SpringCloud整合分布式服务跟踪zipkin的实现
1、zipkin
zipkin是Twitter的一个开源项目,它基于Google Dapper实现。我们可以使用它来收集各个服务器上请求链路的跟踪数据,并通过它提供的REST API接口来辅助我们查询跟踪数据以实现对分布式系统的监控程序,从而及时地发现系统中出现的延迟升高问题并找出系统性能瓶颈的根源。除了面向开发的API接口之外,它也提供了方便的UI组件来帮助我们直观的搜索跟踪信息和分析请求链路明细,比如:可以查询某段时间内各用户请求的处理时间等。
zipkin的架构图如下:
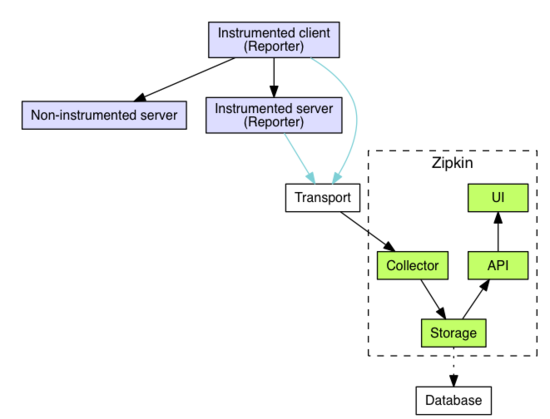
由上面的架构图可以看出,zipkin有四个核心组件:
- Collector:收集器组件,它主要用于处理从外部系统发送过来的跟踪信息,将这些信息转换为zipkin内部处理的Span格式,以支持后续的存储、分析、展示等功能。
- Storage:存储组件,它主要对处理收集器接收到的跟踪信息,默认会将这些信息存储在内存中,我们也可以修改此存储策略,通过使用其他存储组件将跟踪信息存储到数据库中,目前支持的数据库有Mysql、Cassandra和Elasticsearch。
- API:API组件,提供给UI组件,展示跟踪信息。
- UI:UI组件,基于API组件实现的上层应用。通过UI组件用户可以方便而有直观地查询和分析跟踪信息。
2、构建zipkin-server
目前最新版的zipkin-server,是直接到官网获取最新可执行的jar,然后直接运行该jar文件,例如:
curl -sSL https://zipkin.io/quickstart.sh | bash -s java -jar zipkin.jar
也可以用docker启动,在此通过docker来启动zipkin-server服务。
由于在此存储组件使用Elasticsearch,所以先通过docker将Elasticsearch启动,执行如下命令:
docker run -d -p 9200:9200 --name es elasticsearch:6.6.0
如果在启动elasticsearch的时候出现如下错误:
[1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
可以先执行如下命令解决:
sysctl -w vm.max_map_count=262144
接下来,启动zipkin-server服务,执行如下命令:
docker run -d -e STORAGE_TYPE=elasticsearch -e ES_HOSTS=192.168.208.134:9200 -p 9411:9411 --name zipkin openzipkin/zipkin:2.12.1
通过浏览器打开http://192.168.208.134:9411页面,如果出现如下界面,则表示zipkin-server服务启动成功了:
3、微服务集成zipkin
在原来微服务的pom文件中,添加如下的依赖:
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency>
然后在application.yml文件需要新增如下配置:
spring: zipkin: base-url: http://192.168.208.134:9411 sleuth: sampler: percentage: 1
其中spring.sleuth.sampler.percentage表示收集跟踪信息的比例,1表示全部收集,它的值的范围是0-1之间的。
4、部署zipkin-dependencies
由于新版本当中,如果需要查看各个微服务之间的依赖关系,则必需要部署zipkin-dependencies,此处还是通过docker来部署,由于zipkin-dependencies运行一次就会结束,所以可以让其每小时运行一次,即:
docker run -e STORAGE_TYPE=elasticsearch -e ES_HOSTS=192.168.208.134:9200 openzipkin/zipkin-dependencies:2.0.4 sh -c 'crond -f'
5、参考资料
https://github.com/openzipkin/docker-zipkin
https://github.com/openzipkin/docker-zipkin-dependencies
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
详解spring cloud分布式整合zipkin的链路跟踪
为什么使用zipkin? 上篇主要写了:spring cloud分布式日志链路跟踪 从上篇中可以看出服务之间的调用,假设现在有十几台服务,那么在查找日志的时候比较繁琐.复杂,而且在查看调用的时候也会像蜘蛛网一样,量太大. 这时候zipkin可以把链路调用整个过程给升级起来,只需要到一个地方去查找,就可以知道哪一步出错. zipkin也分为服务器和客户端,服务器就是zipkin,微服务就是客户端. 首先,建立服务器zipkin 在此服务build.gradle加上zipkin的依赖: compil
-
SpringCloud整合分布式服务跟踪zipkin的实现
1.zipkin zipkin是Twitter的一个开源项目,它基于Google Dapper实现.我们可以使用它来收集各个服务器上请求链路的跟踪数据,并通过它提供的REST API接口来辅助我们查询跟踪数据以实现对分布式系统的监控程序,从而及时地发现系统中出现的延迟升高问题并找出系统性能瓶颈的根源.除了面向开发的API接口之外,它也提供了方便的UI组件来帮助我们直观的搜索跟踪信息和分析请求链路明细,比如:可以查询某段时间内各用户请求的处理时间等. zipkin的架构图如下: 由上面的架构图可以
-

Spring Cloud 专题之Sleuth 服务跟踪实现方法
目录 准备工作 实现跟踪 抽样收集 整合Zipkin 1.下载Zipkin 2.引入依赖配置 3.测试与分析 持久化到mysql 1.创建zipkin数据库 2.启动zipkin 3.测试与分析 在一个微服务架构中,系统的规模往往会比较大,各微服务之间的调用关系也错综复杂.通常一个有客户端发起的请求在后端系统中会经过多个不同的微服务调用阿里协同产生最后的请求结果.在复杂的微服务架构中,几乎每一个前端请求都会形成一条复杂的分布式的服务调用链路,在每条链路中任何一个依赖服务出现延迟过高或错误的时候都
-
springboot cloud使用eureka整合分布式事务组件Seata 的方法
前言 近期一直在忙项目,我也是打工仔.不多说,我们开始玩一玩seata. 正文 什么都不说,我们按照惯例,先上一个图(图里不规范的使用请忽略): 简单一眼就看出来, 比我们平时用的东西,多了 Seata Server 微服务 . 同样这个 Seata Server 微服务 ,也是需要注册到eureka上面去的. 那么我们首先就搞一搞这个 seata server ,那么剩下的就是一些原本的业务服务整合配置了. 该篇用的 seata server 版本,用的是1.4.1 , 可以去git下载下.当
-
SpringCloud分布式链路跟踪的方法
注:作者使用IDEA + Gradle 注:需要有一定的java SpringBoot and SSM+Springcloud基础 程序测试错误追责 我举个例子,我现在要做一个电商项目,项目里面有一个购买模块,那我这边可能要执行一个代码,比如减库存之类的东西,那我两个服务不就是要相互调用嘛,我自身是一个服务,我现在要调用减库存这个服务: 你调用它,你知道它一定能执行成功吗?肯定是不一定: 比如说,我现在要执行一个减库存的代码,我调用这个方法会进行库存的一个更改,这个库存减少成功还好,万一要是失败
-
Java 实现分布式服务的调用链跟踪
目录 为什么要实现调用链跟踪? 如何实现? 第一步,看图.看场景,用户浏览器的一次请求行为所走的路径是什么样的 第二步,实现.不想看代码可直接拉最后看结果和原理 测试一下结果: 为什么要实现调用链跟踪? 随着业务的发展,所有的系统最终都会走向服务化体系,微服务的目的一是提高系统的稳定性,二是提高持续交付的效率,为什么能提高这两项不是今天讨论的内容. 当然这也不是绝对的,如果业务还在MVP验证,团队规模小个人觉得完全没必要微服务化.单体应用是比较好的选择.作者是有经历过从单体应用到1000+应用的
-
浅析springcloud 整合 zipkin-server 内存日志监控
Zipkin Zipkin是一款开源的分布式实时数据追踪系统(Distributed Tracking System),基于 Google Dapper的论文设计而来,由 Twitter 公司开发贡献.其主要功能是聚集来自各个异构系统的实时监控数据. Zipkin主要包括四个模块 - Collector 接收或收集各应用传输的数据 - Storage 存储接受或收集过来的数据,当前支持Memory,MySQL,Cassandra,ElasticSea
-
seata springcloud整合教程与遇到的坑
SEATA概要 seata 是alibaba 出的一款分布式事务管理器,他有侵入性小,实现简单等特点.我们能够使用seata 实现分布式事务管理, 是微服务必备的组件.他可以实现在微服务之间的事务管理,也可以实现多个数据源的事务管理. seata 在阿里内部,和众多的公司都有应用,因此我们可以放心的使用它. 依赖 <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-clou
-
springcloud整合seata的实现代码
目录 一.背景 二.项目结构 三.实现功能: 四.项目使用到的技术 五.整合步骤 1.引入spring-cloud-starter-alibaba-seata jar包 2.涉及到的业务库操作 1.业务库需要存在 undo_log 表 2.业务表主键 3.页面中自动更新时间戳 3.开启数据源代理 1.自动配置数据源代理 2.手动配置AT模式数据源代理 4.传递 xid 5.事务分组和seata server对应上 6.注册中心和配置中心 7.业务方法加上@GlobalTransactional
-
SpringCloud 分布式微服务架构操作步骤
目录 前言 SpringCloud微服务 单体架构和微服务分布式架构 单体架构分析 微服务分布式架构分析 服务拆分和远程调用 服务拆分 案例需求准备 远程调用初步 Eureka注册中心 服务注册与负载均衡 服务注册 Ribbon负载均衡 指定负载均衡规则 Nocas 注册中心 环境配置启动服务注册 Nacos 分级存储模型与集群 负载均衡 namespace 环境隔离 统一配置管理与热更新 前言 这篇笔记文章我还是没有接上之前的java,因为我中间偷懒了,写不动了.打算先把这篇安排下,然后再把之
-
详解springcloud组件consul服务治理
Consul是一款由HashiCorp公司开源的,用于服务治理的软件,Spring Cloud Consul对其进行了封装.Consul具有如下特点: 服务注册 - 自动注册和取消注册服务实例的网络位置 运行状况检查 - 检测服务实例何时启动并运行 分布式配置 - 确保所有服务实例使用相同的配置 Consul agent有两种运行模式:Server和Client.这里的Server和Client只是Consul集群层面的区分,与搭建在Cluster之上 的应用服务无关. 以Server模式运行的