两台服务器之间无密码传输数据和操作的方法
我们知道如果要向远程服务器传输数据和操作必须输入用户名和密码远程登录服务器 ,或用FTP等协议,都需要权限控制。
然而如果是两台服务器间的软件需要通讯和数据传输,如hadoop集群中机器互访,是不是每次也要输入用户名和密码?那是不是很麻烦?下面介绍SSH来解决这个问题(不是JAVA中的SSH概念)
SSH是一种网络协议,用于计算机之间的加密登录。
如果一个用户从本地计算机,使用SSH协议登录另一台远程计算机,我们就可以认为,这种登录是安全的,即使被中途截获,密码也不会泄露。
最早的时候,互联网通信都是明文通信,一旦被截获,内容就暴露无疑。1995年,芬兰学者Tatu Ylonen设计了SSH协议,将登录信息全部加密,成为互联网安全的一个基本解决方案,迅速在全世界获得推广,目前已经成为Linux系统的标准配置。
需要指出的是,SSH只是一种协议,存在多种实现,既有商业实现,也有开源实现。本文针对的实现是OpenSSH,它是自由软件,应用非常广泛。
此外,本文只讨论SSH在Linux Shell中的用法。如果要在Windows系统中使用SSH,会用到另一种软件PuTTY
Hadoop运行过程中需要管理远端Hadoop守护进程,在Hadoop启动以后,NameNode是通过SSH(Secure Shell)来启动和停止各个DataNode上的各种守护进程的。
这就必须在节点之间执行指令的时候是不需要输入密码的形式,故我们需要配置SSH运用无密码公钥认证的形式,这样NameNode使用SSH无密码登录并启动DataName进程,同样原理,DataNode上也能使用SSH无密码登录到NameNode。
下面就安装总结一下网友和自己的经验。
环境
CentOS7.0
安装
yum install ssh 安装SSH协议 yum install rsync (rsync是一个远程数据同步工具,可通过LAN/WAN快速同步多台主机间的文件) service sshd restart 启动服务
查看安装
rpm –qa | grep openssh rpm –qa | grep rsync
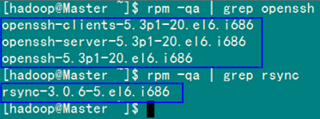
为避免麻烦,每个服务器上都要装。
配置Master无密码登录所有Salve
1)SSH无密码原理
Master(NameNode | JobTracker)作为客户端,要实现无密码公钥认证,连接到服务器Salve(DataNode | Tasktracker)上时,需要在Master上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到所有的Slave上。当Master通过SSH连接Salve时,Salve就会生成一个随机数并用Master的公钥对随机数进行加密,并发送给Master。Master收到加密数之后再用私钥解密,并将解密数回传给Slave,Slave确认解密数无误之后就允许Master进行连接了。这就是一个公钥认证过程,其间不需要用户手工输入密码。重要过程是将客户端Master复制到Slave上。
2)Master机器上生成密码对
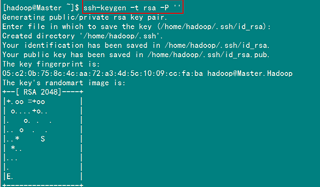
在Master节点上执行以下命令:
ssh-keygen –t rsa –P ''
这条命是生成其无密码密钥对,询问其保存路径时直接回车采用默认路径。生成的密钥对:id_rsa和id_rsa.pub,默认存储在"/home/hadoop/.ssh"目录下(每台服务器看各自的生成路径信息 因为hadoop为用户名,所以生成在当前用户名下)。
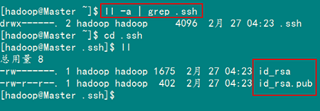
查看"/home/hadoop/"下是否有".ssh"文件夹,且".ssh"文件下是否有两个刚生产的无密码密钥对。
接着在Master节点上做如下配置,把id_rsa.pub追加到授权的key里面去。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys

在验证前,需要做两件事儿。第一件事儿是修改文件"authorized_keys"权限(权限的设置非常重要,因为不安全的设置安全设置,会让你不能使用RSA功能),另一件事儿是用root用户设置"/etc/ssh/sshd_config"的内容。使其无密码登录有效。
1)修改文件"authorized_keys"
chmod 600 ~/.ssh/authorized_keys
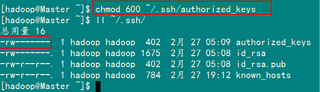
备注:如果不进行设置,在验证时,扔提示你输入密码,在这里花费了将近半天时间来查找原因。
2)设置SSH配置
用root用户登录服务器修改SSH配置文件"/etc/ssh/sshd_config"的下列内容。

RSAAuthentication yes # 启用 RSA 认证 PubkeyAuthentication yes # 启用公钥私钥配对认证方式 AuthorizedKeysFile .ssh/authorized_keys # 公钥文件路径(和上面生成的文件同)
设置完之后记得重启SSH服务,才能使刚才设置有效。
service sshd restart
退出root登录,使用hadoop普通用户验证是否成功。
ssh localhost
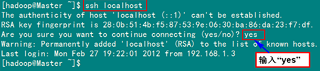
从上图中得知无密码登录本级已经设置完毕,接下来的事儿是把公钥复制所有的Slave机器上。使用下面的命令格式进行复制公钥:
scp ~/.ssh/id_rsa.pub 远程用户名@远程服务器IP:~/
例如:
scp ~/.ssh/id_rsa.pub hadoop@192.168.1.3:~/
上面的命令是复制文件"id_rsa.pub"到服务器IP为"192.168.1.3"的用户为"hadoop"的"/home/hadoop/"下面。
下面就针对IP为"192.168.1.3"的Slave1.Hadoop的节点进行配置。
1)把Master.Hadoop上的公钥复制到Slave1.Hadoop上

从上图中我们得知,已经把文件"id_rsa.pub"传过去了,因为并没有建立起无密码连接,所以在连接时,仍然要提示输入输入Slave1.Hadoop服务器用户hadoop的密码。为了确保确实已经把文件传过去了,用SecureCRT登录Slave1.Hadoop:192.168.1.3服务器,查看"/home/hadoop/"下是否存在这个文件。

从上面得知我们已经成功把公钥复制过去了。
2)在"/home/hadoop/"下创建".ssh"文件夹
这一步并不是必须的,如果在Slave1.Hadoop的"/home/hadoop"已经存在就不需要创建了,因为我们之前并没有对Slave机器做过无密码登录配置,所以该文件是不存在的。用下面命令进行创建。(备注:用hadoop登录系统,如果不涉及系统文件修改,一般情况下都是用我们之前建立的普通用户hadoop进行执行命令。)
mkdir ~/.ssh
然后是修改文件夹".ssh"的用户权限,把他的权限修改为"700",用下面命令执行:
chmod 700 ~/.ssh
备注:如果不进行,即使你按照前面的操作设置了"authorized_keys"权限,并配置了"/etc/ssh/sshd_config",还重启了sshd服务,在Master能用"ssh localhost"进行无密码登录,但是对Slave1.Hadoop进行登录仍然需要输入密码,就是因为".ssh"文件夹的权限设置不对。这个文件夹".ssh"在配置SSH无密码登录时系统自动生成时,权限自动为"700",如果是自己手动创建,它的组权限和其他权限都有,这样就会导致RSA无密码远程登录失败。
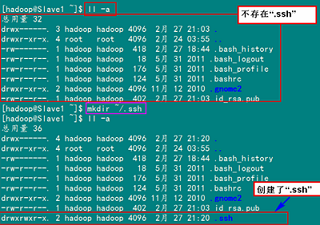

对比上面两张图,发现文件夹".ssh"权限已经变了。
3)追加到授权文件"authorized_keys"
到目前为止Master.Hadoop的公钥也有了,文件夹".ssh"也有了,且权限也修改了。这一步就是把Master.Hadoop的公钥追加到Slave1.Hadoop的授权文件"authorized_keys"中去。使用下面命令进行追加并修改"authorized_keys"文件权限:
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys chmod 600 ~/.ssh/authorized_keys

4)用root用户修改"/etc/ssh/sshd_config"
具体步骤参考前面Master.Hadoop的"设置SSH配置",具体分为两步:第1是修改配置文件;第2是重启SSH服务。
5)用Master.Hadoop使用SSH无密码登录Slave1.Hadoop
当前面的步骤设置完毕,就可以使用下面命令格式进行SSH无密码登录了。
ssh 远程服务器IP

从上图我们主要3个地方,第1个就是SSH无密码登录命令,第2、3个就是登录前后"@"后面的机器名变了,由"Master"变为了"Slave1",这就说明我们已经成功实现了SSH无密码登录了。
最后记得把"/home/hadoop/"目录下的"id_rsa.pub"文件删除掉。
rm –r ~/id_rsa.pub
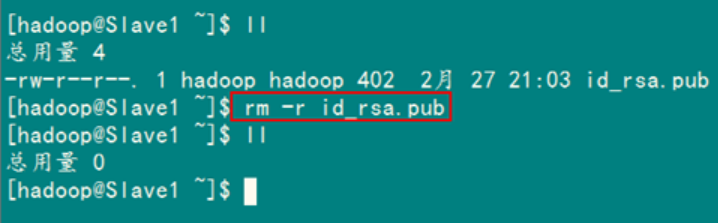
到此为止,我们经过前5步已经实现了从"Master.Hadoop"到"Slave1.Hadoop"SSH无密码登录,下面就是重复上面的步骤把剩余的Slave服务器进行配置。这样,我们就完成了"配置Master无密码登录所有的Slave服务器"。
扩展
如果实现Slave服务器无密码登录Master?
以上所述是小编给大家介绍的两台服务器之间无密码传输数据和操作的方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
Nginx服务器对数据传输速度限制的基本配置方法讲解
注意: nginx 1.1.8 之后的版本的语法改为limit_conn_zone $binary_remote_addr zone=NAME:10m; NAME 就是 zone 的名字详情请看这里 http://nginx.org/en/docs/http/ngx_http_limit_conn_module.html 限制连接数: 要限制连接,必须先有一个容器对连接进行计数,在http段加入如下代码: "zone=" 给它一个名字,可以随便叫,这个名字要跟下面的 limit_con
-

两台服务器之间无密码传输数据和操作的方法
我们知道如果要向远程服务器传输数据和操作必须输入用户名和密码远程登录服务器 ,或用FTP等协议,都需要权限控制. 然而如果是两台服务器间的软件需要通讯和数据传输,如hadoop集群中机器互访,是不是每次也要输入用户名和密码?那是不是很麻烦?下面介绍SSH来解决这个问题(不是JAVA中的SSH概念) SSH是一种网络协议,用于计算机之间的加密登录. 如果一个用户从本地计算机,使用SSH协议登录另一台远程计算机,我们就可以认为,这种登录是安全的,即使被中途截获,密码也不会泄露. 最早的时候,互联网通
-
Linux两台服务器之间传输文件和文件夹操作步骤
今天处理一个项目要迁移的问题,突然发现这么多图片怎么移过去,可能第一时间想到的是先从这台服务器下载下来,然后再上传到另外一台服务器上面去,这个方法确实是可行,但是实在是太费时间了,今天我就教大家怎么快速的在两台服务器之间传输文件和文件夹. 第一步:打开我们的远程连接工具,输入账号密码登录到服务器,如图: 点击文件打开或者新建一个会话,新建会话输入主机的ip和账号密码即可,如果已经登录过,直接点击文件下面那个带+号的图标就可以了. 第二步:找到你要传输的文件或者文件夹: 这里有这么多图片,我随便传
-
Linux两台服务器之间复制文件及免密码登录的方法
有时候搭建集群机器是,需要在多台机器中间相互拷贝文件,一种方式是同事sftp拷贝到本机,再分别拷贝到其他服务器上.这里介绍一种直接在两台服务器之间拷贝文件且去掉繁琐的登陆操作的方法. 两台服务器之间拷贝文件 采用linux命令scp可以在两台电脑之间复制文件,如有两台服务器192.168.129.100/101,现在需要拷贝100 /etc/passwd文件到101服务器的/etc目录下,登陆100服务器,知道101的用户root的密码为123456 scp /etc/passwd root@1
-
java实现两台服务器间文件复制的方法
本文实例讲述了java实现两台服务器间文件复制的方法.分享给大家供大家参考.具体分析如下: 通常我们使用最多的文件复制功能就是同服务器之间的文件复制功能,这里介绍的是在普通文件复制上功能升级,可以实现两台服务器实现文件的复制,下面一起来看看代码. 1.服务器端 复制代码 代码如下: package sterning; import java.io.BufferedInputStream; import java.io.DataInputStream; import java.io.DataOut
-
python实现简单socket程序在两台电脑之间传输消息的方法
本文实例讲述了python实现简单socket程序在两台电脑之间传输消息的方法.分享给大家供大家参考.具体分析如下: python开发简单socket程序在两台电脑之间传输消息,分为客户端和服务端,分别在两台电脑上运行后即可进行简单的消息传输,也可以在一台电脑上测试,设置两个不同的端口即可. # Save as server.py 服务端代码 # Message Receiver import os from socket import * host = "" port = 13000
-
Python 实现两个服务器之间文件的上传方法
如下所示: # coding: utf-8 import paramiko import MySQLdb def main(): connection=MySQLdb.connect(host='10.10.41.22',user='root',passwd='root',db='Trojan',port=3306) cur=connection.cursor() sql ='select count(*) from blacklist;' cur.execute(sql) count = cu
-
vue实现两个组件之间数据共享和修改操作
我们在使用vue开发过程中会遇到这样的情况,在父组件中引入了子组件,需要将父组件的值传到子组件中显示,同时子组件还可以更改父组件的值. 以我目前的一个项目的开发为例,如下图页面: 在父组件中,我引入了两个子组件,一个是左边的导航栏,还有中间的一个富文本编译器组件,当我点击左边导航栏时,中间的页面会切换,也就是改变引入的子组件. 怎么实现呢,首先,设置在该页面index.vue中设置一个变量index,左边导航栏每一项也对应一个index值,导航菜单绑定select函数,@select="hand
-
JS正则截取两个字符串之间及字符串前后内容的方法
本文实例讲述了JS正则截取两个字符串之间及字符串前后内容的方法.分享给大家供大家参考,具体如下: 1.js截取两个字符串之间的内容: var str = "aaabbbcccdddeeefff"; str = str.match(/aaa(\S*)fff/)[1]; alert(str);//结果bbbcccdddeee 2.js截取某个字符串前面的内容: var str = "aaabbbcccdddeeefff"; tr = str.match(/(\S*)ff
-
php判断两个日期之间相差多少个月份的方法
本文实例讲述了php判断两个日期之间相差多少个月份的方法.分享给大家供大家参考.具体实现方法如下: /** * @author injection(injection.mail@gmail.com) * @var date1日期1 * @var date2 日期2 * @var tags 年月日之间的分隔符标记,默认为'-' * @return 相差的月份数量 * @example: $date1 = "2003-08-11"; $date2 = "2008-11-06&qu
-
SQLServer 2000 数据库同步详细步骤[两台服务器]
为什么要同步SQL Server 2000 数据库,它都用在什么场合 SQL Server 2000 数据库同步配置的原理 从0开始一步一步配置SQL Server 2000 数据库同步,非常细 已经非常熟练,可以看精品版SQL Server 2000 数据库同步配置 配置SQL Server 2000 数据库同步时的 常见问题 为什么要同步SQL Server 2000 数据库,它都用在什么场合 数据实时备份同步,数据库服务器出问题时我们也有其正常工作时的备份 数据实时备份同步,一台服务器负载