Caffe卷积神经网络视觉层Vision Layers及参数详解
目录
- 引言
- 1、Convolution层:
- 2、Pooling层
- 3、Local Response Normalization (LRN)层
- 4、im2col层
引言
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe卷积神经网络数据层及参数
本文只讲解视觉层(Vision Layers)的参数,视觉层包括Convolution, Pooling,Local Response Normalization (LRN), im2col等层。
1、Convolution层:
就是卷积层,是卷积神经网络(CNN)的核心层。
层类型:Convolution
lr_mult: 学习率的系数,最终的学习率是这个数乘以solver.prototxt配置文件中的base_lr。
如果有两个lr_mult, 则第一个表示权值的学习率,第二个表示偏置项的学习率。一般偏置项的学习率是权值学习率的两倍。
在后面的convolution_param中,我们可以设定卷积层的特有参数。
必须设置的参数:
- num_output: 卷积核(filter)的个数
- kernel_size: 卷积核的大小。如果卷积核的长和宽不等,需要用kernel_h和kernel_w分别设定
其它参数:
- stride: 卷积核的步长,默认为1。也可以用stride_h和stride_w来设置。
- pad: 扩充边缘,默认为0,不扩充。 扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图就不会变小。也可以通过pad_h和pad_w来分别设定。
- weight_filler: 权值初始化。 默认为“constant",值全为0,很多时候我们用"xavier"算法来进行初始化,也可以设置为”gaussian"
- bias_filler: 偏置项的初始化。一般设置为"constant",值全为0。
- bias_term: 是否开启偏置项,默认为true, 开启
group: 分组,默认为1组。如果大于1,我们限制卷积的连接操作在一个子集内。如果我们根据图像的通道来分组,那么第i个输出分组只能与第i个输入分组进行连接。
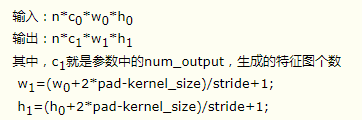
如果设置stride为1,前后两次卷积部分存在重叠。如果设置pad=(kernel_size-1)/2,则运算后,宽度和高度不变。
示例:
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
2、Pooling层
也叫池化层,为了减少运算量和数据维度而设置的一种层。
层类型:Pooling
必须设置的参数:
kernel_size: 池化的核大小。也可以用kernel_h和kernel_w分别设定。
其它参数:
- pool: 池化方法,默认为MAX。目前可用的方法有MAX, AVE, 或STOCHASTIC
- pad: 和卷积层的pad的一样,进行边缘扩充。默认为0
- stride: 池化的步长,默认为1。一般我们设置为2,即不重叠。也可以用stride_h和stride_w来设置。
示例:
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
pooling层的运算方法基本是和卷积层是一样的。

如果设置stride为2,前后两次卷积部分不重叠。100*100的特征图池化后,变成50*50.
3、Local Response Normalization (LRN)层
此层是对一个输入的局部区域进行归一化,达到“侧抑制”的效果。可去搜索AlexNet或GoogLenet,里面就用到了这个功能
层类型:LRN
参数:全部为可选,没有必须
- local_size: 默认为5。如果是跨通道LRN,则表示求和的通道数;如果是在通道内LRN,则表示求和的正方形区域长度。
- alpha: 默认为1,归一化公式中的参数。
- beta: 默认为5,归一化公式中的参数。
- norm_region: 默认为ACROSS_CHANNELS。有两个选择,ACROSS_CHANNELS表示在相邻的通道间求和归一化。WITHIN_CHANNEL表示在一个通道内部特定的区域内进行求和归一化。与前面的local_size参数对应。
归一化公式:对于每一个输入, 去除以
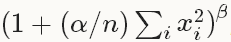
得到归一化后的输出
示例:
layers {
name: "norm1"
type: LRN
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
4、im2col层
如果对matlab比较熟悉的话,就应该知道im2col是什么意思。它先将一个大矩阵,重叠地划分为多个子矩阵,对每个子矩阵序列化成向量,最后得到另外一个矩阵。
看一看图就知道了:
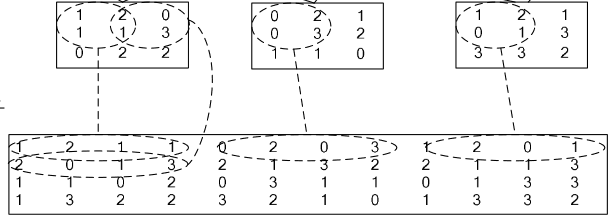
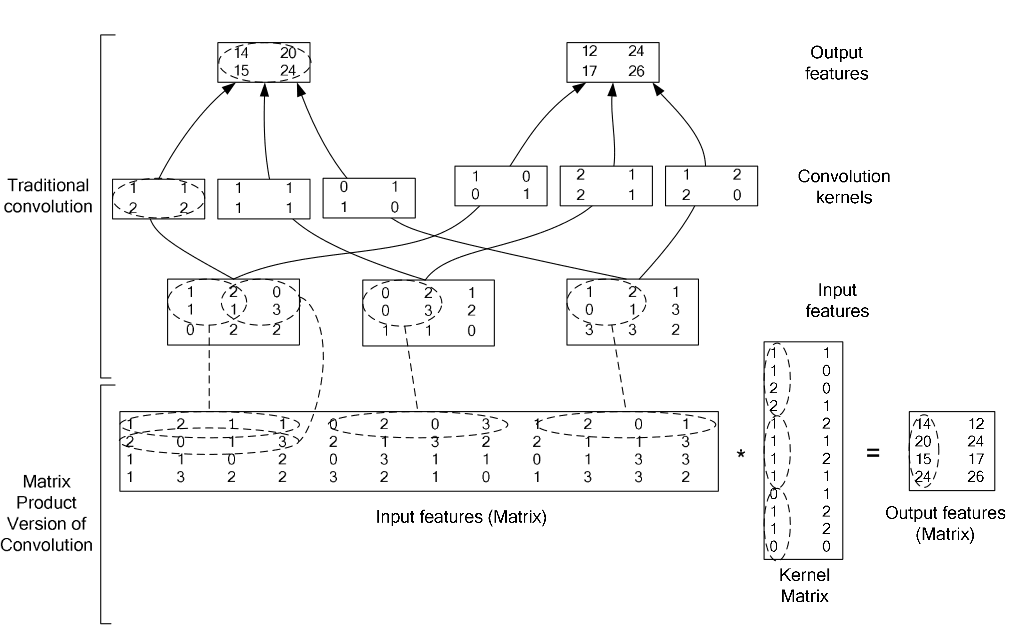
在caffe中,卷积运算就是先对数据进行im2col操作,再进行内积运算(inner product)。这样做,比原始的卷积操作速度更快。
看看两种卷积操作的异同:
以上就是Caffe卷积神经网络视觉层Vision Layers及参数详解的详细内容,更多关于Caffe视觉层Vision Layers的资料请关注我们其它相关文章!
相关推荐
-

Caffe数据可视化环境python接口配置教程示例
目录 引言 一.安装python和pip 二.安装pyhon接口依赖库 三.利用anaconda来配置python环境 四.编译python接口 五.安装jupyter 引言 caffe程序是由c++语言写的,本身是不带数据可视化功能的.只能借助其它的库或接口,如opencv, python或matlab.大部分人使用python接口来进行可视化,因为python出了个比较强大的东西:ipython notebook, 现在的最新版本改名叫jupyter notebook,它能将python代码
-
Caffe卷积神经网络数据层及参数
目录 引言 数据层 1.数据来自于数据库(如LevelDB和LMDB) 2.数据来自于内存 3.数据来自于HDF5 4.数据来自于图片 5.数据来源于Windows 引言 要运行caffe,需要先创建一个模型(model),如比较常用的Lenet,Alex等, 而一个模型由多个屋(layer)构成,每一屋又由许多参数组成.所有的参数都定义在caffe.proto这个文件中.要熟练使用caffe,最重要的就是学会配置文件(prototxt)的编写. 层有很多种类型,比如Data,Convoluti
-
Caffe图像数据转换成可运行leveldb lmdb文件
目录 引言 该文件的使用格式 调用linux命令生成图片清单 FLAGS参数组 最后运行脚本文件 引言 在深度学习的实际应用中,我们经常用到的原始数据是图片文件,如jpg,jpeg,png,tif等格式的,而且有可能图片的大小还不一致. 而在caffe中经常使用的数据类型是lmdb或leveldb,因此就产生了这样的一个问题:如何从原始图片文件转换成caffe中能够运行的db(leveldb/lmdb)文件? 在caffe中,作者为我们提供了这样一个文件:convert_imageset.cpp
-
caffe的python接口生成solver文件详解学习
目录 solver.prototxt的文件参数设置 生成solver文件 简便的方法 训练模型(training) solver.prototxt的文件参数设置 caffe在训练的时候,需要一些参数设置,我们一般将这些参数设置在一个叫solver.prototxt的文件里面,如下: base_lr: 0.001display: 782gamma: 0.1lr_policy: “step”max_iter: 78200momentum: 0.9snapshot: 7820snapshot_pref
-
python格式的Caffe图片数据均值计算学习
目录 引言 一.二进制格式的均值计算 二.python格式的均值计算 引言 图片减去均值后,再进行训练和测试,会提高速度和精度.因此,一般在各种模型中都会有这个操作. 那么这个均值怎么来的呢,实际上就是计算所有训练样本的平均值,计算出来后,保存为一个均值文件,在以后的测试中,就可以直接使用这个均值来相减,而不需要对测试图片重新计算. 一.二进制格式的均值计算 caffe中使用的均值数据格式是binaryproto, 作者为我们提供了一个计算均值的文件compute_image_mean.cpp,
-
caffe的python接口之手写数字识别mnist实例
目录 引言 一.数据准备 二.导入caffe库,并设定文件路径 二.生成配置文件 三.生成参数文件solver 四.开始训练模型 五.完成的python文件 引言 深度学习的第一个实例一般都是mnist,只要这个例子完全弄懂了,其它的就是举一反三的事了.由于篇幅原因,本文不具体介绍配置文件里面每个参数的具体函义,如果想弄明白的,请参看我以前的博文: 数据层及参数 视觉层及参数 solver配置文件及参数 一.数据准备 官网提供的mnist数据并不是图片,但我们以后做的实际项目可能是图片.因此有些
-
Caffe卷积神经网络视觉层Vision Layers及参数详解
目录 引言 1.Convolution层: 2.Pooling层 3.Local Response Normalization (LRN)层 4.im2col层 引言 所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe卷积神经网络数据层及参数 本文只讲解视觉层(Vision Layers)的参数,视觉层包括Convolution, Pooling,Local Response Normalization (LRN
-
Caffe卷积神经网络solver及其配置详解
目录 引言 Solver的流程: 引言 solver算是caffe的核心的核心,它协调着整个模型的运作.caffe程序运行必带的一个参数就是solver配置文件.运行代码一般为 # caffe train --solver=*_slover.prototxt 在Deep Learning中,往往loss function是非凸的,没有解析解,我们需要通过优化方法来求解.solver的主要作用就是交替调用前向(forward)算法和后向(backward)算法来更新参数,从而最小化loss,实际上
-
python神经网络学习数据增强及预处理示例详解
目录 学习前言 处理长宽不同的图片 数据增强 1.在数据集内进行数据增强 2.在读取图片的时候数据增强 3.目标检测中的数据增强 学习前言 进行训练的话,如果直接用原图进行训练,也是可以的(就如我们最喜欢Mnist手写体),但是大部分图片长和宽不一样,直接resize的话容易出问题. 除去resize的问题外,有些时候数据不足该怎么办呢,当然要用到数据增强啦. 这篇文章就是记录我最近收集的一些数据预处理的方式 处理长宽不同的图片 对于很多分类.目标检测算法,输入的图片长宽是一样的,如224,22
-
业务层hooks封装useSessionStorage实例详解
目录 封装原因: 建议: 工具库封装模式: 工具库目录: API设计: 代码实践: Hooks设计方式 useSessionStorage.js 简介: 注意点 Api Params Options Result 总结: 封装原因: 名称:useSessionStorage 功能开发过程中,需要进行数据的临时存储,正常情况下,使用localStorage或者 sessionStorage,存在于 window 对象中,使用场景不一样. sessionStorage的生命周期是在浏览器关闭前,浏览
-
Python使用循环神经网络解决文本分类问题的方法详解
本文实例讲述了Python使用循环神经网络解决文本分类问题的方法.分享给大家供大家参考,具体如下: 1.概念 1.1.循环神经网络 循环神经网络(Recurrent Neural Network, RNN)是一类以序列数据为输入,在序列的演进方向进行递归且所有节点(循环单元)按链式连接的递归神经网络. 卷积网络的输入只有输入数据X,而循环神经网络除了输入数据X之外,每一步的输出会作为下一步的输入,如此循环,并且每一次采用相同的激活函数和参数.在每次循环中,x0乘以系数U得到s0,再经过系数W输入
-
layer弹出层框架alert与msg详解
layer至今仍作为layui的代表作,她的受众广泛并非偶然,而是这五年多的坚持,不断完善和维护.不断建设和提升社区服务,使得猿们纷纷自发传播,乃至于成为今天的Layui最强劲的源动力.目前,layer已成为国内最多人使用的web弹层组件,GitHub自然Stars3000+,官网累计下载量达30w+,大概有20万Web平台正在使用layer. 在贴出代码 layer.alert('见到你真的很高兴', {icon: 6}); 这是一个最简单的弹出层,可根据icon配置左边的图标 通常情况下,除
-
layer实现关闭弹出层刷新父界面功能详解
本文实例讲述了layer实现关闭弹出层刷新父界面功能.分享给大家供大家参考,具体如下: layer是一款近年来备受青睐的web弹层组件,她具备全方位的解决方案,致力于服务各水平段的开发人员,您的页面会轻松地拥有丰富友好的操作体验. 最近一个项目采用的是hui前端框架,他的弹出层就是用的layer插件,对于弹出层,有一个操作体验大家都知道,就是关闭弹出层,需要刷新父页面.开始写的时候,我陷入了自己的误区,在弹出层处理成功之后,我调用的是: var index = parent.layer.getF
-
TensorFlow实现卷积神经网络
本文实例为大家分享了TensorFlow实现卷积神经网络的具体代码,供大家参考,具体内容如下 代码(源代码都有详细的注释)和数据集可以在github下载: # -*- coding: utf-8 -*- '''卷积神经网络测试MNIST数据''' #########导入MNIST数据######## from tensorflow.examples.tutorials.mnist import input_data import tensorflow as tf mnist = input_da
-
卷积神经网络经典模型及其改进点学习汇总
目录 经典神经网络的改进点 经典神经网络的结构汇总 1.VGG16 2.ResNet50 3.InceptionV3 4.Xception 5.MobileNet 经典神经网络的改进点 名称 改进点 VGG16 1.使用非常多的3*3卷积串联,利用小卷积代替大卷积,该操作使得其拥有更少的参数量,同时会比单独一个卷积层拥有更多的非线性变换.2.探索了卷积神经网络的深度与其性能之间的关系,成功构建16层网络(还有VGG19的19层网络). ResNet50 1.使用残差网络,其可以解决由于网络深度加