使用sharding-jdbc实现水平分表的示例代码
目录
- 在mysql中新建数据库sharding_db,新增两张结构一样的表student_1和student_2。
- 添加依赖
- 编写配置文件
- 编写实体类
- 编写mapper接口
- 编写测试类
- 执行测试
在mysql中新建数据库sharding_db,新增两张结构一样的表student_1和student_2。
CREATE TABLE `student_1` ( `ID` bigint(20) NOT NULL , `NAME` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL , `AGE` int(11) NOT NULL , `GENDER` varchar(1) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL , PRIMARY KEY (`ID`) );
此处未指定主键自增,因为两张表的id不能重复,所以只能从后端传入id。
添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Druid连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.20</version>
</dependency>
<!-- Mysql驱动依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!-- MybatisPlus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
<!-- Sharding-JDBC -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<!-- lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
编写配置文件
spring.main.allow-bean-definition-overriding=true
# 配置Sharding-JDBC的分片策略
# 配置数据源,给数据源起名g1,g2...此处可配置多数据源
spring.shardingsphere.datasource.names=g1
# 配置数据源具体内容:连接池,驱动,地址,用户名,密码
# 由于上面配置数据源只有g1因此下面只配置g1.type,g1.driver-class-name,g1.url,g1.username,g1.password
spring.shardingsphere.datasource.g1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.g1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.g1.url=jdbc:mysql://localhost:3306/sharding_db?characterEncoding=utf-8&useUnicode=true&useSSL=false&serverTimezone=UTC
spring.shardingsphere.datasource.g1.username=root
spring.shardingsphere.datasource.g1.password=123456
# 配置表的分布,表的策略
spring.shardingsphere.sharding.tables.student.actual-data-nodes=g1.student_$->{1..2}
# 指定student表 主键gid 生成策略为 SNOWFLAKE
spring.shardingsphere.sharding.tables.student.key-generator.column=id
spring.shardingsphere.sharding.tables.student.key-generator.type=SNOWFLAKE
# 指定分片策略 约定id值是偶数添加到student_1表,如果id是奇数添加到student_2表
spring.shardingsphere.sharding.tables.student.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.student.table-strategy.inline.algorithm-expression=student_$->{id % 2 + 1}
# 打开sql输出日志
spring.shardingsphere.props.sql.show=true
或者是yml格式
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
g1:
driver-class-name: com.mysql.cj.jdbc.Driver
password: 123456
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://localhost:3306/sharding_db?characterEncoding=utf-8&useUnicode=true&useSSL=false&serverTimezone=UTC
username: root
names: g1
props:
sql:
show: true
sharding:
tables:
student:
actual-data-nodes: g1.student_$->{1..2}
key-generator:
column: id
type: SNOWFLAKE
table-strategy:
inline:
algorithm-expression: student_$->{id % 2 + 1}
sharding-column: id
编写实体类
@Data
public class Student {
private Long id;
private String name;
private int age;
private String gender;
}
编写mapper接口
@Repository
public interface StudentMapper extends BaseMapper<Student> {
}
编写测试类
@SpringBootTest
class ShardingJdbcDemoApplicationTests {
@Autowired
private StudentMapper studentMapper;
@Test
public void test01() {
for (int i = 0; i < 10; i++) {
Student student = new Student();
student.setName("wuwl");
student.setAge(27);
student.setGender("男");
studentMapper.insert(student);
}
}
}
执行测试

执行成功,主键通过雪花算法在后端生成,传入到数据库中,根据奇偶性进行分表。
student_1表数据:

student_2表数据:

两张表的数据分别有5条,但这只是因为雪花算法生成的id奇数偶数各5个,不是1:1的关系,需要注意。
主键生成后,根据策略插入到对应的表中,从打印出来的sql可以证明这一点。
通过mapper接口的selectById方法进行查询时,会先根据主键策略判断在哪个库,再直接去那个库根据主键查询。而如果是通过其它条件查询,或者是多个id的selectById方法查询,又是如何的呢?
@Test
public void test03() {
List<Long> list = new ArrayList<>();
list.add(1362282042768609282l);
list.add(1362282040277192705l);
List<Student> studentList = studentMapper.selectBatchIds(list);
System.out.println(studentList);
}
取了两张表的id进行查询。
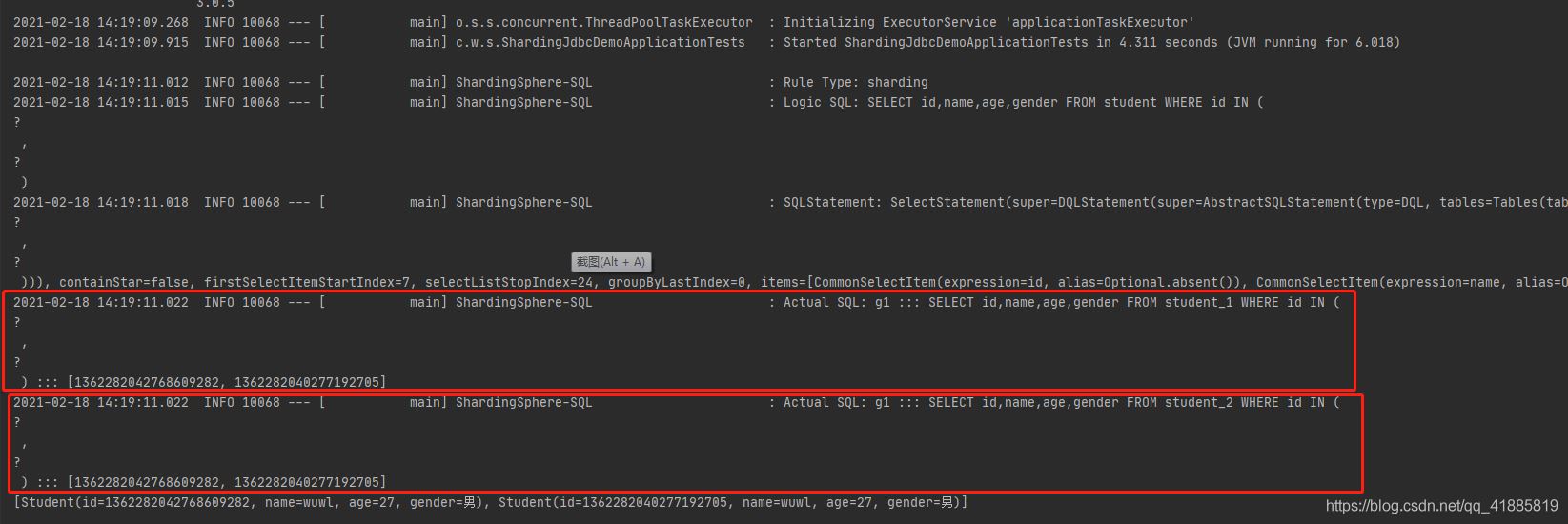
执行同样的sql,在两张表中都查询一遍,再组合结果。
如果所有的id,都来自同一张表,那是否会去多个表中重复查询呢?

只执行了一遍。所以,在执行查询时,sharding会先判断是否可以确定需要的数据来自那张表,如果能,则直接去那一张表中查询数据即可,而如果不能确定,则会多个表重复查询,以确定查询结果的完整性。
到此这篇关于使用sharding-jdbc实现水平分表的示例代码的文章就介绍到这了,更多相关sharding-jdbc 水平分表内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Sharding-Jdbc 自定义复合分片的实现(分库分表)
目录 Sharding-JDBC的数据分片策略 分片键 分片算法 分片策略 SQL Hint 实战–自定义复合分片策略 小结 Sharding-JDBC中的分片策略有两个维度,分别是: 数据源分片策略(DatabaseShardingStrategy) 表分片策略(TableShardingStrategy) 其中,数据源分片策略表示:数据路由到的物理目标数据源,表分片策略表示数据被路由到的目标表. 特别的,表分片策略是依赖于数据源分片策略的,也就是说要先分库再分表,当然也可以只分表. Shar
-
Spring Boot 集成 Sharding-JDBC + Mybatis-Plus 实现分库分表功能
一. Sharding-jdbc简介 " Sharding-jdbc是开源的数据库操作中间件:定位为轻量级Java框架,在Java的JDBC层提供的额外服务.它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架. 官方文档地址:https://shardingsphere.apache.org/document/current/cn/overview/ 本文demo实现了分库分表功能.如有错误,欢迎各位在评论中指出.不
-
利用Sharding-Jdbc组件实现分表
看到了当当开源的Sharding-JDBC组件,它可以在几乎不修改代码的情况下完成分库分表的实现.摘抄其中一段介绍: Sharding-JDBC直接封装JDBC API,可以理解为增强版的JDBC驱动,旧代码迁移成本几乎为零: 可适用于任何基于java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC. 可基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid等. 理论上可支持任意实现JDB
-
SpringBoot整合sharding-jdbc实现自定义分库分表的实践
目录 一.前言 二.简介 1.分片键 2.分片算法 三.程序实现 一.前言 SpringBoot整合sharding-jdbc实现分库分表与读写分离 本文将通过自定义算法来实现定制化的分库分表来扩展相应业务 二.简介 1.分片键 用于数据库/表拆分的关键字段 ex: 用户表根据user_id取模拆分到不同的数据库中 2.分片算法 可参考:https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere
-
Java使用Sharding-JDBC分库分表进行操作
目录 主从库搭建 Compose File Master 配置 Slave 配置 主从配置 创建分库分表 Order 1 库 Order 2 库 User 库 Sharding-JDBC 引入 Sharding-JDBC 配置 可选配置 数据源配置 主从复制配置 数据节点配置 Demo 程序 Sharding-JDBC 是无侵入式的 MySQL 分库分表操作工具,所有库表设置仅需要在配置文件中配置即可,无须修改任何代码. 本文写了一个 Demo,使用的是 SpringBoot 框架,通过 Doc
-
SpringBoot整合sharding-jdbc实现分库分表与读写分离的示例
目录 一.前言 二.数据库表准备 三.整合 四.docker-compose部署mysql主从 五.本文案例demo源码 一.前言 本文将基于以下环境整合sharding-jdbc实现分库分表与读写分离 springboot2.4.0 mybatis-plus3.4.3.1 mysql5.7主从 https://github.com/apache/shardingsphere 二.数据库表准备 温馨小提示:此sql执行时,如果之前有存在相应库和表会进行自动删除后再创建! DROP DATABAS
-
SpringBoot 2.0 整合sharding-jdbc中间件实现数据分库分表
一.水平分割 1.水平分库 1).概念: 以字段为依据,按照一定策略,将一个库中的数据拆分到多个库中. 2).结果 每个库的结构都一样:数据都不一样: 所有库的并集是全量数据: 2.水平分表 1).概念 以字段为依据,按照一定策略,将一个表中的数据拆分到多个表中. 2).结果 每个表的结构都一样:数据都不一样: 所有表的并集是全量数据: 二.Shard-jdbc 中间件 1.架构图 2.特点 1).Sharding-JDBC直接封装JDBC API,旧代码迁移成本几乎为零. 2).适
-
使用sharding-jdbc实现水平分表的示例代码
目录 在mysql中新建数据库sharding_db,新增两张结构一样的表student_1和student_2. 添加依赖 编写配置文件 编写实体类 编写mapper接口 编写测试类 执行测试 在mysql中新建数据库sharding_db,新增两张结构一样的表student_1和student_2. CREATE TABLE `student_1` ( `ID` bigint(20) NOT NULL , `NAME` varchar(50) CHARACTER SET utf8mb4 CO
-
使用sharding-jdbc实现水平分库+水平分表的示例代码
前面的文章使用sharding-jdbc实现水平分表中详细记录了如何使用sharding-jdbc实现水平分表,即根据相应的策略,将一部分数据存入到表1中,一部分数据存入到表2中,逻辑上为同一张表,分表操作全部交由sharding-jdbc进行处理. 可能根据需要,还需要将一张表的数据拆分存入到多个数据库中,甚至多个数据库的多个表中,使用sharding-jdbc同样可以实现. 重复的篇幅则不再赘述,下面重点记录升级的过程. 分库分表策略:将id为偶数的存入到库1中,奇数存入到库2中,在每个库中
-
springboot实现以代码的方式配置sharding-jdbc水平分表
目录 关于依赖 shardingsphere-jdbc-core-spring-boot-starter shardingsphere-jdbc-core 数据源DataSource 原DataSource ShardingJdbcDataSource 完整的ShardingJdbcDataSource配置 分表策略 主要的类 其他的分表配置类 groovy行表达式说明 properties配置 Sharding-jdbc的坑 结语 多数项目可能是已经运行了一段时间,才开始使用sharding-
-
Mysql的水平分表与垂直分表的讲解
在我上一篇文章中说过,mysql语句的优化有局限性,mysql语句的优化都是围绕着索引去优化的,那么如果mysql中的索引也解决不了海量数据查询慢的状况,那么有了水平分表与垂直分表的出现(我就是记录一下自己的理解) 水平分表: 如上图所示:另外三张表表结构是一样的 只不过把数据进行分别存放在这三张表中,如果要insert 或者query 那么都需要对id进行取余 然后table名进行拼接,那么就是一张完整的table_name 但是如果我需要对name进行分表呢 或者对email呢? 那么就需
-
springboot+mybatis拦截器方法实现水平分表操作
目录 1.前言 2.MyBatis 允许使用插件来拦截的方法 3.Interceptor接口 4分表实现 4.1.大体思路 4.2.1 Mybatis如何找到我们新增的拦截服务 4.2.2 应该拦截什么样的对象 4.2.3 实现自定义拦截器 4.2.逐步实现 1.前言 业务飞速发展导致了数据规模的急速膨胀,单机数据库已经无法适应互联网业务的发展.由于MySQL采用 B+树索引,数据量超过阈值时,索引深度的增加也将使得磁盘访问的 IO 次数增加,进而导致查询性能的下降:高并发访问请求也使得集中式数
-
Java中利用Alibaba开源技术EasyExcel来操作Excel表的示例代码
一.读Excel 1.Excel表格示例 2.对象示例 @Data public class DemoData { private String string; private Date date; private Double doubleData; } 3.监听器(重点部分) // 有个很重要的点 DemoDataListener 不能被spring管理,要每次读取excel都要new,然后里面用到spring可以构造方法传进去 public class DemoDataListener e
-
MySQL/MariaDB 如何实现数据透视表的示例代码
前文介绍了Oracle 中实现数据透视表的几种方法,今天我们来看看在 MySQL/MariaDB 中如何实现相同的功能. 本文使用的示例数据可以点此下载. 使用 CASE 表达式和分组聚合 数据透视表的本质就是按照行和列的不同组合进行数据分组,然后对结果进行汇总:因此,它和数据库中的分组(GROUP BY)加聚合函数(COUNT.SUM.AVG 等)的功能非常类似. 我们首先使用以下 GROUP BY 子句对销售数据进行分类汇总: select coalesce(product, '[全部产品]
-
C/C++实现线性顺序表的示例代码
目录 线性顺序表简介 C语言实现代码 C++语言实现代码 线性顺序表简介 使用顺序存储结构的线性存储结构的表为线性顺序表,线性存储结构是元素逻辑结构一对一,顺序存储结构是元素物理结构连续,线性顺序表操作没有限制,线性顺序表优点是可以使用下标获取和修改元素,线性顺序表缺点是不可以直接插入和删除元素. C语言实现代码 #include<stdio.h>//包含标准输入输出文件 #include<stdlib.h>//包含标准库文件 typedef struct//定义类型定义结构体 {
-
python读取Windows注册表的示例代码
运行结果 代码 import winreg def read_reg(): location = r"Software\\Microsoft\\Windows\\CurrentVersion\\Explorer\\Shell Folders" # 获取注册表该位置的所有键值 key = winreg.OpenKey(winreg.HKEY_CURRENT_USER, location) print("\n" + "-"*100 + "\
-
C语言实现动态顺序表的示例代码
目录 顺序表概念及结构 基本操作 功能实现 程序运行 顺序表概念及结构 顺序表是用一段物理地址连续的存储单元依次存储数据元素的线性结构,一般情况下采用数组存储.在数组上完成数据的增删查改. 分类: 一般分为静态顺序表和动态顺序表: 静态顺序表:数组大小是固定的用完了无法增容:同时我们无法控制给数组开多少空间合适,开少了,空间不够:开多了,有回会存在空间浪费: 动态顺序表:空间是可以变动的,空间满了我们就增容:解决了静态顺序表的空间不足问题,同时也在一定程度上减少了空间浪费: 因此本篇博客主要实现