面试分析分布式架构Redis热点key大Value解决方案
目录
- 引言
- 1、面试官:你在项目中有没有遇到Redis热点数据问题,一般都是什么原因引起的?
- 2、面试官:真实项目中,那热点数据问题你是如何准确定位的呢?
- 3、如何解决热点数据问题
- 4、面试官:关于Redis最后一个问题,Redis支持丰富的数据类型,那么这些数据类型存储的大Value如何解决,线上有遇到这种情况吗?
- 总结
引言
关于 Redis 热点数据 & 大 key 大 value 问题也是容易被问的高阶问题,不如一次痛快点说完,让面试官无话可说,个人工作经验中,热点数据问题在工作中相比雪崩更容易遇到,只是大部分时候热点不够热,都会被提前告警解决,但这个问题一旦控制不了造成的线上问题也是足够让你今年绩效垫底了,废话不说进入正题。
正常情况下,Redis 集群中数据都是均匀分配到每个节点,请求也会均匀的分布到每个分片上,但在一些特殊场景中,比如外部爬虫、攻击、热点商品等,最典型的就是明星在微博上宣布离婚,吃瓜群众纷纷涌入留言,导致微博评论功能崩溃,这种短时间内某些 key 访问量过于大,对于这种相同的 key 会请求到同一台数据分片上,导致该分片负载较高成为瓶颈问题,导致雪崩等一系列问题。
1、面试官:你在项目中有没有遇到 Redis 热点数据问题,一般都是什么原因引起的?
问题分析:上次听群里大佬面试阿里 p7 就被问到这个问题,难度指数五颗星,对我等小白着实是加分项。
答:关于热点数据问题我有话要说,这个问题我早在刚刚学习使用 Redis 时就从已经意识到了,所以在使用时会刻意避免,坚决不会给自己挖坑,热点数据最大的问题会造成 Reids 集群负载不均衡(也就是数据倾斜)导致的故障,这些问题对于 Redis 集群都是致命打击。
先说说造成 Reids 集群负载不均衡故障的主要原因:
- 高访问量的 Key,也就是热 key,根据过去的维护经验一个 key 访问的 QPS 超过 1000 就要高度关注了,比如热门商品,热门话题等。
- 大 Value,有些 key 访问 QPS 虽然不高,但是由于 value 很大,造成网卡负载较大,网卡流量被打满,单台机器可能出现千兆 / 秒,IO 故障。
- 热点 Key + 大 Value 同时存在,服务器杀手。
那么热点 key 或大 Value 会造成哪些故障呢:
- 数据倾斜问题:大 Value 会导致集群不同节点数据分布不均匀,造成数据倾斜问题,大量读写比例非常高的请求都会落到同一个 redis server 上,该 redis 的负载就会严重升高,容易打挂。
- QPS 倾斜:分片上的 QPS 不均。
- 大 Value 会导致 Redis 服务器缓冲区不足,造成 get 超时。
- 由于 Value 过大,导致机房网卡流量不足。
- Redis 缓存失效导致数据库层被击穿的连锁反应。
2、面试官:真实项目中,那热点数据问题你是如何准确定位的呢?
答:这个问题的解决办法比较宽泛,要具体看不同业务场景,比如公司组织促销活动,那参加促销的商品肯定是有办法提前统计的,这种场景就可以通过预估法。对于突发事件,不确定因素,Redis 会自己监控热点数据。大概归纳下:
提前获知法:
根据业务,人肉统计 or 系统统计可能会成为热点的数据,如,促销活动商品,热门话题,节假日话题,纪念日活动等。
Redis 客户端收集法:
调用端通过计数的方式统计 key 的请求次数,但是无法预知 key 的个数,代码侵入性强。
public Connection sendCommand(final ProtocolCommand cmd, final byte[]... args) {
//从参数中获取key
String key = analysis(args);
//计数
counterKey(key);
//ignore
}
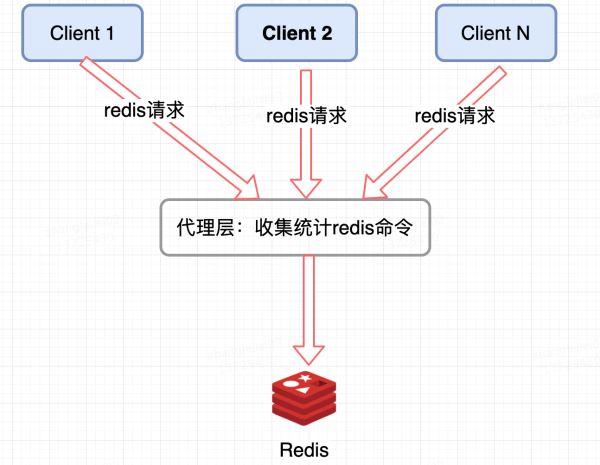
Redis 集群代理层统计:
像 Twemproxy,codis 这些基于代理的 Redis 分布式架构,统一的入口,可以在 Proxy 层做收集上报,但是缺点很明显,并非所有的 Redis 集群架构都有 proxy。
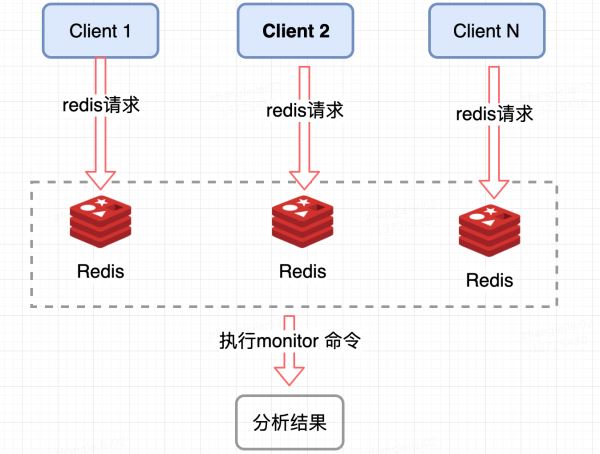
Redis 服务端收集:
监控 Redis 单个分片的 QPS,发现 QPS 倾斜到一定程度的节点进行 monitor,获取热点 key, Redis 提供了 monitor 命令,可以统计出一段时间内的某 Redis 节点上的所有命令,分析热点 key,在高并发条件下,会存在内存暴涨和 Redis 性能的隐患,所以此种方法适合在短时间内使用;同样只能统计一个 Redis 节点的热点 key,对于集群需要汇总统计,业务角度讲稍微麻烦一点。
以上为说的这 4 个方法都是现在业界比较常用的,方法,我通过学习 Redis 源码还有一个新的想法。第 5 种:修改 Redis 源码。
修改 Redis 源代码:(从读源码中想到的思路)
我发现 Redis4.0 为我们带来了许多新特性,其中便包括基于 LFU 的热点 key 发现机制,有了这个新特性,我们就可以在此基础上实现热点 key 的统计,这个只是我的个人思路。
面试官心理:小伙子还挺有想法,思路挺开阔,还打起了修改源码的注意,我都没这个野心。团队里就需要这样的人。
(发现问题,分析问题,解决问题,不等面试官发问,直接讲述如何解决热点数据问题,这才是核心内容)
3、如何解决热点数据问题
答:关于如何治理热点数据问题,解决这个问题主要从两个方面考虑,第一是数据分片,让压力均摊到集群的多个分片上,防止单个机器打挂,第二是迁移隔离。
概括总结:
key 拆分:
如果当前 key 的类型是一个二级数据结构,例如哈希类型。如果该哈希元素个数较多,可以考虑将当前 hash 进行拆分,这样该热点 key 可以拆分为若干个新的 key 分布到不同 Redis 节点上,从而减轻压力
迁移热点 key:
以 Redis Cluster 为例,可以将热点 key 所在的 slot 单独迁移到一个新的 Redis 节点上,这样这个热点 key 即使 QPS 很高,也不会影响到整个集群的其他业务,还可以定制化开发,热点 key 自动迁移到独立节点上,这种方案也较多副本。
热点 key 限流:
对于读命令我们可以通过迁移热点 key 然后添加从节点来解决,对于写命令我们可以通过单独针对这个热点 key 来限流。
增加本地缓存:
对于数据一致性不是那么高的业务,可以将热点 key 缓存到业务机器的本地缓存中,因为是业务端的本地内存中,省去了一次远程的 IO 调用。但是当数据更新时,可能会造成业务和 Redis 数据不一致。
面试官:你回答得很好,考虑得很全面。
4、面试官:关于 Redis 最后一个问题,Redis 支持丰富的数据类型,那么这些数据类型存储的大 Value 如何解决,线上有遇到这种情况吗?
问题分析:相比热点 key 大概念,大 Value 的概念比好好理解,由于 Redis 是单线程运行的,如果一次操作的 value 很大会对整个 redis 的响应时间造成负面影响,因为 Redis 是 Key - Value 结构数据库,大 value 就是单个 value 占用内存较大,对 Redis 集群造成最直接的影响就是数据倾斜。
答:(想难倒我?我可是有备而来。)
我先说说多大的 Value 算大,根据公司基础架构给出的经验值可做以下划分:
注:(经验值不是标准,都是根据集群运维人员长期观察线上 case 总结出来的)
大:string 类型 value > 10K,set、list、hash、zset 等集合数据类型中的元素个数 > 1000。
超大: string 类型 value > 100K,set、list、hash、zset 等集合数据类型中的元素个数 > 10000。
由于 Redis 是单线程运行的,如果一次操作的 value 很大会对整个 redis 的响应时间造成负面影响,所以,业务上能拆则拆,下面举几个典型的分拆方案:
- 一个较大的 key-value 拆分成几个 key-value ,将操作压力平摊到多个 redis 实例中,降低对单个 redis 的 IO 影响
- 将分拆后的几个 key-value 存储在一个 hash 中,每个 field 代表一个具体的属性,使用 hget,hmget 来获取部分的 value,使用 hset,hmset 来更新部分属性。
- hash、set、zset、list 中存储过多的元素
类似于场景一中的第一个做法,可以将这些元素分拆。
以 hash 为例,原先的正常存取流程是:
hget(hashKey, field); hset(hashKey, field, value)
现在,固定一个桶的数量,比如 10000,每次存取的时候,先在本地计算 field 的 hash 值,模除 10000,确定该 field 落在哪个 key 上,核心思想就是将 value 打散,每次只 get 你需要的。
newHashKey = hashKey + (hash(field) % 10000); hset(newHashKey, field, value); hget(newHashKey, field)
面试官已经被我折服,终于放弃了 Redis 的追问。
总结
如果你对 Redis 真对不是很熟悉,有些人干脆说自己项目小,压根没有用过 Redis,只知道一些理论知识,那么我建议你读者重点掌握《 说说 Redis 中有哪些数据结构及底层实现原理》《缓存必问:Redis 持久化,高可用集群》《Redis 雪崩,穿透,击穿三连问》这三篇,至于 Redis 热点数据问题,如果想要多谈点工资尽量掌握。推荐阅读《Redis 开发与运维》
以上就是面试分析分布式架构Redis热点key大Value解决方案的详细内容,更多关于分布式架构面试Redis热点key大Value的资料请关注我们其它相关文章!
相关推荐
-
Redis缓存及热点key问题解决方案
今天又学到了很多,感觉雪崩和穿透很有意思理解起来也比较清晰,然后我搜索了一些资料,给自己做一个普及 我们通常使用 缓存 + 过期时间的策略来帮助我们加速接口的访问速度,减少了后端负载,同时保证功能的更新 缓存穿透 缓存系统,按照KEY去查询VALUE,当KEY对应的VALUE一定不存在的时候并对KEY并发请求量很大的时候,就会对后端造成很大的压力. (查询一个必然不存在的数据.比如文章表,查询一个不存在的id,每次都会访问DB,如果有人恶意破坏,很可能直接对DB造成影响.) 由于缓存不命中,每次
-
Redis上实现分布式锁以提高性能的方案研究
背景: 在很多互联网产品应用中,有些场景需要加锁处理,比如:秒杀,全局递增ID,楼层生成等等.大部分是解决方案基于DB实现的,Redis为单进程单线程模式,采用队列模式将并发访问变成串行访问,且多客户端对Redis的连接并不存在竞争关系. 项目实践 任务队列用到分布式锁的情况比较多,在将业务逻辑中可以异步处理的操作放入队列,在其他线程中处理后出队,此时队列中使用了分布式锁,保证入队和出队的一致性.关于redis队列这块的逻辑分析,我将在下一次对其进行总结,此处先略过. 接下来对redis实现的分
-
基于redis分布式锁实现秒杀功能
最近在项目中遇到了类似"秒杀"的业务场景,在本篇博客中,我将用一个非常简单的demo,阐述实现所谓"秒杀"的基本思路. 业务场景 所谓秒杀,从业务角度看,是短时间内多个用户"争抢"资源,这里的资源在大部分秒杀场景里是商品:将业务抽象,技术角度看,秒杀就是多个线程对资源进行操作,所以实现秒杀,就必须控制线程对资源的争抢,既要保证高效并发,也要保证操作的正确. 一些可能的实现 刚才提到过,实现秒杀的关键点是控制线程对资源的争抢,根据基本的线程知识,可
-
redis分布式锁的问题与解决方法
分布式锁 在分布式环境中,为了保证业务数据的正常访问,防止出现重复请求的问题,会使用分布式锁来阻拦后续请求.我们先写一段有问题的业务代码: public void doSomething(String userId){ User user=getUser(userId); if(user==null){ user.setUserName("xxxxx"); user.setUserId(userId); insert(user); return; } update(user); } 上
-

使用redis分布式锁解决并发线程资源共享问题
前言 众所周知, 在多线程中,因为共享全局变量,会导致资源修改结果不一致,所以需要加锁来解决这个问题,保证同一时间只有一个线程对资源进行操作 但是在分布式架构中,我们的服务可能会有n个实例,但线程锁只对同一个实例有效,就需要用到分布式锁----redis setnx 原理 修改某个资源时, 在redis中设置一个key,value根据实际情况自行决定如何表示 我们既然要通过检查key是否存在(存在表示有线程在修改资源,资源上锁,其他线程不可同时操作,若key不存在,表示资源未被线程占用,允许线程
-
面试分析分布式架构Redis热点key大Value解决方案
目录 引言 1.面试官:你在项目中有没有遇到Redis热点数据问题,一般都是什么原因引起的? 2.面试官:真实项目中,那热点数据问题你是如何准确定位的呢? 3.如何解决热点数据问题 4.面试官:关于Redis最后一个问题,Redis支持丰富的数据类型,那么这些数据类型存储的大Value如何解决,线上有遇到这种情况吗? 总结 引言 关于 Redis 热点数据 & 大 key 大 value 问题也是容易被问的高阶问题,不如一次痛快点说完,让面试官无话可说,个人工作经验中,热点数据问题在工作中相比雪
-
分布式架构Redis中有哪些数据结构及底层实现原理
目录 引言 1.面试官:我看你提到,项目中使用了Reids作为缓存,为什么是Reids而不是其他,Redis有什么优势吗? 2.面试官:刚刚你提到Redis是单线程,为什么单线程模型的Redis性能不减. 3.面试官:那你刚刚说的Redis数据结构都有哪几种,如何选择使用哪种? 深入分析 1.简单动态字符串结构,Redis字符串的实现方式 2.链表数据结构,List底层结构 3.跳跃表,sortedset底层结构 关于缓存的一些算法 常用缓存数据淘汰策略 缓存数据更新策略 总结 引言 面完了负载
-
从架构思维角度分析分布式锁方案
目录 1 介绍 2 关于分布式锁 3 分布式锁的实现方案 3.1 基于数据库实现 3.1.1 乐观锁的实现方式 3.1.2 悲观锁的实现方式 3.1.3 数据库锁的优缺点 3.2基于Redis实现 3.2.1 基于缓存实现分布式锁 3.2.2缓存实现分布式锁的优缺点 3.3 基于Zookeeper实现 3.3.1 实现过程 3.3.2 zk实现分布式锁的优缺点 3.4 三种方案的对比总结 1 介绍 前面的文章我们介绍了分布式系统和它的CAP原理:一致性(Consistency).可用性(Ava
-
分布式架构中关于正向代理反向代理面试提问
目录 引言 1.面试官:完看你简历提到使用过Nginx做代理,你是如何理解“正向代理”,“反向代理”的? 2.面试官:那服务端为什么要使用代理?有啥好处? 3.面试官:那你知道哪些负载均衡算法? 深入分析 什么是负载均衡 常用的负载均衡框架 正向代理&反向代理 正向代理 反向代理 总结 引言 面完了RPC相关的一系列问题,面试官确定我对分布式架构的理论知识和服务间通讯框架(RPC) 确实了解了. 接下来又开始问我网络相关的知识,但不是直接问HTTP三次握手,TCP,UPD这些,因为这些基础已经在
-
Redis中什么是Big Key(大key)问题?如何解决Big Key问题?
目录 一.什么是Big Key? 二.Big Key产生的场景? 三.Big Key的危害? 四.如何识别Big Key? 五.如何解决Big Key问题? 补充知识:key设计 总结 一.什么是Big Key? 通俗易懂的讲,Big Key就是某个key对应的value很大,占用的redis空间很大,本质上是大value问题.key往往是程序可以自行设置的,value往往不受程序控制,因此可能导致value很大. redis中这些Big Key对应的value值很大,在序列化/反序列化过程中花
-
Springboot整合Redis实现超卖问题还原和流程分析(分布式锁)
目录 超卖简单代码 超卖问题 单服务器单应用情况下 设置synchronized Redis实现分布式锁 通过超时间解决上述问题 通过key设置值匹配的方式解决形同虚设问题 最终版 超卖简单代码 写一段简单正常的超卖逻辑代码,多个用户同时操作同一段数据,探究出现的问题. Redis中存储一项数据信息,请求对应接口,获取商品数量信息: 商品数量信息如果大于0,则扣减1,重新存储Redis中: 运行代码测试问题. /** * Redis数据库操作,超卖问题模拟 * @author * */ @Res
-
Redis超详细分析分布式锁
目录 分布式锁 应用场景 使用Redis 实现分布式锁 单机版Redis实现分布式锁 使用原生Jedis实现 使用Springboot实现 分布式锁 为了保证一个方法在高并发情况下的同一时间只能被同一个线程执行,在传统单体应用单机部署的情况下,可以使用Java并发处理相关的API(如ReentrantLcok或synchronized)进行互斥控制.但是,随着业务发展的需要,原单体单机部署的系统被演化成分布式系统后,由于分布式系统多线程.多进程并且分布在不同机器上,这将使原单机部署情况下的并发控
-
Redis获取某个大key值的脚本实例
1.前言 工作中,经常有些Redis实例使用不恰当,或者对业务预估不准确,或者key没有及时进行处理等等原因,导致某些KEY相当大. 那么大Key会带来哪些问题呢? 如果是集群模式下,无法做到负载均衡,导致请求倾斜到某个实例上,而这个实例的QPS会比较大,内存占用也较多:对于Redis单线程模型又容易出现CPU瓶颈,当内存出现瓶颈时,只能进行纵向库容,使用更牛逼的服务器. 涉及到大key的操作,尤其是使用hgetall.lrange 0 -1.get.hmget 等操作时,网卡可能会成为瓶颈,也
-
Python自定义主从分布式架构实例分析
本文实例讲述了Python自定义主从分布式架构.分享给大家供大家参考,具体如下: 环境:Win7 x64,Python 2.7,APScheduler 2.1.2. 原理图如下: 代码部分: (1).中心节点: #encoding=utf-8 #author: walker #date: 2014-12-03 #function: 中心节点(主要功能是分配任务) import SocketServer, socket, Queue CenterIP = '127.0.0.1' #中心节点IP C