zookeeper集群搭建超详细过程
目录
- 一、准备三台虚拟机,并列出对应的IP地址和主机名,如下图所示
- 二、环境准备(下面的步骤每一台虚拟机都需要做!!)
- 1.关闭防火墙
- 2. 配置操作系统
- 3. 设置本机IP地址与MAC地址
- 三、安装与配置zookeeper
- 四、zookeeper集群测试
一、准备三台虚拟机,并列出对应的IP地址和主机名,如下图所示
| IP | Hostname |
| 192.168.154.133 | zookeeper1 |
| 192.168.154.134 | zookeeper2 |
| 192.168.154.135 | zookeeper3 |
备注:
- 可以在虚拟机中输入ifconfig查看虚拟机的ip(下图中圈住的部分即是IP地址)

在虚拟机分别对hostname进行命名
[root@localhost /]# hostnamectl set-hostname zookeeper1 //修改hostname [root@localhost /]# hostname //查看hostname

二、环境准备(下面的步骤每一台虚拟机都需要做!!)
1.关闭防火墙
[root@localhost /]# systemctl stop firewalld //停止firewalld防火墙 [root@localhost /]# systemctl disable firewalld //disable防火墙,使其开机不自启 [root@localhost /]# systemctl status firewalld //查看firewalld是否已经关闭,running:激活状态 dead:未激活状态
2. 配置操作系统
[root@localhost /]# vi /etc/sysconfig/selinux SELINUX=disabled //修改成disabled

3. 设置本机IP地址与MAC地址
[root@localhost /]# vi /etc/sysconfig/network-scripts/ifcfg-ens33 (也有部分是eth0,根据情况自行修改)
把下图中BOOTPROTO的值修改成static,然后在文末加上对应的IP地址与MAC地址等数据

IPADDR=192.168.154.133 //IP 哪台主机就设置对应的IP MACADDR=00:0C:29:36:97:20 NETMASK=255.255.255.0 //子网掩码 GATEWAY=192.168.154.2 //网关 DNS1=8.8.8.8 DNS2=114.114.114.114
网关和子网掩码查询地址:
进入VMware左上角编辑下的虚拟网络编辑器,选择NAT设置

就可以看到对应的网关和IP了

添加主机名与映射关系
vi /etc/hosts
三、安装与配置zookeeper
大家可以移步我的另外一篇文章,里面对于zookeeper的安装有着详细的说明Linux环境下zookeeper的安装教程(超详细!!)
https://www.jb51.net/article/149967.htm
安装完成之后,我们再来做进一步的配置:
1.添加环境变量
[root@localhost /]# vim /etc/profile
#zookeeper export ZK_HOME=/opt/module/zookeeper export PATH=$PATH:$ZK_HOME/bin
2.在原本的基础上对zookeeper/conf 中的zoo.cfg做进一步的修改
说明:2888为组成zookeeper服务器之间的通信端口,3888为用来选举leader的端口,server后面的数字与后面的myid相对应
server.1=192.168.154.133:2888:3888 server.2=192.168.154.134:2888:3888 server.3=192.168.154.135:2888:3888
3.进入zkData中,修改myid文件,此处要与zoo.cfg中的修改相对应


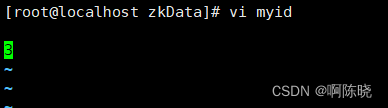
待三台虚拟机都配置完成后就可以开始开始测试了
四、zookeeper集群测试
启动各个服务器的zookeeper
[root@zookeeper1 bin]# ./zkServer.sh start //启动zookeeper服务器 [root@zookeeper1 bin]# ./zkServer.sh status //查看当前zookeeper的状态
如果正常启动的话,我们可以发现,因为选举机制,我们启动第一台和第二台时,都未能启动成功


当我们启动第三台时,出现选票超过半数,则此时我们再去看,zookeeper3成为了leader而zookeeper1和zookeeper2成为了follower



至此,zookeeper集群搭建成功!!
到此这篇关于zookeeper集群搭建超详细过程的文章就介绍到这了,更多相关zookeeper集群内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
ZooKeeper入门教程二在单机和集群环境下的安装搭建及使用
目录 1.下载 2.解压 3.创建配置文件 4.单机启动ZooKeeper 5.通过客户端连接ZooKeeper 6.通过客户端执行基本命令 7.集群配置和启动 小结: 通过本篇学习掌握zookeeper环境的搭建,为后续学习做好准备 1.下载 首先我们下载最新稳定版本的zookeeper https://www.jb51.net/softs/578345.html 2.解压 下载完成后,我们解开压缩包 3.创建配置文件 解压后的路径下找到conf文件夹,进入conf文件夹复制zoo_sampl
-
Hadoop+HBase+ZooKeeper分布式集群环境搭建步骤
目录 一.环境说明 2.1 安装JDK 2.2 添加Hosts映射关系 2.3 集群之间SSH无密码登陆 三.Hadoop集群安装配置 3.1 修改hadoop配置 3.2 启动hadoop集群 四.ZooKeeper集群安装配置 4.1 修改配置文件zoo.cfg 4.2 新建并编辑myid文件 4.3 启动ZooKeeper集群 五.HBase集群安装配置 5.1 hbase-env.sh 5.2 hbase-site.xml 5.3 更改 regionservers 5.4 分发并同步安装
-
基于 ZooKeeper 搭建 Hadoop 高可用集群 的教程图解
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求比 YARN ResourceManger 高得多,所以它的实现也更加复杂,故下面先进行讲解: 1.1 高可用整体架构 HDFS 高可用架构如下: 图片引用自: https://www.edureka.co/blog/how-to-set-up-hadoop-cluster-with-hdfs-hi
-
Zookeeper 单机环境和集群环境搭建
一.单机环境搭建# 1.1 下载# 下载对应版本 Zookeeper,这里我下载的版本 3.4.14.官方下载地址:https://archive.apache.org/dist/zookeeper/ # wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz 1.2 解压# # tar -zxvf zookeeper-3.4.14.tar.gz 1.3 配置环境变量# #
-

zookeeper集群搭建超详细过程
目录 一.准备三台虚拟机,并列出对应的IP地址和主机名,如下图所示 二.环境准备(下面的步骤每一台虚拟机都需要做!!) 1.关闭防火墙 2. 配置操作系统 3. 设置本机IP地址与MAC地址 三.安装与配置zookeeper 四.zookeeper集群测试 一.准备三台虚拟机,并列出对应的IP地址和主机名,如下图所示 IP Hostname 192.168.154.133 zookeeper1 192.168.154.134 zookeeper2 192.168.154.135 zookeepe
-
Apache Pulsar集群搭建部署详细过程
目录 一.集群组成说明 二.安装前置条件 三.ZooKeeper集群搭建 四.BookKeeper集群搭建 五.Broker集群搭建 六.docker安装pulsar-dashboard 一.集群组成说明 1.搭建Pulsar集群至少需要3个组件:ZooKeeper集群.BookKeeper集群和Broker集群(Broker是Pulsar的自身实例).这三个集群组件如下:ZooKeeper集群(3个ZooKeeper节点组成)Bookie集群(也称为BookKeeper集群,3个BookKee
-
部署k8s集群的超详细实践步骤
目录 1.部署k8s的两种方式: 2.环境准备 3.初始化配置 3.1.安装环境准备:下面的操作需要在所有的节点上执行. 3.2.安装 Docker.kubeadm.kubelet[所有节点] 4.部署k8s-master[master执行] 4.1.kubeadm部署(需要等上一会) 4.2.拷贝k8s认证文件 5.配置k8s的node节点[node节点操作] 5.1.向集群添加新节点,执行在kubeadm init输出的kubeadm join命令 6.部署容器网络 (master执行) 7
-
MGR集群搭建及配置过程
MGR全称MySQL Group Replication(Mysql组复制),是MySQL官方于2016年12月推出的一个全新的高可用与高扩展的解决方案.MGR提供了高可用.高扩展.高可靠的MySQL集群服务.在MGR出现之前,用户常见的MySQL高可用方式,无论怎么变化架构,本质就是Master-Slave架构.MySQL 5.7版本开始支持无损半同步复制(lossless semi-sync replication),从而进一步提示数据复制的强一致性. MGR是MySQL数据库未来发展的一个
-
Nacos集群搭建过程详解
目录 1.集群结构图 2.搭建集群 2.1.初始化数据库 2.2.下载nacos 2.3.配置Nacos 2.4.启动 2.5.nginx反向代理 2.6.优化 1.集群结构图 官方给出的Nacos集群图: 其中包含3个nacos节点,然后一个负载均衡器代理3个Nacos.这里负载均衡器可以使用nginx. 我们计划的集群结构: 三个nacos节点的地址: 节点 ip port nacos1 192.168.150.1 8845 nacos2 192.168.150.1 8846 nacos3
-
redis集群搭建过程(非常详细,适合新手)
目录 redis集群搭建 一.Redis Cluster(Redis集群)简介 二.集群搭建需要的环境 三.集群搭建具体步骤如下(注意要关闭防火墙) 四.结语 redis集群搭建 在开始redis集群搭建之前,我们先简单回顾一下redis单机版的搭建过程 下载redis压缩包,然后解压压缩文件: 进入到解压缩后的redis文件目录(此时可以看到Makefile文件),编译redis源文件: 把编译好的redis源文件安装到/usr/local/redis目录下,如果/local目录下没有redi
-
kubernetes集群搭建Zabbix监控平台的详细过程
目录 一.zabbix介绍 1.zabbix简介 2.zabbix特点 3.zabbix的主要功能 4.zabbix架构图 二.检查本地k8s环境 1.检查系统pod运行状态 2.检查node节点状态 三.配置nfs共享存储 1.安装nfs 2.创建共享目录 3.配置共享目录 4.启动相关服务 5.使配置生效 6.查看nfs 7.其他节点检查nfs共享 四.安装zabbix-mysql 1.编写zabbix-mysql的yaml文件 2.创建命名空间 3.创建zabbix数据库 4.检查pod状
-
使用IDEA搭建一个简单的SpringBoot项目超详细过程
一.创建项目 1.File->new->project: 2.选择"Spring Initializr",点击next:(jdk1.8默认即可) 3.完善项目信息,组名可不做修改,项目名可做修改:最终建的项目名为:test,src->main->java下包名会是:com->example->test:点击next: 4.Web下勾选Spring Web Start,(网上创建springboot项目多是勾选Web选项,而较高版本的Springboo
-
Elasticsearches的集群搭建及数据分片过程详解
目录 Elasticsearch高级之集群搭建,数据分片 广播方式 单播方式 选取主节点 什么是脑裂 错误识别 Elasticsearch高级之集群搭建,数据分片 es使用两种不同的方式来发现对方: 广播 单播 也可以同时使用两者,但默认的广播,单播需要已知节点列表来完成 广播方式 当es实例启动的时候,它发送了广播的ping请求到地址224.2.2.4:54328.而其他的es实例使用同样的集群名称响应了这个请求. 一般这个默认的集群名称就是上面的cluster_name对应的elastics
-
ZooKeeper集群操作及集群Master选举搭建启动
目录 ZooKeeper介绍 ZooKeeper特征 分层命名空间 搭建ZK集群 启动zk集群 zk集群master选举 ZooKeeper介绍 ZooKeeper 是一个为 分布式应用 提供的 分布式 .开源的 协调服务 . 它公开了一组简单的 原语 ,分布式应用程序可以根据这些原语来实现用于 同步 .配置维护 以及 命名 的更高级别的服务. 怎么理解协调服务呢?比如我们有很多应用程序,他们之间都需要读写维护一个 id ,那么这些 id 怎么命名呢,程序一多,必然会乱套,ZooKeeper 能