KubeSphere分级管理实践及解析
目录
- 前言
- 为什么要在 KuberSphere 上实现分级管理
- 什么是分级体系
- 如何实现分级管理
- 如何实现资源的升降级
- 不同层级间 Pod 的网络隔离
- 总结
前言
K8s 是容器编排和分布式应用部署领域的领导者,在 K8s 环境中,我们只需要关心应用的业务逻辑,减轻了我们服务器网络以及存储等方面的管理负担。对于一个用户而言,K8s 是一个很复杂的容器编排平台,学习成本非常高。KubeSphere 抽象了底层的 K8s,并进行了高度的产品化,构建了一个全栈的多租户容器云平台,为用户提供了一个健壮、安全、功能丰富、具备极致体验的 Web 控制台,解决了 K8s 使用门槛高和云原生生态工具庞杂等痛点,使我们可以专注于业务的快速迭代,其多维度的数据监控,对于问题的定位,提供了很大的帮助。
为什么要在 KuberSphere 上实现分级管理
在 KubeSphere 中,资源可以在租户之间共享,根据分配的不同角色,可以对各种资源进行操作。租户与资源之间、资源与资源之间的自由度很高,权限粒度也比较大。在我们的系统中,资源是有权限等级的,像是低等级用户可以通过邀请、赋予权限等操作来操作高等级资源,或者像是低等级项目中的 Pod 可以调度到高等级的节点上,对资源。诸如此类跨等级操作资源等问题,我们在 KubeSphere 基础上来实现了分级管理。
什么是分级体系
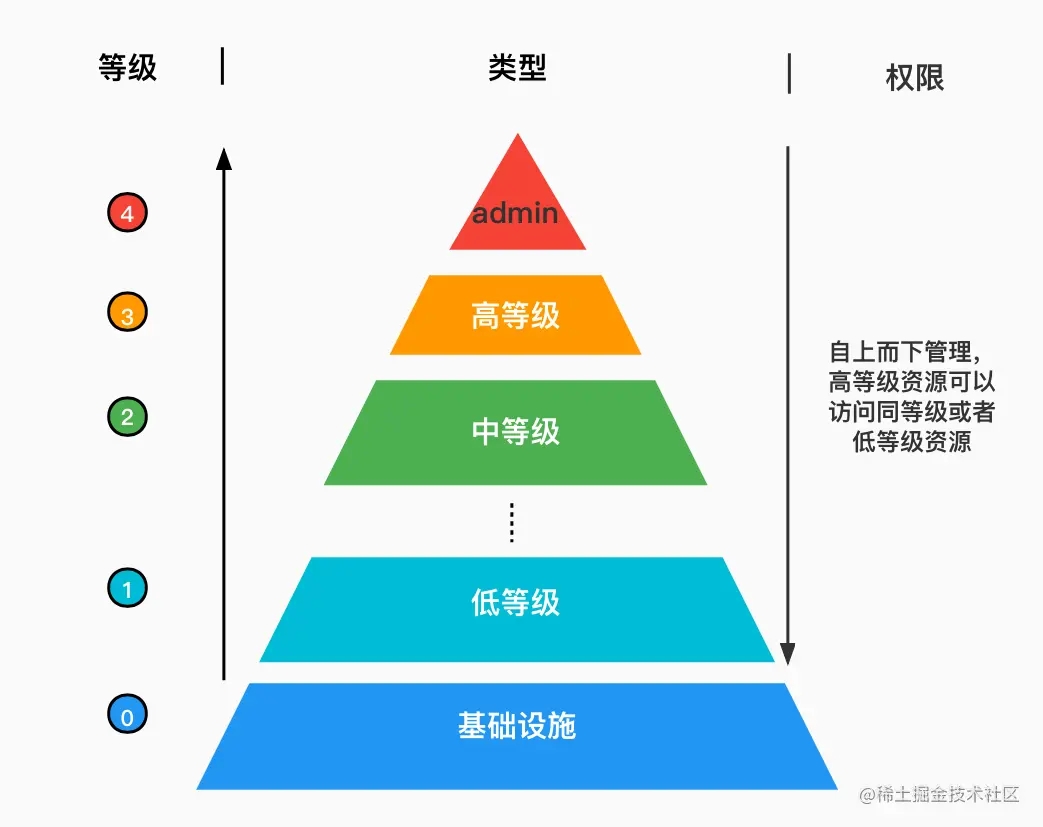
分级,顾名思义就是按照既定的标准对整体进行分解、分类。我们将其抽象成一个金字塔模型,从地基到塔顶会有很多个层级,我们将公共资源作为金字塔的地基,拥有最高权限的 admin 作为塔顶,其他资源按照权限等级划分成不同等级。低层级资源是不能访问高等级资源,高等级资源可以获取它等级之下的所有资源,构建了这样一个权益递减、层级间隔离的分级体系。
如何实现分级管理
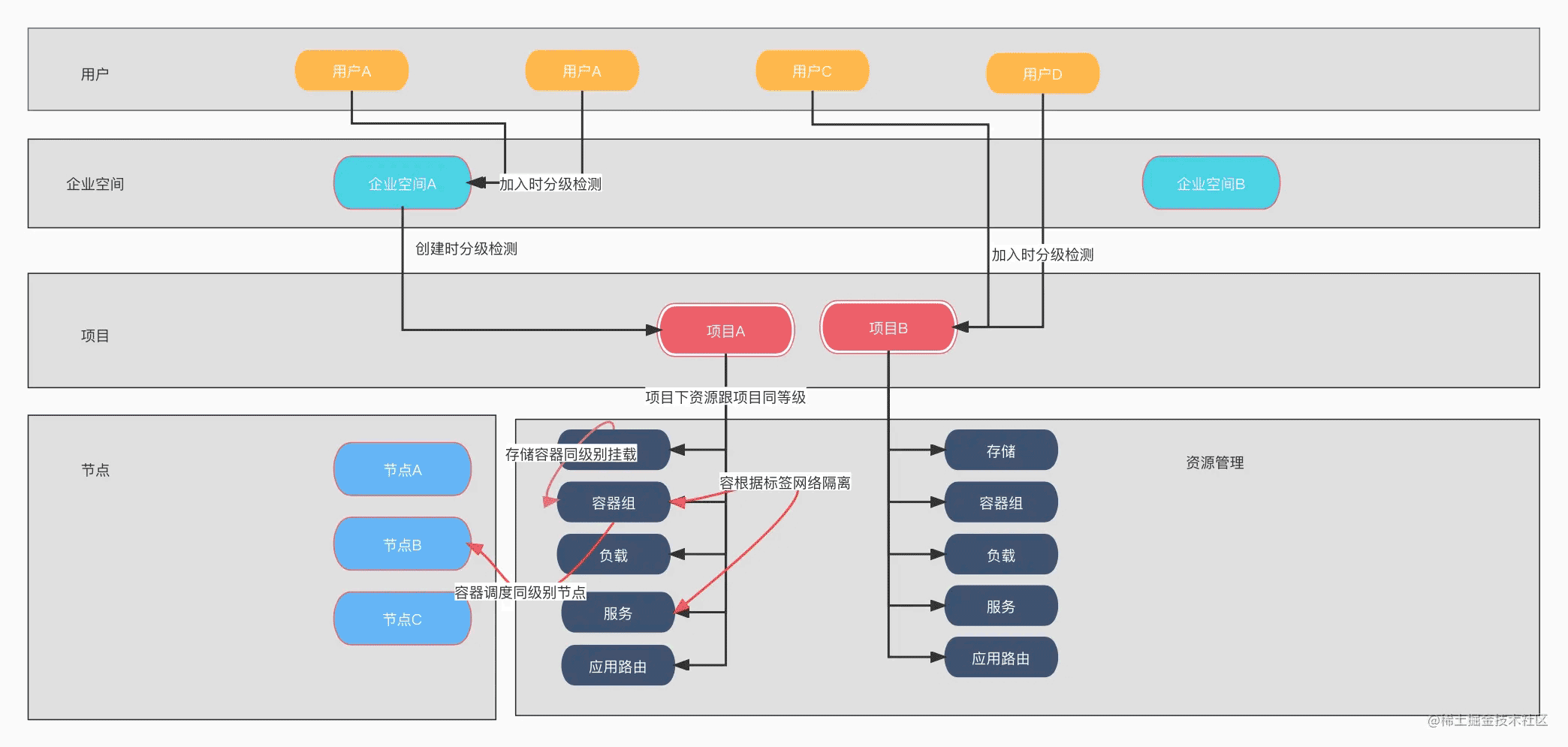
我们定义了一个代表等级的标签 kubernetes.io/level。以一个多节点的集群为例,首先我们会给用户、企业空间、节点等资源打上代表等级的标签。在邀请用户加入企业空间或者项目时,要求加入的企业空间或者项目的等级不得高于用户的等级,同样项目在绑定企业空间时,也要求项目的等级不得高于企业空间的等级,才能对资源进行纳管;我们认为同一项目下的资源的等级是相同的,基于项目创建的负载、Pod、服务等资源的等级跟项目保持一致;同时 Pod 中加入节点亲和性,以使 Pod 调度到不高于其权限等级的节点上。
例如这里,我们创建了一个权限等级是 3 的用户 demo-user,他可以加入权限等级不高于3的企业空间或者项目中。
kind: User
apiVersion: iam.kubesphere.io/v1alpha2
metadata:
name: demo-user
labels:
kubernetes.io/level: 3
spec:
email: demo-user@kubesphere.io
创建一个权限等级是 2 的项目 demo-ns,那么基于项目创建的负载、Pod、存储等资源的权限等级也是 2。
apiVersion: v1
kind: Namespace
metadata:
name: demo-ns
labels:
kubernetes.io/level: 2
基于 demo-ns 项目创建了一个nginx 的 Pod,他的权限等级也是 2,同时加入节点亲和性,要求其调度到权限等级不高于 2 的节点上。
apiVersion: apps/v1
kind: Pod
metadata:
labels:
kubernetes.io/level: 2
name: nginx
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
protocol: TCP
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/level
operator: Lt
values:
- 2
- matchExpressions:
- key: kubernetes.io/level
operator: In
values:
- 2
如何实现资源的升降级
在分级管理体系中,支持等级的无限划分,只需要定义一个中间值,就可以在两个等级之间插入一个新的等级,无需操作其他资源;在对资源进行升降级时,只需要修改对应资源的 label 标签,就可以对资源进行升降级操作。当然,在对资源进行升降级的时候,我们需要对资源进行检测,保证升级时,其上层资源的权限等级不得低于目标等级;同时,降级时,其下层资源的权限等级不得高于目标等级。在不满足升降级操作条件时,需要将对应资源也做相应调整才可以。

不同层级间 Pod 的网络隔离
在分级体系中,我们要求高等级的 Pod 能访问低等级的 Pod,但是低等级的 Pod 不能访问高等级的 Pod,那我们需要如何保证不同层级间 Pod 的网络通信呢。
项目在不开启网络隔离的情况下,Pod 间的网络是互通的,所以这里会新增一个黑名单的网络策略。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: deny-all
namespace: demo-ns
labels:
kubernetes.io/level: 2
spec:
podSelector: {}
policyTypes:
- Ingress
podSelector:{} 作用于项目中所有 Pod,阻止所有流量的流入。
然后放行标签等级大于目标等级(这里是 2)的流量流入(我们对 Ingress 流量没有做限制)。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: level-match-network-policy
namespace: demo-ns
labels:
kubernetes.io/level: 2
spec:
podSelector:
matchExpressions:
- key: kubernetes.io/level
operator: Gt
values:
- 2
policyTypes:
- Ingress
总结
KubeSphere 解决了用户构建、部署、管理和可观测性等方面的痛点,它的资源可以在多个租户之间共享。但是在资源有权限等级的场景中,低等级资源可以操作高等级资源,造成资源越权管理的问题。为解决这一问题,我们在 KubeSphere 的基础上进行了改造,以适应租户与资源之间和资源与资源之间的分级管理,同时在项目的网络策略中,增加黑名单和白名单策略,增强了项目间的网络隔离,让资源的管理更安全。
以上就是KubeSphere分级管理实践及解析的详细内容,更多关于KubeSphere分级管理实践的资料请关注我们其它相关文章!
相关推荐
-
通过kubesphere部署redis的方法
docker部署redis命令 docker run --name redis -p 6379:6379 -d --restart=always a4d3716dbb72 redis-server --appendonly yes --requirepass "123456" 创建配置,点击配置中心->配置->创建配置 这里的配置信息就和上面redis-server后面的一样 创建存储卷 创建redis服务 选择无状态服务,因为有状态服务不能对外暴露端口,只有无状态服务才可
-
KubeSphere中部署Wiki系统wiki.js并启用中文全文检索
目录 背景 准备 storageclass 部署 PostgreSQL 数据库 准备用户名密码配置 准备数据库初始化脚本 准备存储 部署 PostgreSQL 数据库 创建供其他 Pod 访问的 Service 完成 PostgreSQL 部署 部署 wiki.js 准备用户名密码配置 准备数据库连接配置 创建数据库用户和数据库 准备 wiki.js 的 yaml 部署文件 创建集群内访问 wiki.js 的 Service 创建集群外访问的 Ingress 执行部署 配置 wiki.js 支持
-

KubeSphere分级管理实践及解析
目录 前言 为什么要在 KuberSphere 上实现分级管理 什么是分级体系 如何实现分级管理 如何实现资源的升降级 不同层级间 Pod 的网络隔离 总结 前言 K8s 是容器编排和分布式应用部署领域的领导者,在 K8s 环境中,我们只需要关心应用的业务逻辑,减轻了我们服务器网络以及存储等方面的管理负担.对于一个用户而言,K8s 是一个很复杂的容器编排平台,学习成本非常高.KubeSphere 抽象了底层的 K8s,并进行了高度的产品化,构建了一个全栈的多租户容器云平台,为用户提供了一个健壮.
-
Dubbo扩展点SPI实践示例解析
目录 正文 扩展点配置: 扩展实现类: 拦截配置文件: 调用拦截扩展: 拦截扩展说明: 常用约定: 实现细节: 扩展点的几个特点: 扩展点自动包装 扩展点自动装配 扩展点自适应 扩展点自动激活 正文 Dubbo的扩展点加载从JDK标准的SPI(Service Provider Interface)扩展点发现机制加强而来.Dubbo改进了JDK标准的SPI的以下问题: JDK标准的SPI会一次性实例化扩展点所有实现,如果有扩展实现初始化很耗时,但如果没用上也加载,会很浪费资源.如果扩展点加载失败,
-
SpringBoot之webflux全面解析
目录 webflux介绍 webflux应用场景 SpringBoot2.0WebFlux 响应式编程 SpringWebflux springwebflux和springmvc的异同点 Nettyselector模型 Reactor指南 Java原有的异步编程方式 Reactor线程模型 webflux实践 webflux解析 总结 webflux介绍 Spring Boot 2.0 spring.io 官网有句醒目的话是: BUILD ANYTHING WITH SPRING BOOT Sp
-
Android ListView 单条刷新方法实践及原理解析
对于使用listView配合adapter进行刷新的方法大家都不陌生,先刷新adapter里的数据,然后调用notifydatasetchange通知listView刷新界面. 方法虽然简单,但这里面涉及到一个效率的问题,调用notifydatasetchange其实会导致adpter的getView方法被多次调用 (画面上能显示多少就会被调用多少次),如果是很明确的知道只更新了list中的某一个项的数据(比如用户点击list某一项后更新该项的显示状态,或者 后台回调更新list某一项,等等),
-
React服务端渲染原理解析与实践
关于服务端渲染也就是我们说的SSR大多数人都听过这个概念,很多同学或许在公司中已经做过服务端渲染的项目了,主流的单页面应用比如说Vue或者React开发的项目采用的一般都是客户端渲染的模式也就是我们说的CSR. 但是这种模式会带来明显的两个问题,第一个就是TTFP时间比较长,TTFP指的就是首屏展示时间,同时不具备SEO排名的条件,搜索引擎上排名不是很好.所以我们可以借助一些工具来进行改良我们的项目,将单页面应用编程服务器端渲染项目,这样就可以解决掉这些问题了. 目前主流的服务器端渲染框架也就是
-
三种Java自定义DNS解析器方法与实践
目录 1.InMemoryDnsResolver 2.SystemDefaultDnsResolver 3.自定义DnsResolver 4.连接池管理器 5.测试 前言: 最近终于用上了高性能的测试机(54C96G * 3),相较之前的单机性能提升了三倍,数量提升了三倍,更关键的宽带提单机升了30倍不止,总体讲提升了100多倍,这下再也不用担心单机压力机瓶颈,直接原地起飞. 不过没高兴5分钟,我发现接口居然请求不通,经过一阵拨乱反正终于找到原因:域名无法解析,IP无法直接访问. 自然而然,解决
-
Apache Hudi结合Flink的亿级数据入湖实践解析
目录 1. 实时数据落地需求演进 2. 基于Spark+Hudi的实时数据落地应用实践 3. 基于Flink自定义实时数据落地实践 4. 基于Flink + Hudi的落地数据实践 5. 后续应用规划及展望 5.1 取代离线报表,提高报表实时性及稳定性 5.2 完善监控体系,提升落数据任务稳定性 5.3 落数据中间过程可视化探索 本次分享分为5个部分介绍Apache Hudi的应用与实践 1. 实时数据落地需求演进 实时平台上线后,主要需求是开发实时报表,即抽取各类数据源做实时etl后,吐出实时
-
OnZoom基于Apache Hudi的一体架构实践解析
1. 背景 OnZoom是Zoom新产品,是基于Zoom Meeting的一个独一无二的在线活动平台和市场.作为Zoom统一通信平台的延伸,OnZoom是一个综合性解决方案,为付费的Zoom用户提供创建.主持和盈利的活动,如健身课.音乐会.站立表演或即兴表演,以及Zoom会议平台上的音乐课程. 在OnZoom data platform中,source数据主要分为MySQL DB数据和Log数据. 其中Kafka数据通过Spark Streaming job实时消费,MySQL数据通过Spark
-
Java中Excel高效解析工具EasyExcel的实践
目录 简介 读 Execl 实践 写 Execl 实践 模板填充 文件追加 总结 参考资料:alibaba-easyexcel.github.io 简介 EasyExcel是一个基于Java的简单.省内存的读写Excel的开源项目.在尽可能节约内存的情况下支持读写百M的Excel. maven 依赖如下: <dependency> <groupId>com.alibaba</groupId> <artifactId>easyexcel</artifac
-
Golang实现Json分级解析及数字解析实践详解
目录 一.背景介绍 二.解决方案 (1)将Json直接解析为map (2)解析部分json struct的方法 (json.RawMessage的用法) (3) json.Number类型的使用 一.背景介绍 在go语言开发过程中经常需要将json字符串解析为struct,通常我们都是根据json的具体层级关系定义对应的struct,然后通过json.Unmarshal()命令实现json到struct对象的转换,然后再根据具体逻辑处理相应的数据. 你是否遇到过在无法准确确定json层级关系的情