python爬虫_实现校园网自动重连脚本的教程
一、背景
最近学校校园网不知道是什么情况,总出现掉线的情况。每次掉线都需要我手动打开web浏览器重新进行账号密码输入,重新进行登录。系统的问题我没办法解决,但是可以写一个简单的python脚本用于自动登录校园网。每次掉线后,再打开任意网页就是这个页面。

二、实现代码
#-*- coding:utf-8 -*-
__author__ = 'pf'
import time
import requests
class Login:
#初始化
def __init__(self):
#检测间隔时间,单位为秒
self.every = 10
#模拟登录
def login(self):
print self.getCurrentTime(), u"拼命连网中..."
url="http://222.24.19.190:8080/portal/pws?t=li"
#消息头
headers={
'Host':"222.24.19.190:8080",
'User-Agent':"Mozilla/5.0 (Windows NT 6.3; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0",
'Accept':"application/json, text/javascript, */*; q=0.01",
'Accept-Language':"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
'Accept-Encoding':"gzip, deflate",
'Referer':"http://222.24.19.190:8080/portal/index_default.jsp",
'Content-Type':"application/x-www-form-urlencoded",
'X-Requested-With':"XMLHttpRequest",
'Content-Length':"291",
'Connection':"close"
}
#提交的信息
payload={
'userName':'1403810041',
'userPwd':'MTk4NDEy',
'userurl':'http%3A%2F%2Fwww.msn.com%3Focid%3Dwispr&userip=222.24.52.200',
'portalProxyIP':'222.24.19.190',
'portalProxyPort':'50200',
'dcPwdNeedEncrypt':'1',
'assignIpType':'0',
'appRootUrl':'=http%3A%2F%2F222.24.19.190%3A8080%2Fportal%2F',
'manualUrlEncryptKey':'rTCZGLy2wJkfobFEj0JF8A%3D%3D'
}
try:
r=requests.post(url,headers=headers,data=payload)
print self.getCurrentTime(),u'连上了...现在开始看连接是否正常'
except:
print("error")
#判断当前是否可以连网
def canConnect(self):
try:
q=requests.get("http://www.baidu.com")
if(q.status_code==200):
return True
else:
return False
except:
print 'error'
#获取当前时间
def getCurrentTime(self):
return time.strftime('[%Y-%m-%d %H:%M:%S]',time.localtime(time.time()))
#主函数
def main(self):
print self.getCurrentTime(), u"Hi,欢迎使用自动登陆系统"
while True:
self.login()
while True:
can_connect = self.canConnect()
if not can_connect:
print self.getCurrentTime(),u"断网了..."
self.login()
else:
print self.getCurrentTime(), u"一切正常..."
time.sleep(self.every)
time.sleep(self.every)
login = Login()
login.main()
三、解决步骤
首先需要一个用于抓包的工具。我们要抓取提交的数据以及提交到的url地址。我这里用的是firefox浏览器的httpfox插件。
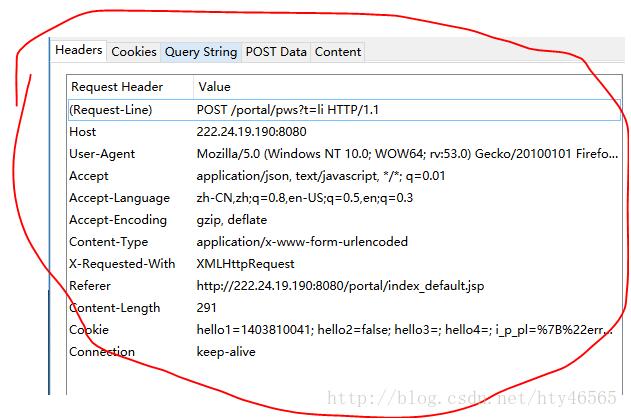
用firefox浏览器打开登录页面,并且打开httpfox插件。在页面中输入账户名和密码点击上线后,注意一下httpfox中有一行记录的Method是POST。我们需要记录的就是其中的POST Data中的userName和userPwd。以及Headers中的数据。还有POST到的URL地址。
如图:

我这里使用了python中的requests库。
将获取到的URL地址、userName、userPwd、Headers填入代码中对应的位置。

可以直接运行python程序,如图:

或者可以用pyinstaller库生成exe文件再运行,如图:


四、总结
我这里设置了一个死循环,让程序每隔10s检测一下是否能连上网,若可以连上则输出“一切正常”然后接着循环,若不能连上,则输出“断网了”然后重新连网。我们可以对程序设置开机自启动。这样,开机也就不需要再手动去连网了。
以上这篇python爬虫_实现校园网自动重连脚本的教程就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
您可能感兴趣的文章:
- python实现校园网自动登录的示例讲解
- python爬虫实战之最简单的网页爬虫教程
- python实现简单爬虫功能的示例
- 零基础写python爬虫之爬虫编写全记录
相关推荐
-
python实现校园网自动登录的示例讲解
因为最近想用树莓派搞个远程监控系统,又因为学校的网需要从网页登录而树莓派又不方便搞个显示器带着,所以寻思着搞个能够自动登录校园网的脚本程序,省去了每次都要打开浏览器输入账号密码的烦恼. 1.工具 火狐浏览器+firedebug插件,debug插件可才浏览器中附加组件中添加,其他浏览器也可以只要可以监控浏览器的网络行为即可. python+requests包 2.步骤 1) 先打开到登录界面,然后在按f12打开firedebug插件,此时debug无任何记录行为,然后点击刷新按钮,再点击登录按钮
-

python爬虫实战之最简单的网页爬虫教程
前言 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.最近对python爬虫有了强烈地兴趣,在此分享自己的学习路径,欢迎大家提出建议.我们相互交流,共同进步.话不多说了,来一起看看详细的介绍: 1.开发工具 笔者使用的工具是sublime text3,它的短小精悍(可能男人们都不喜欢这个词)使我十分着迷.推荐大家使用,当然如果你的电脑配置不错,pycharm可能更加适合你. sublime text3
-
python实现简单爬虫功能的示例
在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材. 我们最常规的做法就是通过鼠标右键,选择另存为.但有些图片鼠标右键的时候并没有另存为选项,还有办法就通过就是通过截图工具截取下来,但这样就降低图片的清晰度.好吧-!其实你很厉害的,右键查看页面源代码. 我们可以通过python 来实现这样一个简单的爬虫功能,把我们想要的代码爬取到本地.下面就看看如何使用python来实现这样一个功能. 一,获取整个页面数据 首先我们
-
零基础写python爬虫之爬虫编写全记录
先来说一下我们学校的网站: http://jwxt.sdu.edu.cn:7777/zhxt_bks/zhxt_bks.html 查询成绩需要登录,然后显示各学科成绩,但是只显示成绩而没有绩点,也就是加权平均分. 显然这样手动计算绩点是一件非常麻烦的事情.所以我们可以用python做一个爬虫来解决这个问题. 1.决战前夜 先来准备一下工具:HttpFox插件. 这是一款http协议分析插件,分析页面请求和响应的时间.内容.以及浏览器用到的COOKIE等. 以我为例,安装在火狐上即可,效果如图:
-
python爬虫_实现校园网自动重连脚本的教程
一.背景 最近学校校园网不知道是什么情况,总出现掉线的情况.每次掉线都需要我手动打开web浏览器重新进行账号密码输入,重新进行登录.系统的问题我没办法解决,但是可以写一个简单的python脚本用于自动登录校园网.每次掉线后,再打开任意网页就是这个页面. 二.实现代码 #-*- coding:utf-8 -*- __author__ = 'pf' import time import requests class Login: #初始化 def __init__(self): #检测间隔时间,单位
-
python爬虫_自动获取seebug的poc实例
简单的写了一个爬取www.seebug.org上poc的小玩意儿~ 首先我们进行一定的抓包分析 我们遇到的第一个问题就是seebug需要登录才能进行下载,这个很好处理,只需要抓取返回值200的页面,将我们的headers信息复制下来就行了 (这里我就不放上我的headers信息了,不过headers里需要修改和注意的内容会在下文讲清楚) headers = { 'Host':******, 'Connection':'close', 'Accept':******, 'User-Agent':*
-
python爬虫_微信公众号推送信息爬取的实例
问题描述 利用搜狗的微信搜索抓取指定公众号的最新一条推送,并保存相应的网页至本地. 注意点 搜狗微信获取的地址为临时链接,具有时效性. 公众号为动态网页(JavaScript渲染),使用requests.get()获取的内容是不含推送消息的,这里使用selenium+PhantomJS处理 代码 #! /usr/bin/env python3 from selenium import webdriver from datetime import datetime import bs4, requ
-
Python实现树莓派WiFi断线自动重连的实例代码
实现 WiFi 断线自动重连.原理是用 Python 监测网络是否断线,如果断线则重启网络服务. 1.Python 代码 autowifi.py,放在 /home/pi 目录下: #!/usr/bin/python import os, time while True: if '192' not in os.popen('ifconfig | grep 192').read(): print '\n****** wifi is down, restart... ******\n' os.syst
-
python爬虫利用selenium实现自动翻页爬取某鱼数据的思路详解
基本思路: 首先用开发者工具找到需要提取数据的标签列 利用xpath定位需要提取数据的列表 然后再逐个提取相应的数据: 保存数据到csv: 利用开发者工具找到下一页按钮所在标签: 利用xpath提取此标签对象并返回: 调用点击事件,并循环上述过程: 最终效果图: 代码: from selenium import webdriver import time import re class Douyu(object): def __init__(self): # 开始时的url self.start
-
Python实现校园网自动登录的脚本分享
目录 背景 思路 技术点 碎碎念 代码 背景 我在的学校校园网登录是web式的,即随便打开一个网页就会自动跳转到登录页面,然后输入用户名密码,点登录,便可以上网了. 但这种登录方式有个缺点:登录状态不会一直保持下去.即过一段时间就会掉线,然后你需要重新登陆才行.这个时间大概是一天. 这就蛋疼了,想让实验室的电脑随时保持联网状态怎么办呢?(有时候我需要远程我的电脑) 这个时候可以用python脚本解决这个问题! 思路 写一个死循环一直 ping 8.8.8.8,如果 ping 通说明正连着网,进入
-
Python爬虫实现百度图片自动下载
制作爬虫的步骤 制作一个爬虫一般分以下几个步骤: 分析需求分析网页源代码,配合开发者工具编写正则表达式或者XPath表达式正式编写 python 爬虫代码 效果预览 运行效果如下: 存放图片的文件夹: 需求分析 我们的爬虫至少要实现两个功能:一是搜索图片,二是自动下载. 搜索图片:最容易想到的是爬百度图片的结果,我们就上百度图片看看: 随便搜索几个关键字,可以看到已经搜索出来很多张图片: 分析网页 我们点击右键,查看源代码: 打开源代码之后,发现一堆源代码比较难找出我们想要的资源. 这个时候,就
-
Python爬虫_城市公交、地铁站点和线路数据采集实例
城市公交.地铁数据反映了城市的公共交通,研究该数据可以挖掘城市的交通结构.路网规划.公交选址等.但是,这类数据往往掌握在特定部门中,很难获取.互联网地图上有大量的信息,包含公交.地铁等数据,解析其数据反馈方式,可以通过Python爬虫采集.闲言少叙,接下来将详细介绍如何使用Python爬虫爬取城市公交.地铁站点和数据. 首先,爬取研究城市的所有公交和地铁线路名称,即XX路,地铁X号线.可以通过图吧公交.公交网.8684.本地宝等网站获取,该类网站提供了按数字和字母划分类别的公交线路名称.Pyth
-
python爬虫项目设置一个中断重连的程序的实现
做爬虫项目时,我们需要考虑一个爬虫在爬取时会遇到各种情况(网站验证,ip封禁),导致爬虫程序中断,这时我们已经爬取过一些数据,再次爬取时这些数据就可以忽略,所以我们需要在爬虫项目中设置一个中断重连的功能,使其在重新运行时从之前断掉的位置重新爬取数据. 实现该功能有很多种做法,我自己就有好几种思路,但是真要自己写出来就要费很大的功夫,下面我就把自己好不容易拼凑出来的代码展示出来吧. 首先是来介绍代码的思路: 将要爬取的网站连接存在一个数组new_urls中,爬取一个网址就将它移入另一个数组old_
-
用Python编写生成树状结构的文件目录的脚本的教程
有时候需要罗列下U盘等移动设备或一个程序下面的目录结构的需求.基于这样的需求个人整理了一个使用Python的小工具,期望对有这方面需求的朋友有所帮助.以下为具体代码: 如果你所有要求的文件目录不需要完整的文件路径的话,直接更换下面的注释代码即可~ # -*- coding:utf-8 -*- import os def list_files(startPath): fileSave = open('list.txt','w') for root, dirs, files in os.walk(s