TensorFlow实现Batch Normalization
一、BN(Batch Normalization)算法
1. 对数据进行归一化处理的重要性
神经网络学习过程的本质就是学习数据分布,在训练数据与测试数据分布不同情况下,模型的泛化能力就大大降低;另一方面,若训练过程中每批batch的数据分布也各不相同,那么网络每批迭代学习过程也会出现较大波动,使之更难趋于收敛,降低训练收敛速度。对于深层网络,网络前几层的微小变化都会被网络累积放大,则训练数据的分布变化问题会被放大,更加影响训练速度。
2. BN算法的强大之处
1)为了加速梯度下降算法的训练,我们可以采取指数衰减学习率等方法在初期快速学习,后期缓慢进入全局最优区域。使用BN算法后,就可以直接选择比较大的学习率,且设置很大的学习率衰减速度,大大提高训练速度。即使选择了较小的学习率,也会比以前不使用BN情况下的收敛速度快。总结就是BN算法具有快速收敛的特性。
2)BN具有提高网络泛化能力的特性。采用BN算法后,就可以移除针对过拟合问题而设置的dropout和L2正则化项,或者采用更小的L2正则化参数。
3)BN本身是一个归一化网络层,则局部响应归一化层(Local Response Normalization,LRN层)则可不需要了(Alexnet网络中使用到)。
3. BN算法概述
BN算法提出了变换重构,引入了可学习参数γ、β,这就是算法的关键之处:

引入这两个参数后,我们的网络便可以学习恢复出原是网络所要学习的特征分布,BN层的钱箱传到过程如下:

其中m为batchsize。BatchNormalization中所有的操作都是平滑可导,这使得back propagation可以有效运行并学到相应的参数γ,β。需要注意的一点是Batch Normalization在training和testing时行为有所差别。Training时μβ和σβ由当前batch计算得出;在Testing时μβ和σβ应使用Training时保存的均值或类似的经过处理的值,而不是由当前batch计算。
二、TensorFlow相关函数
1.tf.nn.moments(x, axes, shift=None, name=None, keep_dims=False)
x是输入张量,axes是在哪个维度上求解, 即想要 normalize的维度, [0] 代表 batch 维度,如果是图像数据,可以传入 [0, 1, 2],相当于求[batch, height, width] 的均值/方差,注意不要加入channel 维度。该函数返回两个张量,均值mean和方差variance。
2.tf.identity(input, name=None)
返回与输入张量input形状和内容一致的张量。
3.tf.nn.batch_normalization(x, mean, variance, offset, scale, variance_epsilon,name=None)
计算公式为scale(x - mean)/ variance + offset。
这些参数中,tf.nn.moments可得到均值mean和方差variance,offset和scale是可训练的,offset一般初始化为0,scale初始化为1,offset和scale的shape与mean相同,variance_epsilon参数设为一个很小的值如0.001。
三、TensorFlow代码实现
1. 完整代码
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
ACTIVITION = tf.nn.relu
N_LAYERS = 7 # 总共7层隐藏层
N_HIDDEN_UNITS = 30 # 每层包含30个神经元
def fix_seed(seed=1): # 设置随机数种子
np.random.seed(seed)
tf.set_random_seed(seed)
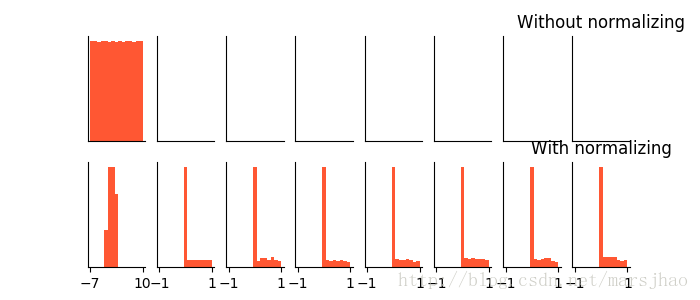
def plot_his(inputs, inputs_norm): # 绘制直方图函数
for j, all_inputs in enumerate([inputs, inputs_norm]):
for i, input in enumerate(all_inputs):
plt.subplot(2, len(all_inputs), j*len(all_inputs)+(i+1))
plt.cla()
if i == 0:
the_range = (-7, 10)
else:
the_range = (-1, 1)
plt.hist(input.ravel(), bins=15, range=the_range, color='#FF5733')
plt.yticks(())
if j == 1:
plt.xticks(the_range)
else:
plt.xticks(())
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
plt.title("%s normalizing" % ("Without" if j == 0 else "With"))
plt.draw()
plt.pause(0.01)
def built_net(xs, ys, norm): # 搭建网络函数
# 添加层
def add_layer(inputs, in_size, out_size, activation_function=None, norm=False):
Weights = tf.Variable(tf.random_normal([in_size, out_size],
mean=0.0, stddev=1.0))
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)
Wx_plus_b = tf.matmul(inputs, Weights) + biases
if norm: # 判断是否是Batch Normalization层
# 计算均值和方差,axes参数0表示batch维度
fc_mean, fc_var = tf.nn.moments(Wx_plus_b, axes=[0])
scale = tf.Variable(tf.ones([out_size]))
shift = tf.Variable(tf.zeros([out_size]))
epsilon = 0.001
# 定义滑动平均模型对象
ema = tf.train.ExponentialMovingAverage(decay=0.5)
def mean_var_with_update():
ema_apply_op = ema.apply([fc_mean, fc_var])
with tf.control_dependencies([ema_apply_op]):
return tf.identity(fc_mean), tf.identity(fc_var)
mean, var = mean_var_with_update()
Wx_plus_b = tf.nn.batch_normalization(Wx_plus_b, mean, var,
shift, scale, epsilon)
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
return outputs
fix_seed(1)
if norm: # 为第一层进行BN
fc_mean, fc_var = tf.nn.moments(xs, axes=[0])
scale = tf.Variable(tf.ones([1]))
shift = tf.Variable(tf.zeros([1]))
epsilon = 0.001
ema = tf.train.ExponentialMovingAverage(decay=0.5)
def mean_var_with_update():
ema_apply_op = ema.apply([fc_mean, fc_var])
with tf.control_dependencies([ema_apply_op]):
return tf.identity(fc_mean), tf.identity(fc_var)
mean, var = mean_var_with_update()
xs = tf.nn.batch_normalization(xs, mean, var, shift, scale, epsilon)
layers_inputs = [xs] # 记录每一层的输入
for l_n in range(N_LAYERS): # 依次添加7层
layer_input = layers_inputs[l_n]
in_size = layers_inputs[l_n].get_shape()[1].value
output = add_layer(layer_input, in_size, N_HIDDEN_UNITS, ACTIVITION, norm)
layers_inputs.append(output)
prediction = add_layer(layers_inputs[-1], 30, 1, activation_function=None)
cost = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction),
reduction_indices=[1]))
train_op = tf.train.GradientDescentOptimizer(0.001).minimize(cost)
return [train_op, cost, layers_inputs]
fix_seed(1)
x_data = np.linspace(-7, 10, 2500)[:, np.newaxis]
np.random.shuffle(x_data)
noise =np.random.normal(0, 8, x_data.shape)
y_data = np.square(x_data) - 5 + noise
plt.scatter(x_data, y_data)
plt.show()
xs = tf.placeholder(tf.float32, [None, 1])
ys = tf.placeholder(tf.float32, [None, 1])
train_op, cost, layers_inputs = built_net(xs, ys, norm=False)
train_op_norm, cost_norm, layers_inputs_norm = built_net(xs, ys, norm=True)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
cost_his = []
cost_his_norm = []
record_step = 5
plt.ion()
plt.figure(figsize=(7, 3))
for i in range(250):
if i % 50 == 0:
all_inputs, all_inputs_norm = sess.run([layers_inputs, layers_inputs_norm],
feed_dict={xs: x_data, ys: y_data})
plot_his(all_inputs, all_inputs_norm)
sess.run([train_op, train_op_norm],
feed_dict={xs: x_data[i*10:i*10+10], ys: y_data[i*10:i*10+10]})
if i % record_step == 0:
cost_his.append(sess.run(cost, feed_dict={xs: x_data, ys: y_data}))
cost_his_norm.append(sess.run(cost_norm,
feed_dict={xs: x_data, ys: y_data}))
plt.ioff()
plt.figure()
plt.plot(np.arange(len(cost_his))*record_step,
np.array(cost_his), label='Without BN') # no norm
plt.plot(np.arange(len(cost_his))*record_step,
np.array(cost_his_norm), label='With BN') # norm
plt.legend()
plt.show()
2. 实验结果
输入数据分布:
批标准化BN效果对比:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
您可能感兴趣的文章:
- tensorflow中next_batch的具体使用
- 详解Tensorflow数据读取有三种方式(next_batch)
相关推荐
-
tensorflow中next_batch的具体使用
本文介绍了tensorflow中next_batch的具体使用,分享给大家,具体如下: 此处给出了几种不同的next_batch方法,该文章只是做出代码片段的解释,以备以后查看: def next_batch(self, batch_size, fake_data=False): """Return the next `batch_size` examples from this data set.""" if fake_data: fake_i
-

详解Tensorflow数据读取有三种方式(next_batch)
Tensorflow数据读取有三种方式: Preloaded data: 预加载数据 Feeding: Python产生数据,再把数据喂给后端. Reading from file: 从文件中直接读取 这三种有读取方式有什么区别呢? 我们首先要知道TensorFlow(TF)是怎么样工作的. TF的核心是用C++写的,这样的好处是运行快,缺点是调用不灵活.而Python恰好相反,所以结合两种语言的优势.涉及计算的核心算子和运行框架是用C++写的,并提供API给Python.Python调用这些A
-
TensorFlow实现Batch Normalization
一.BN(Batch Normalization)算法 1. 对数据进行归一化处理的重要性 神经网络学习过程的本质就是学习数据分布,在训练数据与测试数据分布不同情况下,模型的泛化能力就大大降低:另一方面,若训练过程中每批batch的数据分布也各不相同,那么网络每批迭代学习过程也会出现较大波动,使之更难趋于收敛,降低训练收敛速度.对于深层网络,网络前几层的微小变化都会被网络累积放大,则训练数据的分布变化问题会被放大,更加影响训练速度. 2. BN算法的强大之处 1)为了加速梯度下降算法的训练,我们
-
解决Pytorch中Batch Normalization layer踩过的坑
1. 注意momentum的定义 Pytorch中的BN层的动量平滑和常见的动量法计算方式是相反的,默认的momentum=0.1 BN层里的表达式为: 其中γ和β是可以学习的参数.在Pytorch中,BN层的类的参数有: CLASS torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 每个参数具体含义参见文档,需要注意的是,affine定义了BN层的
-
python神经网络Batch Normalization底层原理详解
目录 什么是Batch Normalization Batch Normalization的计算公式 Bn层的好处 为什么要引入γ和β变量 Bn层的代码实现 什么是Batch Normalization Batch Normalization是神经网络中常用的层,解决了很多深度学习中遇到的问题,我们一起来学习一哈. Batch Normalization是由google提出的一种训练优化方法.参考论文:Batch Normalization Accelerating Deep Network T
-
tensorflow使用L2 regularization正则化修正overfitting过拟合方式
L2正则化原理: 过拟合的原理:在loss下降,进行拟合的过程中(斜线),不同的batch数据样本造成红色曲线的波动大,图中低点也就是过拟合,得到的红线点低于真实的黑线,也就是泛化更差. 可见,要想减小过拟合,减小这个波动,减少w的数值就能办到. L2正则化训练的原理:在Loss中加入(乘以系数λ的)参数w的平方和,这样训练过程中就会抑制w的值,w的(绝对)值小,模型复杂度低,曲线平滑,过拟合程度低(奥卡姆剃刀),参考公式如下图: (正则化是不阻碍你去拟合曲线的,并不是所有参数都会被无脑抑制,实
-
keras的三种模型实现与区别说明
前言 一.keras提供了三种定义模型的方式 1. 序列式(Sequential) API 序贯(sequential)API允许你为大多数问题逐层堆叠创建模型.虽然说对很多的应用来说,这样的一个手法很简单也解决了很多深度学习网络结构的构建,但是它也有限制-它不允许你创建模型有共享层或有多个输入或输出的网络. 2. 函数式(Functional) API Keras函数式(functional)API为构建网络模型提供了更为灵活的方式. 它允许你定义多个输入或输出模型以及共享图层的模型.除此之外
-
对比分析BN和dropout在预测和训练时区别
目录 Batch Normalization Dropout Batch Normalization和Dropout是深度学习模型中常用的结构. 但BN和dropout在训练和测试时使用却不相同. Batch Normalization BN在训练时是在每个batch上计算均值和方差来进行归一化,每个batch的样本量都不大,所以每次计算出来的均值和方差就存在差异.预测时一般传入一个样本,所以不存在归一化,其次哪怕是预测一个batch,但batch计算出来的均值和方差是偏离总体样本的,所以通常是
-
Python利用keras接口实现深度神经网络回归
目录 1 写在前面 2 代码分解介绍 2.1 准备工作 2.2 参数配置 2.3 数据导入与数据划分 2.4 联合分布图绘制 2.5 因变量分离与数据标准化 2.6 原有模型删除 2.7 最优Epoch保存与读取 2.8 模型构建 2.9 训练图像绘制 2.10 最优Epoch选取 2.11 模型测试.拟合图像绘制.精度验证与模型参数与结果保存 3 完整代码 1 写在前面 前期一篇文章Python TensorFlow深度学习回归代码:DNNRegressor详细介绍了基于TensorFlow
-
pytorch之添加BN的实现
pytorch之添加BN层 批标准化 模型训练并不容易,特别是一些非常复杂的模型,并不能非常好的训练得到收敛的结果,所以对数据增加一些预处理,同时使用批标准化能够得到非常好的收敛结果,这也是卷积网络能够训练到非常深的层的一个重要原因. 数据预处理 目前数据预处理最常见的方法就是中心化和标准化,中心化相当于修正数据的中心位置,实现方法非常简单,就是在每个特征维度上减去对应的均值,最后得到 0 均值的特征.标准化也非常简单,在数据变成 0 均值之后,为了使得不同的特征维度有着相同的规模,可以除以标准
-
使用 PyTorch 实现 MLP 并在 MNIST 数据集上验证方式
简介 这是深度学习课程的第一个实验,主要目的就是熟悉 Pytorch 框架.MLP 是多层感知器,我这次实现的是四层感知器,代码和思路参考了网上的很多文章.个人认为,感知器的代码大同小异,尤其是用 Pytorch 实现,除了层数和参数外,代码都很相似. Pytorch 写神经网络的主要步骤主要有以下几步: 1 构建网络结构 2 加载数据集 3 训练神经网络(包括优化器的选择和 Loss 的计算) 4 测试神经网络 下面将从这四个方面介绍 Pytorch 搭建 MLP 的过程. 项目代码地址:la
-
关于Pytorch的MNIST数据集的预处理详解
关于Pytorch的MNIST数据集的预处理详解 MNIST的准确率达到99.7% 用于MNIST的卷积神经网络(CNN)的实现,具有各种技术,例如数据增强,丢失,伪随机化等. 操作系统:ubuntu18.04 显卡:GTX1080ti python版本:2.7(3.7) 网络架构 具有4层的CNN具有以下架构. 输入层:784个节点(MNIST图像大小) 第一卷积层:5x5x32 第一个最大池层 第二卷积层:5x5x64 第二个最大池层 第三个完全连接层:1024个节点 输出层:10个节点(M