前端面试的底气之实现一个深拷贝
目录
- 前言
- 青铜段位
- 白银段位
- 黄金段位
- 铂金段位
- 砖石段位
- 星耀段位
- 王者段位
- 总结
前言
深拷贝这个功能在开发中经常使用到,特别在对引用类型的数据进行操作时,一般会先深拷贝一份赋值给一个变量,然后在对其操作,防止影响到其它使用该数据的地方。
如何实现一个深拷贝,在面试中出现频率一直居高不下。因为在实现一个深拷贝过程中,可以看出应聘者很多方面的能力。
本专栏将从青铜到王者来介绍怎么实现一个深拷贝,以及每个段位对应的能力。
青铜段位
JSON.parse(JSON.stringify(data))
这种写法非常简单,而且可以应对大部分的应用场景,但是它有很大缺陷的。如果你不知道它有那些缺陷,而且这种实现方法体现不出你任何能力,所以这种实现方法处于青铜段位。
- 如果对象中存在循环引用的情况也无法正确实现深拷贝。
const a = {
b: 1,
}
a.c = a;
JSON.parse(JSON.stringify(a));

- 如果 data 里面有时间对象,则
JSON.stringify后再JSON.parse的结果,时间将只是字符串的形式。而不是时间对象。
const a = {
b: new Date(1536627600000),
}
console.log(JSON.parse(JSON.stringify(a)))
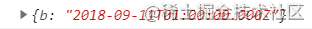
- 如果 data 里有RegExp、Error对象,则序列化的结果将只得到空对象;
const a = {
b: new RegExp(/\d/),
c: new Error('错误')
}
console.log(JSON.parse(JSON.stringify(a)))

- 如果 data 里有函数,undefined,则序列化的结果会把函数置为undefined或丢失;
const a = {
b: function (){
console.log(1)
},
c:1,
d:undefined
}
console.log(JSON.parse(JSON.stringify(a)))

- 如果 data 里有NaN、Infinity和-Infinity,则序列化的结果会变成null
const a = {
b: NaN,
c: 1.7976931348623157E+10308,
d: -1.7976931348623157E+10308,
}
console.log(JSON.parse(JSON.stringify(a)))

白银段位
深拷贝的核心就是对引用类型的数据的拷贝处理。
function deepClone(target){
if(target !== null && typeof target === 'object'){
let result = {}
for (let k in target){
if (target.hasOwnProperty(k)) {
result[k] = deepClone(target[k])
}
}
return result;
}else{
return target;
}
}
以上代码中,deepClone函数的参数 target 是要深拷贝的数据。
执行 target !== null && typeof target === 'object' 判断 target 是不是引用类型。
若不是,直接返回 target。
若是,创建一个变量 result 作为深拷贝的结果,遍历 target,执行 deepClone(target[k]) 把 target 每个属性的值深拷贝后赋值到深拷贝的结果对应的属性 result[k] 上,遍历完毕后返回 result。
在执行 deepClone(target[k]) 中,又会对 target[k] 进行类型判断,重复上述流程,形成了一个递归调用 deepClone 函数的过程。就可以层层遍历要拷贝的数据,不管要拷贝的数据有多少子属性,只要子属性的值的类型是引用类型,就会调用 deepClone 函数将其深拷贝后赋值到深拷贝的结果对应的属性上。
另外使用 for...in 循环遍历对象的属性时,其原型链上的所有属性都将被访问,如果只要只遍历对象自身的属性,而不遍历继承于原型链上的属性,要使用 hasOwnProperty 方法过滤一下。
在这里可以向面试官展示你的三个编程能力。
- 对原始类型和引用类型数据的判断能力。
- 对递归思维的应用的能力。
- 深入理解for...in的用法。
黄金段位
白银段位的代码中只考虑到了引用类型的数据是对象的情况,漏了对引用类型的数据是数组的情况。
function deepClone(target){
if(target !== null && typeof target === 'object'){
let result = Object.prototype.toString.call(target) === "[object Array]" ? [] : {};
for (let k in target){
if (target.hasOwnProperty(k)) {
result[k] = deepClone(target[k])
}
}
return result;
}else{
return target;
}
}
以上代码中,只是额外增加对参数 target 是否是数组的判断。执行 Object.prototype.toString.call(target) === "[object Array]" 判断 target 是不是数组,若是数组,变量result 为 [],若不是数组,变量result 为 {}。
在这里可以向面试官展示你的两个编程能力。
- 正确理解引用类型概念的能力。
- 精确判断数据类型的能力。
铂金段位
假设要深拷贝以下数据 data
let data = {
a: 1
};
data.f=data
执行 deepClone(data),会发现控制台报错,错误信息如下所示。
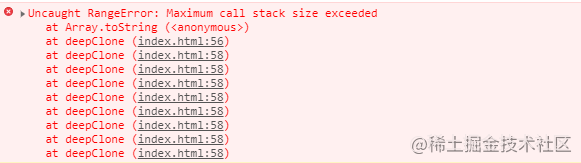
这是因为递归进入死循环导致栈内存溢出了。根本原因是 data 数据存在循环引用,即对象的属性间接或直接的引用了自身。
function deepClone(target) {
function clone(target, map) {
if (target !== null && typeof target === 'object') {
let result = Object.prototype.toString.call(target) === "[object Array]" ? [] : {};
if (map[target]) {
return map[target];
}
map[target] = result;
for (let k in target) {
if (target.hasOwnProperty(k)) {
result[k] = clone(target[k],map)
}
}
return result;
} else {
return target;
}
}
let map = new Map();
const result = clone(target, map);
map.clear();
map = null;
return result
}
以上代码中利用额外的变量 map 来存储当前对象和拷贝对象的对应关系,当需要拷贝当前对象时,先去 map 中找,有没有拷贝过这个对象,如果有的话直接返回,如果没有的话继续拷贝,这样就巧妙化解的循环引用的问题。
之所以采用 ES6 中 Map 数据结构,是因为相对于普通的 Object 结构,其键值不限于字符串,各种类型的值(包括对象)都可以当作键。换句话来说。Object 结构提供了“字符串——值”的对应,Map 结构提供了“值——值” 的对应。若采用 Object 结构,当 target 不是字符串时,那么其键值全部都是 [Object Object],会引起混乱。
最后需要执行 map.clear();map = null; ,释放内存,防止内存泄露。
在这里可以向面试官展示你的三个编程能力。
- 对循环引用的理解,如何解决循环引用引起的问题的能力。
- 熟悉 ES6 中 Map 数据结构的概念及应用
- 对内存泄露的认识和避免泄露的能力。
砖石段位
该段位要考虑性能问题了。上面用 Map 来解决循环引用的问题。但是最后一定要执行 map.clear();map = null; ,释放内存,防止内存泄露。
也可以使用 WeakMap 来解决循环引用。WeakMap 数据结构和 Map 数据结构,有两点区别:
- WeakMap 只接受对象作为键名( null 除外),不接受其他类型的值作为键名。但是 target 正好符合要求故不影响。
- WeakMap 的键名所指向的对象不计入垃圾回收机制。这里用下面的例子来解释。
let map = new WeakMap();
let obj = {a : 1}
map.set(obj , 1);
现代浏览器GC回收策略,采用计算引用次来回收,就是某个对象被引用的次数为 1,因为 map 中的键名 obj 和对象 obj 之间的引用是弱引用,也就是不计入引用次数,对象 obj 被引用的次数还是 1。 当执行 obj = null后,执行GC回收时,对象 obj 被引用的次数变成 0 ,故会把 obj 所占的内存释放掉。
但是如果 map 是 Map 数据结构,因为 Map 的键名所引用的对象是强引用,就算执行 obj = null 后,再执行GC回收,Map 的键名 obj 对所引用的对象 obj 还是有引用,那么obj 被引用的次数还是 1,故 obj 所占的内存释放不掉。
所以使用 WeakMap 可以防止忘记把 map 置为 null 导致的内存泄漏。然而 WeakMap 这种弱引用,仅仅只是为了防止内存泄漏吗?其还有个特性,当执行 obj = null,相当对象 obj 被GC回收了,但是执行 map.get(obj) 得到的值还是 1。我们可以利用这个特性来做一下性能优化。
在深拷贝的代码中。是使用拷贝的对象作为键名的,设想一下,当拷贝的对象非常庞大时,导致 map 会占用很大的内存。
如果 map 使用 Map 数据结构,因为 Map 的键名所引用的对象是强引用,所以在浏览器定时执行GC回收时,除非手动清除 Map 这个键值对,才能把这个拷贝对象所占用的内存释放掉。
如果 map 使用 WeakMap 数据结构,因为 WeakMap 的键名所引用的对象是弱引用,所以在浏览器会定时执行GC回收,会直接把这个拷贝对象所占用的内存释放掉,那么这样是不是对内存占用减少,间接优化了代码运行性能。
此外在上面的代码中,我们遍历数组和对象都使用了 for...in 这种方式,实际上 for...in 在遍历时效率是非常低的,故用效率比较高的 while 来遍历。
function deepClone(target) {
/**
* 遍历数据处理函数
* @array 要处理的数据
* @callback 回调函数,接收两个参数 value 每一项的值 index 每一项的下标或者key。
*/
function handleWhile(array, callback) {
const length = array.length;
let index = -1;
while (++index < length) {
callback(array[index], index)
}
}
function clone(target, map) {
if (target !== null && typeof target === 'object') {
let result = Object.prototype.toString.call(target) === "[object Array]" ? [] : {};
// 解决循环引用
if (map.has(target)) {
return map.get(target);
}
map.set(target, result);
const keys = Object.prototype.toString.call(target) === "[object Array]" ? undefined : Object.keys(
target);
function callback(value, key) {
if (keys) {
// 如果keys存在则说明value是一个对象的key,不存在则说明key就是数组的下标。
key = value;
}
result[key] = clone(target[key], map)
}
handleWhile(keys || target, callback)
return result;
} else {
return target;
}
}
let map = new WeakMap();
const result = clone(target,map);
map = null;
return result
}
用 while 遍历的深拷贝记为 deepClone,把用 for ... in 遍历的深拷贝记为 deepClone1。利用 console.time() 和 console.timeEnd() 来计算执行时间。
let arr = [];
for (let i = 0; i < 1000000; i++) {
arr.push(i)
}
let data = {
a: arr
};
console.time();
const result = deepClone(data);
console.timeEnd();
console.time();
const result1 = deepClone1(data);
console.timeEnd();

从上图明显可以看到用 while 遍历的深拷贝的性能远优于用 for ... in 遍历的深拷贝。
在这里可以向面试官展示你的五个编程能力。
- 熟悉 ES6 中 WeakMap 数据结构的概念及应用
- 具有优化代码运行性能的能力。
- 了解遍历的效率的能力。
- 了解
++i和i++的区别。 - 代码抽象的能力。
星耀段位
在这个阶段应该考虑代码逻辑的严谨性。在上面段位的代码虽然已经满足平时开发的需求,但是还是有几处逻辑不严谨的地方。
- 判断数据不是引用类型时就直接返回 target,但是原始类型中还有 Symbol 这一特殊类型的数据,因为其每个 Symbol 都是独一无二,需要额外拷贝处理,不能直接返回。
- 判断数据是不是引用类型时不严谨,漏了
typeof target === function'的判断。 - 只考虑了 Array、Object 两种引用类型数据的处理,引用类型的数据还有Function 函数、Date 日期、RegExp 正则、Map 数据结构、Set 数据机构,其中 Map 、Set 属于 ES6 的。
废话不多说,直接贴上全部代码,代码中有注释。
function deepClone(target) {
// 获取数据类型
function getType(target) {
return Object.prototype.toString.call(target)
}
//判断数据是不是引用类型
function isObject(target) {
return target !== null && (typeof target === 'object' || typeof target === 'function');
}
//处理不需要遍历的应引用类型数据
function handleOherData(target) {
const type = getType(target);
switch (type) {
case "[object Date]":
return new Date(target)
case "[object RegExp]":
return cloneReg(target)
case "[object Function]":
return cloneFunction(target)
}
}
//拷贝Symbol类型数据
function cloneSymbol(targe) {
const a = String(targe); //把Symbol字符串化
const b = a.substring(7, a.length - 1); //取出Symbol()的参数
return Symbol(b); //用原先的Symbol()的参数创建一个新的Symbol
}
//拷贝正则类型数据
function cloneReg(target) {
const reFlags = /\w*$/;
const result = new target.constructor(target.source, reFlags.exec(target));
result.lastIndex = target.lastIndex;
return result;
}
//拷贝函数
function cloneFunction(targe) {
//匹配函数体的正则
const bodyReg = /(?<={)(.|\n)+(?=})/m;
//匹配函数参数的正则
const paramReg = /(?<=\().+(?=\)\s+{)/;
const targeString = targe.toString();
//利用prototype来区分下箭头函数和普通函数,箭头函数是没有prototype的
if (targe.prototype) { //普通函数
const param = paramReg.exec(targeString);
const body = bodyReg.exec(targeString);
if (body) {
if (param) {
const paramArr = param[0].split(',');
//使用 new Function 重新构造一个新的函数
return new Function(...paramArr, body[0]);
} else {
return new Function(body[0]);
}
} else {
return null;
}
} else { //箭头函数
//eval和函数字符串来重新生成一个箭头函数
return eval(targeString);
}
}
/**
* 遍历数据处理函数
* @array 要处理的数据
* @callback 回调函数,接收两个参数 value 每一项的值 index 每一项的下标或者key。
*/
function handleWhile(array, callback) {
let index = -1;
const length = array.length;
while (++index < length) {
callback(array[index], index);
}
}
function clone(target, map) {
if (isObject(target)) {
let result = null;
if (getType(target) === "[object Array]") {
result = []
} else if (getType(target) === "[object Object]") {
result = {}
} else if (getType(target) === "[object Map]") {
result = new Map();
} else if (getType(target) === "[object Set]") {
result = new Set();
}
// 解决循环引用
if (map.has(target)) {
return map.get(target);
}
map.set(target, result);
if (getType(target) === "[object Map]") {
target.forEach((value, key) => {
result.set(key, clone(value, map));
});
return result;
} else if (getType(target) === "[object Set]") {
target.forEach(value => {
result.add(clone(value, map));
});
return result;
} else if (getType(target) === "[object Object]" || getType(target) === "[object Array]") {
const keys = getType(target) === "[object Array]" ? undefined : Object.keys(target);
function callback(value, key) {
if (keys) {
// 如果keys存在则说明value是一个对象的key,不存在则说明key就是数组的下标。
key = value
}
result[key] = clone(target[key], map)
}
handleWhile(keys || target, callback)
} else {
result = handleOherData(target)
}
return result;
} else {
if (getType(target) === "[object Symbol]") {
return cloneSymbol(target)
} else {
return target;
}
}
}
let map = new WeakMap;
const result = clone(target, map);
map = null;
return result
}
在这里可以向面试官展示你的六个编程能力。
- 代码逻辑的严谨性。
- 深入了解数据类型的能力。
- JS Api 的熟练使用的能力。
- 了解箭头函数和普通函数的区别。
- 熟练使用正则表达式的能力。
- 模块化开发的能力
王者段位
以上代码中还有很多数据类型的拷贝,没有实现,有兴趣的话可以在评论中实现一下,王者属于你哦!
总结
综上所述,面试官叫你实现一个深拷贝,其实是要考察你各方面的能力。例如
- 白银段位
- 对原始类型和引用类型数据的判断能力。
- 对递归思维的应用的能力。
- 黄金段位
- 正确理解引用类型概念的能力。
- 精确判断数据类型的能力。
- 铂金段位
- 对循环引用的理解,如何解决循环引用引起的问题的能力。
- 熟悉 ES6 中 Map 数据结构的概念及应用。
- 对内存泄露的认识和避免泄露的能力。
- 砖石段位
- 熟悉 ES6 中 WeakMap 数据结构的概念及应用。
- 具有优化代码运行性能的能力。
- 了解遍历的效率的能力。
- 了解
++i和i++的区别。 - 代码抽象的能力。
- 星耀段位
- 代码逻辑的严谨性。
- 深入了解数据类型的能力。
- JS Api 的熟练使用的能力。
- 了解箭头函数和普通函数的区别。
- 熟练使用正则表达式的能力。
- 模块化开发的能力
所以不要去死记硬背一些手写代码的面试题,最好自己动手写一下,看看自己达到那个段位了。
到此这篇关于前端面试的底气之实现一个深拷贝的文章就介绍到这了,更多相关深拷贝实现内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
javascript深拷贝(deepClone)详解
javascript深拷贝是初学者甚至有经验的开发着,都会经常遇到问题,并不能很好的理解javascript的深拷贝. 深拷贝(deepClone)? 与深拷贝相对的就是浅拷贝,很多初学者在接触这个感念的时候,是很懵逼的. 为啥要用深拷贝? 在很多情况下,我们都需要给变量赋值,给内存地址赋予一个值,但是在赋值引用值类型的时候,只是共享一个内存区域,导致赋值的时候,还跟之前的值保持一直性. 看一个具体的例子 // 给test赋值了一个对象 var test = { a: 'a', b: 'b' }
-
js对象浅拷贝和深拷贝详解
本文为大家分享了JavaScript对象的浅拷贝和深拷贝代码,供大家参考,具体内容如下 1.浅拷贝 拷贝就是把父对像的属性,全部拷贝给子对象. 下面这个函数,就是在做拷贝: var Chinese = { nation:'中国' } var Doctor = { career:'医生' } function extendCopy(p) { var c = {}; for (var i in p) { c[i] = p[i]; } c.uber = p; return c; } 使用的时候,这样写
-
JS中实现浅拷贝和深拷贝的代码详解
(一)JS中基本类型和引用类型 JavaScript的变量中包含两种类型的值:基本类型值 和 引用类型值,在内存中的表现形式在于:前者是存储在栈中的一些简单的数据段,后者则是保存在堆内存中的一个对象. 基本类型值 在JavaScript中基本数据类型有 String , Number , Undefined , Null , Boolean ,在ES6中,又定义了一种新的基本数据类型 Symbol ,所以一共有6种. 基本类型是按值访问的,从一个变量复制基本类型的值到另一个变量后,这两个变量的值
-
JavaScript数组深拷贝和浅拷贝的两种方法
例如这个例子: 复制代码 代码如下: var arr = ["One","Two","Three"]; var arrto = arr;arrto[1] = "test";document.writeln("数组的原始值:" + arr + "<br />");//Export:数组的原始值:One,test,Threedocument.writeln("数组的新值
-
javascript 深拷贝
我们先看一下浅复制的缺陷,不知多少人中过招呢? 复制代码 代码如下: var oOriginal = { memNum: 1, // number memStr: "I am a string", // string memObj: { test1: "Old value" // we'll test }, memArr: [ // array "a string", // string member of array { // object m
-
JS实现数组深拷贝的方法分析
本文实例讲述了JS实现数组深拷贝的方法.分享给大家供大家参考,具体如下: 最近在网上看到一篇关于js数组复制最有效的方法是直接使用slice和concat方法.这2个方法的确是最快的把数组成功复制,而不是引用.可以运行实例: <script type="text/javascript"> <!-- var arr1=["1","2","3"],arr2; arr2=arr1.slice(0); arr1[0]
-
js 深拷贝函数
function objectClone(obj,preventName){ if((typeof obj)=='object'){ var res=(!obj.sort)?{}:[]; for(var i in obj){ if(i!=preventName) res[i]=objectClone(obj[i],preventName); } return res; }else if((typeof obj)=='function'){ return (new obj()).construct
-
JavaScript 中对象的深拷贝
对象的深拷贝与浅拷贝的区别如下: 浅拷贝:仅仅复制对象的引用,而不是对象本身: 深拷贝:把复制的对象所引用的全部对象都复制一遍. 一. 浅拷贝的实现 浅拷贝的实现方法比较简单,只要使用是简单的复制语句即可. 1.1 方法一:简单的复制语句 /* ================ 浅拷贝 ================ */ function simpleClone(initalObj) { var obj = {}; for ( var i in initalObj) {
-
JavaScript基础心法 深浅拷贝(浅拷贝和深拷贝)
前言 说到深浅拷贝,必须先提到的是JavaScript的数据类型,之前的一篇文章JavaScript基础心法--数据类型说的很清楚了,这里就不多说了. 需要知道的就是一点:JavaScript的数据类型分为基本数据类型和引用数据类型. 对于基本数据类型的拷贝,并没有深浅拷贝的区别,我们所说的深浅拷贝都是对于引用数据类型而言的. 浅拷贝 浅拷贝的意思就是只复制引用,而未复制真正的值. const originArray = [1,2,3,4,5]; const originObj = {a:'a'
-

前端面试的底气之实现一个深拷贝
目录 前言 青铜段位 白银段位 黄金段位 铂金段位 砖石段位 星耀段位 王者段位 总结 前言 深拷贝这个功能在开发中经常使用到,特别在对引用类型的数据进行操作时,一般会先深拷贝一份赋值给一个变量,然后在对其操作,防止影响到其它使用该数据的地方. 如何实现一个深拷贝,在面试中出现频率一直居高不下.因为在实现一个深拷贝过程中,可以看出应聘者很多方面的能力. 本专栏将从青铜到王者来介绍怎么实现一个深拷贝,以及每个段位对应的能力. 青铜段位 JSON.parse(JSON.stringify(data)
-
前端面试JavaScript高频手写大全
目录 1. 手写instanceof 2. 实现数组的map方法 3. reduce实现数组的map方法 4. 手写数组的reduce方法 5. 数组扁平化 5. 1 es6提供的新方法 flat(depth) 5.2 利用cancat 6. 函数柯里化 7. 浅拷贝和深拷贝的实现 7.1浅拷贝和深拷贝的区别 8. 手写call, apply, bind 8.1 手写call 8.2 手写apply(arguments[this, [参数1,参数2.....] ]) 8.3 手写bind 9.
-
前端面试知识点目录一览
写在前面: 金三银四, 又到了一年一度的跳槽季, 相信大家都在准备自己面试笔记, 我也针对自己工作中所掌握或了解的一些东西做了一个目录总结,方便自己复习; 详细内容会在之后一一对应地补充上去(有些在我的个人主页笔记中也有相关记录), 这里暂且放一个我的面试知识点目录; 大家有兴趣可以自己根据目录去扩展, 欢迎在评论下方指点一二, 看还有哪些没考虑到的, 互相交流一哈... 基本功考察 关于Html 1. html语义化标签的理解; 结构化的理解; 能否写出简洁的html结构; SEO优化
-
JS前端面试必备——基本排序算法原理与实现方法详解【插入/选择/归并/冒泡/快速排序】
本文实例讲述了JS前端面试必备--基本排序算法原理与实现方法.分享给大家供大家参考,具体如下: 排序算法是面试及笔试中必考点,本文通过动画方式演示,通过实例讲解,最后给出JavaScript版的排序算法 插入排序 算法描述: 1. 从第一个元素开始,该元素可以认为已经被排序 2. 取出下一个元素,在已经排序的元素序列中从后向前扫描 3. 如果该元素(已排序)大于新元素,将该元素移到下一位置 4. 重复步骤 3,直到找到已排序的元素小于或者等于新元素的位置 5. 将新元素插入到该位置后 6. 重复
-
JS一次前端面试经历记录
本文实例讲述了JS一次前端面试经历.分享给大家供大家参考,具体如下: 最近公司在做一些战略调整,部门有不少老员工前辈们都陆陆续续的离职或者被离职了.而我所在的团队--网易菠萝,也被归并到游戏运营中心了.因为产品策划还没有出来.暂时没什么需求做,闲得有点e-g-g疼的,每天从早到晚都是待在公司看看书.刷刷知乎等.我真是命途多舛啊,还没有真正步入社会,就见证了一个上百人的事业部说没落就没落.甚至已看破红尘,连参加省公务员考试的计划都做好了.这可不是开玩笑的哈,已经在报名费和复习资料上花了两三百块啦,
-
JavaScript前端面试扁平数据转tree与tree数据扁平化
目录 一.写在前面 二.正文部分 2.1 扁平数据转为 tree 数据 2.2 tree 数据转为扁平数据 2.3 完整测试 demo 三.写在后面 一.写在前面 有时我们拿到的数据的数据结构可能不是理想的,那么此时就要求前端程序员,具有改造数据的能力.例如拿到扁平的数据, 但我们要应用在 tree 树形组件或 Cascader 级联选择器组件中,这样的组件要求数据结构是非扁平的的具有层级递进关系的 tree 结构. 总之就是说,提供数据的接口给到的数据,未必符合要求,而当我们又无法令他人为为我
-
高级前端面试手写扁平数据结构转Tree
目录 前言 什么是好算法,什么是坏算法 时间复杂度 计算方法 空间复杂度 计算方法: 不考虑性能实现,递归遍历查找 不用递归,也能搞定 最优性能 小试牛刀 前言 招聘季节一般都在金三银四,或者金九银十.最近在这五六月份,陆陆续续面试了十几个高级前端.有一套考察算法的小题目.后台返回一个扁平的数据结构,转成树. 我们看下题目:打平的数据内容如下: let arr = [ {id: 1, name: '部门1', pid: 0}, {id: 2, name: '部门2', pid: 1}, {id:
-
js前端面试常见浏览器缓存强缓存及协商缓存实例
目录 前言 搭建环境 强缓存 协商缓存 Etag和If-None-Match Last-Modify和if-modified-since 前言 最近在背面试题时,时常会看见浏览器缓存,虽然没有用过但是从它的描写中大致是知道它的作用和重要性.但是还是没有代码实操过,也是一知半解的,这口气咽不下啊,开始找资料,但是大部分都是理论半行代码没有,终于东拼西凑顿悟了.开始搭环境,干活. 浏览器缓存 浏览器缓存是浏览器在本地磁盘对用户最近请求过的文档进行存储,当访问者再次访问同一页面时,浏览器就可以直接从本
-
JavaScript前端面试组合函数
经历过一些列的函数式编程思想的学习总结,一些重要的高阶函数的学习,以及前一段时间关于 RxJS 的学习. 我们再回看一次 —— 组合函数 compose 本瓜越来越觉得,[易读]的代码应该是将声明和调用分开来的.根据不同的流程,用函数组合的方式.也可以说它是管道.或者说是链式调用,将声明的函数组合起来,再等待时机进行调用. 如果没有组合函数 compose,函数连续调用将会是嵌套的: const multi10 = function(x) { return x * 10; } const toS
-
前端面试之输入npm run后执行原理
目录 引言 引言 在前端开发的工作当中,使用 npm run dev 的命令启动本地开发环境,是再正常不过的事了.那么,当输入完类似 npm run xxx 的命令后,究竟是如何触发各种构建工具的构建命令以及启动 Node 服务等功能的呢? 首先我们知道,Node 作为 JavaScript 的运行时,可以把 .js 文件当做脚本来运行,像这种: node index.js 当我们使用 npm 来管理项目(或者 yarn)时,会在根目录下生成一个 package.json 文件,其中的 scri