Python可视化绘制图表的教程详解
目录
- 1.Matplotlib 程序包
- 2.绘图命令的基本架构及其属性设置
- 3.Seaborn 模块介绍
- 3.1 未加Seaborn 模块的效果
- 4.描述性统计图形概览
- 4.1制作数据
- 4.2 频数分析
python 有许多可视化工具,但本书只介绍Matplotlib。Matplotlib是一种2D的绘图库,它可以支持硬拷贝和跨系统的交互,它可以在python脚本,IPython的交互环境下、Web应用程序中使用。该项目是由John Hunter 于2002年启动,其目的是为python构建MATLAB式的绘图接口。如果结合使用一种GUI工具包(如IPython),Matplotlib还具有诸如缩放和平移等交互功能。它不仅支持各种操作系统上许多不同的GUI后端,而且还能将图片导出为各种常见的矢量(vector)和光栅(raster)图:PDF、SVG、JPG、PNG、BMP、GIF等。
1.Matplotlib 程序包
所谓“一图胜千言”,我们很多时候需要通过可视化的方式查看、分析数据,虽然pandas中也有一些绘图操作,但是相比较而言,Matplotlib在绘图显示效果方面更加绚丽。Pyplot为Matplotlib提供了一个方便的接口,我们可以通过pyplot对matplotlib进行操作,多数情况下pyplot的命令与MATLAB有些相似。
导入Matplotlib包进行简单的操作(此处需要安装pip install matplotlib):
import matplotlib.pyplot as plt #首先定义两个函数(正弦&余弦) import numpy as np X = np.linspace(-np.pi,np.pi,256,endpoint=True) #-Π to +Π的256个值 C,S = np.cos(X),np.sin(X) plt.plot(X,C) plt.plot(X,S) #在ipython 的交互环境中需要这句才能显示出来 plt.show()

2.绘图命令的基本架构及其属性设置
上面的例子我们可以看出,几乎所有的属性和绘图的框架我们都选用默认设置。现在我们来看Pyplot 绘图的基本框架是什么,用过photoshop的人都知道,作图时先要定义一个画布,此处的画布就是Figure,然后把其他素材“画”到该Figure上。
(1)在Figure 上创建子plot,并设置属性,
具体简析和代码如下:
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0,10,1000) #X轴数据
y1 = np.sin(x) #Y轴数据
y2 = np.cos(x**2) #Y轴数据
plt.figure(figsize=(8,4))
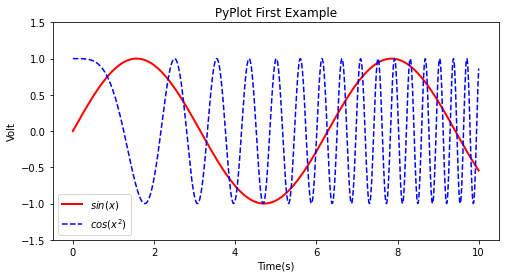
plt.plot(x,y1,label="$sin(x)$",color="red",linewidth=2)
plt.plot(x,y2,"b--",label="$cos(x^2)$")
#指定曲线的颜色和线形,如“b--”表示蓝色虚线(b:蓝色,-:虚线)
plt.xlabel("Time(s)")
plt.ylabel("Volt")
plt.title("PyPlot First Example")
#书上写的是:plt.figure(figsize(8,4))
#注意:会报错 name 'figsize' is not defined
#这里figsize是一个参数,并不是一个函数,给参数赋值中间需要加一个等号,写为:plt.figure(figsize=(8,4))
#使用关键字参数可以指定所绘制的曲线的各种属性:
#label:给曲线指定一个标签名称,此标签将在图示中显示。如果标签字符串的前后有字符“$”,则Matplotlib 会使用其内嵌的LaTex引擎将其显示为数学公式
#color:指定曲线的颜色。颜色可以用如下方法表示
#英文单词
#以“#”字符开头的3个16进制数,如“#ff0000”表示红色。以0~1的RGB表示,如(1.0,0.0,0.0)也表示红色
#linewidth:指定曲线的宽度,可以不是整数,也可以使用缩写形式的参数名lw
plt.ylim(-1.5,1.5)
plt.legend()
plt.show()
(2)在Figure上创建多个子plot
如果需要同时绘制多幅图表的话,可以给Figure传递一个整数参数指定图表的序号,如果所指定序号的绘图对象已经存在的话,将不创建新的对象,而只是让它成为当前绘图对象,具体分析和代码如下:
import numpy as np import matplotlib.pyplot as plt fig1 =plt.figure(2) plt.subplot(211) #subplot(211)把绘图区域等分为2行*1列共两个区域 #然后在区域1(上区域)中创建一个轴对象 plt.subplot(212)#在区域2(下区域)创建一个轴对象 plt.show()

#我们还可通过命令再次拆分这些块(相当于Word中拆分单元格的操作) f1 = plt.figure(5) plt.subplot(221) plt.subplot(222) plt.subplot(212) plt.subplots_adjust(left = 0.08,right = 0.95,wspace = 0.25,hspace = 0.45) #subplots_adjust的操作是类似网页csv格式化中的边距处理,左边距离多少? #右边边距多少?这个取决于你需要绘制的大小和各个模块之间的间距。 plt.show()

(3)通过Axes设置当前对象plot的属性
以上我们操作的是在Figure上绘制图案,但是当我们绘制的图案过多,又需要选取不同的小模块进行格式化设置时,Axes对象就能很好的解决这个问题。具体简析和代码如下:
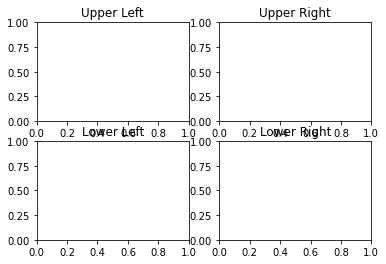
import numpy as np import matplotlib.pyplot as plt fig,axes = plt.subplots(nrows=2,ncols=2) #定一个2*2的plot plt.show()

#现在我们需要通过命令来操作每个plot(subplot),设置他们的title并删除横纵坐标值 fig,axes =plt.subplots(nrows=2,ncols=2) axes[0,0].set(title="Upper Left") axes[0,1].set(title="Upper Right") axes[1,0].set(title="Lower Left") axes[1,1].set(title="Lower Right")
另外,实际来说,plot操作的底层操作就是Axes对象的操作,只不过如果我们不使用Axes而用plot操作时,它默认的是plot.subplot(111),也就是说plot其实是Axes的特例
(4)保存Figure对象
最后一项操作就是保存,我们绘制的目的是用在其他研究中,或者希望可以把研究结果保存下来,此时需要的操作是save。具体简析和代码如下:
import numpy as np
import matplotlib.pyplot as plt
plt.savefig("save_test.png",dpi=520) #默认像素是dpi是80
#此处只是用了savefig属性对Figure进行保存
另外,除了上述的基本操作之外,Matplotlib还有其他的绘图优势,此处只是简单介绍了它在绘图时需要注意的事项。
3.Seaborn 模块介绍
前面我们简单介绍了Matplotlib库的绘图功能和属性设置,对于常规性的绘图,使用pandas的API属性研究较为透彻,几乎没有不能解决的问题。但是有的时候Matplotlib还是有它的不足之处,Matplotlib 自动化程度非常高,但是,掌握如何设置系统以便获得一个吸引人的图是相当困难的事。为了控制Matplotlib图表的外观,Seaborn 模块自带许多定制的主题和高级的接口。
3.1 未加Seaborn 模块的效果
具体简析和代码如下:
#有关于seaborn介绍
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
np.random.seed(sum(map(ord,"aesthetics")))
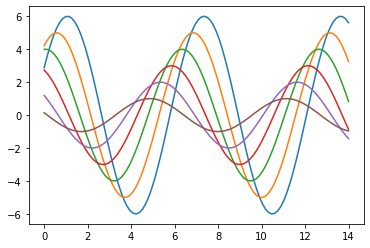
#首先定义一个函数用来画正弦函数,可帮助了解可以控制的不同风格参数
def sinplot(flip=1):
x=np.linspace(0,14,100)
for i in range(1,7):
plt.plot(x,np.sin(x+i*.5)*(7-i)*flip)
sinplot()
plt.show()

#有关于seaborn介绍
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
np.random.seed(sum(map(ord,"aesthetics")))
def sinplot(flip=1):
x = np.linspace(0,14,100)
for i in range(1,7):
plt.plot(x,np.sin(x + i * .5) * (7-i) * flip)
#转换成Seaborn 模块,只需要引入seaborn模块
import seaborn as sns #不同之处在此
sinplot()
plt.show()
使用seaborn的优点有:1.seaborn默认浅灰色背景与白色网格线的灵感来源于Matplotlib,却比matplotlib的颜色更加柔和;2.seaborn把绘图风格参数与数据参数分开设置。seaborn有两组函数对风格进行控制:axes_style()/set_style()函数和plotting_context()/set_context()函数。axes_style()函数和plotting_context()函数返回参数字典,set_style()函数和set_context()函数设置Matplotlib。
(1)使用set_style()函数
具体通过cording查看效果:
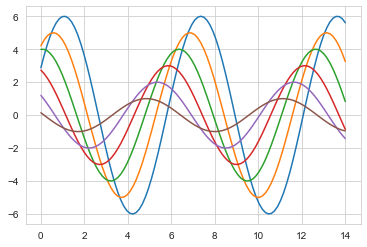
import seaborn as sns
sns.set_style("ticks")
sns.set_style("whitegrid")
sinplot()
plt.show()
#seaborn 有5种预定义的主题:
#darkgrid (灰色背景+白网格)
#whitegrid(白色背景+黑网格)
#dark (仅灰色背景)
#white (仅白色背景)
#ticks (坐标轴带刻度)
#默认的主题是darkgrid,修改主题可以使用set_style()函数
(2)使用set_context()函数
具体通过coding查看效果:
import seaborn as sns
sns.set_context("paper")
sinplot()
plt.show()
#上下文(context)可以设置输出图片的大小尺寸(scale)
#seaborn中预定义的上下文有4种:paper、notebook、talk和poster。 默认使用notebook上下文
(3)使用Seaborn“耍酷”
然而seaborn 不仅能够用来更改背景颜色,或者改变画布大小,还有其他很多方面的用途,比如下面这个例子:
import seaborn as sns
sns.set()
#通过加载sns自带数据库中的数据(具体数据可以不关心)
flights_long = sns.load_dataset("flights")
flights = flights_long.pivot("month","year","passengers")
#使用每个单元格中的数据值绘制一个热图heatmap
sns.heatmap(flights,annot=True,fmt="d",linewidths=.5)
plt.show()
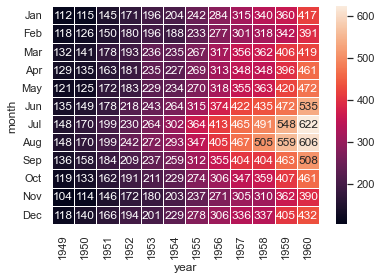
4.描述性统计图形概览
描述性统计是借助图表或者总结性的数值来描述数据的统计手段。数据挖掘工作的数据分析阶段,我们可借助描述性统计来描述或总结数据的基本情况,一来可以梳理自己的思维,二来可以更好地向他人展示数据分析结果。数值分析的过程中,我们往往要计算出数据的统计特征,用来做科学计算的Numpy和SciPy工具可以满足我们的需求。Matplotlib工具可用来绘制图,满足图分析的需求。
4.1制作数据
数据是自己制作的,主要包括个人身高、体重及一年的借阅图书量(之所以自己制作数据是因为不是每份真实的数据都可以进行接下来的分析,比如有些数据就不能绘制饼图,另一个角度也说明,此处举例的数据其实没有实际意义,只是为了分析而举例,但是不代表在具体的应用中这些分析不能发挥作用)。
另外,以下的数据显示都是在Seaborn库的作用下体现的效果。
#案例分析(结合图书情报学,比如借书量)
from numpy import array
from numpy.random import normal
def getData():
heights = []
weights = []
books = []
N =10000
for i in range(N):
while True:
#身高服从均值为172,标准差为6的正态分布
height = normal(172,6)
if 0<height:break
while True:
#体重由身高作为自变量的线性回归模型产生,误差服从标准正态分布
weight = (height-80)*0.7 + normal(0,1)
if 0 < weight:break
while True:
#借阅量服从均值为20,标准差为5的正态分布
number = normal(20,5)
if 0<= number and number<=50:
book = "E"if number <10 else("D"if number<15 else ("C"if number<20 else("B"if number<25 else "A")))
break
heights.append(height)
weights.append(weight)
books.append(book)
return array(heights),array(weights),array(books)
heights,weights,books =getData()
4.2 频数分析
(1)定性分析
柱状图和饼形图是对定性数据进行频数分析的常用工具,使用前需将每一类的频数计算出来。
①柱状图。柱状图是以柱的高度来指代某种类型的频数,使用Matplotlib对图书借阅量这一定性变量绘制柱状图的代码如下:
from matplotlib import pyplot
#绘制柱状图
def drawBar(books):
xticks=["A","B","C","D","E"]
bookGroup ={ }
#对每一类借阅量进行频数统计
for book in books:
bookGroup[book] = bookGroup.get(book,0) + 1
#创建柱状图
#第一个参数为柱的横坐标
#第二个参数为柱的高度
#参数align为柱的对齐方式,以第一个参数为参考标准
pyplot.bar(range(5),[bookGroup.get(xtick,0) for xtick in xticks],align="center")
#设置柱的文字说明
#第一个参数为文字说明的横坐标
#第二个参数为文字说明的内容
pyplot.xticks(range(5),xticks)
#设置横坐标的文字说明
pyplot.xlabel("Types of Students")
#设置纵坐标的文字说明
pyplot.ylabel("Frequency")
#设置标题
pyplot.title("Numbers of Books Students Read")
#绘图
pyplot.show()
drawBar(books)
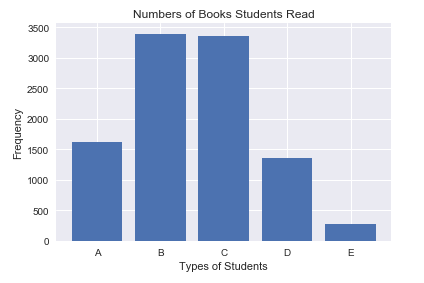
import matplotlib.pyplot as plt
num_list = [1506,3500,3467,1366,200]
pyplot.xlabel("Types of Students")
pyplot.ylabel("Frequency")
pyplot.title("Numbers of Books Students Read")
plt.bar(range(len(num_list)), num_list,color="green")
import seaborn as sns
sns.set_style("whitegrid")
plt.show()
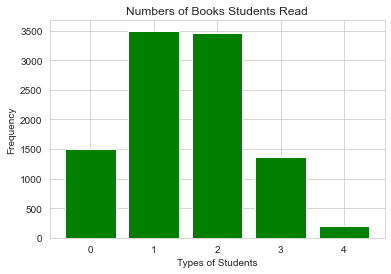
②饼形图。饼形图是以扇形的面积来指代某种类型的频率,使用Matplotlib对图书借阅量这一定性变量绘制饼形图的代码如下:
import numpy as np
import matplotlib.mlab as mlab
import matplotlib.pyplot as plt
labels=['A','B','C','D','E']
X=[257,145,32,134,252]
fig = plt.figure()
plt.pie(X,labels=labels,autopct='%1.1f%%') #画饼图(数据,数据对应的标签,百分数保留两位小数点)
plt.title("Numbers of Books Student Read")
plt.show()
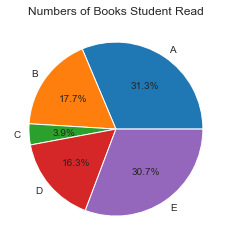
(2)定量分析
直方图类似于柱状图,是用柱的高度来指代频数,不同的是其将定量数据划分为若干连续的区间,在这些连续的区间上绘制柱。
①直方图。使用Matplotlib对身高这一定量变量绘制直方图的代码如下:
#绘制直方图
def drawHist(heights):
#创建直方图
#第一个参数为待绘制的定量数据,不同于定性数据,这里并没有实现进行频数统计
#第二个参数为划分的区间个数
pyplot.hist(heights,100)
pyplot.xlabel('Heights')
pyplot.ylabel('Frequency')
pyplot.title('Height of Students')
pyplot.show()
drawHist(heights)

累积曲线:使用Matplotlib对身高这一定量变量绘制累积曲线的代码如下:
#绘制累积曲线
def drawCumulativaHist(heights):
#创建累积曲线
#第一个参数为待绘制的定量数据
#第二个参数为划分的区间个数
#normal参数为是否无量纲化
#histtype参数为‘step',绘制阶梯状的曲线
#cumulative参数为是否累积
pyplot.hist(heights,20,normed=True,histtype='step',cumulative=True)
pyplot.xlabel('Heights')
pyplot.ylabel('Frequency')
pyplot.title('Heights of Students')
pyplot.show()
drawCumulativaHist(heights)
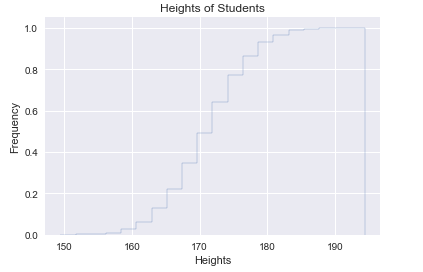
(3)关系分析
散点图。在散点图中,分别以自变量和因变量作为横坐标。当自变量与因变量线性相关时,散点图中的点近似分布在一条直线上。我们以身高作为自变量,体重作为因变量,讨论身高对体重的影响。使用Matplotlib绘制散点图的代码如下:
#绘制散点图
def drawScatter(heights,weights):
#创建散点图
#第一个参数为点的横坐标
#第二个参数为点的纵坐标
pyplot.scatter(heights,weights)
pyplot.xlabel('Heights')
pyplot.ylabel('Weight')
pyplot.title('Heights & Weight of Students')
pyplot.show()
drawScatter(heights,weights)

(4)探索分析
箱型图。在不明确数据分析的目标时,我们对数据进行一些探索性的分析,可以知道数据的中心位置、发散程度及偏差程度。使用Matplotlib绘制关于身高的箱型图代码如下:
#绘制箱型图
def drawBox(heights):
#创建箱型图
#第一个参数为待绘制的定量数据
#第二个参数为数据的文字说明
pyplot.boxplot([heights],labels=['Heights'])
pyplot.title('Heights of Students')
pyplot.show()
drawBox(heights)

注:
① 上四分位数与下四分位数的差叫四分位差,它是衡量数据发散程度的指标之一
② 上界线和下界线是距离中位数1.5倍四分位差的线,高于上界线或者低于下界线的数据为异常值
描述性统计是容易操作、直观简洁的数据分析手段。但是由于简单,对于多元变量的关系难以描述。现实生活中,自变量通常是多元的:决定体重的不仅有身高,还有饮食习惯、肥胖基因等因素。通过一些高级的数据处理手段,我们可以对多元变量进行处理,例如,特征工程中,可以使用互信息方法来选择多个对因变量有较强相关性的自变量作为特征,还可以使用主成分分析法来消除一些冗余的自变量来降低运算复杂度。
以上就是Python可视化绘制图表的教程详解的详细内容,更多关于Python可视化绘制图表的资料请关注我们其它相关文章!
相关推荐
-

Python seaborn数据可视化绘图(直方图,密度图,散点图)
目录 前言 一.直方图distplot() 二.密度图 1.单个样本数据分布密度图 2.两个样本数据分布密度图 三.散点图 1.jointplot()综合散点图 2.拆分综合散点图JointGrid() 3.pairplot()矩阵散点图 4.拆分综合散点图JointGrid() 前言 系统自带的数据表格,使用时通过sns.load_dataset('表名称')即可,结果为一个DataFrame. print(sns.get_dataset_names()) #获取所有数据表名称 # ['ans
-
python用matplotlib可视化绘图详解
目录 1.Matplotlib 简介 2.Matplotlib图形绘制 1)折线图 2)柱状图 3)条形图 3)饼图 4)散点图 5)直方图 6)箱型图 7)子图 1.Matplotlib 简介 Matplotlib 简介: Matplotlib 是一个python的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形,matplotlib 对于图像美化方面比较完善,可以自定义线条的颜色和样式,可以在一张绘图纸上绘制多张小图,也可以在一张图上绘制多条线,可以很方便地将数据可
-
Python 绘图和可视化详细介绍
Python之绘图和可视化 1. 启用matplotlib 最常用的Pylab模式的IPython(IPython --pylab) 2. matplotlib的图像都位于Figure对象中. 可以使用plt.figure创建一个新的Figure,不能通过空Figure绘图,必须用add_subplot创建一个或多个subplot axes[0,1]可以通过sharex和sharey指定subplot应该具有相同的X轴或Y轴. 利用Figure的subplots_adjust方法可以修改间距,w
-
Python数据可视化绘图实例详解
目录 利用可视化探索图表 1.数据可视化与探索图 2.常见的图表实例 数据探索实战分享 1.2013年美国社区调查 2.波士顿房屋数据集 利用可视化探索图表 1.数据可视化与探索图 数据可视化是指用图形或表格的方式来呈现数据.图表能够清楚地呈现数据性质, 以及数据间或属性间的关系,可以轻易地让人看图释义.用户通过探索图(Exploratory Graph)可以了解数据的特性.寻找数据的趋势.降低数据的理解门槛. 2.常见的图表实例 本章主要采用 Pandas 的方式来画图,而不是使用 Matpl
-
Python数据分析之绘图和可视化详解
一.前言 matplotlib是一个用于创建出版质量图表的桌面绘图包(主要是2D方面).该项目是由John Hunter于2002年启动的,其目的是为Python构建一个MATLAB式的绘图接口.matplotlib和IPython社区进行合作,简化了从IPython shell(包括现在的Jupyter notebook)进行交互式绘图.matplotlib支持各种操作系统上许多不同的GUI后端,而且还能将图片导出为各种常见的矢量(vector)和光栅(raster)图:PDF.SVG.JPG
-
python数据分析绘图可视化
前言: 数据分析初始阶段,通常都要进行可视化处理.数据可视化旨在直观展示信息的分析结果和构思,令某些抽象数据具象化,这些抽象数据包括数据测量单位的性质或数量.本章用的程序库matplotlib是建立在Numpy之上的一个Python图库,它提供了一个面向对象的API和一个过程式类的MATLAB API,他们可以并行使用. 1. import numpy as np import matplotlib.pyplot as plt scores=np.random.randint(0,100,50)
-
Python可视化绘制图表的教程详解
目录 1.Matplotlib 程序包 2.绘图命令的基本架构及其属性设置 3.Seaborn 模块介绍 3.1 未加Seaborn 模块的效果 4.描述性统计图形概览 4.1制作数据 4.2 频数分析 python 有许多可视化工具,但本书只介绍Matplotlib.Matplotlib是一种2D的绘图库,它可以支持硬拷贝和跨系统的交互,它可以在python脚本,IPython的交互环境下.Web应用程序中使用.该项目是由John Hunter 于2002年启动,其目的是为python构建MA
-
Python绘制散点图的教程详解
少废话,直接上代码 import matplotlib.pyplot as plt import numpy as np # 1. 首先是导入包,创建数据 n = 10 x = np.random.rand(n) * 2# 随机产生10个0~2之间的x坐标 y = np.random.rand(n) * 2# 随机产生10个0~2之间的y坐标 # 2.创建一张figure fig = plt.figure(1) # 3. 设置颜色 color 值[可选参数,即可填可不填],方式有几种 # col
-
Python+Seaborn绘制分布图的示例详解
目录 前言 示例 1 示例 2 示例 3 示例 4 示例 5 例子 6 例子 7 示例 8 示例 9 示例10 前言 在本文中,我们将介绍10个示例,以掌握如何使用用于Python的Seaborn库创建图表. 任何数据产品的第一步都应该是理解原始数据.对于成功和高效的产品,这一步骤占据了整个工作流程的很大一部分. 有几种方法用于理解和探索数据.其中之一是创建数据可视化.它们帮助我们探索和解释数据. 通过创建适当和设计良好的可视化,我们可以发现数据中的底层结构和关系. 分布区在数据分析中起着至关重
-
Python可视化模块altair的使用详解
目录 Altair是啥 Altair初体验 图表的保存 Altair之进阶操作 今天小编来和大家聊一下Python当中的altair可视化模块,并且通过调用该模块来绘制一些常见的图表,借助Altair,我们可以将更多的精力和时间放在理解数据本身以及数据的意义上面,从复杂的数据可视化过程中解脱出来. Altair是啥 Altair被称为是统计可视化库,因为它可以通过分类汇总.数据变换.数据交互.图形复合等方式全面地认识数据.理解和分析数据,并且其安装的过程也是十分的简单,直接通过pip命令来执行,
-
Python可视化Matplotlib散点图scatter()用法详解
散点图是数据分析中非常常用的图形.用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式. 特点:判断变量之间是否存在数量关联趋势,展示离群点(分布规律) Matplotlib 中绘制散点图的函数为 scatter() ,使用语法如下: matplotlib.pyplot.scatter(x, y, s=None, c=None, marker=None, cmap=None, norm=None, vmin=None, vmax=None, alpha
-
matplotlib在python上绘制3D散点图实例详解
大家可以先参考官方演示文档: 效果图: ''' ============== 3D scatterplot ============== Demonstration of a basic scatterplot in 3D. ''' from mpl_toolkits.mplot3d import Axes3D import matplotlib.pyplot as plt import numpy as np def randrange(n, vmin, vmax): ''' Helper f
-
Python音频操作工具PyAudio上手教程详解
0.引子 当需要使用Python处理音频数据时,使用python读取与播放声音必不可少,下面介绍一个好用的处理音频PyAudio工具包. PyAudio是Python开源工具包,由名思义,是提供对语音操作的工具包.提供录音播放处理等功能,可以视作语音领域的OpenCv. 1.简介 PyAudio为跨平台音频I / O库 PortAudio 提供 Python 绑定.使用PyAudio,您可以轻松地使用Python在各种平台上播放和录制音频,例如GNU / Linux,Microsoft Wi
-
Python后台开发Django的教程详解(启动)
Django版本为:2.1.7 Python的web框架,MTV思想 MVC Model(模板文件,数据库操作) view(视图模板文件 )controller(业务处理) MTV Model(模板文件,数据库操作) template(视图模板文件) view(业务处理) 安装及访问 安装 pip3 install django 创建目录 如win:在需要创建目录的文件夹按住shift+鼠标右键打开命令行,创建dongjg工程目录 C:\Users\东东\AppData\Local\Pro
-
Python PyInstaller安装和使用教程详解
Pyinstaller这个库是我用pip下载的第一个模块.接下来通过本文给大家分享Python PyInstaller安装和使用教程,一起看看吧. 安装 PyInstalle Python 默认并不包含 PyInstaller 模块,因此需要自行安装 PyInstaller 模块. 安装 PyInstaller 模块与安装其他 Python 模块一样,使用 pip 命令安装即可.在命令行输入如下命令: pip install pyinstaller 强烈建议使用 pip 在线安装的方式来安装 P
-
Python 安装 virturalenv 虚拟环境的教程详解
一.概述 有时候会在一台主机上安装多个不同的Python版本,用以运行不同时期开发的项目, 而在这些不同的Python版本上有时又会加装不同的库和包.因此需要一种工具来管理各个不同的Python版本和运行环境. virtualenv工具可以为每个Python项目创建一个"独立隔离"的虚拟Python运行环境,而且每个项目都可以为自己独立的Python 运行环境加装不同的扩展包和库,而不影响其他项目. 在使用virtualenv之前,首先需要保证你的操作系统上已经安装了所需的Python