JAVA实现PDF转HTML文档的示例代码
本文是基于PDF文档转PNG图片,然后进行图片拼接,拼接后的图片转为base64字符串,然后拼接html文档写入html文件实现PDF文档转HTML文档。
引入Maven依赖
<!-- https://mvnrepository.com/artifact/org.apache.pdfbox/pdfbox -->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.12</version>
</dependency>
工具实现类
package com.frame.utils;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.rendering.PDFRenderer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import sun.misc.BASE64Decoder;
import sun.misc.BASE64Encoder;
import javax.imageio.ImageIO;
import java.awt.*;
import java.awt.image.BufferedImage;
import java.io.*;
/**
* PDF文档转HTML文档
* @author LXW
* @date 2020/6/17 16:45
*/
public class PdfConvertHtmlUtil {
/**
* 日志对象
*/
private static Logger logger = LoggerFactory.getLogger(PdfConvertHtmlUtil.class);
/**
* PDF文档流转Png
* @param pdfFileInputStream
* @return BufferedImage
*/
public static BufferedImage pdfStreamToPng(InputStream pdfFileInputStream){
PDDocument doc = null;
PDFRenderer renderer = null;
try {
doc = PDDocument.load(pdfFileInputStream);
renderer = new PDFRenderer(doc);
int pageCount = doc.getNumberOfPages();
BufferedImage image = null;
for (int i = 0; i < pageCount; i++) {
if (image != null) {
image = combineBufferedImages(image, renderer.renderImageWithDPI(i, 144));
}
if (i == 0) {
image = renderer.renderImageWithDPI(i, 144); // Windows native DPI
}
// BufferedImage srcImage = resize(image, 240, 240);//产生缩略图
}
return combineBufferedImages(image);
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
if(doc != null){doc.close();}
} catch (IOException e) {
e.printStackTrace();
}
}
return null;
}
/**
*BufferedImage拼接处理,添加分割线
* @param images
* @return BufferedImage
*/
public static BufferedImage combineBufferedImages(BufferedImage... images) {
int height = 0;
int width = 0;
for (BufferedImage image : images) {
//height += Math.max(height, image.getHeight());
height += image.getHeight();
width = image.getWidth();
}
BufferedImage combo = new BufferedImage(width, height, BufferedImage.TYPE_INT_ARGB);
Graphics2D g2 = combo.createGraphics();
int x = 0;
int y = 0;
for (BufferedImage image : images) {
//int y = (height - image.getHeight()) / 2;
g2.setStroke(new BasicStroke(2.0f));// 线条粗细
g2.setColor(new Color(193, 193, 193));// 线条颜色
g2.drawLine(x, y, width, y);// 线条起点及终点位置
g2.drawImage(image, x, y, null);
//x += image.getWidth();
y += image.getHeight();
}
return combo;
}
/**
* 通过Base64创建HTML文件并输出html文件
* @param base64
* @param htmlPath html保存路径
*/
public static void createHtmlByBase64(String base64,String htmlPath) {
StringBuilder stringHtml = new StringBuilder();
PrintStream printStream = null;
try {
// 打开文件
printStream = new PrintStream(new FileOutputStream(htmlPath));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
// 输入HTML文件内容
stringHtml.append("<html><head>");
stringHtml.append("<meta http-equiv=\"Content-Type\" content=\"text/html; charset=UTF-8\">");
stringHtml.append("<title></title>");
stringHtml.append("</head>");
stringHtml.append(
"<body style=\"\r\n" + " text-align: center;\r\n" + " background-color: #C1C1C1;\r\n" + "\">");
stringHtml.append("<img src=\"data:image/png;base64," + base64 + "\" />");
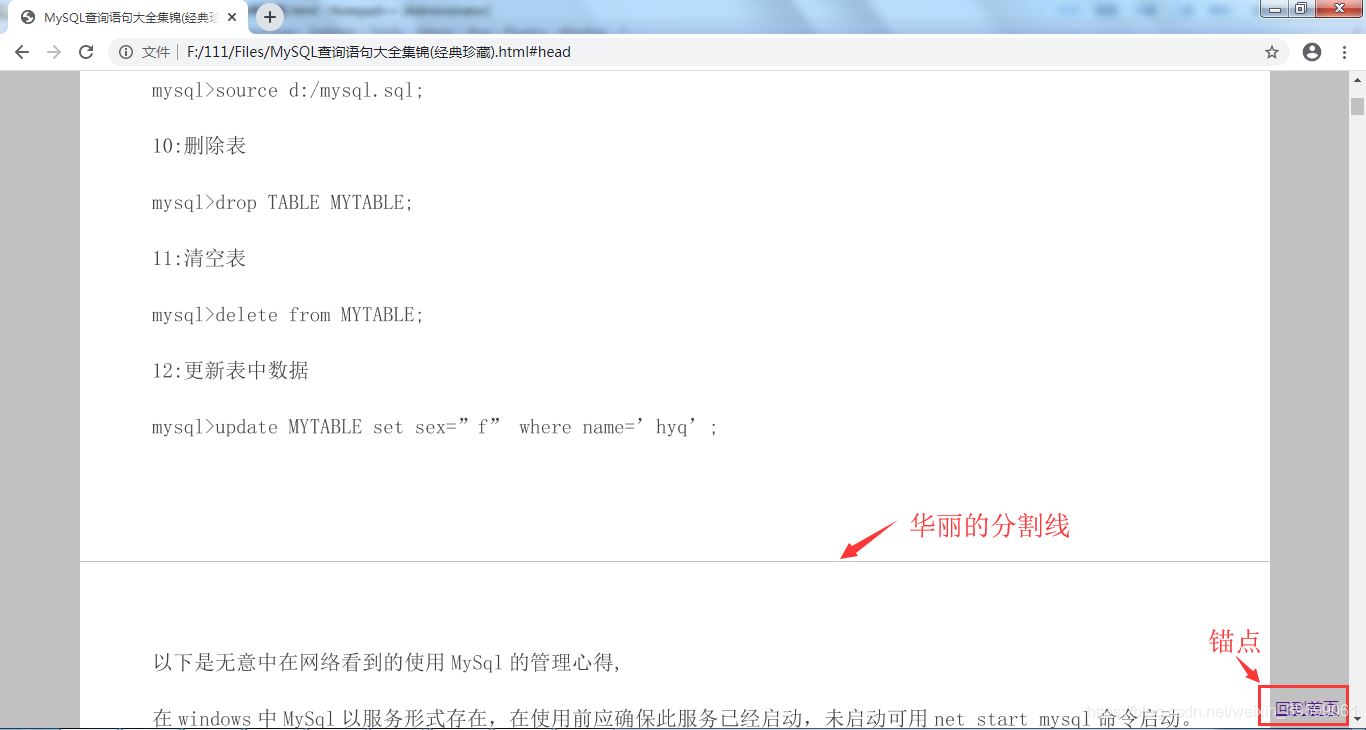
stringHtml.append("<a name=\"head\" style=\"position:absolute;top:0px;\"></a>");
//添加锚点用于返回首页
stringHtml.append("<a style=\"position:fixed;bottom:10px;right:10px\" href=\"#head\">回到首页</a>");
stringHtml.append("</body></html>");
try {
// 将HTML文件内容写入文件中
printStream.println(stringHtml.toString());
} catch (Exception e) {
e.printStackTrace();
}finally {
if(printStream != null){printStream.close();}
}
}
/**
* bufferedImage 转为 base64编码
* @param bufferedImage
* @return
*/
public static String bufferedImageToBase64(BufferedImage bufferedImage) {
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
String png_base64 = "";
try {
ImageIO.write(bufferedImage, "png", byteArrayOutputStream);// 写入流中
byte[] bytes = byteArrayOutputStream.toByteArray();// 转换成字节
BASE64Encoder encoder = new BASE64Encoder();
// 转换成base64串 删除 \r\n
png_base64 = encoder.encodeBuffer(bytes).trim()
.replaceAll("\n", "")
.replaceAll("\r", "");
} catch (IOException e) {
e.printStackTrace();
}
return png_base64;
}
}
测试Demo
public static void main(String[] args) {
File file = new File("F:\\111\\Files\\MySQL查询语句大全集锦(经典珍藏).pdf");
String htmlPath = "F:\\111\\Files\\MySQL查询语句大全集锦(经典珍藏).html";
InputStream inputStream = null;
BufferedImage bufferedImage = null;
try {
inputStream = new FileInputStream(file);
bufferedImage = pdfStreamToPng(inputStream);
String base64_png = bufferedImageToBase64(bufferedImage);
createHtmlByBase64(base64_png,htmlPath);
} catch (FileNotFoundException e) {
e.printStackTrace();
}finally {
try {
if(inputStream != null){inputStream.close();}
} catch (IOException e) {
e.printStackTrace();
}
}
}
最终结果 转换后文件
转换后的文件内容
文件预览效果
到此这篇关于JAVA实现PDF转HTML文档的示例代码的文章就介绍到这了,更多相关JAVA PDF转HTML 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Java实现Html转Pdf的方法
本文实例讲述了Java实现Html转Pdf的方法.分享给大家供大家参考.具体如下: package test; import java.io.File; import java.io.FileOutputStream; import java.io.OutputStream; import org.xhtmlrenderer.pdf.ITextFontResolver; import org.xhtmlrenderer.pdf.ITextRenderer; import com.lowagie.
-
Java实现Word/Pdf/TXT转html的实例代码
引言: 最近公司在做一个教育培训学习及在线考试的项目,本人主要从事网络课程模块,主要做课程分类,课程,课件的创建及在线学习和统计的功能,因为课件涉及到多种类型,像视频,音频,图文,外部链接及文档类型.其中就涉及到一个问题,就是文档型课件课程在网页上的展示和学习问题,因为要在线统计学习的课程,学习的人员,学习的时长,所以不能像传统做法将文档下载到本地学习,那样就不受系统控制了,所以最终的方案是,在上传文档型课件的时候,将其文件对应的转换成HTML文件,以便在网页上能够浏览学习 下边主要针对word
-
Java实现Word/Pdf/TXT转html的示例
引言: 最近公司在做一个教育培训学习及在线考试的项目,本人主要从事网络课程模块,主要做课程分类,课程,课件的创建及在线学习和统计的功能,因为课件涉及到多种类型,像视频,音频,图文,外部链接及文档类型.其中就涉及到一个问题,就是文档型课件课程在网页上的展示和学习问题,因为要在线统计学习的课程,学习的人员,学习的时长,所以不能像传统做法将文档下载到本地学习,那样就不受系统控制了,所以最终的方案是,在上传文档型课件的时候,将其文件对应的转换成HTML文件,以便在网页上能够浏览学习 下边主要针对word
-

JAVA实现PDF转HTML文档的示例代码
本文是基于PDF文档转PNG图片,然后进行图片拼接,拼接后的图片转为base64字符串,然后拼接html文档写入html文件实现PDF文档转HTML文档. 引入Maven依赖 <!-- https://mvnrepository.com/artifact/org.apache.pdfbox/pdfbox --> <dependency> <groupId>org.apache.pdfbox</groupId> <artifactId>pdfbox
-
Java实现PDF转为Word文档的示例代码
目录 代码编译环境 将 PDF 转换为固定布局的 Doc/Docx 文档 完整代码 将 PDF 转换为流动形态的 Doc/Docx 文档 完整代码 效果图 众所周知,PDF文档除了具有较强稳定性和兼容性外, 还具有较强的安全性,在工作中可以有效避免别人无意中对文档内容进行修改.但与此同时,也妨碍了对文档的正常的修改.这时我们可以将PDF转为Word文档进行修改或再编辑.使用软件将 PDF 文档转换为 Word 文档十分简单,然而要在转换时保持布局甚至字体格式却并不容易.本文将分为以下两部分介绍如
-
Java开发SpringBoot集成接口文档实现示例
目录 swagger vs smart-doc Swagger的代码侵入性比较强 原生swagger不支持接口的参数分组 简单罗列一下smart-doc的优点 SpringBoot集成 smart-doc 引入依赖,版本选择最新版本 新建配置文件smart-doc.json 通过执行maven 命令生成对应的接口文档 访问接口文档 功能增强 1. 开启调试 2. 通用响应体 3. 自定义Header 4. 参数分组 5. idea配置doc 6. 完整配置 小结 之前我在SpringBoot老鸟
-
Java实现合并word文档的示例代码
目录 说明 实现 1.首先定义好主文档 2.定义需要追加的文档 3. 代码实现 4. 成果展示 说明 在做项目中,遇到了一种情况,需要将一个小word文档的内容插入到一个大word(主文档)中. 实现 1.首先定义好主文档 在主文档需要插入小word文档的位置上添加一个书签,这个书签名字要记住,后面要用. 2.定义需要追加的文档 3. 代码实现 package com.test.word; import com.aspose.words.Body; import com.aspose.words
-
Java 生成PDF文档的示例代码
最近项目需要实现PDF下载的功能,由于没有这方面的经验,从网上花了很长时间查找了相关的资料.整理之后,发现有几个框架可以实现这个功能. 1. 开源框架支持 iText,生成PDF文档,还支持将XML.Html文件转化为PDF文件: Apache PDFBox,生成.合并PDF文档: docx4j,生成docx文档,支持转换为PDF格式. 2. 实现方案 比较了一番后,采用了FreeMarker+docx4j+Apache PDFBox的方案: maven依赖 <!-- pdfbox --> &
-
jquery的相对父元素和相对文档定位示例代码
在开发jquery时候经常需要用到定位,这里概括两种定位: 1.相对父元素定位: $("#ele").position(),进而得到 left = $("#ele").postion().left right = $("#ele").postion().right 2.相对文档定位:$("#ele").offset(), 进而得到 left = $("#ele").offset().left right =
-
JAVA读取PDF、WORD文档实例代码
读取PDF文件jar引用 <dependency> <groupid>org.apache.pdfbox</groupid> pdfbox</artifactid> <version>1.8.13</version> </dependency> 读取WORD文件jar引用 <dependency> <groupid>org.apache.poi</groupid> poi-scratch
-
三种Java打印PDF文档的实例代码
以下内容归纳了通过Java程序打印PDF文档时的3种情形.即: 1 静默打印 2 显示打印对话框打印 3 打印PDF时自定义纸张大小 使用工具:Spire.PDF for Java Jar文件获取及导入: 方法1:下载jar包.下载后,解压文件,并将lib文件夹下的Spire.Pdf.jar导入java程序. 方法2:可通过maven库导入.参考导入方法. Java代码示例 [示例1]静默打印 即通过使用默认打印机直接打印PDF文档.打印时,我们可以设置打印份数,设置纸张打印页边距等. impo
-
Java 添加超链接到 Word 文档方法详解
在Word文档中,超链接是指在特定文本或者图片中插入的能跳转到其他位置或网页的链接,它也是我们在编辑制作Word文档时广泛使用到的功能之一.今天这篇文章就将为大家演示如何使用Free Spire.Doc for Java在Word文档中添加文本超链接和图片超链接. Jar包导入 方法一:下载Free Spire.Doc for Java包并解压缩,然后将lib文件夹下的Spire.Doc.jar包作为依赖项导入到Java应用程序中. 方法二:通过Maven仓库安装JAR包,配置pom.xml文件
-
Java实现 word、excel文档在线预览
java实现办公文件在线预览功能是一个大家在工作中也许会遇到的需求,网上些公司专门提供这样的服务,不过需要收费 如果想要免费的,可以用openoffice,实现原理就是: 通过第三方工具openoffice,将word.excel.ppt.txt等文件转换为pdf文件流: 当然如果装了Adobe Reader XI,那把pdf直接拖到浏览器页面就可以直接打开预览,前提就是浏览器支持pdf文件浏览. 我这里介绍通过poi实现word.excel.ppt转pdf流,这样就可以在浏览器上实现预览了.