python神经网络学习数据增强及预处理示例详解
目录
- 学习前言
- 处理长宽不同的图片
- 数据增强
- 1、在数据集内进行数据增强
- 2、在读取图片的时候数据增强
- 3、目标检测中的数据增强
学习前言
进行训练的话,如果直接用原图进行训练,也是可以的(就如我们最喜欢Mnist手写体),但是大部分图片长和宽不一样,直接resize的话容易出问题。
除去resize的问题外,有些时候数据不足该怎么办呢,当然要用到数据增强啦。
这篇文章就是记录我最近收集的一些数据预处理的方式
处理长宽不同的图片
对于很多分类、目标检测算法,输入的图片长宽是一样的,如224,224、416,416等。

直接resize的话,图片就会失真。

但是我们可以采用如下的代码,使其用padding的方式不失真。
from PIL import Image
def letterbox_image(image, size):
# 对图片进行resize,使图片不失真。在空缺的地方进行padding
iw, ih = image.size
w, h = size
scale = min(w/iw, h/ih)
nw = int(iw*scale)
nh = int(ih*scale)
image = image.resize((nw,nh), Image.BICUBIC)
new_image = Image.new('RGB', size, (128,128,128))
new_image.paste(image, ((w-nw)//2, (h-nh)//2))
return new_image
img = Image.open("2007_000039.jpg")
new_image = letterbox_image(img,[416,416])
new_image.show()
得到图片为:

数据增强
1、在数据集内进行数据增强
这个的意思就是可以直接增加图片的方式进行数据增强。其主要用到的函数是:
ImageDataGenerator(featurewise_center=False,
samplewise_center=False,
featurewise_std_normalization=False,
samplewise_std_normalization=False,
zca_whitening=False,
zca_epsilon=1e-06,
rotation_range=0,
width_shift_range=0.0,
height_shift_range=0.0,
brightness_range=None,
shear_range=0.0,
zoom_range=0.0,
channel_shift_range=0.0,
fill_mode='nearest',
cval=0.0,
horizontal_flip=False,
vertical_flip=False,
rescale=None,
preprocessing_function=None,
data_format=None,
validation_split=0.0,
dtype=None)
对于我而言,常用的方法如下:
datagen = ImageDataGenerator(
rotation_range=10,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.2,
zoom_range=0.1,
horizontal_flip=False,
brightness_range=[0.1, 2],
fill_mode='nearest')
其中,参数的意义为:
1、rotation_range:旋转范围
2、width_shift_range:水平平移范围
3、height_shift_range:垂直平移范围
4、shear_range:float, 透视变换的范围
5、zoom_range:缩放范围
6、horizontal_flip:水平反转
7、brightness_range:图像随机亮度增强,给定一个含两个float值的list,亮度值取自上下限值间
8、fill_mode:‘constant’,‘nearest’,‘reflect’或‘wrap’之一,当进行变换时超出边界的点将根据本参数给定的方法进行处理。
实际使用时可以利用如下函数生成图像:
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
import os
datagen = ImageDataGenerator(
rotation_range=10,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.2,
zoom_range=0.1,
horizontal_flip=False,
brightness_range=[0.1, 2],
fill_mode='nearest')
trains = os.listdir("./train/")
for index,train in enumerate(trains):
img = load_img("./train/" + train)
x = img_to_array(img)
x = x.reshape((1,) + x.shape)
i = 0
for batch in datagen.flow(x, batch_size=1,
save_to_dir='./train_out', save_prefix=str(index), save_format='jpg'):
i += 1
if i > 20:
break
生成效果为:
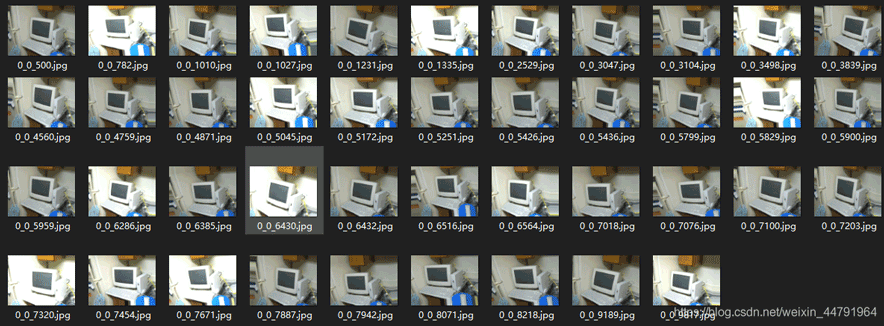
2、在读取图片的时候数据增强
ImageDataGenerator是一个非常nice的增强方式,不过如果不想生成太多的图片,然后想要直接在读图的时候处理,也是可以的。
我们用到PIL中的ImageEnhance库。
1、亮度增强ImageEnhance.Brightness(image)
2、色度增强ImageEnhance.Color(image)
3、对比度增强ImageEnhance.Contrast(image)
4、锐度增强ImageEnhance.Sharpness(image)
在如下的函数中,可以通过改变Ehance函数中的参数实现不同的增强方式。
import os
import numpy as np
from PIL import Image
from PIL import ImageEnhance
def Enhance_Brightness(image):
# 变亮,增强因子为0.0将产生黑色图像,为1.0将保持原始图像。
# 亮度增强
enh_bri = ImageEnhance.Brightness(image)
brightness = np.random.uniform(0.6,1.6)
image_brightened = enh_bri.enhance(brightness)
return image_brightened
def Enhance_Color(image):
# 色度,增强因子为1.0是原始图像
# 色度增强
enh_col = ImageEnhance.Color(image)
color = np.random.uniform(0.4,2.6)
image_colored = enh_col.enhance(color)
return image_colored
def Enhance_contrasted(image):
# 对比度,增强因子为1.0是原始图片
# 对比度增强
enh_con = ImageEnhance.Contrast(image)
contrast = np.random.uniform(0.6,1.6)
image_contrasted = enh_con.enhance(contrast)
return image_contrasted
def Enhance_sharped(image):
# 锐度,增强因子为1.0是原始图片
# 锐度增强
enh_sha = ImageEnhance.Sharpness(image)
sharpness = np.random.uniform(0.4,4)
image_sharped = enh_sha.enhance(sharpness)
return image_sharped
def Add_pepper_salt(image):
# 增加椒盐噪声
img = np.array(image)
rows,cols,_=img.shape
random_int = np.random.randint(500,1000)
for _ in range(random_int):
x=np.random.randint(0,rows)
y=np.random.randint(0,cols)
if np.random.randint(0,2):
img[x,y,:]=255
else:
img[x,y,:]=0
img = Image.fromarray(img)
return img
def Enhance(image_path, change_bri=1, change_color=1, change_contras=1, change_sha=1, add_noise=1):
#读取图片
image = Image.open(image_path)
if change_bri==1:
image = Enhance_Brightness(image)
if change_color==1:
image = Enhance_Color(image)
if change_contras==1:
image = Enhance_contrasted(image)
if change_sha==1:
image = Enhance_sharped(image)
if add_noise==1:
image = Add_pepper_salt(image)
image.save("0.jpg")
Enhance("2007_000039.jpg")
原图:

效果如下:

3、目标检测中的数据增强
在目标检测中如果要增强数据,并不是直接增强图片就好了,还要考虑到图片扭曲后框的位置。
也就是框的位置要跟着图片的位置进行改变。
原图:

增强后:

from PIL import Image, ImageDraw
import numpy as np
from matplotlib.colors import rgb_to_hsv, hsv_to_rgb
def rand(a=0, b=1):
return np.random.rand()*(b-a) + a
def get_random_data(annotation_line, input_shape, random=True, max_boxes=20, jitter=.3, hue=.1, sat=1.5, val=1.5, proc_img=True):
'''random preprocessing for real-time data augmentation'''
line = annotation_line.split()
image = Image.open(line[0])
iw, ih = image.size
h, w = input_shape
box = np.array([np.array(list(map(int,box.split(',')))) for box in line[1:]])
# resize image
new_ar = w/h * rand(1-jitter,1+jitter)/rand(1-jitter,1+jitter)
scale = rand(.7, 1.3)
if new_ar < 1:
nh = int(scale*h)
nw = int(nh*new_ar)
else:
nw = int(scale*w)
nh = int(nw/new_ar)
image = image.resize((nw,nh), Image.BICUBIC)
# place image
dx = int(rand(0, w-nw))
dy = int(rand(0, h-nh))
new_image = Image.new('RGB', (w,h), (128,128,128))
new_image.paste(image, (dx, dy))
image = new_image
# flip image or not
flip = rand()<.5
if flip: image = image.transpose(Image.FLIP_LEFT_RIGHT)
# distort image
hue = rand(-hue, hue)
sat = rand(1, sat) if rand()<.5 else 1/rand(1, sat)
val = rand(1, val) if rand()<.5 else 1/rand(1, val)
x = rgb_to_hsv(np.array(image)/255.)
x[..., 0] += hue
x[..., 0][x[..., 0]>1] -= 1
x[..., 0][x[..., 0]<0] += 1
x[..., 1] *= sat
x[..., 2] *= val
x[x>1] = 1
x[x<0] = 0
image_data = hsv_to_rgb(x) # numpy array, 0 to 1
# correct boxes
box_data = np.zeros((max_boxes,5))
if len(box)>0:
np.random.shuffle(box)
box[:, [0,2]] = box[:, [0,2]]*nw/iw + dx
box[:, [1,3]] = box[:, [1,3]]*nh/ih + dy
if flip: box[:, [0,2]] = w - box[:, [2,0]]
box[:, 0:2][box[:, 0:2]<0] = 0
box[:, 2][box[:, 2]>w] = w
box[:, 3][box[:, 3]>h] = h
box_w = box[:, 2] - box[:, 0]
box_h = box[:, 3] - box[:, 1]
box = box[np.logical_and(box_w>1, box_h>1)] # discard invalid box
if len(box)>max_boxes: box = box[:max_boxes]
box_data[:len(box)] = box
return image_data, box_data
if __name__ == "__main__":
line = r"F:\Collection\yolo_Collection\keras-yolo3-master\VOCdevkit/VOC2007/JPEGImages/00001.jpg 738,279,815,414,0"
image_data, box_data = get_random_data(line,[416,416])
left, top, right, bottom = box_data[0][0:4]
img = Image.fromarray((image_data*255).astype(np.uint8))
draw = ImageDraw.Draw(img)
draw.rectangle([left, top, right, bottom])
img.show()
以上就是python神经网络学习数据增强及预处理示例详解的详细内容,更多关于python神经网络数据增强预处理的资料请关注我们其它相关文章!
相关推荐
-
python数据预处理之将类别数据转换为数值的方法
在进行python数据分析的时候,首先要进行数据预处理. 有时候不得不处理一些非数值类别的数据,嗯, 今天要说的就是面对这些数据该如何处理. 目前了解到的大概有三种方法: 1,通过LabelEncoder来进行快速的转换: 2,通过mapping方式,将类别映射为数值.不过这种方法适用范围有限: 3,通过get_dummies方法来转换. import pandas as pd from io import StringIO csv_data = '''A,B,C,D 1,2,3,4 5,6,,
-

python数据预处理之数据标准化的几种处理方式
何为标准化: 在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析.数据标准化也就是统计数据的指数化.数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面.数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果.数据无量纲化处理主要解决数据的可比性. 几种标准化方法: 归一化Max-Min min-max标准化方
-
Python----数据预处理代码实例
本文实例为大家分享了Python数据预处理的具体代码,供大家参考,具体内容如下 1.导入标准库 import numpy as np import matplotlib.pyplot as plt import pandas as pd 2.导入数据集 dataset = pd.read_csv('data (1).csv') # read_csv:读取csv文件 #创建一个包含所有自变量的矩阵,及因变量的向量 #iloc表示选取数据集的某行某列:逗号之前的表示行,之后的表示列:冒号表示选取全部
-
python实现数据预处理之填充缺失值的示例
1.给定一个数据集noise-data-1.txt,该数据集中保护大量的缺失值(空格.不完整值等).利用"全局常量"."均值或者中位数"来填充缺失值. noise-data-1.txt: 5.1 3.5 1.4 0.2 4.9 3 1.4 0.2 4.7 3.2 1.3 0.2 4.6 3.1 1.5 0.2 5 3.6 1.4 0.2 5.4 3.9 1.7 0.4 4.6 3.4 1.4 0.3 5 3.4 1.5 0.2 4.4 2.9 1.4 0.2 4.9
-
python数据预处理 :样本分布不均的解决(过采样和欠采样)
何为样本分布不均: 样本分布不均衡就是指样本差异非常大,例如共1000条数据样本的数据集中,其中占有10条样本分类,其特征无论如何你和也无法实现完整特征值的覆盖,此时属于严重的样本分布不均衡. 为何要解决样本分布不均: 样本分部不均衡的数据集也是很常见的:比如恶意刷单.黄牛订单.信用卡欺诈.电力窃电.设备故障.大企业客户流失等. 样本不均衡将导致样本量少的分类所包含的特征过少,很难从中提取规律,即使得到分类模型,也容易产生过度依赖于有限的数量样本而导致过拟合问题,当模型应用到新的数据上时,模型的
-
Python数据预处理之数据规范化(归一化)示例
本文实例讲述了Python数据预处理之数据规范化.分享给大家供大家参考,具体如下: 数据规范化 为了消除指标之间的量纲和取值范围差异的影响,需要进行标准化(归一化)处理,将数据按照比例进行缩放,使之落入一个特定的区域,便于进行综合分析. 数据规范化方法主要有: - 最小-最大规范化 - 零-均值规范化 数据示例 代码实现 #-*- coding: utf-8 -*- #数据规范化 import pandas as pd import numpy as np datafile = 'normali
-
python神经网络学习数据增强及预处理示例详解
目录 学习前言 处理长宽不同的图片 数据增强 1.在数据集内进行数据增强 2.在读取图片的时候数据增强 3.目标检测中的数据增强 学习前言 进行训练的话,如果直接用原图进行训练,也是可以的(就如我们最喜欢Mnist手写体),但是大部分图片长和宽不一样,直接resize的话容易出问题. 除去resize的问题外,有些时候数据不足该怎么办呢,当然要用到数据增强啦. 这篇文章就是记录我最近收集的一些数据预处理的方式 处理长宽不同的图片 对于很多分类.目标检测算法,输入的图片长宽是一样的,如224,22
-
TensorFlow人工智能学习数据合并分割统计示例详解
目录 一.数据合并与分割 1.tf.concat() 2.tf.split() 3.tf.stack() 二.数据统计 1.tf.norm() 2.reduce_min/max/mean() 3.tf.argmax/argmin() 4.tf.equal() 5.tf.unique() 一.数据合并与分割 1.tf.concat() 填入两个tensor, 指定某维度,在指定的维度合并.除了合并的维度之外,其他的维度必须相等. 2.tf.split() 填入tensor,指定维度,指定分割的数量
-
人工智能学习Pytorch教程Tensor基本操作示例详解
目录 一.tensor的创建 1.使用tensor 2.使用Tensor 3.随机初始化 4.其他数据生成 ①torch.full ②torch.arange ③linspace和logspace ④ones, zeros, eye ⑤torch.randperm 二.tensor的索引与切片 1.索引与切片使用方法 ①index_select ②... ③mask 三.tensor维度的变换 1.维度变换 ①torch.view ②squeeze/unsqueeze ③expand,repea
-
python爬虫使用requests发送post请求示例详解
简介 HTTP协议规定post提交的数据必须放在消息主体中,但是协议并没有规定必须使用什么编码方式.服务端通过是根据请求头中的Content-Type字段来获知请求中的消息主体是用何种方式进行编码,再对消息主体进行解析.具体的编码方式包括: application/x-www-form-urlencoded 最常见post提交数据的方式,以form表单形式提交数据. application/json 以json串提交数据. multipart/form-data 一般使用来上传文件. 一. 以f
-
Python黑魔法库安装及操作字典示例详解
目录 1. 安装方法 2. 简单示例 3. 兼容字典的所有操作 4. 设置返回默认值 5. 工厂函数自动创建key 6. 序列化的支持 7. 说说局限性 本篇文章收录于<Python黑魔法手册>v3.0 第七章,手册完整版在线阅读地址:Python黑魔法手册 3.0 文档 字典是 Python 中基础的数据结构之一,字典的使用,可以说是非常的简单粗暴,但即便是这样一个与世无争的数据结构,仍然有很多人 "用不惯它" . 也许你并不觉得,但我相信,你看了这篇文章后,一定会和我一
-
MySQL教程数据定义语言DDL示例详解
目录 1.SQL语言的基本功能介绍 2.数据定义语言的用途 3.数据库的创建和销毁 4.数据库表的操作(所有演示都以student表为例) 1)创建表 2)修改表 3)销毁表 如果你是刚刚学习MySQL的小白,在你看这篇文章之前,请先看看下面这些文章.有些知识你可能掌握起来有点困难,但请相信我,按照我提供的这个学习流程,反复去看,肯定可以看明白的,这样就不至于到了最后某些知识不懂却不知道从哪里下手去查. <MySQL详细安装教程> <MySQL完整卸载教程> <这点基础都不懂
-
人工智能学习Pytorch梯度下降优化示例详解
目录 一.激活函数 1.Sigmoid函数 2.Tanh函数 3.ReLU函数 二.损失函数及求导 1.autograd.grad 2.loss.backward() 3.softmax及其求导 三.链式法则 1.单层感知机梯度 2. 多输出感知机梯度 3. 中间有隐藏层的求导 4.多层感知机的反向传播 四.优化举例 一.激活函数 1.Sigmoid函数 函数图像以及表达式如下: 通过该函数,可以将输入的负无穷到正无穷的输入压缩到0-1之间.在x=0的时候,输出0.5 通过PyTorch实现方式
-
Python可视化学习之seaborn绘制矩阵图详解
目录 本文内容速览 1.绘图数据准备 2.seaborn.pairplot 加上分类变量 修改调色盘 x,y轴方向选取相同子集 x,y轴方向选取不同子集 非对角线散点图加趋势线 对角线上的四个图绘制方式 只显示网格下三角图形 图形外观设置 3.seaborn.PairGrid(更灵活的绘制矩阵图) 每个子图绘制同类型的图 对角线和非对角线分别绘制不同类型图 对角线上方.对角线.对角线下方分别绘制不同类型图 其它一些参数修改 本文内容速览 1.绘图数据准备 还是使用鸢尾花iris数据集 #导入本帖
-
Python中八大图像特效算法的示例详解
目录 0写在前面 1毛玻璃特效 2浮雕特效 3油画特效 4马赛克特效 5素描特效 6怀旧特效 7流年特效 8卡通特效 0 写在前面 图像特效处理是基于图像像素数据特征,将原图像进行一定步骤的计算——例如像素作差.灰度变换.颜色通道融合等,从而达到期望的效果.图像特效处理是日常生活中应用非常广泛的一种计算机视觉应用,出现在各种美图软件中,这些精美滤镜背后的数学原理都是相通的,本文主要介绍八大基本图像特效算法,在这些算法基础上可以进行二次开发,生成更高级的滤镜. 本文采用面向对象设计,定义了一个图像
-
Go语言学习教程之反射的示例详解
目录 介绍 反射的规律 1. 从接口值到反射对象的反射 2. 从反射对象到接口值的反射 3. 要修改反射对象,该值一定是可设置的 介绍 reflect包实现运行时反射,允许一个程序操作任何类型的对象.典型的使用是:取静态类型interface{}的值,通过调用TypeOf获取它的动态类型信息,调用ValueOf会返回一个表示运行时数据的一个值.本文通过记录对reflect包的简单使用,来对反射有一定的了解.本文使用的Go版本: $ go version go version go1.18 dar