Python+SimpleRNN实现股票预测详解
目录
- 1、数据源
- 2、代码实现
- 3、完整代码
原理请查看前面几篇文章。
1、数据源
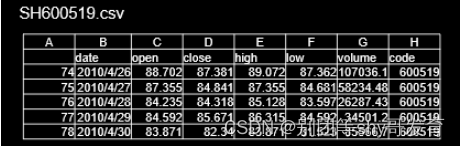
SH600519.csv 是用 tushare 模块下载的 SH600519 贵州茅台的日 k 线数据,本次例子中只用它的 C 列数据(如图 所示):
用连续 60 天的开盘价,预测第 61 天的开盘价。

2、代码实现
按照六步法: import 相关模块->读取贵州茅台日 k 线数据到变量 maotai,把变量 maotai 中前 2126 天数据中的开盘价作为训练数据,把变量 maotai 中后 300 天数据中的开盘价作为测试数据;然后对开盘价进行归一化,使送入神经网络的数据分布在 0 到 1 之间;
接下来建立空列表分别用于接收训练集输入特征、训练集标签、测试集输入特征、测试集标签;
继续构造数据。用 for 循环遍历整个训练数据,每连续60 天数据作为输入特征 x_train,第 61 天数据作为对应的标签 y_train ,一共生成 2066 组训练数据,然后打乱训练数据的顺序并转变为 array 格式继而转变为 RNN 输入要求的维度;
同理,利用 for 循环遍历整个测试数据,一共生成 240组测试数据,测试集不需要打乱顺序,但需转变为 array 格式继而转变为 RNN 输入要求的维度。

用 sequntial 搭建神经网络:
第一层循环计算层记忆体设定 80 个,每个时间步推送 h t h_t ht给下一层,使用 0.2 的 Dropout;
第二层循环计算层设定记忆体有 100 个,仅最后的时间步推送 h t h_t ht给下一层,使用 0.2 的 Dropout;
由于输出值是第 61 天的开盘价只有一个数,所以全连接 Dense 是 1->compile 配置训练方法使用 adam 优化器,使用均方误差损失函数。在股票预测代码中,只需观测 loss,训练迭代打印的时候也只打印 loss,所以这里就无需给metrics赋值->设置断点续训,fit 执行训练过程->summary 打印出网络结构和参数统计。

进行 loss 可视化与参数报错操作

进行股票预测。用 predict 预测测试集数据,然后将预测值和真实值从归一化的数值变换到真实数值,最后用红色线画出真实值曲线 、用蓝色线画出预测值曲线。
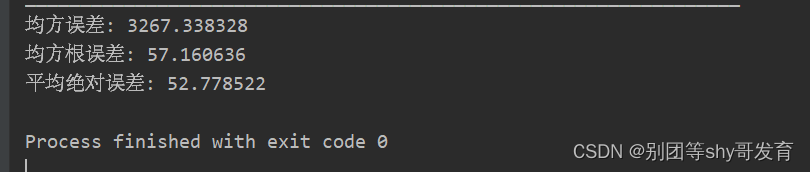
为了评价模型优劣,给出了三个评判指标:均方误差、均方根误差和平均绝对误差,这些误差越小说明预测的数值与真实值越接近。
RNN 股票预测 loss 曲线:

RNN 股票预测曲线:

RNN 股票预测评价指标:
模型摘要:

3、完整代码
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Dropout, Dense, SimpleRNN
import matplotlib.pyplot as plt
import os
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error
import math
# 读取股票文件
maotai = pd.read_csv('./SH600519.csv')
# 前(2426-300=2126)天的开盘价作为训练集,表格从0开始计数,2:3 是提取[2:3)列,前闭后开,故提取出C列开盘价
training_set = maotai.iloc[0:2426 - 300, 2:3].values
# 后300天的开盘价作为测试集
test_set = maotai.iloc[2426 - 300:, 2:3].values
# 归一化
sc = MinMaxScaler(feature_range=(0, 1)) # 定义归一化:归一化到(0,1)之间
training_set_scaled = sc.fit_transform(training_set) # 求得训练集的最大值,最小值这些训练集固有的属性,并在训练集上进行归一化
test_set = sc.transform(test_set) # 利用训练集的属性对测试集进行归一化
x_train = []
y_train = []
x_test = []
y_test = []
# 测试集:csv表格中前2426-300=2126天数据
# 利用for循环,遍历整个训练集,提取训练集中连续60天的开盘价作为输入特征x_train,第61天的数据作为标签,for循环共构建2426-300-60=2066组数据。
for i in range(60, len(training_set_scaled)):
x_train.append(training_set_scaled[i - 60:i, 0])
y_train.append(training_set_scaled[i, 0])
# 对训练集进行打乱
np.random.seed(7)
np.random.shuffle(x_train)
np.random.seed(7)
np.random.shuffle(y_train)
tf.random.set_seed(7)
# 将训练集由list格式变为array格式
x_train, y_train = np.array(x_train), np.array(y_train)
# 使x_train符合RNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]。
# 此处整个数据集送入,送入样本数为x_train.shape[0]即2066组数据;输入60个开盘价,预测出第61天的开盘价,循环核时间展开步数为60; 每个时间步送入的特征是某一天的开盘价,只有1个数据,故每个时间步输入特征个数为1
x_train = np.reshape(x_train, (x_train.shape[0], 60, 1))
# 测试集:csv表格中后300天数据
# 利用for循环,遍历整个测试集,提取测试集中连续60天的开盘价作为输入特征x_test,第61天的数据作为标签y_test,for循环共构建300-60=240组数据。
for i in range(60, len(test_set)):
x_test.append(test_set[i - 60:i, 0])
y_test.append(test_set[i, 0])
# 测试集变array并reshape为符合RNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]
x_test, y_test = np.array(x_test), np.array(y_test)
x_test = np.reshape(x_test, (x_test.shape[0], 60, 1))
model = tf.keras.Sequential([
SimpleRNN(80, return_sequences=True),# 第一层循环计算层:记忆体设定80个,每个时间步推送ht给下一层
Dropout(0.2), #使用0.2的Dropout
SimpleRNN(100),# 第二层循环计算层,设定记忆体100个
Dropout(0.2), #
Dense(1) # 由于输出值是第61天的开盘价,只有一个数,所以Dense是1
])
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss='mean_squared_error') # 损失函数用均方误差
# 该应用只观测loss数值,不观测准确率,所以删去metrics选项,一会在每个epoch迭代显示时只显示loss值
checkpoint_save_path = "./checkpoint/rnn_stock.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True,
monitor='val_loss')
history = model.fit(x_train, y_train, batch_size=64, epochs=50, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
file = open('./weights.txt', 'w') # 参数提取
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
################## predict ######################
# 测试集输入模型进行预测
predicted_stock_price = model.predict(x_test)
# 对预测数据还原---从(0,1)反归一化到原始范围
predicted_stock_price = sc.inverse_transform(predicted_stock_price)
# 对真实数据还原---从(0,1)反归一化到原始范围
real_stock_price = sc.inverse_transform(test_set[60:])
# 画出真实数据和预测数据的对比曲线
plt.plot(real_stock_price, color='red', label='MaoTai Stock Price')
plt.plot(predicted_stock_price, color='blue', label='Predicted MaoTai Stock Price')
plt.title('MaoTai Stock Price Prediction')
plt.xlabel('Time')
plt.ylabel('MaoTai Stock Price')
plt.legend()
plt.show()
##########evaluate##############
# calculate MSE 均方误差 ---> E[(预测值-真实值)^2] (预测值减真实值求平方后求均值)
mse = mean_squared_error(predicted_stock_price, real_stock_price)
# calculate RMSE 均方根误差--->sqrt[MSE] (对均方误差开方)
rmse = math.sqrt(mean_squared_error(predicted_stock_price, real_stock_price))
# calculate MAE 平均绝对误差----->E[|预测值-真实值|](预测值减真实值求绝对值后求均值)
mae = mean_absolute_error(predicted_stock_price, real_stock_price)
print('均方误差: %.6f' % mse)
print('均方根误差: %.6f' % rmse)
print('平均绝对误差: %.6f' % mae)
以上就是Python+SimpleRNN实现股票预测详解的详细内容,更多关于Python SimpleRNN股票预测的资料请关注我们其它相关文章!
相关推荐
-

python实现股票历史数据可视化分析案例
投资有风险,选择需谨慎. 股票交易数据分析可直观股市走向,对于如何把握股票行情,快速解读股票交易数据有不可替代的作用! 1 数据预处理 1.1 股票历史数据csv文件读取 import pandas as pd import csv df = pd.read_csv("/home/kesci/input/maotai4154/maotai.csv") 1.2 关键数据--在csv文件中选择性提取"列" df_high_low = df[['date','high',
-
python基于机器学习预测股票交易信号
引言 近年来,随着技术的发展,机器学习和深度学习在金融资产量化研究上的应用越来越广泛和深入.目前,大量数据科学家在Kaggle网站上发布了使用机器学习/深度学习模型对股票.期货.比特币等金融资产做预测和分析的文章.从金融投资的角度看,这些文章可能缺乏一定的理论基础支撑(或交易思维),大都是基于数据挖掘.但从量化的角度看,有很多值得我们学习参考的地方,尤其是Pyhton的深入应用.数据可视化和机器学习模型的评估与优化等.下面借鉴Kaggle上的一篇文章<Building an Asset Trad
-
python用线性回归预测股票价格的实现代码
线性回归在整个财务中广泛应用于众多应用程序中.在之前的教程中,我们使用普通最小二乘法(OLS)计算了公司的beta与相对索引的比较.现在,我们将使用线性回归来估计股票价格. 线性回归是一种用于模拟因变量(y)和自变量(x)之间关系的方法.通过简单的线性回归,只有一个自变量x.可能有许多独立变量属于多元线性回归的范畴.在这种情况下,我们只有一个自变量即日期.对于第一个日期上升到日期向量长度的整数,该日期将由1开始的整数表示,该日期可以根据时间序列数据而变化.当然,我们的因变量将是股票的价格.为了理
-
python量化之搭建Transformer模型用于股票价格预测
目录 前言 1.Transformer模型 2.环境准备 3.代码实现 3.1. 导入库以及定义超参 3.2. 模型构建 3.3. 数据预处理 3.4. 模型训练以及评估 3.5. 模型运行 4.总结 前言 下面的这篇文章主要教大家如何搭建一个基于Transformer的简单预测模型,并将其用于股票价格预测当中.原代码在文末进行获取. 1.Transformer模型 Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于
-
Python爬取股票交易数据并可视化展示
目录 开发环境 第三方模块 爬虫案例的步骤 爬虫程序全部代码 分析网页 导入模块 请求数据 解析数据 翻页 保存数据 实现效果 数据可视化全部代码 导入数据 读取数据 可视化图表 效果展示 开发环境 解释器版本: python 3.8 代码编辑器: pycharm 2021.2 第三方模块 requests: pip install requests csv 爬虫案例的步骤 1.确定url地址(链接地址) 2.发送网络请求 3.数据解析(筛选数据) 4.数据的保存(数据库(mysql\mong
-
Python+SimpleRNN实现股票预测详解
目录 1.数据源 2.代码实现 3.完整代码 原理请查看前面几篇文章. 1.数据源 SH600519.csv 是用 tushare 模块下载的 SH600519 贵州茅台的日 k 线数据,本次例子中只用它的 C 列数据(如图 所示): 用连续 60 天的开盘价,预测第 61 天的开盘价. 2.代码实现 按照六步法: import 相关模块->读取贵州茅台日 k 线数据到变量 maotai,把变量 maotai 中前 2126 天数据中的开盘价作为训练数据,把变量 maotai 中后 300 天数
-
Python使用LSTM实现销售额预测详解
大家经常会遇到一些需要预测的场景,比如预测品牌销售额,预测产品销量. 今天给大家分享一波使用 LSTM 进行端到端时间序列预测的完整代码和详细解释. 我们先来了解两个主题: 什么是时间序列分析? 什么是 LSTM? 时间序列分析:时间序列表示基于时间顺序的一系列数据.它可以是秒.分钟.小时.天.周.月.年.未来的数据将取决于它以前的值. 在现实世界的案例中,我们主要有两种类型的时间序列分析: 单变量时间序列 多元时间序列 对于单变量时间序列数据,我们将使用单列进行预测. 正如我们所见,只有一列,
-
利用Python计算KS的实例详解
在金融领域中,我们的y值和预测得到的违约概率刚好是两个分布未知的两个分布.好的信用风控模型一般从准确性.稳定性和可解释性来评估模型. 一般来说.好人样本的分布同坏人样本的分布应该是有很大不同的,KS正好是有效性指标中的区分能力指标:KS用于模型风险区分能力进行评估,KS指标衡量的是好坏样本累计分布之间的差值. 好坏样本累计差异越大,KS指标越大,那么模型的风险区分能力越强. 1.crosstab实现,计算ks的核心就是好坏人的累积概率分布,我们采用pandas.crosstab函数来计算累积概率
-
Python 线性回归分析以及评价指标详解
废话不多说,直接上代码吧! """ # 利用 diabetes数据集来学习线性回归 # diabetes 是一个关于糖尿病的数据集, 该数据集包括442个病人的生理数据及一年以后的病情发展情况. # 数据集中的特征值总共10项, 如下: # 年龄 # 性别 #体质指数 #血压 #s1,s2,s3,s4,s4,s6 (六种血清的化验数据) #但请注意,以上的数据是经过特殊处理, 10个数据中的每个都做了均值中心化处理,然后又用标准差乘以个体数量调整了数值范围. #验证就会发现任
-
Python深度学习线性代数示例详解
目录 标量 向量 长度.维度和形状 矩阵 张量 张量算法的基本性质 降维 点积 矩阵-矩阵乘法 范数 标量 标量由普通小写字母表示(例如,x.y和z).我们用 R \mathbb{R} R表示所有(连续)实数标量的空间. 标量由只有一个元素的张量表示.下面代码,我们实例化了两个标量,并使用它们执行一些熟悉的算数运算,即加法.乘法.除法和指数. import torch x = torch.tensor([3.0]) y = torch.tensor([2.0]) x + y, x * y, x
-
python神经网络Xception模型复现详解
目录 什么是Xception模型 Xception网络部分实现代码 图片预测 Xception是继Inception后提出的对Inception v3的另一种改进,学一学总是好的 什么是Xception模型 Xception是谷歌公司继Inception后,提出的InceptionV3的一种改进模型,其改进的主要内容为采用depthwise separable convolution来替换原来Inception v3中的多尺寸卷积核特征响应操作. 在讲Xception模型之前,首先要讲一下什么是
-
python神经网络InceptionV3模型复现详解
目录 神经网络学习小记录21——InceptionV3模型的复现详解 学习前言什么是InceptionV3模型InceptionV3网络部分实现代码图片预测 学习前言 Inception系列的结构和其它的前向神经网络的结构不太一样,每一层的内容不是直直向下的,而是分了很多的块. 什么是InceptionV3模型 InceptionV3模型是谷歌Inception系列里面的第三代模型,其模型结构与InceptionV2模型放在了同一篇论文里,其实二者模型结构差距不大,相比于其它神经网络模型,Inc
-
python神经网络ShuffleNetV2模型复现详解
目录 什么是ShuffleNetV2 ShuffleNetV2 1.所用模块 2.网络整体结构 网络实现代码 什么是ShuffleNetV2 据说ShuffleNetV2比Mobilenet还要厉害,我决定好好学一下 这篇是ECCV2018关于轻量级模型的文章. 目前大部分的轻量级模型在对比模型速度时用的指标是FLOPs,这个指标主要衡量的就是卷积层的乘法操作. 但是实际运用中会发现,同一个FLOPS的网络运算速度却不同,只用FLOPS去进行衡量的话并不能完全代表模型速度. 通过如下图所示对比,
-
Python实现聚类K-means算法详解
目录 手动实现 sklearn库中的KMeans K-means(K均值)算法是最简单的一种聚类算法,它期望最小化平方误差 注:为避免运行时间过长,通常设置一个最大运行轮数或最小调整幅度阈值,若到达最大轮数或调整幅度小于阈值,则停止运行. 下面我们用python来实现一下K-means算法:我们先尝试手动实现这个算法,再用sklearn库中的KMeans类来实现.数据我们采用<机器学习>的西瓜数据(P202表9.1): # 下面的内容保存在 melons.txt 中 # 第一列为西瓜的密度:第
-
Python sklearn分类决策树方法详解
目录 决策树模型 决策树学习 使用Scikit-learn进行决策树分类 决策树模型 决策树(decision tree)是一种基本的分类与回归方法. 分类决策树模型是一种描述对实例进行分类的树形结构.决策树由结点(node)和有向边(directed edge)组成.结点有两种类型:内部结点(internal node)和叶结点(leaf node).内部结点表示一个特征或属性,叶结点表示一个类. 用决策树分类,从根结点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子