Python爬虫实战之使用Scrapy爬取豆瓣图片
使用Scrapy爬取豆瓣某影星的所有个人图片
以莫妮卡·贝鲁奇为例

1.首先我们在命令行进入到我们要创建的目录,输入 scrapy startproject banciyuan 创建scrapy项目
创建的项目结构如下

2.为了方便使用pycharm执行scrapy项目,新建main.py
from scrapy import cmdline
cmdline.execute("scrapy crawl banciyuan".split())
再edit configuration
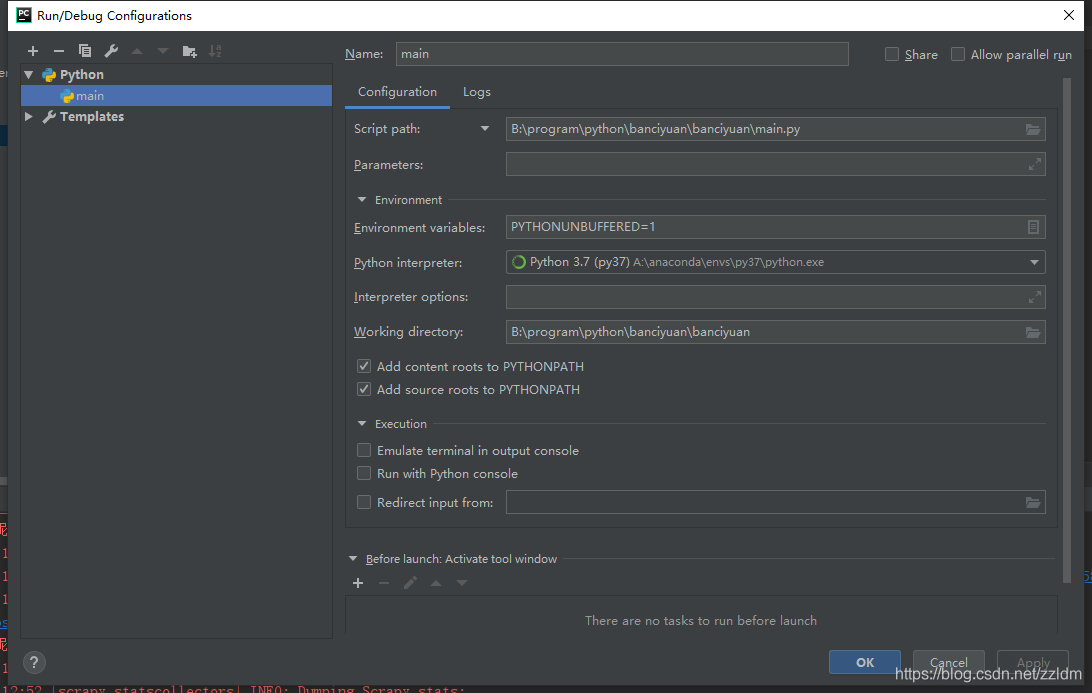
然后进行如下设置,设置后之后就能通过运行main.py运行scrapy项目了
3.分析该HTML页面,创建对应spider
from scrapy import Spider
import scrapy
from banciyuan.items import BanciyuanItem
class BanciyuanSpider(Spider):
name = 'banciyuan'
allowed_domains = ['movie.douban.com']
start_urls = ["https://movie.douban.com/celebrity/1025156/photos/"]
url = "https://movie.douban.com/celebrity/1025156/photos/"
def parse(self, response):
num = response.xpath('//div[@class="paginator"]/a[last()]/text()').extract_first('')
print(num)
for i in range(int(num)):
suffix = '?type=C&start=' + str(i * 30) + '&sortby=like&size=a&subtype=a'
yield scrapy.Request(url=self.url + suffix, callback=self.get_page)
def get_page(self, response):
href_list = response.xpath('//div[@class="article"]//div[@class="cover"]/a/@href').extract()
# print(href_list)
for href in href_list:
yield scrapy.Request(url=href, callback=self.get_info)
def get_info(self, response):
src = response.xpath(
'//div[@class="article"]//div[@class="photo-show"]//div[@class="photo-wp"]/a[1]/img/@src').extract_first('')
title = response.xpath('//div[@id="content"]/h1/text()').extract_first('')
# print(response.body)
item = BanciyuanItem()
item['title'] = title
item['src'] = [src]
yield item
4.items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class BanciyuanItem(scrapy.Item):
# define the fields for your item here like:
src = scrapy.Field()
title = scrapy.Field()
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class BanciyuanPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
yield scrapy.Request(url=item['src'][0], meta={'item': item})
def file_path(self, request, response=None, info=None, *, item=None):
item = request.meta['item']
image_name = item['src'][0].split('/')[-1]
# image_name.replace('.webp', '.jpg')
path = '%s/%s' % (item['title'].split(' ')[0], image_name)
return path
settings.py
# Scrapy settings for banciyuan project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'banciyuan'
SPIDER_MODULES = ['banciyuan.spiders']
NEWSPIDER_MODULE = 'banciyuan.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'}
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'banciyuan.middlewares.BanciyuanSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'banciyuan.middlewares.BanciyuanDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'banciyuan.pipelines.BanciyuanPipeline': 1,
}
IMAGES_STORE = './images'
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
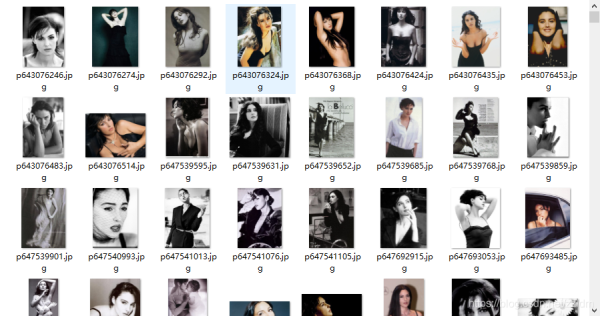
5.爬取结果
reference
到此这篇关于Python爬虫实战之使用Scrapy爬取豆瓣图片的文章就介绍到这了,更多相关Scrapy爬取豆瓣图片内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python基于scrapy爬取京东笔记本电脑数据并进行简单处理和分析
一.环境准备 python3.8.3 pycharm 项目所需第三方包 pip install scrapy fake-useragent requests selenium virtualenv -i https://pypi.douban.com/simple 1.1 创建虚拟环境 切换到指定目录创建 virtualenv .venv 创建完记得激活虚拟环境 1.2 创建项目 scrapy startproject 项目名称 1.3 使用pycharm打开项目,将创建的虚拟环境配置到项目中来
-
Scrapy+Selenium自动获取cookie爬取网易云音乐个人喜爱歌单
此货很干,跟上脚步!!! Cookie cookie是什么东西? 小饼干?能吃吗? 简单来说就是你第一次用账号密码访问服务器 服务器在你本机硬盘上设置一个身份识别的会员卡(cookie) 下次再去访问的时候只要亮一下你的卡片(cookie) 服务器就会知道是你来了,因为你的账号密码等信息已经刻在了会员卡上 需求分析 爬虫要访问一些私人的数据就需要用cookie进行伪装 想要得到cookie就得先登录,爬虫可以通过表单请求将账号密码提交上去 但是在火狐的F12截取到的数据就是, 网易云音乐先将你的
-
如何在scrapy中集成selenium爬取网页的方法
1.背景 我们在爬取网页时一般会使用到三个爬虫库:requests,scrapy,selenium.requests一般用于小型爬虫,scrapy用于构建大的爬虫项目,而selenium主要用来应付负责的页面(复杂js渲染的页面,请求非常难构造,或者构造方式经常变化). 在我们面对大型爬虫项目时,肯定会优选scrapy框架来开发,但是在解析复杂JS渲染的页面时,又很麻烦. 尽管使用selenium浏览器渲染来抓取这样的页面很方便,这种方式下,我们不需要关心页面后台发生了怎样的请求,也不需要分析整
-
python实现Scrapy爬取网易新闻
1. 新建项目 在命令行窗口下输入scrapy startproject scrapytest, 如下 然后就自动创建了相应的文件,如下 2. 修改itmes.py文件 打开scrapy框架自动创建的items.py文件,如下 # Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import s
-
Python利用Scrapy框架爬取豆瓣电影示例
本文实例讲述了Python利用Scrapy框架爬取豆瓣电影.分享给大家供大家参考,具体如下: 1.概念 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 通过Python包管理工具可以很便捷地对scrapy进行安装,如果在安装中报错提示缺少依赖的包,那就通过pip安装所缺的包 pip install scrapy scrapy的组成结构如下图所示 引擎Scrapy Engine,用于中转调度其他部分的信号和数据
-
Python爬虫之教你利用Scrapy爬取图片
Scrapy下载图片项目介绍 Scrapy是一个适用爬取网站数据.提取结构性数据的应用程序框架,它可以通过定制化的修改来满足不同的爬虫需求. 使用Scrapy下载图片 项目创建 首先在终端创建项目 # win4000为项目名 $ scrapy startproject win4000 该命令将创建下述项目目录. 项目预览 查看项目目录 win4000 win4000 spiders __init__.py __init__.py items.py middlewares.py pipelines
-
使用scrapy ImagesPipeline爬取图片资源的示例代码
这是一个使用scrapy的ImagesPipeline爬取下载图片的示例,生成的图片保存在爬虫的full文件夹里. scrapy startproject DoubanImgs cd DoubanImgs scrapy genspider download_douban douban.com vim spiders/download_douban.py # coding=utf-8 from scrapy.spiders import Spider import re from scrapy
-
Python scrapy增量爬取实例及实现过程解析
这篇文章主要介绍了Python scrapy增量爬取实例及实现过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 开始接触爬虫的时候还是初学Python的那会,用的还是request.bs4.pandas,再后面接触scrapy做个一两个爬虫,觉得还是框架好,可惜都没有记录都忘记了,现在做推荐系统需要爬取一定的文章,所以又把scrapy捡起来.趁着这次机会做一个记录. 目录如下: 环境 本地窗口调试命令 工程目录 xpath选择器 一个简单
-
scrapy与selenium结合爬取数据(爬取动态网站)的示例代码
scrapy框架只能爬取静态网站.如需爬取动态网站,需要结合着selenium进行js的渲染,才能获取到动态加载的数据. 如何通过selenium请求url,而不再通过下载器Downloader去请求这个url? 方法:在request对象通过中间件的时候,在中间件内部开始使用selenium去请求url,并且会得到url对应的源码,然后再将 源 代码通过response对象返回,直接交给process_response()进行处理,再交给引擎.过程中相当于后续中间件的process_req
-
Python爬虫实战之使用Scrapy爬取豆瓣图片
使用Scrapy爬取豆瓣某影星的所有个人图片 以莫妮卡·贝鲁奇为例 1.首先我们在命令行进入到我们要创建的目录,输入 scrapy startproject banciyuan 创建scrapy项目 创建的项目结构如下 2.为了方便使用pycharm执行scrapy项目,新建main.py from scrapy import cmdline cmdline.execute("scrapy crawl banciyuan".split()) 再edit configuration 然后
-
Python爬虫实战之用selenium爬取某旅游网站
一.selenium实战 这里我们只会用到很少的selenium语法,我这里就不补充别的用法了,以实战为目的 二.打开艺龙网 可以直接点击这里进入:艺龙网 这里是主页 三.精确目标 我们的目标是,鹤壁市,所以我们应该先点击搜索框,然后把北京删掉,替换成鹤壁市,那么怎么通过selenium实现呢? 打开pycharm,新建一个叫做艺龙网的py文件,先导包: from selenium import webdriver import time # 导包 driver = webdriver.Chro
-
Python爬虫实战之虎牙视频爬取附源码
目录 知识点 开发环境 分析目标url 开始代码 最开始还是线导入所需模块 数据请求 获取视频标题以及url地址 获取视频id 保存数据 调用函数 运行代码,得到数据 知识点 爬虫基本流程 re正则表达式简单使用 requests json数据解析方法 视频数据保存 开发环境 Python 3.8 Pycharm 爬虫基本思路流程: (重点) [无论任何网站 任何数据内容 都是按照这个流程去分析] 1.确定需求 (爬取的内容是什么东西?) 都通过开发者工具进行抓包分析 分析视频播放url地址 是
-
Python爬虫实现的根据分类爬取豆瓣电影信息功能示例
本文实例讲述了Python爬虫实现的根据分类爬取豆瓣电影信息功能.分享给大家供大家参考,具体如下: 代码的入口: if __name__ == '__main__': main() #! /usr/bin/python3 # -*- coding:utf-8 -*- # author:Sirius.Zhao import json from urllib.parse import quote from urllib.request import urlopen from urllib.reque
-
Python爬虫入门教程01之爬取豆瓣Top电影
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理 基本开发环境 Python 3.6 Pycharm 相关模块的使用 requests parsel csv 安装Python并添加到环境变量,pip安装需要的相关模块即可. 爬虫基本思路 一.明确需求 爬取豆瓣Top250排行电影信息 电影名字 导演.主演 年份.国家.类型 评分.评价人数 电影简介 二.发送请求 Python中的大量开源的模块使得编码变的特别简单,我们写爬虫第一个要了解的模
-
python爬虫 正则表达式使用技巧及爬取个人博客的实例讲解
这篇博客是自己<数据挖掘与分析>课程讲到正则表达式爬虫的相关内容,主要简单介绍Python正则表达式爬虫,同时讲述常见的正则表达式分析方法,最后通过实例爬取作者的个人博客网站.希望这篇基础文章对您有所帮助,如果文章中存在错误或不足之处,还请海涵.真的太忙了,太长时间没有写博客了,抱歉~ 一.正则表达式 正则表达式(Regular Expression,简称Regex或RE)又称为正规表示法或常规表示法,常常用来检索.替换那些符合某个模式的文本,它首先设定好了一些特殊的字及字符组合,通过组合的&
-
python爬虫之利用Selenium+Requests爬取拉勾网
一.前言 利用selenium+requests访问页面爬取拉勾网招聘信息 二.分析url 观察页面可知,页面数据属于动态加载 所以现在我们通过抓包工具,获取数据包 观察其url和参数 url="https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false" 参数: city=%E5%8C%97%E4%BA%AC ==>城市 first=true ==>无用 pn=
-
python爬虫之教你如何爬取地理数据
一.shapely模块 1.shapely shapely是python中开源的针对空间几何进行处理的模块,支持点.线.面等基本几何对象类型以及相关空间操作. 2.point→Point类 curve→LineString和LinearRing类: surface→Polygon类 集合方法分别对应MultiPoint.MultiLineString.MultiPolygon 3.导入所需模块 # 导入所需模块 from shapely import geometry as geo from s
-
Python爬虫实战案例之爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一起期待吧!! 这个案例的视频地址在这里 https://v.douyu.com/show/a2JEMJj3e3mMNxml 项目目标 爬取喜马拉雅音频数据 受害者地址 https://www.ximalaya.com/ 本文知识点: 1.系统分析网页性质 2.多层数据解析 3.海量音频数据保存 环境