elasticsearch python 查询的两种方法
elasticsearch python 查询的两种方法,具体内容如下所述:
from elasticsearch import Elasticsearch
es = Elasticsearch
res1 = es.search(index="2018-07-31", body={"query": {"match_all": {}}})
print(es1)
{'_shards': {'failed': 0, 'skipped': 0, 'successful': 5, 'total': 5},
'hits': {'hits': [{'_id': '1',
'_index': '2018-07-31',
'v_ma20': 891995.98,
'volume': 720150.81},
'_type': 'stock'}],
'max_score': 1.0,
'total': 1},
'timed_out': False,
'took': 1163}
result = es.get(index="2018-07-31",doc_type="stock",id=1)
知识点扩展:
基于python的Elasticsearch索引的建立和数据的上传
今天我想讲一讲关于Elasticsearch的索引建立,当然提前是你已经安装部署好Elasticsearch。
ok,先来介绍一下Elaticsearch,它是一款基于lucene的实时分布式搜索和分析引擎,是后台系统,用来存储数据,检索数据,属于完全命令行交互。
那为什么选择python作为脚本进行命令的写入和数据的上传呢?那是因为Python里面有固定的模板,可以上传数据到Elasticsearch。
接下来就聊一聊该如何编写代码:
我们上传数据之后,数据到哪里去了呢?
存在索引里面了。
那么,何为索引??可以理解为是一个文件用来存放数据的,可以算是单个数据库的同义词。
所以上传数据前的第一步就是建立索引了,以下为Python代码
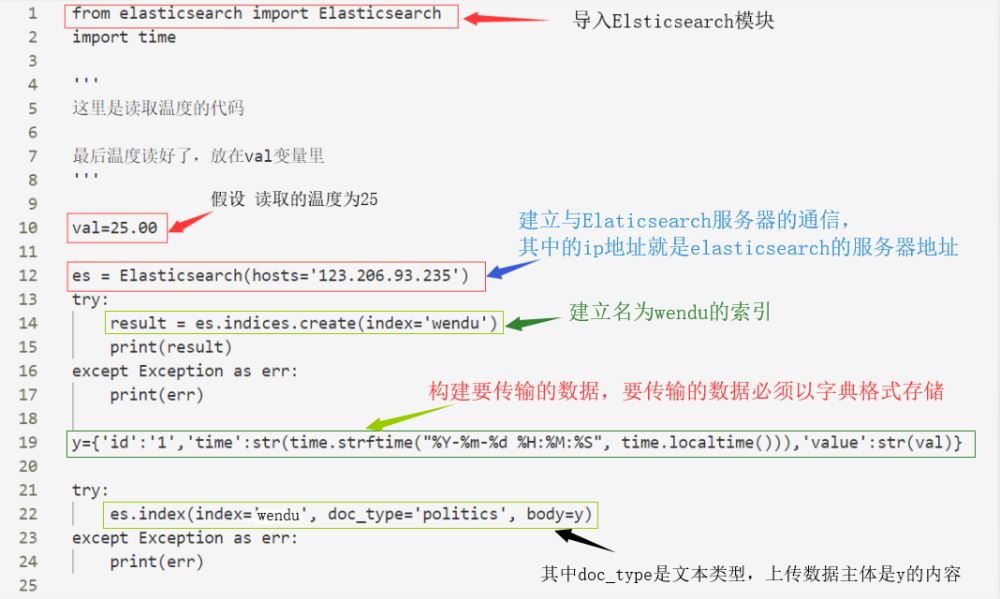
我是连接了一个温度传感器然后读取得到一个数据,按照本例来说就是默认25,传入一条数据至elasticsearch服务器。
如果索引建立成功他将会显示如下界面:

至此,基于python的Elaticsearch索引的建立和数据的上传就已经讲完啦,关于如何查看elasticsearch上传的数据将在下一篇文章中讲到,记得关注喔(#^.^#)
总结
以上所述是小编给大家介绍的elasticsearch python 查询的两种方法,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的!
相关推荐
-
python elasticsearch从创建索引到写入数据的全过程
python elasticsearch从创建索引到写入数据 创建索引 from elasticsearch import Elasticsearch es = Elasticsearch('192.168.1.1:9200') mappings = { "mappings": { "type_doc_test": { #type_doc_test为doc_type "properties": { "id": { "
-
python elasticsearch环境搭建详解
windows下载zip linux下载tar 下载地址:https://www.elastic.co/downloads/elasticsearch 解压后运行:bin/elasticsearch (or bin\elasticsearch.bat on Windows) 检查是否成功:访问 http://localhost:9200 linux下不能以root用户运行, 普通用户运行报错: java.nio.file.AccessDeniedException 原因:当前用户没有执行权限 解
-
Python对ElasticSearch获取数据及操作
使用Python对ElasticSearch获取数据及操作,供大家参考,具体内容如下 Version Python :2.7 ElasticSearch:6.3 代码: #!/usr/bin/env python # -*- coding: utf-8 -*- """ @Time : 2018/7/4 @Author : LiuXueWen @Site : @File : ElasticSearchOperation.py @Software: PyCharm @Descri
-
Python 操作 ElasticSearch的完整代码
官方文档:https://elasticsearch-py.readthedocs.io/en/master/ 1.介绍 python提供了操作ElasticSearch 接口,因此要用python来操作ElasticSearch,首先要安装python的ElasticSearch包,用命令pip install elasticsearch安装或下载安装:https://pypi.python.org/pypi/elasticsearch/5.4.0 2.创建索引 假如创建索引名称为ott,类型
-
python Elasticsearch索引建立和数据的上传详解
今天我想讲一讲关于Elasticsearch的索引建立,当然提前是你已经安装部署好Elasticsearch. ok,先来介绍一下Elaticsearch,它是一款基于lucene的实时分布式搜索和分析引擎,是后台系统,用来存储数据,检索数据,属于完全命令行交互. 那为什么选择python作为脚本进行命令的写入和数据的上传呢?那是因为Python里面有固定的模板,可以上传数据到Elasticsearch. 接下来就聊一聊该如何编写代码: 我们上传数据之后,数据到哪里去了呢? 存在索引里面了. 那
-
elasticsearch python 查询的两种方法
elasticsearch python 查询的两种方法,具体内容如下所述: from elasticsearch import Elasticsearch es = Elasticsearch res1 = es.search(index="2018-07-31", body={"query": {"match_all": {}}}) print(es1) {'_shards': {'failed': 0, 'skipped': 0, 'suc
-
Spring Data JPA实现动态查询的两种方法
前言 一般在写业务接口的过程中,很有可能需要实现可以动态组合各种查询条件的接口.如果我们根据一种查询条件组合一个方法的做法来写,那么将会有大量方法存在,繁琐,维护起来相当困难.想要实现动态查询,其实就是要实现拼接SQL语句.无论实现如何复杂,基本都是包括select的字段,from或者join的表,where或者having的条件.在Spring Data JPA有两种方法可以实现查询条件的动态查询,两种方法都用到了Criteria API. Criteria API 这套API可用于构建对数据
-
MySql逗号拼接字符串查询的两种方法
下面两个函数的使用和FIND_IN_SET一样,使用时只需要把FIND_IN_SET换成FIND_PART_IN_SET或FIND_ALL_PART_IN_SET 例如某字段里是为1,2,3,4,5 使用方法: 第一种,传入1,3,6 可以查出来 select * from XXX where FIND_PART_IN_SET('1,3,6','1,2,3,4,5') 第二种,传入1,3,6 查不出来 select * from XXX where FIND_ALL_PART_IN_SET(
-
jpa实现多对多的属性时查询的两种方法
目录 jpa多对多的属性查询 第一:采用JPQL方式 第二:采用specification 方法 JPA,HQL多对多的查询语句 Hql语句 另外一种写法 jpa多对多的属性查询 第一:采用JPQL方式 使用@Query拼接jpql语句完成多对多的查询; @query( SELECT User FROM User u JOIN Student s on s.id = u.id where u.name LIKE :name ) User findallByName(@param("name&qu
-

更改Ubuntu默认python版本的两种方法python-> Anaconda
你可以按照以下方法使用 ls 命令来查看你的系统中都有那些 Python 的二进制文件可供使用. $ ls /usr/bin/python* /usr/bin/python /usr/bin/python2 /usr/bin/python2.7 /usr/bin/python3 /usr/bin/python3.4 /usr/bin/python3.4m /usr/bin/python3m 执行如下命令查看默认的 Python 版本信息: $ python --version Python 2.
-
Python更新数据库脚本两种方法及对比介绍
最近项目的两次版本迭代中,根据业务需求的变化,需要对数据库进行更新,两次分别使用了不同的方式进行更新. 第一种:使用python的MySQLdb模块利用原生的sql语句进行更新 import MySQLdb #主机名 HOST = '127.0.0.1' #用户名 USER = "root" #密码 PASSWD = "123456" #数据库名 DB = "db_name" # 打开数据库连接 db=MySQLdb.connect(HOST,U
-
python爬虫 使用真实浏览器打开网页的两种方法总结
1.使用系统自带库 os 这种方法的优点是,任何浏览器都能够使用, 缺点不能自如的打开一个又一个的网页 import os os.system('"C:/Program Files/Internet Explorer/iexplore.exe" http://www.baidu.com') 2.使用python 集成的库 webbroswer python的webbrowser模块支持对浏览器进行一些操作,主要有以下三个方法: import webbrowser webbrowser.
-
python学习之第三方包安装方法(两种方法)
这篇文章主要介绍了python学习之第三方包安装方法,最近在学习QQ空间.微博(爬虫)模拟登录,都涉及到了RSA算法.这样需要下一个RSA包(第三方包),在网上搜了好多资料,具体有以下两种方法: 第一种方法(不使用pip或者easy_install): Step1:在网上找到的需要的包,下载下来.eg. rsa-3.1.4.tar.gz Step2:解压缩该文件. Step3:命令行工具cd切换到所要安装的包的目录,找到setup.py文件,然后输入python setup.py install
-
Python在图片中添加文字的两种方法
本文主要介绍的是利用Python在图片中添加文字的两种方法,下面分享处理供大家参考学习,下来要看看吧 一.使用OpenCV 在图片中添加文字看上去很简单,但是如果是利用OpenCV来做却很麻烦.OpenCV中并没有使用自定义字体文件的函数,这不仅意味着我们不能使用自己的字体,而且意味着他无法显示中文字符.这还是非常要命的事情.而且他显示出来的文字位置也不太好控制.比如下面的代码,他想做的仅仅是显示数字3: 代码: #coding=utf-8 import cv2 import numpy as
-
总结python实现父类调用两种方法的不同
python中有两种方法可以调用父类的方法: super(Child, self).method(args) Parent.method(self, args) 我用其中的一种报了如下错误: 找不到 classobj.当我把调用改为 super(B, self).f(name) 就能正确运行,且结果正确. 分析错误 因为基类没有继承 object , 在python中,一个可以这样创建: class A: pass 也可以这样创建: class A(object): pass 这两者的区别就是: