliveCount++] = connection;
continue;
}
if (checkTime) {
// phyTimeoutMillis表示连接的物理存活超时时间,默认值是-1
if (phyTimeoutMillis > 0) {
// phyConnectTimeMillis表示连接的物理存活时间
long phyConnectTimeMillis = currentTimeMillis
- connection.connectTimeMillis;
// 连接的物理存活时间大于phyTimeoutMillis,则将这个连接放入evictConnections数组
if (phyConnectTimeMillis > phyTimeoutMillis) {
evictConnections[evictCount++] = connection;
continue;
}
}
// idleMillis表示连接的空闲时间
long idleMillis = currentTimeMillis - connection.lastActiveTimeMillis;
// minEvictableIdleTimeMillis表示连接允许的最小空闲时间,默认是30分钟
// keepAliveBetweenTimeMillis表示保活间隔时间,默认是2分钟
// 如果连接的空闲时间小于minEvictableIdleTimeMillis且还小于keepAliveBetweenTimeMillis
// 则connections数组中当前连接之后的连接都会满足空闲时间小于minEvictableIdleTimeMillis且还小于keepAliveBetweenTimeMillis
// 此时跳出遍历,不再检查其余的连接
if (idleMillis < minEvictableIdleTimeMillis
&& idleMillis < keepAliveBetweenTimeMillis
) {
break;
}
// 连接的空闲时间大于等于允许的最小空闲时间
if (idleMillis >= minEvictableIdleTimeMillis) {
if (checkTime && i < checkCount) {
// i < checkCount这个条件的理解如下:
// 每次shrink()方法执行时,connections数组中只有索引0到checkCount-1的连接才允许被销毁
// 这样才能保证销毁完连接后,connections数组中至少还有minIdle个连接
evictConnections[evictCount++] = connection;
continue;
} else if (idleMillis > maxEvictableIdleTimeMillis) {
// 如果空闲时间过久,已经大于了允许的最大空闲时间(默认7小时)
// 那么无论如何都要销毁这个连接
evictConnections[evictCount++] = connection;
continue;
}
}
// 如果开启了保活机制,且连接空闲时间大于等于了保活间隔时间
// 此时将连接加入到保活连接数组中
if (keepAlive && idleMillis >= keepAliveBetweenTimeMillis) {
keepAliveConnections[keepAliveCount++] = connection;
}
} else {
// checkTime为false,那么前checkCount个连接直接进行销毁,不再判断这些连接的空闲时间是否超过阈值
if (i < checkCount) {
evictConnections[evictCount++] = connection;
} else {
break;
}
}
}
// removeCount = 销毁连接数 + 保活连接数
// removeCount表示本次从connections数组中拿掉的连接数
// 注:一定是从前往后拿,正常情况下最后minIdle个连接是安全的
int removeCount = evictCount + keepAliveCount;
if (removeCount > 0) {
// [0, 1, 2, 3, 4, null, null, null] -> [3, 4, 2, 3, 4, null, null, null]
System.arraycopy(connections, removeCount, connections, 0, poolingCount - removeCount);
// [3, 4, 2, 3, 4, null, null, null] -> [3, 4, null, null, null, null, null, null, null]
Arrays.fill(connections, poolingCount - removeCount, poolingCount, null);
// 更新池中连接数
poolingCount -= removeCount;
}
keepAliveCheckCount += keepAliveCount;
// 如果池中连接数加上活跃连接数(借出去的连接)小于最小空闲连接数
// 则将needFill设为true,后续需要唤醒生产连接的线程来生产连接
if (keepAlive && poolingCount + activeCount < minIdle) {
needFill = true;
}
} finally {
lock.unlock();
}
if (evictCount > 0) {
// 遍历evictConnections数组,销毁其中的连接
for (int i = 0; i < evictCount; ++i) {
DruidConnectionHolder item = evictConnections[i];
Connection connection = item.getConnection();
JdbcUtils.close(connection);
destroyCountUpdater.incrementAndGet(this);
}
Arrays.fill(evictConnections, null);
}
if (keepAliveCount > 0) {
// 遍历keepAliveConnections数组,对其中的连接做可用性校验
// 校验通过连接就放入connections数组,没通过连接就销毁
for (int i = keepAliveCount - 1; i >= 0; --i) {
DruidConnectionHolder holer = keepAliveConnections[i];
Connection connection = holer.getConnection();
holer.incrementKeepAliveCheckCount();
boolean validate = false;
try {
this.validateConnection(connection);
validate = true;
} catch (Throwable error) {
if (LOG.isDebugEnabled()) {
LOG.debug("keepAliveErr", error);
}
}
boolean discard = !validate;
if (validate) {
holer.lastKeepTimeMillis = System.currentTimeMillis();
boolean putOk = put(holer, 0L, true);
if (!putOk) {
discard = true;
}
}
if (discard) {
try {
connection.close();
} catch (Exception e) {
}
lock.lock();
try {
discardCount++;
if (activeCount + poolingCount <= minIdle) {
emptySignal();
}
} finally {
lock.unlock();
}
}
}
this.getDataSourceStat().addKeepAliveCheckCount(keepAliveCount);
Arrays.fill(keepAliveConnections, null);
}
// 如果needFill为true则唤醒生产连接的线程来生产连接
if (needFill) {
lock.lock();
try {
// 计算需要生产连接的个数
int fillCount = minIdle - (activeCount + poolingCount + createTaskCount);
for (int i = 0; i < fillCount; ++i) {
emptySignal();
}
} finally {
lock.unlock();
}
} else if (onFatalError || fatalErrorIncrement > 0) {
lock.lock();
try {
emptySignal();
} finally {
lock.unlock();
}
}
}
在DruidDataSource#shrink方法中,核心逻辑是遍历connections数组中的连接,并判断这些连接是需要销毁还是需要保活。通常情况下,connections数组中的前checkCount(checkCount = poolingCount - minIdle) 个连接是危险的,因为这些连接只要满足了:空闲时间 >= minEvictableIdleTimeMillis(允许的最小空闲时间),那么就需要被销毁,而connections数组中的最后minIdle个连接是相对安全的,因为这些连接只有在满足:空闲时间 > maxEvictableIdleTimeMillis(允许的最大空闲时间) 时,才会被销毁。这么判断的原因,主要就是需要让连接池里能够保证至少有minIdle个空闲连接可以让应用线程获取。
当确定好了需要销毁和需要保活的连接后,此时会先将connections数组清理,只保留安全的连接,这个过程示意图如下。
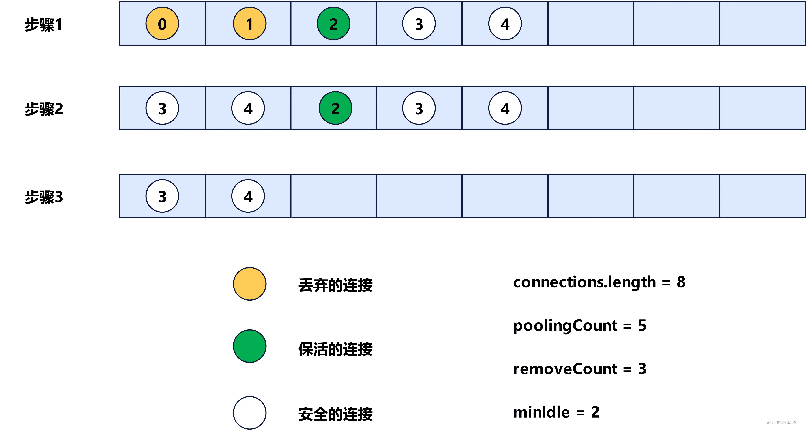
最后,会遍历evictConnections数组,销毁数组中的连接,遍历keepAliveConnections数组,对其中的每个连接做可用性校验,如果校验可用,那么就重新放回connections数组,否则销毁。
总结
连接的创建由一个叫做CreateConnectionThread的线程完成,整体流程就是在一个死循环中不断的等待,被唤醒,然后创建连接。每一个被创建出来的物理连接java.sql.Connection会被封装为一个DruidConnectionHolder,然后存放到connections数组中。
连接的销毁由一个叫做DestroyConnectionThread的线程完成,核心逻辑是周期性的遍历connections数组中的连接,并判断这些连接是需要销毁还是需要保活,需要销毁的连接最后会被物理销毁,需要保活的连接最后会进行一次可用性校验,如果校验不通过,则进行物理销毁。
以上就是Druid之连接创建及销毁示例详解的详细内容,更多关于Druid连接创建销毁的资料请关注我们其它相关文章!
相关推荐
-
解决springboot druid数据库连接池连接失败后一直重连问题
目录 druid数据库连接池连接失败后一直重连问题 druid数据库连接池技术的实现与常见错误 第一步,win+R cmd进入到doc窗口,敲入mysql -V 第二步,写好配置文件jdbc.properties 总结 druid数据库连接池连接失败后一直重连问题 当数据库暂停或者拒绝连接时,druid会一直连接 增加如下配置可以解决重连问题 spring.datasource.druid.break-after-acquire-failure=true spring.datasource.dr
-
拦截Druid数据源自动注入帐密解密实现详解
目录 背景 加密数据源自主实现流程 基础巩固 额外尝试 启示录 背景 SpringBoot 项目,使用 Druid 自动装配的数据源,数据源的帐号密码配置加密后,如何完成数据源的装配呢? druid-spring-boot-starter 虽然自带了加密配置,但是密钥也是配置的,如果需要用自定义的加密解密工具,如果不用自带的工具,怎么自定义实现加密数据源的装配呢? 本文从 DruidDataSourceAutoConfigure 类源码入手,仿造该类,自定义一个数据源注入配置,在真正注入 Dru
-

SpringBoot整合阿里 Druid 数据源的实例详解
目录 1. 在容器中注册 DruidDataSource 数据源. 2. Druid 数据源各种属性配置方法 3. 开启Druid的内置监控页面 4. 打开 Druid 监控统计功能 5. 配置Web和Spring关联监控 6. 配置防火墙: 7. 给监控页加入账号密码 前言:今年是我的第二个 1024 了 ,和我一起大声说出来,技术宅改变世界!!! 本节主要介绍的是:SpringBoot 整合阿里 Druid 数据源手动配置方法 1. 在容器中注册 DruidDataSource 数据源. 编
-
SpringBoot整合Mybatis与druid实现流程详解
目录 SpringBoot整合junit SpringBoot整合junit SpringBoot整合junit的classes SpringBoot整合Mybatis 整合前的准备 整合Mybatis SpringBoot 整合druid 配置前置知识小点 整合druid SpringBoot整合junit SpringBoot整合junit ①还是一样,我们首先创建一个SpringBoot模块. 由于我们并不测试前端,而只是整合junit,所以不用选择模板,选择其中的web即可. 完成以后我
-
Java Druid连接池与Apache的DBUtils使用教程
目录 Druid连接池 连接池思想 Druid连接池使用步骤 引入相关jar包 创建database.properties配置文件 编写连接池工具类 Druid连接池测试 Apache的DBUtils使用 Apache DBUtils介绍 Apache DBUtils特征 Apache DbUtils主要组成 Apache DbUtils使用步骤 综合案例 创建product表 向表中添加数据 创建实体类Product 创建ProductDao接口 创建ProductDaoImpl实现类 创建P
-
数据库连接池Druid与Hikari对比详解
目录 Druid竞品对比 Hikari 官方性能测试数据 对比 总结 Druid竞品对比 功能类别 功能 Druid HikariCP DBCP Tomcat-jdbc C3P0 性能 PSCache 是 否 是 是 是 LRU 是 否 是 是 是 SLB负载均衡支持 是 否 否 否 否 稳定性 ExceptionSorter 是 否 否 否 否 扩展 扩展 Filter JdbcIntercepter 监控 监控方式 jmx/log/http jmx/metrics jmx jmx jmx 支
-
Druid之连接创建及销毁示例详解
目录 前言 正文 一. DruidDataSource连接创建 二. DruidDataSource连接销毁 总结 前言 Druid是阿里开源的数据库连接池,是阿里监控系统Dragoon的副产品,提供了强大的可监控性和基于Filter-Chain的可扩展性. 本篇文章将对Druid数据库连接池的连接创建和销毁进行分析.分析Druid数据库连接池的源码前,需要明确几个概念. Druid数据库连接池中可用的连接存放在一个数组connections中: Druid数据库连接池做并发控制,主要靠一把可重
-
Python-Flask:动态创建表的示例详解
今天小编从项目的实际出发,由于项目某一个表的数据达到好几十万条,此时数据的增删查改会很慢:为了增加提高访问的速度,我们引入动态创建表. 代码如下: from app_factory import app from sqlalchemy import Column, String, Integer class ProjectModel(app.db.model, app.db.Mixin): tablename = 'Project_' ID = Column(String(50), name='
-
Oracle数据库创建存储过程的示例详解
1.1,Oracle存储过程简介: 存储过程是事先经过编译并存储在数据库中的一段SQL语句的集合,调用存储过程可以简化应用开发人员的很多工作, 减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效率是有好处的. 优点: 允许模块化程序设计,就是说只需要创建一次过程,以后在程序中就可以调用该过程任意次. 允许更快执行,如果某操作需要执行大量SQL语句或重复执行,存储过程比SQL语句执行的要快. 减少网络流量,例如一个需要数百行的SQL代码的操作有一条执行语句完成,不需要在网络中发送数百行代
-
File.createTempFile创建临时文件的示例详解
API参数: /** fileName: 临时文件的名字, 生成后的文件名字将会是[fileName + 随机数] suffix: 文件后缀,例如.txt, .tmp parentFile: 临时文件目录,如果不指定,则默认把临时文件存储于系统临时文件目录上 */ public static File createTempFile(String fileName, String suffix, File parentFile) 代码如下: import java.io.File; import
-
TensorFlow人工智能学习创建数据实现示例详解
目录 一.数据创建 1.tf.constant() 2.tf.convert_to_tensor() 3.tf.zeros() 4.tf.fill() 二.数据随机初始化 ①tf.random.normal() ②tf.random.truncated_normal() ③tf.random.uniform() ④tf.random.shuffle() 一.数据创建 1.tf.constant() 创建自定义类型,自定义形状的数据,但不能创建类似于下面In [59]这样的,无法解释的数据. 2.
-
Go语言基础切片的创建及初始化示例详解
目录 概述 语法 一.创建和初始化切片 make 字面量 二.使用切片 赋值和切片 切片增长 遍历切片 总结 总示例 示例一 两个slice是否相等 示例二 两个数字是否包含 概述 切片是一种动态数组 按需自动改变大小 与数组相比,切片的长度可以在运行时修改 语法 一.创建和初始化切片 make 使用内置函数make()创建切片: var slice []type = make([]type, len, cap) //简写: slice := make([]type, len, cap) 字面
-
c语言函数栈帧的创建和销毁过程详解
目录 1 相关知识介绍 1.1 寄存器 1.2 函数栈帧概述 2 栈帧创建与销毁过程 1 相关知识介绍 1.1 寄存器 一般计算机内通用寄存器包括eax,ebx,ecx,edx,esi,edi,esp,edp,其中esp,ebp这两个寄存器是用来存放地址的,这两个地址就是用来维护函数栈帧的 1.2 函数栈帧概述 我们知道c语言中函数都是被调用的,main函数里面能调用其他函数,其实main函数也是被别的函数调用的.main函数是在 _tmainCRTSartup 函数中被调用的,_tmainCR
-
使用OpenGL创建窗口的示例详解
目录 效果展示 窗口创建并启动渲染循环 效果展示 窗口创建并启动渲染循环 /* 因为OpenGL只是一个标准/规范,具体的实现是由驱动开发商针对特定显卡实现的. 由于OpenGL驱动版本众多,它大多数函数的位置都无法在编译时确定下来,需要在运行时查询. 所以任务就落在了开发者身上,开发者需要在运行时获取函数地址并将其保存在一个函数指针中供以后使用. GLAD是一个开源的库,它能解决我们上面提到的获取函数地址并将其保存在一个函数指针中供以后使用繁琐的问题 */ #include <glad/gla
-
Blender Python编程创建发光材质示例详解
目录 前言 正文 在 Python 脚本中创建一个着色器 我们的想法 具体代码与注释 创建发光材质 具体调用代码 前言 Blender 并不是唯一一款允许你为场景编程和自动化任务的3D软件; 随着每一个新版本的推出,Blender 正逐渐成为一个可靠的 CG 制作一体化解决方案,从使用油脂铅笔的故事板到基于节点的合成. 事实上,你可以使用 Python 脚本和一些额外的包来批处理你的对象实例化,程序化地生成东西,配置你的渲染设置,甚至获得你当前项目的自定义统计数据,这是非常棒的功能! 这是一种减
-
使用TLS加密通讯远程连接Docker的示例详解
默认情况下,Docker 通过非联网 UNIX 套接字运行.它还可以使用 HTTP 套接字进行可选通信. 如果需要以安全的方式通过网络访问 Docker,可以通过指定标志将 Docker 标志指向受信任的 CA 证书来启用 TLS. 在守护程序模式下,它只允许来自由该 CA 签名的证书验证的客户端的连接.在客户端模式下,它仅连接到具有该 CA 签名的证书的服务器. # 创建CA证书目录 [root@localhost ~]# mkdir tls [root@localhost ~]# cd tl