详解使用docker搭建hadoop分布式集群
使用Docker搭建部署Hadoop分布式集群
在网上找了很长时间都没有找到使用docker搭建hadoop分布式集群的文档,没办法,只能自己写一个了。
一:环境准备:
1:首先要有一个Centos7操作系统,可以在虚拟机中安装。
2:在centos7中安装docker,docker的版本为1.8.2
安装步骤如下:
<1>安装制定版本的docker
yum install -y docker-1.8.2-10.el7.centos
<2>安装的时候可能会报错,需要删除这个依赖
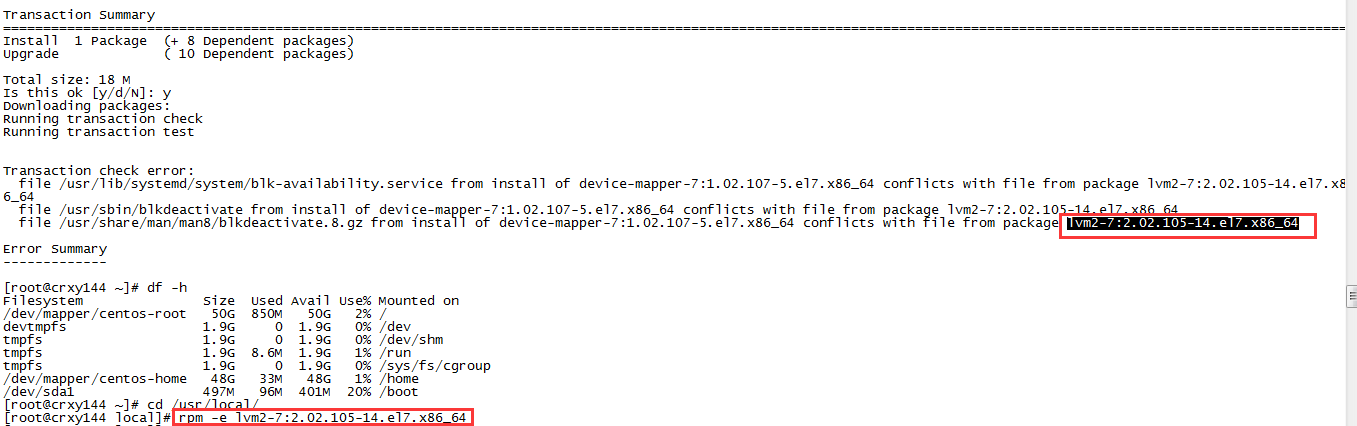
rpm -e lvm2-7:2.02.105-14.el7.x86_64
启动docker
service docker start
验证安装结果:
<3>启动之后执行docker info会看到下面有两行警告信息
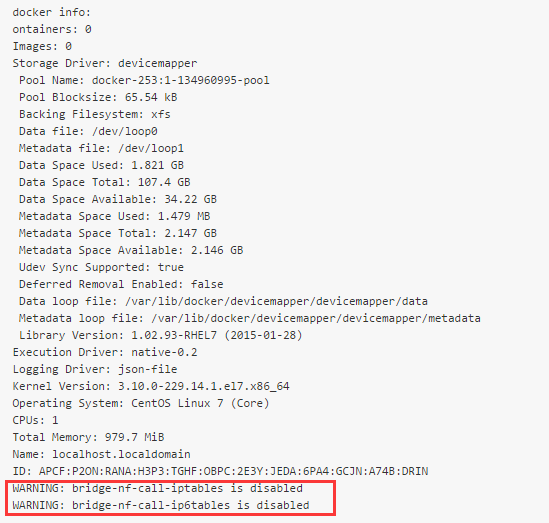
需要关闭防火墙并重启系统
systemctl stop firewalld systemctl disable firewalld #注意:执行完上面的命令之后需要重启系统 reboot -h(重启系统)
<4>运行容器可能会报错

需要关闭selinux
解决方法:
1:setenforce 0(立刻生效,不需要重启操作系统)
2:修改/etc/selinux/config文件中的SELINUX=disabled ,然后重启系统生效
建议两个步骤都执行,这样可以确保系统重启之后selinux也是关闭状态
3:需要先构建一个hadoop的基础镜像,使用dockerfile文件方式进行构建。
先构建一个具备ssh功能的镜像,方便后期使用。(但是这样对于容器的安全性会有影响)
注意:这个镜像中的root用户的密码是root
Mkdir centos-ssh-root Cd centos-ssh-root Vi Dockerfile
# 选择一个已有的os镜像作为基础 FROM centos # 镜像的作者 MAINTAINER crxy # 安装openssh-server和sudo软件包,并且将sshd的UsePAM参数设置成no RUN yum install -y openssh-server sudo RUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config #安装openssh-clients RUN yum install -y openssh-clients # 添加测试用户root,密码root,并且将此用户添加到sudoers里 RUN echo "root:root" | chpasswd RUN echo "root ALL=(ALL) ALL" >> /etc/sudoers # 下面这两句比较特殊,在centos6上必须要有,否则创建出来的容器sshd不能登录 RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key # 启动sshd服务并且暴露22端口 RUN mkdir /var/run/sshd EXPOSE 22 CMD ["/usr/sbin/sshd", "-D"]
构建命令:
docker build -t=”crxy/centos-ssh-root” .
查询刚才构建成功的镜像

4:基于这个镜像再构建一个带有jdk的镜像
注意:jdk使用的是1.7版本的
Mkdir centos-ssh-root-jdk Cd centos-ssh-root-jdk Cp ../jdk-7u75-Linux-x64.tar.gz . Vi Dockerfile
FROM crxy/centos-ssh-root ADD jdk-7u75-linux-x64.tar.gz /usr/local/ RUN mv /usr/local/jdk1.7.0_75 /usr/local/jdk1.7 ENV JAVA_HOME /usr/local/jdk1.7 ENV PATH $JAVA_HOME/bin:$PATH
构建命令:
docker build -t=”crxy/centos-ssh-root-jdk” .
查询构建成功的镜像

5:基于这个jdk镜像再构建一个带有hadoop的镜像
注意:hadoop使用的是2.4.1版本的。
Mkdir centos-ssh-root-jdk-hadoop Cd centos-ssh-root-jdk-hadoop Cp ../hadoop-2.4.1.tar.gz . Vi Dockerfile
FROM crxy/centos-ssh-root-jdk ADD hadoop-2.4.1.tar.gz /usr/local RUN mv /usr/local/hadoop-2.4.1 /usr/local/hadoop ENV HADOOP_HOME /usr/local/hadoop ENV PATH $HADOOP_HOME/bin:$PATH
构建命令:
docker build -t=”crxy/centos-ssh-root-jdk-hadoop” .
查询构建成功的镜像

二:搭建hadoop分布式集群
1:集群规划
准备搭建一个具有三个节点的集群,一主两从
主节点:hadoop0 ip:192.168.2.10
从节点1:hadoop1 ip:192.168.2.11
从节点2:hadoop2 ip:192.168.2.12
但是由于docker容器重新启动之后ip会发生变化,所以需要我们给docker设置固定ip。使用pipework给docker容器设置固定ip
2:启动三个容器,分别作为hadoop0 hadoop1 hadoop2
在宿主机上执行下面命令,给容器设置主机名和容器的名称,并且在hadoop0中对外开放端口50070 和8088
docker run --name hadoop0 --hostname hadoop0 -d -P -p 50070:50070 -p 8088:8088 crxy/centos-ssh-root-jdk-hadoop docker run --name hadoop1 --hostname hadoop1 -d -P crxy/centos-ssh-root-jdk-hadoop docker run --name hadoop2 --hostname hadoop2 -d -P crxy/centos-ssh-root-jdk-hadoop
使用docker ps 查看刚才启动的是三个容器

3:给这三台容器设置固定IP
1:下载pipework 下载地址:https://github.com/jpetazzo/pipework.git
2:把下载的zip包上传到宿主机服务器上,解压,改名字
unzip pipework-master.zip mv pipework-master pipework cp -rp pipework/pipework /usr/local/bin/
3:安装bridge-utils
yum -y install bridge-utils
4:创建网络
brctl addbr br0 ip link set dev br0 up ip addr add 192.168.2.1/24 dev br0
5:给容器设置固定ip
pipework br0 hadoop0 192.168.2.10/24 pipework br0 hadoop1 192.168.2.11/24 pipework br0 hadoop2 192.168.2.12/24
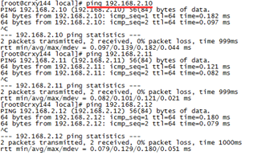
验证一下,分别ping三个ip,能ping通就说明没问题
4:配置hadoop集群
先连接到hadoop0上, 使用命令
docker exec -it hadoop0 /bin/bash
下面的步骤就是hadoop集群的配置过程
1:设置主机名与ip的映射,修改三台容器:vi /etc/hosts
添加下面配置
192.168.2.10 hadoop0 192.168.2.11 hadoop1 192.168.2.12 hadoop2
2:设置ssh免密码登录
在hadoop0上执行下面操作
cd ~ mkdir .ssh cd .ssh ssh-keygen -t rsa(一直按回车即可) ssh-copy-id -i localhost ssh-copy-id -i hadoop0 ssh-copy-id -i hadoop1 ssh-copy-id -i hadoop2 在hadoop1上执行下面操作 cd ~ cd .ssh ssh-keygen -t rsa(一直按回车即可) ssh-copy-id -i localhost ssh-copy-id -i hadoop1 在hadoop2上执行下面操作 cd ~ cd .ssh ssh-keygen -t rsa(一直按回车即可) ssh-copy-id -i localhost ssh-copy-id -i hadoop2
3:在hadoop0上修改hadoop的配置文件
进入到/usr/local/hadoop/etc/hadoop目录
修改目录下的配置文件core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml
(1)hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.7
(2)core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop0:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
(3)hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
(4)yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
</configuration>
(5)修改文件名:mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(6)格式化
进入到/usr/local/hadoop目录下
1、执行格式化命令
bin/hdfs namenode -format
注意:在执行的时候会报错,是因为缺少which命令,安装即可
执行下面命令安装
yum install -y which
看到下面命令说明格式化成功。

格式化操作不能重复执行。如果一定要重复格式化,带参数-force即可。
(7)启动伪分布hadoop
命令:
sbin/start-all.sh
第一次启动的过程中需要输入yes确认一下。

使用jps,检查进程是否正常启动?能看到下面几个进程表示伪分布启动成功
[root@hadoop0 hadoop]# jps 3267 SecondaryNameNode 3003 NameNode 3664 Jps 3397 ResourceManager 3090 DataNode 3487 NodeManager
(8)停止伪分布hadoop
命令:
sbin/stop-all.sh
(9)指定nodemanager的地址,修改文件yarn-site.xml
<property> <description>The hostname of the RM.</description> <name>yarn.resourcemanager.hostname</name> <value>hadoop0</value> </property>
(10)修改hadoop0中hadoop的一个配置文件etc/hadoop/slaves
删除原来的所有内容,修改为如下
hadoop1 hadoop2
(11)在hadoop0中执行命令
scp -rq /usr/local/hadoop hadoop1:/usr/local scp -rq /usr/local/hadoop hadoop2:/usr/local
(12)启动hadoop分布式集群服务
执行sbin/start-all.sh
注意:在执行的时候会报错,是因为两个从节点缺少which命令,安装即可
分别在两个从节点执行下面命令安装
yum install -y which
再启动集群(如果集群已启动,需要先停止)
sbin/start-all.sh
(13)验证集群是否正常
首先查看进程:
Hadoop0上需要有这几个进程
[root@hadoop0 hadoop]# jps 4643 Jps 4073 NameNode 4216 SecondaryNameNode 4381 ResourceManager
Hadoop1上需要有这几个进程
[root@hadoop1 hadoop]# jps 715 NodeManager 849 Jps 645 DataNode
Hadoop2上需要有这几个进程
[root@hadoop2 hadoop]# jps 456 NodeManager 589 Jps 388 DataNode
使用程序验证集群服务
创建一个本地文件
vi a.txt hello you hello me
上传a.txt到hdfs上
hdfs dfs -put a.txt /
执行wordcount程序
cd /usr/local/hadoop/share/hadoop/mapreduce hadoop jar hadoop-mapreduce-examples-2.4.1.jar wordcount /a.txt /out
查看程序执行结果

这样就说明集群正常了。
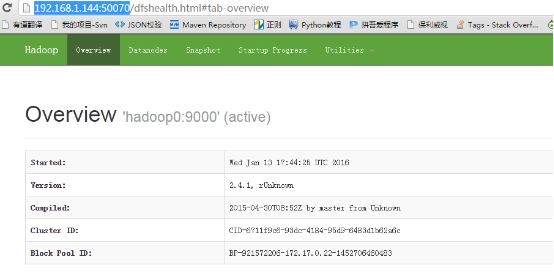
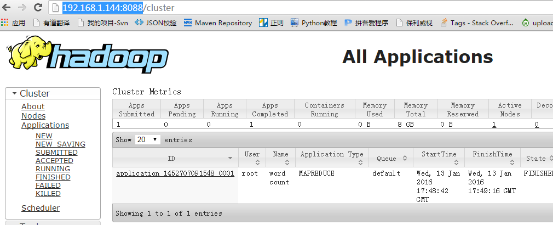
通过浏览器访问集群的服务
由于在启动hadoop0这个容器的时候把50070和8088映射到宿主机的对应端口上了
adb9eba7142b crxy/centos-ssh-root-jdk-hadoop "/usr/sbin/sshd -D" About an hour ago Up About an hour 0.0.0.0:8088->8088/tcp, 0.0.0.0:50070->50070/tcp, 0.0.0.0:32770->22/tcp hadoop0
所以在这可以直接通过宿主机访问容器中hadoop集群的服务
宿主机的ip为:192.168.1.144
http://192.168.1.144:50070/
http://192.168.1.144:8088/
三:集群节点重启
停止三个容器,在宿主机上执行下面命令
docker stop hadoop0 docker stop hadoop1 docker stop hadoop2
容器停止之后,之前设置的固定ip也会消失,重新再使用这几个容器的时候还需要重新设置固定ip
先把之前停止的三个容器起来
docker start hadoop0 docker start hadoop1 docker start hadoop2
在宿主机上执行下面命令重新给容器设置固定ip
pipework br0 hadoop0 192.168.2.10/24 pipework br0 hadoop1 192.168.2.11/24 pipework br0 hadoop2 192.168.2.12/24
还需要重新在容器中配置主机名和ip的映射关系,每次都手工写比较麻烦
写一个脚本,runhosts.sh
#!/bin/bash echo 192.168.2.10 hadoop0 >> /etc/hosts echo 192.168.2.11 hadoop1 >> /etc/hosts echo 192.168.2.12 hadoop2 >> /etc/hosts
添加执行权限,
chmod +x runhosts.sh
把这个脚本拷贝到所有节点,并且分别执行这个脚本
scp runhosts.sh hadoop1:~ scp runhosts.sh hadoop2:~
执行脚本的命令
./runhosts.sh
查看/etc/hosts文件中是否添加成功
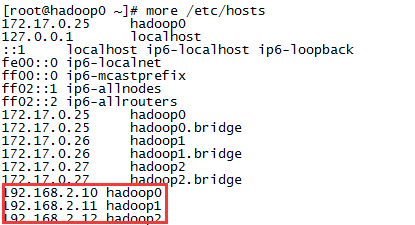
注意:有一些docker版本中不会在hosts文件中自动生成下面这些映射,所以我们才在这里手工给容器设置固定ip,并设置主机名和ip的映射关系。
172.17.0.25 hadoop0
172.17.0.25 hadoop0.bridge
172.17.0.26 hadoop1
172.17.0.26 hadoop1.bridge
172.17.0.27 hadoop2
172.17.0.27 hadoop2.bridge
启动hadoop集群
sbin/start-all.sh
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
docker 搭建hadoop以及hbase集群详解
要用docker搭建集群,首先需要构造集群所需的docker镜像.构建镜像的一种方式是,利用一个已有的镜像比如简单的linux系统,运行一个容器,在容器中手动的安装集群所需要的软件并进行配置,然后commit容器到新的镜像.另一种方式是,使用Dockerfile来自动化的构造镜像. 下面采用第二种. 1. 创建带ssh服务的ubuntu14.04系统镜像 使用ubuntu14系统来安装hadoop和hbase,由于hadoop集群机器之间通过ssh通信,所以需要在ubuntu14系统中安装ssh
-

详解从 0 开始使用 Docker 快速搭建 Hadoop 集群环境
Linux Info: Ubuntu 16.10 x64 Docker 本身就是基于 Linux 的,所以首先以我的一台服务器做实验.虽然最后跑 wordcount 已经由于内存不足而崩掉,但是之前的过程还是可以参考的. 连接服务器 使用 ssh 命令连接远程服务器. ssh root@[Your IP Address] 更新软件列表 apt-get update 更新完成. 安装 Docker sudo apt-get install docker.io 当遇到输入是否继续时,输入「Y/y」继
-
详解使用docker搭建hadoop分布式集群
使用Docker搭建部署Hadoop分布式集群 在网上找了很长时间都没有找到使用docker搭建hadoop分布式集群的文档,没办法,只能自己写一个了. 一:环境准备: 1:首先要有一个Centos7操作系统,可以在虚拟机中安装. 2:在centos7中安装docker,docker的版本为1.8.2 安装步骤如下: <1>安装制定版本的docker yum install -y docker-1.8.2-10.el7.centos <2>安装的时候可能会报错,需要删除这个依赖 r
-
详解基于docker-swarm搭建持续集成集群服务
前言 本文只为自己搭建过程中的一些简单的记录.如果实践中有疑问,可以一起探讨. 为了能在本机(macOS)模拟集群环境,使用了vb和docker-machine.整体持续集成的几个机器设施如下: 1.服务节点:三个manager节点,一个worker节点.manager需要占用更多的资源,manager配置尽量高一些.swarm的manager节点的容错率是 (N-1)/2 .N是manager节点数.也就是如果有3个manager,那就能容忍一个manager节点挂掉.官方的算法说明:Raft
-
基于Docker搭建Redis主从集群的实现
最近陆陆续续有不少园友加我好友咨询 redis 集群搭建的问题,我觉得一定是之前写的这篇 <基于Docker的Redis集群搭建> 文章有问题了,所以我花了几分钟浏览之前的文章总结了下面几个问题: redis 数量太少,只创建了 3 个实例:由于只有 3 个实例,所以全部只能是主节点,无法体现集群主从关系:如何搭建主从集群?如何分配从节点? 基于之前的文章,我想快速的过一下这几个问题,本文基于 Docker + Redis 5.0.5 版本,通过 cluster 方式创建一个 6 个 redi
-
docker搭建redis哨兵集群并且整合springboot的实现
目录 1.创建两个文件夹redis和sentinel文件夹用于存放docker-compose.yml文件 2.redis下的docker-compose.yml 3.sentinel下的docker-compose.yml文件以及sentinel.conf配置文件 4.spring boot整合redis哨兵 5.哨兵工作方式 6.Redis-Cluster集群 7.redis常见问题 1.创建两个文件夹redis和sentinel文件夹用于存放docker-compose.yml文件 2.r
-
Python搭建Spark分布式集群环境
前言 Apache Spark 是一个新兴的大数据处理通用引擎,提供了分布式的内存抽象.Spark 最大的特点就是快,可比 Hadoop MapReduce 的处理速度快 100 倍.本文没有使用一台电脑上构建多个虚拟机的方法来模拟集群,而是使用三台电脑来搭建一个小型分布式集群环境安装. 本教程采用Spark2.0以上版本(比如Spark2.0.2.Spark2.1.0等)搭建集群,同样适用于搭建Spark1.6.2集群. 安装Hadoop并搭建好Hadoop集群环境 Spark分布式集群的安装
-
Hadoop分布式集群的搭建的方法步骤
1 安装说明 1.1 用到的软件 软件 版本 下载地址 linux Ubuntu Server 18.04.2 LTS https://ubuntu.com/download/server hadoop hadoop-2.7.1 http://archive.apache.org/dist/hadoop/common/hadoop-2.7.1/hadoop-2.7.1.tar.gz java jdk-8u211-linux-x64 https://www.oracle.com/technetwo
-
详解用Docker搭建Laravel和Vue项目的开发环境
本文介绍了用Docker搭建Laravel和Vue项目的开发环境,分享给大家,具体如下: 在这篇文章中我们将通过Docker在个人本地电脑上构建一个快速.轻量级.不依赖本地电脑所安装的任何开发套件的可复制的Laravel和Vue项目的开发环境(开发环境的所有依赖都安装在Docker构建容器里),加入Vue只是因为有的项目里会在Laravel项目中使用Vue做前后端分离开发,开发环境中需要安装前端开发需要的工具集,当然前后端也可以分成两个项目开发,这个话题不在本篇文章的讨论范围内. 所以我们的目标
-
详解基于docker搭建lanproxy内网穿透服务
文档更新说明 2018年04月06日 v1.0 内网穿透相信是后端开发者经常遇到的需求,可是怎么实现呢?其实有现成的服务:花生壳.ngrok等,但是,最近花生壳宣布,免费版的内网穿透将不支持80端口映射了,而免费版的ngrok也不够稳定,于是乎,我就开始需找新的解决方案了 本文使用了docker.nginx,要全部搞懂的话需要一定的后端基础(当然,基本上入个门就可以了),个人认为还是有一定阅读门槛的,但是你如果只是想把服务搭建起来,按照步骤来做是不难的 1.概述 内网穿透其实就是用服务器做一个中
-
Docker搭建Zookeeper&Kafka集群的实现
最近在学习Kafka,准备测试集群状态的时候感觉无论是开三台虚拟机或者在一台虚拟机开辟三个不同的端口号都太麻烦了(嗯..主要是懒). 环境准备 一台可以上网且有CentOS7虚拟机的电脑 为什么使用虚拟机?因为使用的笔记本,所以每次连接网络IP都会改变,还要总是修改配置文件的,过于繁琐,不方便测试.(通过Docker虚拟网络的方式可以避免此问题,当时实验的时候没有了解到) Docker 安装 如果已经安装Docker请忽略此步骤 Docker支持以下的CentOS版本: CentOS 7 (64
-
详解通过Docker搭建Mysql容器+Tomcat容器连接环境
1.实验目的:web容器能访问部署在另外容器中的MySQL 2.步骤1:拉取mysql镜像,拉取命令如下: docker pull mysql//官网的最新mysql进行 3.步骤2:拉取tomcat镜像,拉取命令如下: docker pull tomcat --name xuguokun/jdk-tomcat 4.步骤3:创建mysql的一个容器,容器的名字是mymysql,创建命令如下: 复制代码 代码如下: docker run --name mymysql -p 3306:3306 -