C++学习贝叶斯分类器实现手写数字识别示例解析
大家好啊!这次的文章是上一个文章的后续,与上一次不同的是,这一次对数字识别采用的是贝叶斯(Bayes)分类器。贝叶斯在概率论与数理统计这门课讲过,下面我们简单了解一下:
首先,贝叶斯公式是
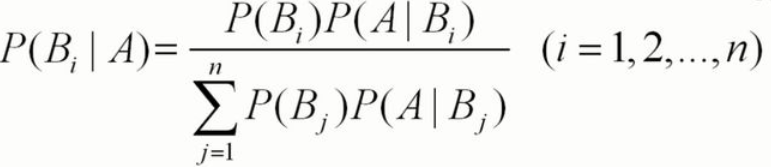
具体的解释就不说了,我们说一说把贝叶斯用在数字识别的什么位置。除了识别部分,其他的包括遍历文件夹和图片数字化都不变;0到9共十个数,所以分母有十项,P(Bj)(j是下标)相应的是0到9,则每一个的概率是1/10,分子上的P(Bi)是取到0到9中的一个,所以概率也是1/10。
(小伙伴如果看不明白建议去看看贝叶斯)所以我们分母可以提出来并约分,然后式子Pi/(P1+P2+P3+P4+P5+P6+P7+P8+P9)(Pi就是P(A|Bi),其他的就是i分别取值),变成这样后,i取0——9的某个数就是测试样本是这个数的概率,比如:i=0,表示测试用例是0的概率为P1/(P1+P2+P3+P4+P5+P6+P7+P8+P9+P10)(1就是对应数字0)。
那么我们该如何找到Pin呢,我们是通过统计样本每一位为1的概率,这样说可能不太清楚,也就是假如一张0的图片的数据化字符串为0000000000100000111000010010001010000111000000000(49位),我们一位一位的去统计每一位为1的个数(如下图,也就是纵向的统计每个样本的第某位为1的个数),最后除以总数,我的训练库一个数字的样本有100张,假如我们统计到数字0的所有样本的第一位数字为1的个数为46个,那么数字0的第一位为1的概率为0.46,其他位也是依次统计,其他数字同上。

最终我们可以统计到每个数字的每一位为1的概率形成一个10*49的二维数组,即10个数字,每个数字49位。然后我们取一个测试用例,依次与10个数字进行计算概率,最后得到的概率比较大小,那么我们如何去计算测试用例是某个数字的概率呢?下面我们把49位简单的看成3位,假如数字0的第一、二、三位为1的概率是0.56、0.05、0.41,而测试用例的数据字符串为101,那么我们取为1的概率直接乘,为0的用1减去这个概率,再乘起来,也就是0.56*0.95*0.41。到这里就差不多使我们的所有思路了。
其他的思路解释看上次的文章,链接 C++编程模板匹配超详细的识别手写数字实现示例
下面是我的代码,首先opencv得自己安装,这里我给一个链接,可以参照上的步骤来
Window系统下Python如何安装OpenCV库
另外,我的Bayes这个函数太长了,应该分成几个函数的,这样会更好调试和阅读
详细的代码解释都在注释里,仔细的看看理解就好了,如果有更好的方法和思路,欢迎交流学习!
#include<iostream>
#include<fstream>
#include<opencv2/opencv.hpp>
#include<opencv2/highgui.hpp>
#include<opencv2/core.hpp>
#include<io.h> //api和结构体
#include<string.h>
#include<string>
#include<sstream> //string 转 int 数据类型包含
using namespace std;
using namespace cv;
void ergodicTest(string filename, string name); //遍历函数
string Image_Compression(string imgpath); //压缩图片并返回字符串
void Bayes(); //贝叶斯分类器
int turn(char a);
void main()
{
const char* filepath = "E:\\learn\\vsfile\\c++project\\pictureData\\train-images";
ergodicTest(filepath, "train_num.txt"); //处理训练集
const char* test_path = "E:\\learn\\vsfile\\c++project\\pictureData\\test-images";
ergodicTest(test_path, "test_num.txt");
Bayes();
}
void ergodicTest(string filename, string name) //遍历并把路径存到files
{
string firstfilename = filename + "\\*.bmp";
struct _finddata_t fileinfo;
intptr_t handle; //不能用long,因为精度问题会导致访问冲突,longlong也可
string rout = "E:\\learn\\vsfile\\c++project\\pictureData\\" + name;
ofstream file;
file.open(rout, ios::out);
handle = _findfirst(firstfilename.c_str(), &fileinfo);
if (_findfirst(firstfilename.c_str(), &fileinfo) != -1)
{
do
{
file << fileinfo.name<<":"<< Image_Compression(filename + "\\" + fileinfo.name) << endl;
} while (!_findnext(handle, &fileinfo));
file.close();
_findclose(handle);
}
}
string Image_Compression(string imgpath) //输入图片地址返回图片二值像素字符
{
Mat Image = imread(imgpath); //输入的图片
cvtColor(Image, Image, COLOR_BGR2GRAY);
int Matrix[28][28]; //将digitization转化为字符串类型
for (int row = 0; row < Image.rows; row++) //把图片的像素点传给数组
for (int col = 0; col < Image.cols; col++)
{
Matrix[row][col] = Image.at<uchar>(row, col);
}
string img_str = ""; //用来存储结果字符串
int x = 0, y = 0;
for (int k = 1; k < 50; k++)
{
int total = 0;
for (int q = 0; q < 4; q++)
for (int p = 0; p < 4; p++)
if (Matrix[x + q][y + p] > 127) total += 1;
y = (y + 4) % 28;
if (total >= 6) img_str += '1'; //将28*28的图片转化为7*7即压缩
else img_str += '0';
if (k % 7 == 0)
{
x += 4;
y = 0;
}
}
return img_str;
}
int turn(char a) //这个函数是把string类型转换成int类型
{
stringstream str;
int f = 1;
str << a;
str >> f;
str.clear();
return f;
}
void Bayes()
{
ifstream data_test, data_train; //从两个数据字符串文件中取数据的文件流
string temp; //中间暂存字符串的变量
double count[10] = { 0 }; //用来计数每个数字样本1个数
double probability[10][49] = { 0 };
int t = 0; //避免算数溢出
for (int i = 0; i < 49; i++) //按列处理训练样本(每一个样本数据长度位49位)
{
data_train.open("E:\\learn\\vsfile\\c++project\\pictureData\\train_num.txt");
for (int j = 0; j < 1000; j++) //按顺序取一千次数据
{
getline(data_train, temp); //顺序取每一行数据
if (temp.length() == 57) //本来长度是49,因为我有文件名所以要跳过文件名
{
t = i + 8; //用t来代替i+8是因为string的[]中没有+-重载,好像是这样
if (turn(temp[t]) == 1) count[turn(temp[0])]++; //相应数字为1计数加1
else continue;
}
else if(temp.length() == 58)
{
t = i + 9; //有的文件名为8位有的为9位
if (turn(temp[t]) == 1) count[turn(temp[0])]++; //相应数字
else continue;
}
}
data_train.close(); //一定要注意文件流打开和关闭的时机,打开和关闭一次之间是一次完整的遍历(getline)
for (int q = 0; q < 10; q++)
{
probability[q][i] =count[q] / 100.0; //计算每个数字数据样本的每一位1的概率
count[q] = 0;//循环还要使用count,所以要初始化
}
}
double probab[10] = { 1,1,1,1,1,1,1,1,1,1 }; //该数组是这个数字的概率(10个数字)
data_test.open("E:\\learn\\vsfile\\c++project\\pictureData\\test_num.txt");
double temp_prob = 0; //对比可能性的中间变量:概率
int temp_num = -1; //对比可能性的中间变量:数字
bool flag = true; //标志拒绝识别,假就拒绝
int num_r = 0, num_f = 0, num_t = 0; //分别表示拒绝,错误,正确
for (int d = 0; d < 200; d++) //200个测试样本
{
for (int o = 0; o < 10; o++) probab[o] = 1;//初始化概率数组,虽然前面有初始化,但是我们循环会多次使用,所以我们要每循环一次初始化一次
getline(data_test, temp);
for (int y = 0; y < 10; y++) //分别和每个数字得出一个概率,既该测试用例是这个数字的概率
{
for (int s = 0; s < 49; s++) //49位对应去累乘得到概率
{
if (temp.length() == 57)
{
t = s + 8;
if (turn(temp[t]) == 1) probab[y] *=1+probability[y][s]; //加1是因为零点几越乘越小,不好比较,而且有的概率可能为0,
else probab[y] *= 2 - probability[y][s]; //同样的,为0的概率也要加上1
}
else
{
t = s + 9;
if (turn(temp[t]) == 1) probab[y] *=1+probability[y][s]; //相应数字
else probab[y] *= (2 - probability[y][s]);
}
}
}
flag = true; //标志置位真
temp_prob = 0; //重置中间变量
temp_num = -1; //开始前不标识为任何数值
for (int l = 0; l < 10; l++) //比较测试用例是某个数字的概率,确定最大的那个
{
if (probab[l] > temp_prob)
{
temp_prob = probab[l];
temp_num = l;
flag = true; //不被拒绝
}
else if (probab[l] == temp_prob )
{
flag = false; //拒绝识别
}
}
if (!flag)
{
num_r++;
}
else
{
cout << temp[0] << " " << temp_num << endl;
if (temp_num == turn(temp[0]))
{
cout << "识别为:" << temp_num << endl;
num_t++;
}
else
{
cout << "识别错误!" << endl;
num_f++;
}
}
}
data_test.close();
cout << "拒绝识别率为:" << num_r / 200.0 << endl;
cout << "正确识别率为:" << num_t / 200.0 << endl;
cout << "错误识别率为:" << num_f / 200.0 << endl;
}
注意,我的代码用的样本图片都是处理好的二值bmp图片,另外代码里的txt文档需要手动建,伙伴们可以自行修改,添加创建文本的语句。
每日一遍:好好学习,天天向上!
以上就是C++学习贝叶斯分类器实现手写数字识别示例解析的详细内容,更多关于实现手写数字识别的资料请关注我们其它相关文章!
相关推荐
-
基于TensorFlow的CNN实现Mnist手写数字识别
本文实例为大家分享了基于TensorFlow的CNN实现Mnist手写数字识别的具体代码,供大家参考,具体内容如下 一.CNN模型结构 输入层:Mnist数据集(28*28) 第一层卷积:感受视野5*5,步长为1,卷积核:32个 第一层池化:池化视野2*2,步长为2 第二层卷积:感受视野5*5,步长为1,卷积核:64个 第二层池化:池化视野2*2,步长为2 全连接层:设置1024个神经元 输出层:0~9十个数字类别 二.代码实现 import tensorflow as tf #Tensorfl
-

C++编程模板匹配超详细的识别手写数字实现示例
首先,本篇文章用到的方法是模板匹配,而不是基于神经网络的,还请各位注意了!(模板匹配还请自行了解,站上有很多介绍)我刚开始做实验的时候只有一点c++基础,对于文件和opencv我一点都不了解,所以导致了我刚开始迷茫了很久,直到后来才渐渐做起来.废话不多说,让我们开始吧! 过程很简单,如下: 匹配成功:存在一个最小距离(这些距离相等),且为一个数字:存在多个最小距离,且为同一个数字. 拒绝识别:存在多个最小距离,且为不同数字. 识别错误:存在一个最小距离,但与被测数字不是相同的数字. 也许乍一看看
-
kaggle+mnist实现手写字体识别
现在的许多手写字体识别代码都是基于已有的mnist手写字体数据集进行的,而kaggle需要用到网站上给出的数据集并生成测试集的输出用于提交.这里选择keras搭建卷积网络进行识别,可以直接生成测试集的结果,最终结果识别率大概97%左右的样子. # -*- coding: utf-8 -*- """ Created on Tue Jun 6 19:07:10 2017 @author: Administrator """ from keras.mo
-
C++学习贝叶斯分类器实现手写数字识别示例解析
大家好啊!这次的文章是上一个文章的后续,与上一次不同的是,这一次对数字识别采用的是贝叶斯(Bayes)分类器.贝叶斯在概率论与数理统计这门课讲过,下面我们简单了解一下: 首先,贝叶斯公式是 具体的解释就不说了,我们说一说把贝叶斯用在数字识别的什么位置.除了识别部分,其他的包括遍历文件夹和图片数字化都不变:0到9共十个数,所以分母有十项,P(Bj)(j是下标)相应的是0到9,则每一个的概率是1/10,分子上的P(Bi)是取到0到9中的一个,所以概率也是1/10. (小伙伴如果看不明白建议去看看贝叶
-
PyTorch CNN实战之MNIST手写数字识别示例
简介 卷积神经网络(Convolutional Neural Network, CNN)是深度学习技术中极具代表的网络结构之一,在图像处理领域取得了很大的成功,在国际标准的ImageNet数据集上,许多成功的模型都是基于CNN的. 卷积神经网络CNN的结构一般包含这几个层: 输入层:用于数据的输入 卷积层:使用卷积核进行特征提取和特征映射 激励层:由于卷积也是一种线性运算,因此需要增加非线性映射 池化层:进行下采样,对特征图稀疏处理,减少数据运算量. 全连接层:通常在CNN的尾部进行重新拟合,减
-
Python tensorflow实现mnist手写数字识别示例【非卷积与卷积实现】
本文实例讲述了Python tensorflow实现mnist手写数字识别.分享给大家供大家参考,具体如下: 非卷积实现 import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data data_path = 'F:\CNN\data\mnist' mnist_data = input_data.read_data_sets(data_path,one_hot=True) #offline da
-
基于Tensorflow的MNIST手写数字识别分类
本文实例为大家分享了基于Tensorflow的MNIST手写数字识别分类的具体实现代码,供大家参考,具体内容如下 代码如下: import tensorflow as tf import numpy as np from tensorflow.examples.tutorials.mnist import input_data from tensorflow.contrib.tensorboard.plugins import projector import time IMAGE_PIXELS
-
PyTorch实现手写数字识别的示例代码
目录 加载手写数字的数据 数据加载器(分批加载) 建立模型 模型训练 测试集抽取数据,查看预测结果 计算模型精度 自己手写数字进行预测 加载手写数字的数据 组成训练集和测试集,这里已经下载好了,所以download为False import torchvision # 是否支持gpu运算 # device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # print(device) # print(torch.cud
-
PyTorch实现MNIST数据集手写数字识别详情
目录 一.PyTorch是什么? 二.程序示例 1.引入必要库 2.下载数据集 3.加载数据集 4.搭建CNN模型并实例化 5.交叉熵损失函数损失函数及SGD算法优化器 6.训练函数 7.测试函数 8.运行 三.总结 前言: 本篇文章基于卷积神经网络CNN,使用PyTorch实现MNIST数据集手写数字识别. 一.PyTorch是什么? PyTorch 是一个 Torch7 团队开源的 Python 优先的深度学习框架,提供两个高级功能: 强大的 GPU 加速 Tensor 计算(类似 nump
-
机器学习python实战之手写数字识别
看了上一篇内容之后,相信对K近邻算法有了一个清晰的认识,今天的内容--手写数字识别是对上一篇内容的延续,这里也是为了自己能更熟练的掌握k-NN算法. 我们有大约2000个训练样本和1000个左右测试样本,训练样本所在的文件夹是trainingDigits,测试样本所在的文件夹是testDigits.文本文件中是0~9的数字,但是是用二值图表示出来的,如图.我们要做的就是使用训练样本训练模型,并用测试样本来检测模型的性能. 首先,我们需要将文本文件中的内容转化为向量,因为图片大小是32*32,所以
-
python实现基于SVM手写数字识别功能
本文实例为大家分享了SVM手写数字识别功能的具体代码,供大家参考,具体内容如下 1.SVM手写数字识别 识别步骤: (1)样本图像的准备. (2)图像尺寸标准化:将图像大小都标准化为8*8大小. (3)读取未知样本图像,提取图像特征,生成图像特征组. (4)将未知测试样本图像特征组送入SVM进行测试,将测试的结果输出. 识别代码: #!/usr/bin/env python import numpy as np import mlpy import cv2 print 'loading ...'
-
详解PyTorch手写数字识别(MNIST数据集)
MNIST 手写数字识别是一个比较简单的入门项目,相当于深度学习中的 Hello World,可以让我们快速了解构建神经网络的大致过程.虽然网上的案例比较多,但还是要自己实现一遍.代码采用 PyTorch 1.0 编写并运行. 导入相关库 import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torchvision import datasets, t
-
Python(TensorFlow框架)实现手写数字识别系统的方法
手写数字识别算法的设计与实现 本文使用python基于TensorFlow设计手写数字识别算法,并编程实现GUI界面,构建手写数字识别系统.这是本人的本科毕业论文课题,当然,这个也是机器学习的基本问题.本博文不会以论文的形式展现,而是以编程实战完成机器学习项目的角度去描述. 项目要求:本文主要解决的问题是手写数字识别,最终要完成一个识别系统. 设计识别率高的算法,实现快速识别的系统. 1 LeNet-5模型的介绍 本文实现手写数字识别,使用的是卷积神经网络,建模思想来自LeNet-5,如下图所示